- 論文名:《YOLOv3: An Incremental Improvement》
- 論文地址
- https://pjreddie.com/media/files/papers/YOLOv3.pdf
- https://arxiv.org/abs/1804.02767v1
- 論文代碼
- https://github.com/yjh0410/yolov2-yolov3_PyTorch
- keras:https://github.com/qqwweee/keras-yolo3
YOLOv3沒有太多的創新,主要是借鑒一些好的方案融合到YOLO里面。不過效果還是不錯的,在保持速度優勢的前提下,提升了預測精度,尤其是加強了對小物體的識別能力。
YOLO3主要的改進有:
- 利用多尺度特征進行對象檢測(類FPN)
- 更好的基礎分類網絡(類ResNet)和分類器 darknet-53,見下圖。
- 分類器-類別預測:YOLOv3不使用Softmax對每個框進行分類,主要考慮因素有兩個:
- Softmax使得每個框分配一個類別(score最大的一個),而對于
Open Images這種數據集,目標可能有重疊的類別標簽,因此Softmax不適用于多標簽分類。 - Softmax可被獨立的多個logistic分類器替代,且準確率不會下降。 分類損失采用binary cross-entropy loss.
- Softmax使得每個框分配一個類別(score最大的一個),而對于
新的網絡結構Darknet-53
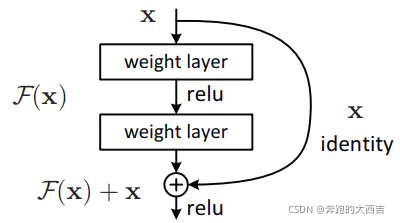
darknet-53借用了resnet的思想,在網絡中加入了殘差模塊,這樣有利于解決深層次網絡的梯度問題,每個殘差模塊由兩個卷積層和一個shortcut connections,
1,2,8,8,4代表有幾個重復的殘差模塊,整個v3結構里面,沒有池化層和全連接層,網絡的下采樣是通過設置卷積的stride為2來達到的,每當通過這個卷積層之后
圖像的尺寸就會減小到一半。而每個卷積層的實現又是包含 卷積+BN+Leaky relu,每個殘差模塊之后又要加上一個zero padding,論文中所給的網絡結構如下,由卷積模塊和殘差模塊組成;
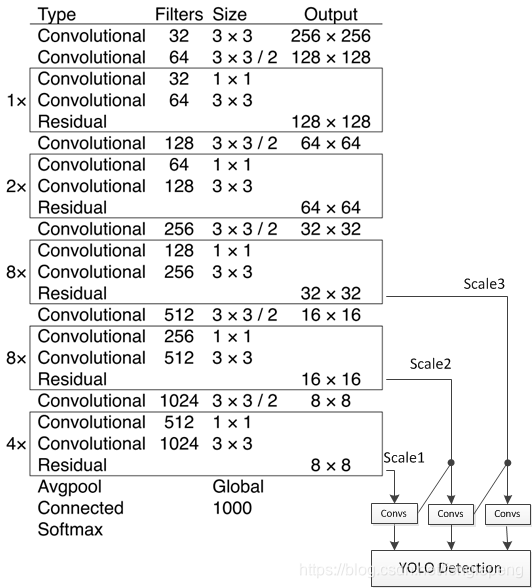
