- 論文原文:https://arxiv.org/abs/2004.10934
- 代碼
- 原版c++: https://github.com/AlexeyAB/darknet
- keras:https://github.com/Ma-Dan/keras-yolo4
- pytorch:https://github.com/Tianxiaomo/pytorch-YOLOv4
前言
2020年YOLO系列的作者Redmon在推特上發表聲明,出于道德方面的考慮,從此退出CV界。本以為YOLOv3已經是YOLO系列的終局之戰。沒想到,俄羅斯的程序員 Alexey Bochkovskiy 憑借自己的摸索復現了 YOLO 系列全部模型,并總結了最接近幾年目標檢測的各種套路推出了 YOLO v4,然后與Redmon取得聯系,正式將他們的研究命名為YOLO v4。
簡單來說,就是說這個YOLO v4算法是在原有YOLO目標檢測架構的基礎上,采用了近些年CNN領域中最優秀的優化策略,從數據處理、主干網絡、網絡訓練、激活函數、損失函數等各個方面都有著不同程度的優化,雖沒有理論上的創新,但是會受到許許多多的工程師的歡迎,各種優化算法的嘗試。文章如同于目標檢測的trick綜述,效果達到了實現FPS與Precision平衡的目標檢測 new baseline。更有意思的是作者提出了 backbone,neck,head 的目標檢測通用框架套路。
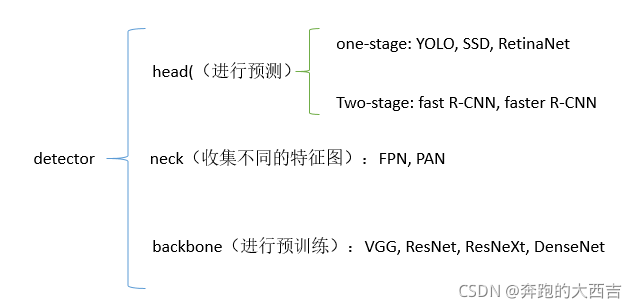
backbone, neck, head 其實非常的形象。它表示組成一個“人”的三個部分。從下到上就是 backbone, neck, head 。
- backbone:各類卷積網絡,目的是對原始圖像做初步的特征提取。
- neck:各類結構,目的是從結構上做“特征的融合”。主要為解決小目標檢測,重疊目標檢測等問題。
- head:gd 編碼,回歸和解析。
0 摘要
目前有很多可以提高CNN準確性的算法。這些算法的組合在龐大數據集上進行測試、對實驗結果進行理論驗證都是非常必要的。有些算法只在特定的模型上有效果,并且只對特定的問題有效,或者只對小規模的數據集有效;然而有些算法,比如 batch-normalization(批量歸一化) 和 residual-connections(殘差連接),對大多數的模型、任務和數據集都適用。我們認為這樣通用的算法包括:Weighted-Residual-Connections(WRC,加權殘差連接), Cross-Stage-Partial-connections(CSP,跨階段部分連接), Cross mini-Batch Normalization(CmBN,交叉小批量標準化), Self-adversarial-training(SAT,自對抗訓練)以及Mish-activation(Mish激活)。我們使用了新的算法:WRC, CSP, CmBN, SAT, Mish activation, Mosaic data augmentation(馬賽克數據增強), CmBN, Dropblock regularization 和CIoU loss以及它們的組合,獲得了最優的效果:在MS COCO數據集上的AP值為43.5%(65.7% AP50),在Tesla V100上的實時推理速度為65FPS。開源代碼鏈接:https://github.com/AlexeyAB/darknet。
從摘要中我們基本上可以看出:v4實際上就是保留Darknet作為backbone,然后通過大量的實驗研究了眾多普適性算法對網絡性能的影響,然后找到了它們最優的組合。
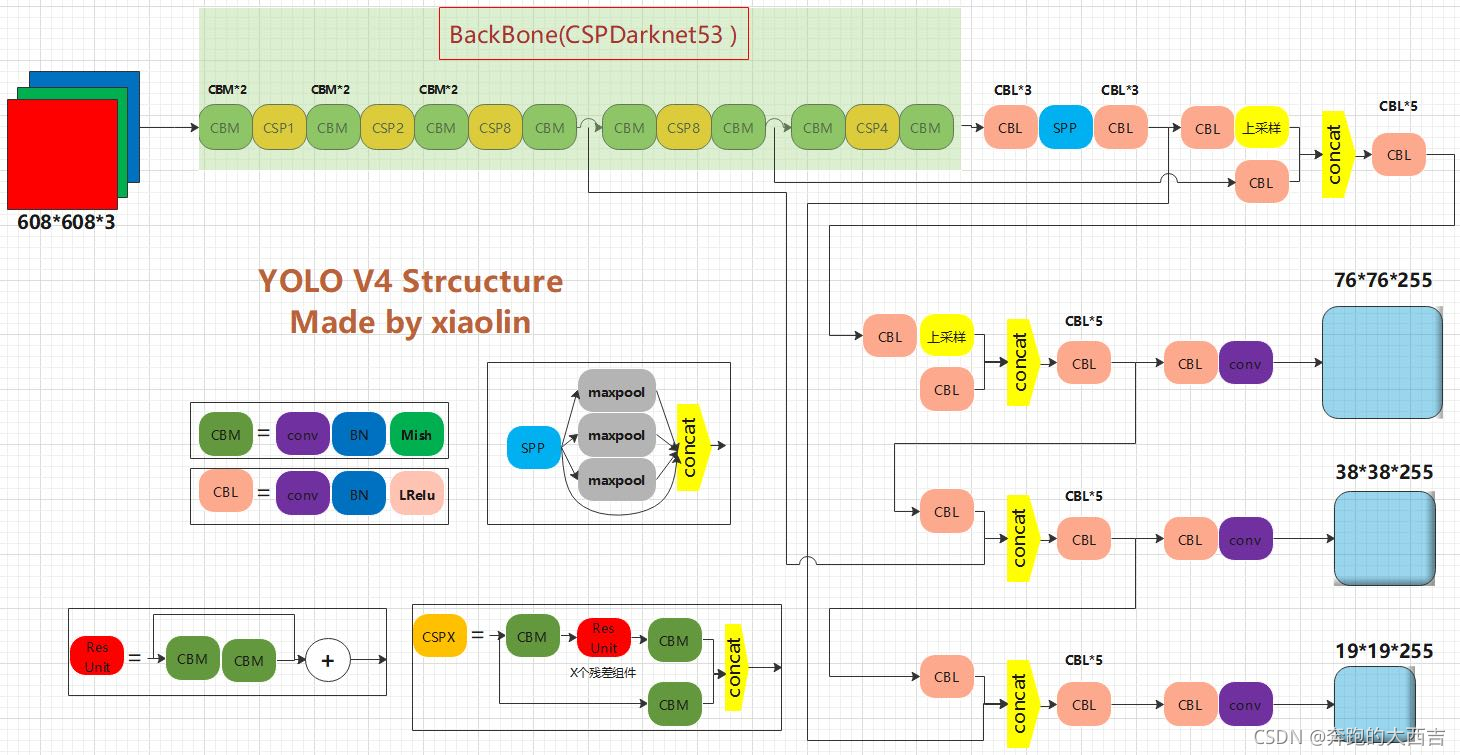
先放網絡架構(圖不記得從哪里保存下來的了)
YOLOv4 = CSPDarknet53(主干) + SPP附加模塊(頸) + PANet路徑聚合(頸) + YOLOv3(頭部)
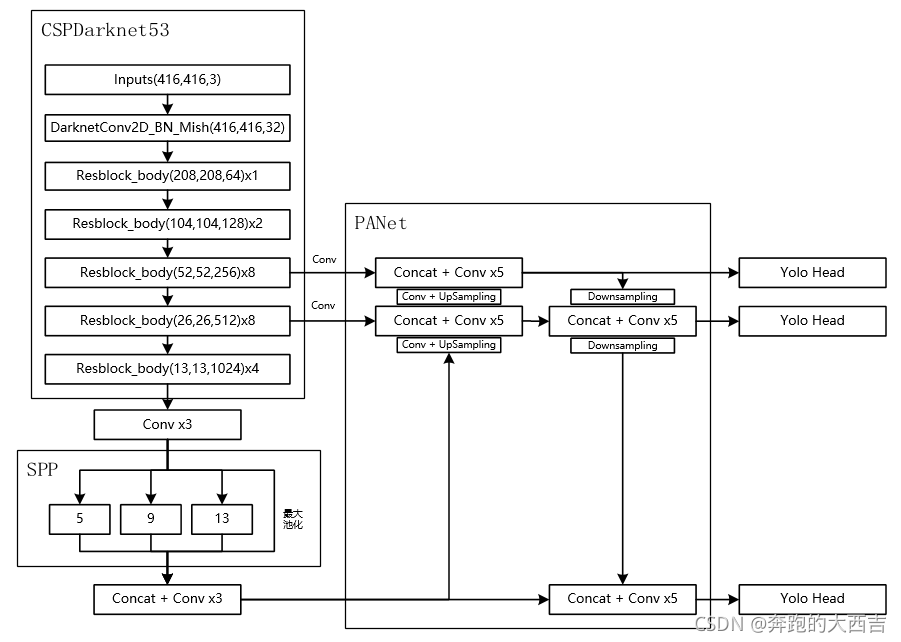
當輸入是416x416時,特征結構如下
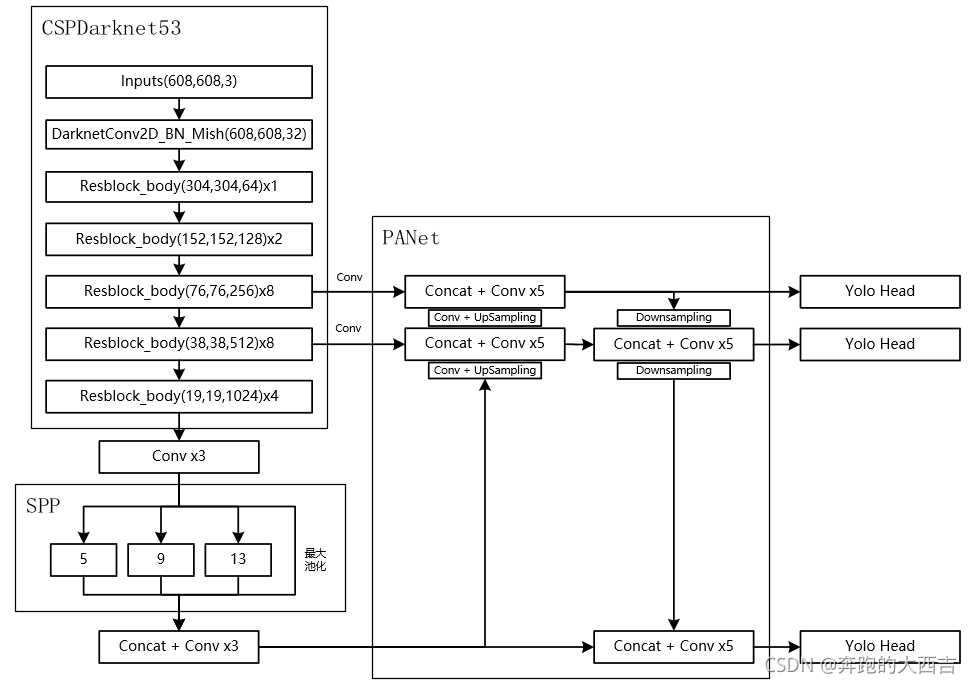
當輸入是608x608時,特征結構如下:
1 介紹
大部分基于CNN的目標檢測器主要只適用于推薦系統。舉例來說,通過城市相機尋找免費停車位置的系統使用著慢速但是高精度的模型,然而汽車碰撞警告卻使用著快速但是低精度的模型。提高實時目標檢測器的精度不經能夠應用在推薦系統上,而且還能用于獨立的流程管理以及降低人員數量上。目前大部分高精度的神經網絡不僅不能實時運行,并且需要較大的mini-batch-size在多個GPUs上進行訓練。我們構建了僅在一塊GPU上就可以實時運行的CNN解決了這個問題,并且它只需要在一塊GPU上進行訓練。