上圖的Darknet-53網絡采用 256?256?3256*256*3256?256?3 作為輸入,最左側那一列的1、2、8等數字表示多少個重復的殘差組件。每個殘差組件有兩個卷積層和一個快捷鏈路,示意圖如下:
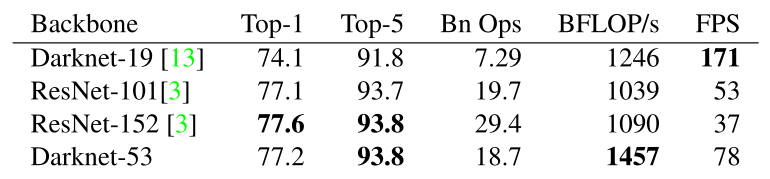
darknet-53仿ResNet, 與ResNet-101或ResNet-152準確率接近,但速度更快.對比如下:
與darknet-19對比可知,darknet-53主要做了如下改進:
- 沒有采用最大池化層,轉而采用步長為2的卷積層進行下采樣。
- 為了防止過擬合,在每個卷積層之后加入了一個BN層和一個Leaky ReLU。
- 引入了殘差網絡的思想,目的是為了讓網絡可以提取到更深層的特征,同時避免出現梯度消失或爆炸。
- 將網絡的中間層和后面某一層的上采樣進行張量拼接,達到多尺度特征融合的目的。
模型可視化
具體的全部模型結構可以從這個網站的工具進行可視化分析:
https://lutzroeder.github.io/netron/
從Yolo的官網上下載yolov3的權重文件,然后通過官網上的指導轉化為H5文件,然后可以再這個瀏覽器工具里直接看yolov3的每一層是如何分布的;類似下邊截圖是一部分網絡(最后的拼接部分);
利用多尺度特征進行對象檢測
對于多尺度檢測來說,采用多個尺度進行預測,具體形式是在網絡預測的最后某些層進行上采樣拼接的操作來達到;對于分辨率對預測的影響如下解釋:
分辨率信息直接反映的就是構成object的像素的數量。一個object,像素數量越多,它對object的細節表現就越豐富越具體,也就是說分辨率信息越豐富。這也就是為什么大尺度feature map提供的是分辨率信息了。語義信息在目標檢測中指的是讓object區分于背景的信息,即語義信息是讓你知道這個是object,其余是背景。在不同類別中語義信息并不需要很多細節信息,分辨率信息大,反而會降低語義信息,因此小尺度feature map在提供必要的分辨率信息下語義信息會提供的更好。(而對于小目標,小尺度feature map無法提供必要的分辨率信息,所以還需結合大尺度的feature map)
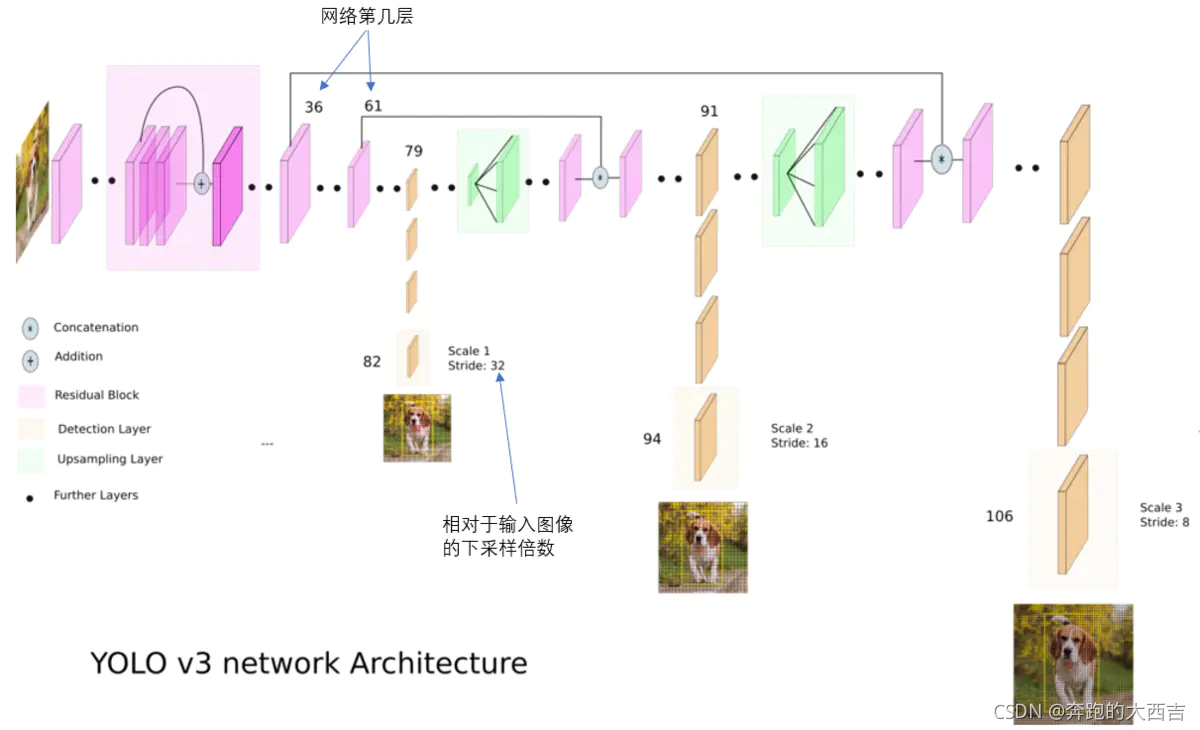
YOLO2曾采用passthrough結構來檢測細粒度特征,在YOLO3更進一步采用了3個不同尺度的特征圖來進行對象檢測。網絡的最終輸出有3個尺度分別為1/32,1/16,1/8;