我們工作的主要目標就是設計一個僅在單個計算系統(比如單個GPU)上就可以快速運行的目標檢測器并且對并行計算進行優化,并非減低計量計算量理論指標(BFLOP)。我們希望這個檢測器能夠輕松的訓練和使用。具體來說就是任何一個人僅僅使用一個GPU進行訓練和測試就可以得到實時的,高精度的以及令人信服的目標檢測結果,正如在圖片1中所示的YOLOv4的結果。我們的貢獻總結如下:
(1)我們提出了一個高效且強大的目標檢測模型。任何人可以使用一個1080Ti或者2080Ti的GPU就可以訓練出一個快速并且高精度的目標檢測器。
(2)我們在檢測器訓練的過程中,測試了目標檢測中最高水準的Bag-of-Freebies和Bat-of-Specials方法。
(3)我們改進了最高水準的算法,使得它們更加高效并且適合于在一個GPU上進行訓練,比如CBN[89]、PAN[49]、SAM[85]等。
2 相關工作(Related work)
2.1 目標檢測模型(Object detection models)
檢測器通常由兩部分組成:backbone和head。前者在 ImageNet 上進行預訓練,后者用來預測類別信息和目標物體的邊界框。在GPU平臺上運行的檢測器,它們的backbone可能是VGG [68],ResNet [26],ResNeXt [86]或DenseNet [30]。在CPU平臺上運行的檢測器,它們的backbone可能是[31],MobileNet [28、66、27、74]或ShuffleNet [97、53]。對于head部分,通常分為兩類:one-stage和two-stage的目標檢測器。Two-stage的目標檢測器的代表是R-CNN [19]系列,包括:faster R-CNN [64],R-FCN [9]和Libra R-CNN [ 58]. 還有基于anchor-free的Two-stage的目標檢測器,比如RepPoints[87]。One-stage目標檢測器的代表模型是YOLO [61、62、63],SSD [50]和RetinaNet [45]。在最近幾年,出現了基于anchor-free的one-stage的算法,比如CenterNet [13],CornerNet [37、38],FCOS [78]等等。在最近幾年,目標檢測器在backbone和head之間會插入一些網絡層,這些網絡層通常用來收集不同的特征圖。我們將其稱之為目標檢測器的neck。通常,一個neck由多個bottom-up路徑和top-down路徑組成。使用這種機制的網絡包括Feature Pyramid Network(FPN,特征金字塔網絡)[44],Path Aggregation Network(PAN,路徑聚集網絡)[49],BiFPN[77]和NAS-FPN[17]。
除了上面的這些模型,一些學者將重點放在為目標檢測器構建新的backbone(DetNet [43],DetNAS [7])或者是一整個新的模型(SpineNet [12],HitDe-tector [20])。
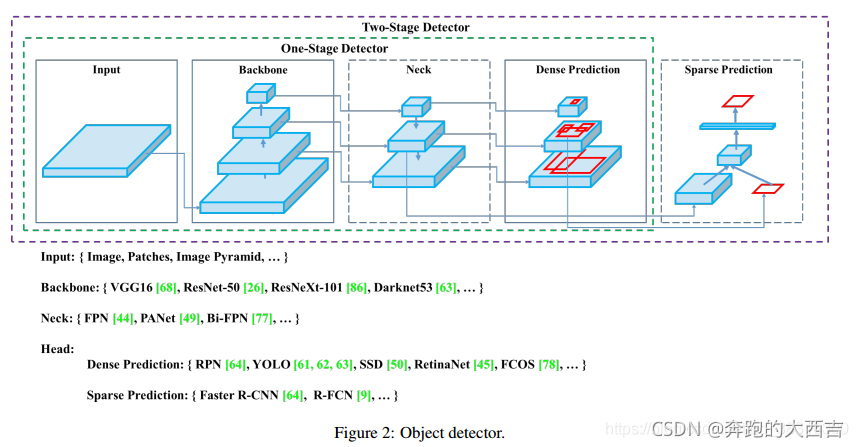
綜上所述,一個普通的目標檢測器由下面四個部分組成:
-
輸入:圖像,斑塊,圖像金字塔
-
骨架:VGG16 [68],ResNet-50 [26],SpineNet [12],EfficientNet-B0 / B7 [75],CSPResNeXt50 [81],CSPDarknet53 [81]
-
頸部:
- 其他塊:SPP [25],ASPP [5],RFB [47],SAM [85]
- 路徑聚合塊:FPN [44],PAN [49],NAS-FPN [17] ],Fully-connected FPN,BiFPN [77],ASFF [48],SFAM [98]
-
Heads :
-
Dense Prediction (密集預測)(一階段):
- RPN[64],SSD [50],YOLO [61], RetinaNet [45](基于錨)
- CornerNet[37],CenterNet [13],MatrixNet [60],FCOS [78](無錨)
-
Sparse Prediction (稀疏預測)(兩階段):
- Faster R-CNN [64],R-FCN [9],Mask R-CNN [23](基于錨)
- RepPoints[87](無錨)
-
2.2 Bag of freebies
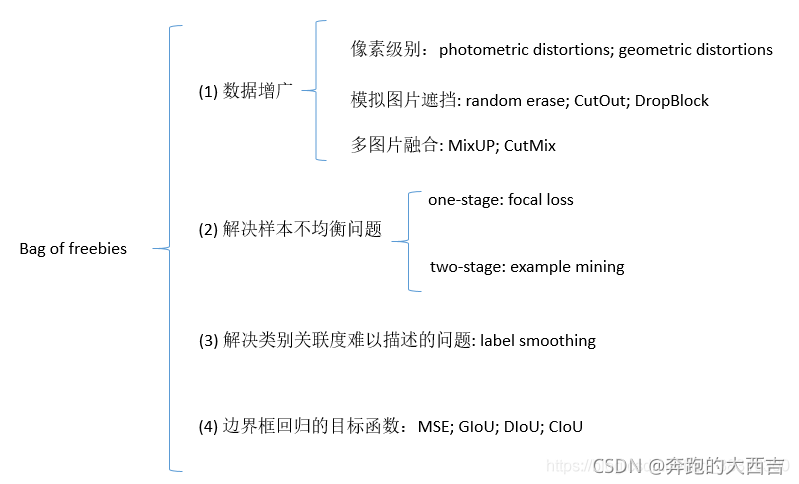