結合上圖看,卷積網絡在79層后,經過下方幾個黃色的卷積層得到一種尺度的檢測結果。相比輸入圖像,這里用于檢測的特征圖有32倍的下采樣。比如輸入是 416?416416*416416?416 的話,這里的特征圖就是 13?1313*1313?13 了。由于下采樣倍數高,這里特征圖的感受野比較大,因此適合檢測圖像中尺寸比較大的對象。
為了實現細粒度的檢測,第79層的特征圖又開始作上采樣(從79層往右開始上采樣卷積),然后與第61層特征圖融合(Concatenation),這樣得到第91層較細粒度的特征圖,同樣經過幾個卷積層后得到相對輸入圖像16倍下采樣的特征圖。它具有中等尺度的感受野,適合檢測中等尺度的對象。
最后,第91層特征圖再次上采樣,并與第36層特征圖融合(Concatenation),最后得到相對輸入圖像8倍下采樣的特征圖。它的感受野最小,適合檢測小尺寸的對象。
concat:張量拼接。將darknet中間層和后面的某一層的上采樣進行拼接。拼接的操作和殘差層add的操作是不一樣的,拼接會擴充張量的維度,而add只是直接相加不會導致張量維度的改變。
9種尺度的先驗框
隨著輸出的特征圖的數量和尺度的變化,先驗框的尺寸也需要相應的調整。YOLO2已經開始采用K-means聚類得到先驗框的尺寸,YOLO3延續了這種方法,為每種下采樣尺度設定3種先驗框,總共聚類出9種尺寸的先驗框。在COCO數據集這9個先驗框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
分配上,在最小的 13?1313*1313?13 特征圖上(有最大的感受野)應用較大的先驗框(116x90),(156x198),(373x326),適合檢測較大的對象。中等的 26?2626*2626?26 特征圖上(中等感受野)應用中等的先驗框(30x61),(62x45),(59x119),適合檢測中等大小的對象。較大的52?5252*5252?52 特征圖上(較小的感受野)應用較小的先驗框(10x13),(16x30),(33x23),適合檢測較小的對象。

感受一下9種先驗框的尺寸,下圖中藍色框為聚類得到的先驗框。黃色框式ground truth,紅框是對象中心點所在的網格。

對象分類softmax改成logistic