通常來說,目標檢測器都是進行離線訓練的(訓練的時候對GPU數量和規格不限制)。因此,研究者總是喜歡揚長避短,使用最好的訓練手段,因此可以在不增加推理成本的情況下,獲得最好的檢測精度。我們將只改變訓練策略或者只增加訓練成本的方法稱之為"bag of freebies"。在目標檢測中經常使用并且滿足bag of freebies的定義的算法稱是①數據增廣。數據增廣的目的是增加輸入圖片的可變性,因此目標檢測模型對從不同場景下獲取的圖片有著更高的魯棒性。舉例來說,photometric distoitions(光度失真)和geometric distortions(幾何失真)是用來數據增強方法的兩個常用的手段。在處理photometric distortion中,我們會調整圖像的亮度,對比度,色調,飽和度以及噪聲。對于geometric distortion,我們會隨機增加尺度變化,裁剪,翻轉以及旋轉。
上面提及的數據增廣的手段都是像素級別的調整,它保留了調整區域的所有原始像素信息。此外,一些研究者將數據增廣的重點放在了②模擬目標物體遮擋問題上。他們在圖像分類和目標檢測上已經取得了不錯的結果。具體來說,random erase[100]和CutOut [11]可以隨機選擇圖像上的矩形區域,然后進行隨機融合或者使用零像素值來進行融合。對于hide-and-seek[69]和grid mask[6],他們隨機地或者均勻地在一幅圖像中選擇多個矩形區域,并且使用零來代替矩形區域中的像素值。如果將相似的概念用來特征圖中,出現了DropOut [71],DropConnect [80]和DropBlock [16]方法。此外,一些研究者提出一起使用多張圖像進行數據增強的方法。舉例來說,MixUp [92]使用兩張圖片進行相乘并且使用不同的系數比進行疊加,然后使用它們的疊加比來調整標簽。對于CutMix [91],它將裁剪的圖片覆蓋到其他圖片的矩形區域,然后根據混合區域的大小調整標簽。除了上面提及的方法,style transfer GAN[15]也用來數據增廣,CNN可以學習如何有效的減少紋理偏差。
一些和上面所提及的不同的方法用來解決數據集中的語義分布可能存在偏差的問題。處理語義分布偏差的問題,一個非常重要的問題就是在不同類別之間存在數據不平衡,并且這個問題在two-stage目標檢測器中,通常使用hard negative example mining[72]或者online hard example mining[67]來解決。但是example mining 方法并不適用于one-stage的目標檢測器,因為這種類型的檢測器屬于dense prediction架構。因此focal loss[45] 算法用來解決不同類別之間數據不均衡的問題。③另外一個非常重要的問題就是使用one-hot很難描述不同類別之間關聯度的關系。Label smothing[73]提出在訓練的時候,將hard label轉換成soft label,這個方法可以使得模型更加的魯棒性。為了得到一個最好的soft label, Islam[33]引入了知識蒸餾的概念來設計標簽細化網絡。
最后一個bag of freebies是④設計邊界框回歸的目標函數。傳統的目標檢測器通常使用均方根誤差(MSE)在Bbox的中心坐標以及寬高上進行直接的回歸預測,即 {xcenter,ycenter,w,h}\{x_{center},y_{center},w,h\}{xcenter?,ycenter?,w,h} ,或者左上角和右下角的兩個點,即 {xtop_left,ytop_left,xbottom_right,ybottom_right}\{x_{top\_left},y_{top\_left},x_{bottom\_right},y_{bottom\_right}\}{xtop_left?,ytop_left?,xbottom_right?,ybottom_right?} 進行回歸。對于anchor-based方法,去預測相應的offset,比如 {xcenter_Offset,ycenter_Offset,wOffset,hoffset}\{x_{center\_Offset},y_{center\_Offset},w_{Offset},h_{offset}\}{xcenter_Offset?,ycenter_Offset?,wOffset?,hoffset?} 和 {xtop_left_offset,ytop_left_offset,xbottom_right_offset,ybottom_right_offset}\{x_{top\_left\_offset},y_{top\_left\_offset},x_{bottom\_right\_offset},y_{bottom\_right\_offset}\}{xtop_left_offset?,ytop_left_offset?,xbottom_right_offset?,ybottom_right_offset?