預測對象類別時不使用softmax,改成使用logistic的輸出進行預測。這樣能夠支持多標簽對象(比如一個人有Woman 和 Person兩個標簽)。
輸入映射到輸出
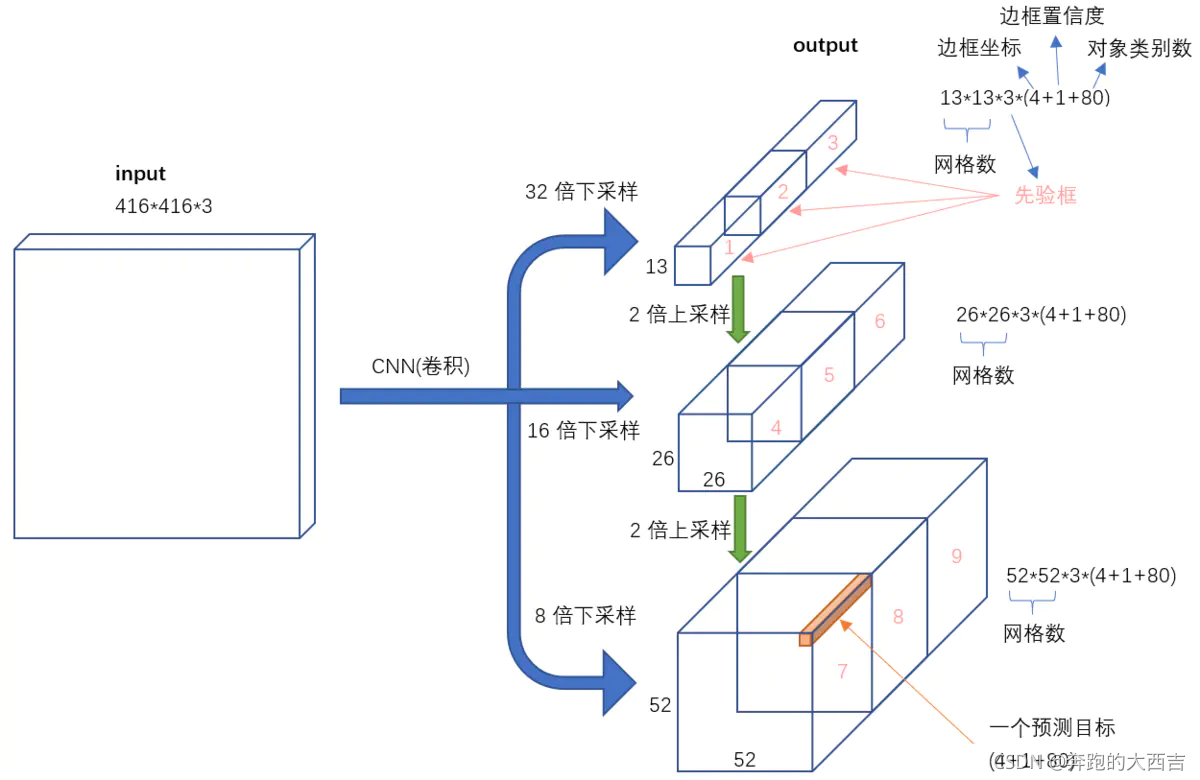
不考慮神經網絡結構細節的話,總的來說,對于一個輸入圖像,YOLO3將其映射到3個尺度的輸出張量,代表圖像各個位置存在各種對象的概率。
我們看一下YOLO3共進行了多少個預測。對于一個416*416的輸入圖像,在每個尺度的特征圖的每個網格設置3個先驗框,總共有 13*13*3 + 26*26*3 + 52*52*3 = 10647 個預測。每一個預測是一個(4+1+80)=85維向量,這個85維向量包含邊框坐標(4個數值),邊框置信度(1個數值),對象類別的概率(對于COCO數據集,有80種對象)。
對比一下,YOLO2采用13*13*5 = 845個預測,YOLO3的嘗試預測邊框數量增加了10多倍,而且是在不同分辨率上進行,所以mAP以及對小物體的檢測效果有一定的提升。
訓練過程
YoloV3 的訓練過程,特別是樣本的選擇和 V1 和 V2 已經完全不一樣了。
在 V1 和 V2 中是看 gd 中心所落的負責區域來確定 gd 由哪個點來負責。由于 V3 中有多個最終的 feature map。使用這種策略可能會導致矛盾(即一個 gd 同時屬于多個點負責)。所以需要新的方式確定樣本由哪個點的區域負責。原則很簡單:
所有預測的 pd 中和 gd 的 IOU 最大的那個就是正樣本。
作者還創新的把預測 pd 分成三類:
-
正例:產生回歸框 loss 和類別置信度 loss。
對任意的 gd,與所有的 pd 計算IOU,IOU 最大那個就是正例。一個pd,只能分配給一個gd。比如第一個 gd 已經匹配了一個正例的 pd,那么下一個 gd,需要在剩下的 pd 中尋找 IOU 最大的作為正例。
-
負例:只產生置信度 loss。
除正例以外(與 gd 計算后 IOU 最大的檢測框,但是IOU小于閾值,仍為正例),與全部 gd 的 IOU 都小于閾值(論文中為 0.5),則為負例。
-
忽略:不產生任何 loss。
除正例以外,與任意一個 gd 的 IOU 大于閾值(論文中為 0.5),則為忽略。