} 。但是,預測Bbox每個點的坐標值是將這些點作為獨立的變量,但是實際上并沒有將目標物體當成一個整體進行預測。為了更好的解決這個問題,一些研究者最近提出了IoU loss[[90],它能夠將Bbox區域和ground truth的BBox區域的作為整體進行考慮。IoU損失函數需要計算BBox四個坐標點以及ground truth的IoU。因為IoU具有尺度不變性,它可以解決傳統算法比如 l1,l2l_1,l_2l1?,l2? 范數計算{x,y,w,h}\{x,y,w,h\}{x,y,w,h} 存在的問題,這個損失函數會隨著尺度的變化而發生變化。最近,一些研究者繼續提高IoU損失函數的性能。舉例來說,除了覆蓋范圍,GIoU[65]還包括目標物體的形狀和坐標。他們提出尋找同時包括預測的BBox和ground truth的BBox的封閉區域BBox,然后使用這個BBox作為分母去代替原來Iou損失函數中的分母。DIoU loss[99]額外考慮了目標物體的中心距離,CIoU [99]另一方面同時將覆蓋區域,中心點距離和縱橫比考慮在內。CIoU在BBox回歸問題上可以獲得最好的收斂速度和準確率。
2.3 Bag of specials
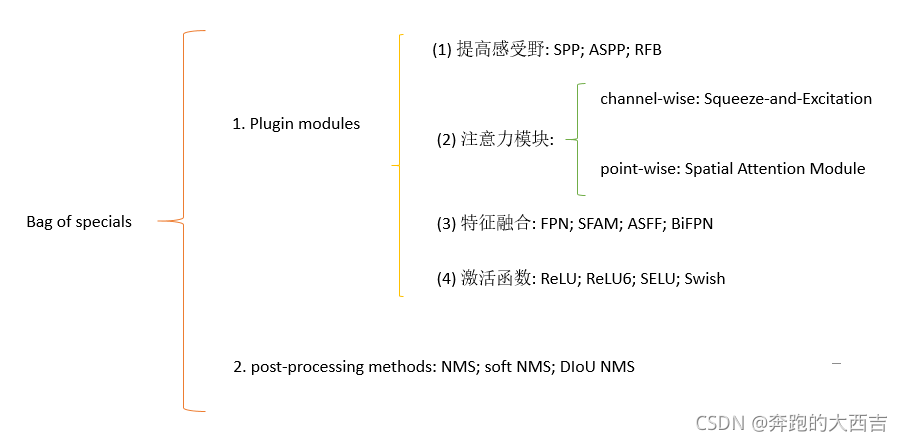
對于那些插件模塊和后處理方法,它們僅僅稍微的增加了推理成本,但是可以極大地提高目標檢測的準確度,我們將其稱之為“bag of specials”。一般來說,這些插件模塊用來提高一個模型中特定的屬性,比如增加感受野,引入注意力機制或者提高特征整合的能力等等;后處理方法是用來抑制模型預測結果的一種方法。
可以用來提升感受野的常規的方法是SPP [25],ASPP [5]和RFB [47]。SPP模型來源于空間金字塔匹配(SPM)[39],而且SPMs原始的方法將特征圖劃分成很多d*d個相等的塊,其中d可以是{1,2,3,…},因此可以形成空間金字塔,然后提取bag-of-word的特征。SPP將SPM應用在CNN中,然后使用max-pooling代替bag-of-word運算。因為SPP輸出的是一維的特征向量,因此它不能應用在全卷積網絡(FCN)中。在YOLOv3中,Redmon和Farhadi改進了SPP模塊,將max-pooling輸出和內核尺寸k*k連接起來,其中k={1,5,8,13},stride=1。基于這個設計,一個相對較大的k*k的max-pooling有效地提高了backbone特征的感受野。在添加了改進后的SPP模型之后,YOLO-v3-608在COCO數據集上,雖然增加了0.5%的額外計算量,但是提高了2.7%的AP50。ASPP模塊和改進的SPP模塊的區別主要在:原始的k*k過濾器尺寸,從stride=1到3*3內核尺寸的max-pooling,在stride=1的碰撞卷積運算中膨脹比為k。RFB模塊使用一些k*k的內核,膨脹比為k,步長為1的碰撞卷積,它比ASPP獲得了更全面的空間覆蓋率。RFB在MS COCO數據集上僅僅增加了7%的額外推理時間,但是得到了5.7%的AP50提升。
目標檢測上經常使用的注意力模塊主要分成channel-wise注意力模塊和point-wise注意力模塊,這兩個注意力模塊主要的代表分別是Squeeze-and-Excitation(SE)[29]和Spatial Attention Module(SAM)[85]。盡管SE模塊在ImageNet圖像分類工作上僅僅增加了2%的計算量而提高了1%的top-1準確率,但是在GPU上提高了10%的推理時間,因此SE模塊更適合在移動設備上使用。但是對于SAM模塊來說,在ImageNet圖像分類任務中,它僅僅需要0.1%的額外計算量卻能夠提升ResNet-SE 0.5%的top-1準確率。它在GPU上并沒有有效地影響推理速度。
關于特征融合,早期的是使用skip connection[51]或者是hyper-column[22]將低級的特征和高級的語義特征進行融合。因為多尺度預測方法比如FPN逐漸受到追捧,因此提出了很多將不同特征金字塔融合的輕量級模型。這類別的模型包括SfAM[98]、ASFF[48]和BiFPN[77]。SFAM的主要思想是在多尺度連接特征圖上使用channel-wise級別的調整。對于ASFF,它使用softmax作為point-wise級別的調整,然后將不同尺度的特征圖加在一起。在BiFPN中,提出使用多輸入權重殘差連接去執行scale-wise級別的調整,然后將不同尺度的特征圖加在一起。