在 YoloV3 中置信域標簽直接設置為 1 和0。而不是 YoloV1 的 IOU 值。原因是假設 iou 是0.8,但學習到的可能只有 0.6 總是會低一些。不如直接將標簽設為 1 (學習到的可能就是 0.8)。
測試過程
由于有三個特征圖,所以需要對三個特征圖分別進行預測。
三個特征圖一共可以出預測 19 × 19 × 3 + 38 × 38 × 3 + 76 × 76 × 3 = 22743 個 pd 坐標以及對應的類別和置信度。
測試時,選取一個置信度閾值,過濾掉低閾值 box,經過 NMS(非極大值抑制),輸出整個網絡的預測結果。注意最后要還原到原始坐標。該改成測試模式的模塊需要改成測試模式(比如 BatchNorm)
小結
YOLO3借鑒了殘差網絡結構,形成更深的網絡層次,以及多尺度檢測,提升了mAP及小物體檢測效果。如果采用COCO mAP50做評估指標(不是太介意預測框的準確性的話),YOLO3的表現相當驚人,如下圖所示,在精確度相當的情況下,YOLOv3的速度是其它模型的3、4倍。
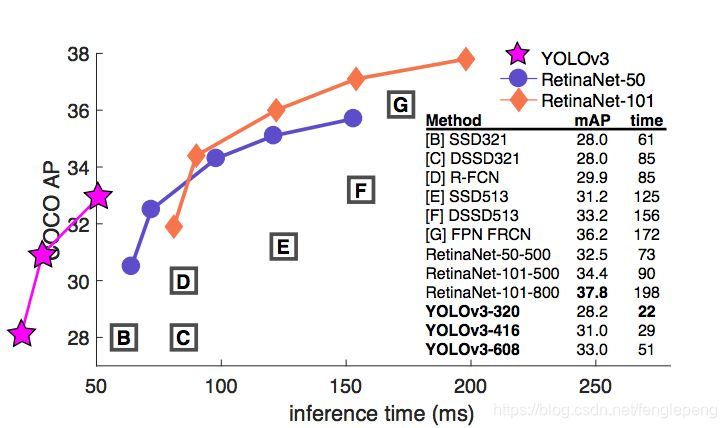
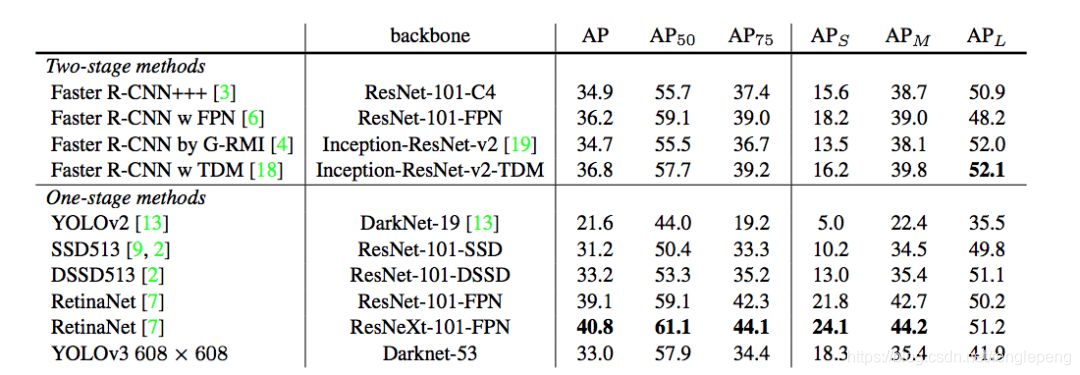
對不同的單階段和兩階段網絡進行了測試。通過對比發現,YOLOv3達到了與當前先進檢測器的同樣的水平。檢測精度最高的是單階段網絡RetinaNet,但是YOLOv3的推理速度比RetinaNet快得多。
YOLOv3在mAP@0.5及小目標APs上具有不錯的結果,但隨著IOU的增大,性能下降,說明YOLOv3不能很好地與ground truth切合.
參考:
- https://www.jianshu.com/p/d13ae1055302
- https://www.cnblogs.com/ywheunji/p/10809695.html
- https://zhuanlan.zhihu.com/p/362761373


)
為博客添加一個漂亮的分享按鈕)

![[Android] 年年有魚手機主題](http://pic.xiahunao.cn/[Android] 年年有魚手機主題)







![[ASP.NET AJAX]類似.NET框架的JavaScript擴展](http://pic.xiahunao.cn/[ASP.NET AJAX]類似.NET框架的JavaScript擴展)

)



和mysql_fetch_rows()函數_mysql)