在深度學習的研究中,一些人重點關心去尋找一個優秀的激活函數。一個優秀的激活函數可以讓梯度更有效的進行傳播,與此同時它不會增加額外的計算量。在2010年,Nair和Hinton[56]提出了ReLU激活函數充分地解決了梯度消失的問題,這個問題在傳統的tanh和sigmoid激活函數中會經常遇到。隨后,LReLU [54],PReLU [24],ReLU6 [28],比例指數線性單位(SELU)[35],Swish [59],hard-Swish [27]和Mish [55]等等相繼提出,它們也用來解決梯度消失的問題。LReLU和PReLU主要用來解決當輸出小于零的時候,ReLU的梯度為零的問題。ReLU6和hard-Swish主要為量化網絡而設計。對于神經網絡的自歸一化,提出SELU激活函數去實現這個目的。需要注意的是Swish和Mish都是連續可導的激活函數。
在基于深度學習的目標檢測中使用的后處理方法是NMS,它可以用來過濾那些預測統一物體、但是效果不好的BBoxes,然后僅僅保留較好的BBoxes。優化NMS和優化目標方程的方法異曲同工。NMS提出的最初的方法并沒有將上下文信息考慮在內,因此Girshick[19]在R-CNN中添加了分類置信度作為參考,然后根據置信度得分的順序,由高到低執行greedy NMS。對于soft NMS來說,它考慮了這樣一個問題:在greedy NMS使用IoU的時候,目標遮擋可能會造成置信度得分的退化。在soft NMS基礎上,DIoU NMS將重心坐標的距離信息添加到Bbox的篩選處理中了。值得一提的是,上面提到的后處理方法中都不直接引用捕獲的圖像特征,后續的anchor-free方法開發中不再需要后處理。
3 方法
我們工作基本的目標就是在生產系統和優化并行預算中加快神經網絡的速度,而非降低計算量理論指標(BFLOP)。我們提供了兩個實時神經網絡的選擇:
- GPU 在卷積層中,我們使用少量的組(1-8): CSPResNeXt50 / CSPDarknet53
- VPU 我們使用分組卷積,但是我們不使用Squeeze-and-excitement(SE)模塊,具體包括以下模型:EfficientNet-lite / MixNet / GhostNet / MobileNetV3
3.1 網絡架構的選擇
我們的目標是尋找 輸入網絡的分辨率、卷積層的個數、參數的數量 (filter_size2?filters?channel/groups)(filter\_size^2*filters*channel/groups)(filter_size2?filters?channel/groups)以及輸出層的個數(filters)之間的最優的平衡。舉例來說,大量的研究表明:在ILSVRC2012(ImageNet)的目標檢測上,CSPResNext50比CSPDarket53的效果更好,但是在MS COCO的目標檢測中,兩個的效果恰好相反。
下一個目標就是選擇額外的模塊去增加感受野以及為不同檢測器不同的backbone選擇參數聚合的最佳方法。比如:FPN, PAN, ASFF, BiFPN。
在分類任務上最優的模型在檢測上未必就是最優的。和分類任務相比,檢測器需要以下要求:
- 更好的輸入尺寸(分辨率)- 為了檢測多個小物體
- 更多網路層 - 為了獲得更大的感受野去覆蓋不斷增大的輸入尺寸
- 更多的參數 - 提高模型的能力從而能夠在一張圖片上檢測到不同尺寸的多個物體。
假設來說,我們可以認為具有更大感受野(有大量的3*3的卷積層)和具有大量參數的模型應當作為檢測器的backbone。表格1展示了CSPResNetXt50, CSPDarkent53以及EfficientNet B3的相關信息。CSPResNetXt50僅僅只有16個3*3的卷積層,一個425*425的感受野和20.6M個參數,然而CSPDarkent53有29個3*3的卷積層,725*725的感受野和27.6M個參數。從理論證明和大量的實驗表明在這兩個模型中,CSPDarkent53是作為檢測器的backbone最優的選擇。

不同尺寸的感受野的影響總結如下:
- 等于目標物體的大小時:能夠看到整個物體
- 等于網絡的尺寸:能夠看到目標物體周圍的上下文信息
- 大于網絡的尺寸:增加圖像點和最終激活之間連接的數量
我們將SPP模塊添加到CSPDarknet53中,因為它極大提高了感受野,能夠分離出最重要的上下文特征而且沒有降低網絡運行的速度。我們使用PANet作為不同檢測器不同backbone訓練階段聚集參數的方法,而非YOLOv3的FPN模塊。
最后,我們選擇CSPDarknet53作為backbone, SPP作為附加的模塊,PANet 作為neck,使用YOLOv3作為YOLOv4架構的head。
未來,我們計劃擴展檢測器的Bag of freebies,它們在理論上可以解決某些問題并且能夠提高檢測器的精度,后續會以實驗的形式探究每個算法對檢測器的影響。
我們沒有使用Cross-GPU Batch Normalization(CGBN 或者 SyncBN) 或者昂貴的定制設備。這能夠使得任何人在一個GPU上就可以得到最先進的結果,比如在GTX 1080Ti或者RTX 2080Ti。
3.2 BoF 和 BoS的選擇
為了提高目標檢測的訓練,CNN通常使用下面一些技巧:
- 激活:ReLU,leaky-ReLU,parameter-ReLU,ReLU6,SELU,Swish或Mish
- 邊界框回歸損失:MSE,IoU,GIoU,CIoU,DIoU
- 數據增強:CutOut,MixUp,CutMix
- 正則化方法:DropOut, DropPath [36],Spatial DropOut [79]或DropBlock
- 通過均值和方差對網絡激活進行歸一化:Batch Normalization (BN) [32],Cross-GPU Batch Normalization (CGBN or SyncBN)[93], Filter Response Normalization (FRN) [70], orCross-Iteration Batch Normalization (CBN) [89]
- 跨連接:Residual connections, Weightedresidual connections, Multi-input weighted residualconnections, or Cross stage partial connections (CSP)
對于訓練激活函數,因為PReLU和SELU難以訓練,并且RELU6是專門為量化網絡設計的,我們因此不考慮這這三個激活函數。在正則化方法中,提出DropBlok的學者將其算法和其他算法進行了比較,然后DropBolck效果更好。因此我們毫不猶豫的選擇DropBlock作為我們的正則化方法。在歸一化方法的選擇中,因為我們關注在一塊GPU上的訓練策略,因此我們不考慮syncBN。
3.3 額外的改進
為了讓檢測器更適合在單個GPU上進行訓練,我們做了以下額外的設計和改進:
-
我們提出了數據增廣的新的方法:Mosaic和Self-Adversarial Training(SAT)
-
在應用遺傳算法去選擇最優的超參數
-
我們改進了一些現有的算法,讓我們的設計更適合高效的訓練和檢測 - 改進SAM, 改進PAN以及Cross mini-Batch Normalization(CmBN)

Mosaic是一種新型的數據增廣的算法,它混合了四張訓練圖片。因此有四種不同的上下文進行融合,然而CutMix僅僅將兩張圖片進行融合。此外,batch normalization在每個網絡層中計算四張不同圖片的激活統計。這極大減少了一個大的mini-batch尺寸的需求。
自適應對抗訓練(SAT)也表示了一個新的數據增廣的技巧,它在前后兩階段上進行操作。在第一階段,神經網絡代替原始的圖片而非網絡的權重。用這種方式,神經網絡自己進行對抗訓練,代替原始的圖片去創建圖片中此處沒有期望物體的描述。在第二階段,神經網絡使用常規的方法進行訓練,在修改之后的圖片上進檢測物體。
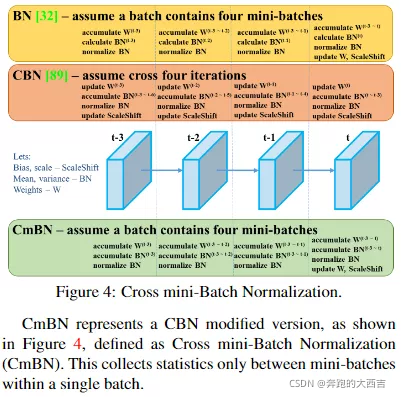
正如圖4中顯示,CmBN(Cross mini-Batch Normalization)代表CBN改進的版本。它只收集了一個批次中的mini-batches之間的統計數據。
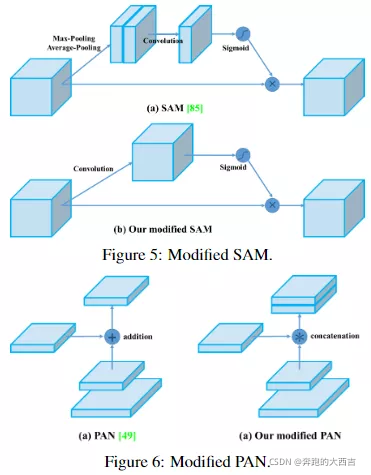
我們將SAM的spatial-wise注意力變成了point-wise注意力機制,然后將PAN中的shortcut連接變成了concatenation連接,正如圖5和圖6所表示的那樣。
3.4 YOLOv4
在這個部分,我們會詳細介紹YOLOv4的細節:
網絡組成 | Backbone | Neck | Head |
采用模塊 | CSPDarknet53 | SPP, PAN | YOLOv3 |
BoF | CutMix and Mosaic data augmentation DropBlock regularization Class label smoothing | ? | CIoU-loss CmBN DropBlock regularization Mosaic data augmentation Self-Adversarial Training Eliminate grid sensitivity Using multiple anchors for a single ground truth Cosine annealing scheduler Optimal hyperparameters Random training shapes |
BoS | Mish activation Cross-stage partial connections(CSP) Multi-input weighted residual connections (MiWRC) | ? | Mish activation SPP-block SAM-block PAN path-aggregation block DIoU-NMS |
模塊作用 | 在ImageNet上進行預訓練 | 融合不同位置上的特征圖 | 進行預測 |
4 實驗
我們測試了不同訓練提升技巧在ImageNet(ILSVRC2012 val)數據集上的精度影響,然后又驗證了檢測器在MS COCO(test-val 2017)數據集的準確率。
4.1 實驗參數配置
在ImageNet圖像分類實驗中,默認的超參數如下:訓練步長為8,000,000;batch size和mini-batch size分別為128和32;polynominal decay learning rate scheduling strategy初始的學習率為0.1;warm-up步長為1000;momentum和weight decay分別設置為0.9和0.005。所有的BoS實驗使用相同的、默認的超參數,在BoF實驗中,我們增加了一半的訓練步長。在BoF實驗中,我們驗證了MixUp, CutMix, Mosaic, Bluring數據增加一節label smoothing regularization方法。在BoS實驗中,我們比較了LReLU,Swish和Mish激活函數的影響。所有的實驗都在1080Ti或者2080Ti GPU上進行訓練。
在MS COCO目標檢測實驗中,默認的超參數如下:訓練步長為500,500;the step decay learning rate scheduling strategy初始化學習率為0.01在步長為400,000和450,000的時候乘以0.1;momentum和weight decay分別設置為0.9和0.0005。所有的架構在一塊GPU進行多尺度訓練,它的batch size為64,然而它的mini-batch為8還是4取決于網絡架構和GPU的內存限制。除了對尋找最優的超參數使用遺傳算法之外,其他所有的實驗都使用默認的設置。遺傳算法和GIoU使用YOLOv3-SPP進行訓練,并且為5k個min-val進行300個epochs。對我們采用搜索的學習率為0.00261,momentum為0.949,IoU閾值為設置為0.213,遺傳算法實驗的損失標準化為0.07。我們還驗證了大量的BoF算法,包括grid sensitivity elimination, mosaic數據增廣,IoU閾值化,遺傳算法,class label smoothing, cross mini-batch normalization,self-adversarial training,cosine anneling scheduler, dynamic mini-batch size, DropBlock, Optimized Anchors, 不同的IoU損失函數。我們也在不同BoS算法上進行了實驗,包括Mish,SPP,SAM,RFB,BiFBN以及Gaussiian YOLO。所有的實驗我們僅僅使用一個GPU進行訓練,因此比如syncBN的優化多個GPU的技巧我們并沒有使用。
4.2 不同算法在分類器訓練上的影響
首先,我們研究了不同算法在分類器訓練上的影響;具體來說,Class label smoothing(類標簽平滑)的影響,不同數據增廣技巧,bilateral blurring(雙邊模糊),MixUp, CutMix和Mosaic(馬賽克)的印象在圖7中顯示,以及不同激活函數的影響,比如Leaky-ReLU(默認的),Swish和Mish。

在表2中所示,在我們的實驗中,通過引入一些算法,分類器的準確率得到了提升,這些算法包括:CutMix和Mosaic數據增廣,Class label smoothing和Mish激活函數。結果,我們的用于分類器訓練的BoF-backbone(Bag of Freebies)包括:Cutmix 和Mosaic數據增廣算法以及Class labelsmoothing。正如表2和表3所示,我們將Mish激活函數作為補充的選項。

4.3 不同算法在檢測器訓練上的影響
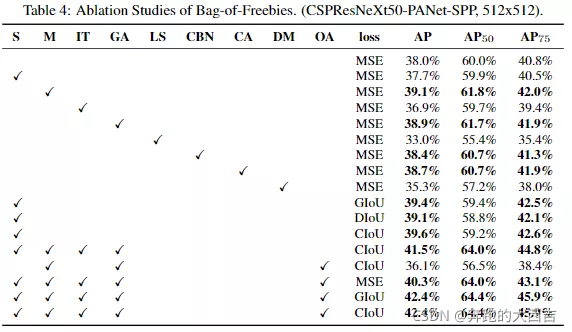
進一步的研究關注不同Bag-of-Freebies(BoF-detector)在檢測器訓練準確度的影響,正如表4所示。通過研究能夠提高檢測器準確度的算法,我們極大地擴展了BoF的算法選項,而且并沒有影響FPS:
- S:消除柵格的敏感度 這個方程在YOLOv3中用于評估目標物體的坐標,自重cx和cy通常是整數,因此,當bx的值非常接近cx或者cx+1的時候,tx的絕對值會非常大。我們通過給sigmoid函數乘以一個大于1的因子來解決這個問題,因此,這樣就消除了柵格對不可檢測物體的影響。
- M:Mosaic數據增廣 - 在訓練過程中,使用四張圖片而非一張進行增廣處理
- IT:IoU****閾值 - 為一個ground truth的IoU使用多個anchors,ground truth IoU(truth, anchor) > IoU 閾值
- GA:遺傳算法 - 在前10%的訓練時間內使用遺傳算法選擇最優的超參數
- LS:C****lass label smoothing - 為sigmoid激活函數使用class label smoothing。
- CBN:CmBN - 在整個批次中通過使用Cross mini-Batch Normalization收集統計數據,而非在單獨的mini-batch中收集統計數據。
- CA:Cosine annealing scheduler - 在sinusoid訓練中改變學習率
- DM:動態的mini-batch尺寸 - 在低分辨率的訓練過程中,通過隨機訓練形狀自動的改提高mini-batch的尺寸。
- OA: 優化Anchors - 使用優化的anchors進行訓練,網絡的分辨率為512*512
- GIoU, CIoU, DIoU, MSE - 為邊界框回歸使用不同的損失函數。
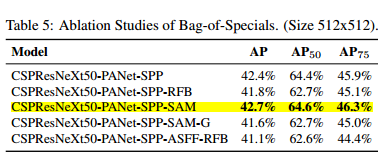
下一步的研究關心在檢測器訓練準確度上,不同Bag-of-Specials(BoS-detector)的影響,包括PAN, RFB, SAM, Gaussian YOLO(G),以及ASFF,正如表5所示。在我們的實驗中,當使用SPP, PAN和SAM的時候,檢測器得到了最好的性能。
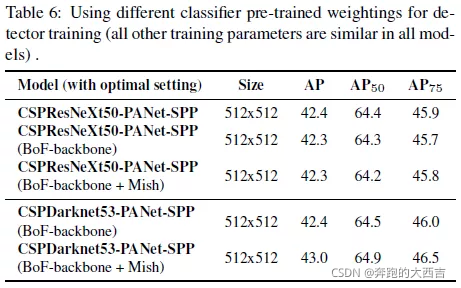
4.4 不同backbones和預訓練權重在檢測器訓練中的影響
下一步我們研究不同backbones模型在檢測器準確率上的影響,正如表6所示。我們注意到擁有最佳分類準確率的模型,檢測器的準確度未必是最佳的。
首先,盡管使用不同算法訓練得到的CSPResNeXt-50模型的分類精度比CSPDarknet53模型的要高,但是CSPDarknet53模型的檢測精度更高。
再者,CSPResNeXt-50分類器訓練使用BoF和Mish提高了它的分類準確率,但是檢測器訓練使用的預訓練權重的進一步使用減少了檢測器的精度。但是,CSPDarknet53分類器訓練使用BoF和Mish提高了分類器和檢測器的準確率,它使用分類器預訓練權重。這表示CSPDarknet53比CSPResNeXt-50更適合作為檢測器。
我們觀察到,由于各種改進,CSPDarknet53模型顯示出了更大的提高的檢測器精度的能力。
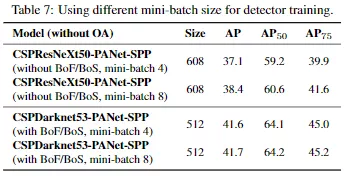
4.5 不同mini-batch尺寸在檢測器訓練上的影響
最后,我們分析了不同mini-batch尺寸的訓練的模型的結果,并且結果在表7中顯示出來。從表7中我們發現在添加了BoF和BoS訓練策略之后,mini-batch尺寸幾乎對檢測器的性能沒有影響。結果顯示在引入了BoF和BoS之后,就不需要使用昂貴的GPUs進行訓練。換句話說,任何人可以僅僅使用一個GPU去訓練一個優秀的檢測器。
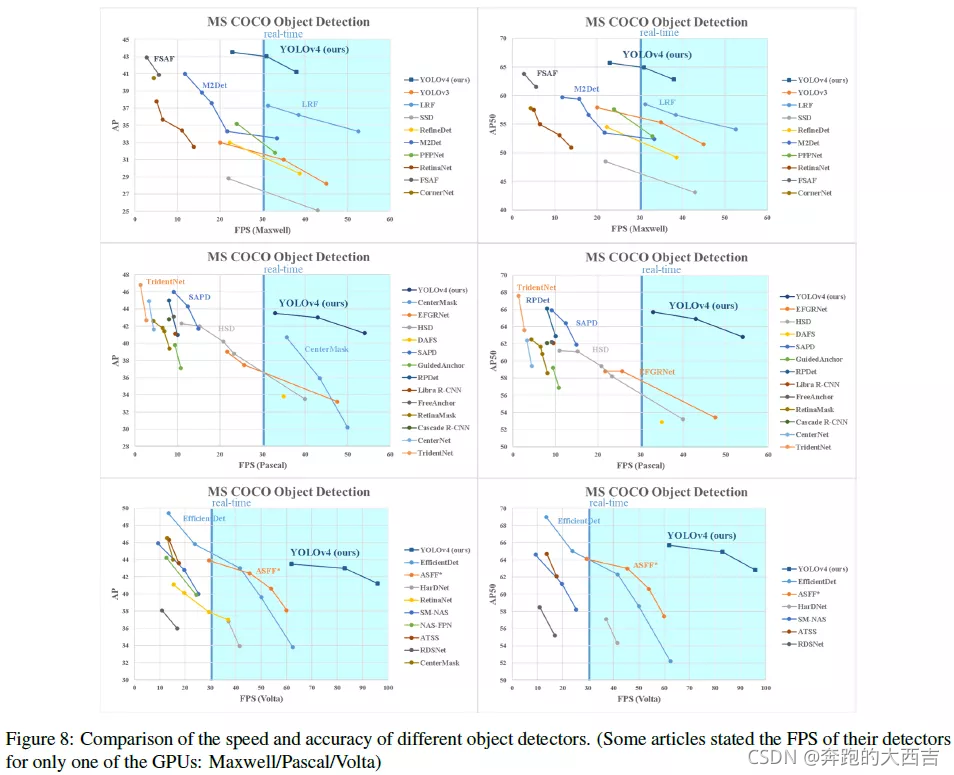
5 結果
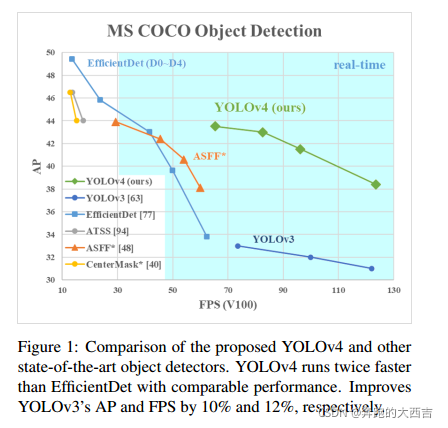
使用最先進的目標檢測器得到的對比結果在圖8中顯示(具體請看原文)。我們的YOLOv4坐落在帕累托最優曲線上,而且在精度和速度上都優于目前最快的和最準確的檢測器。
6 結論
我們提出了一個最先進的目標檢測器,它比所有檢測器都要快而且更準確。這個檢測器可以僅在一塊8-16GB的GPU上進行訓練,這使得它可以廣泛的使用。One-stage的anchor-based的檢測器的原始概念證明是可行的。我們已經驗證了大量的特征,并且其用于提高分類器和檢測器的精度。這些算法可以作為未來研究和發展的最佳實踐。
![[Android] 年年有魚手機主題](http://pic.xiahunao.cn/[Android] 年年有魚手機主題)







![[ASP.NET AJAX]類似.NET框架的JavaScript擴展](http://pic.xiahunao.cn/[ASP.NET AJAX]類似.NET框架的JavaScript擴展)

)



和mysql_fetch_rows()函數_mysql)



,你要什么我就給你什么)
