Hadoop基礎-Hdfs各個組件的運行原理介紹
作者:尹正杰
版權聲明:原創作品,謝絕轉載!否則將追究法律責任。
?
?
?
一.NameNode工作原理(默認端口號:50070)
1>.什么是NameNode
NameNode管理文件系統的命名空間。它維護著文件系統樹及整棵樹內所有的文件和目錄。這些信息以兩個文件形式永久保存在本地磁盤上:命名空間鏡像文件和編輯日志文件。NameNode也記錄著每個文件中各個塊所在的數據節點信息,但它并不永久保存塊的位置信息,因為這些信息在系統啟動時由數據節點重建。
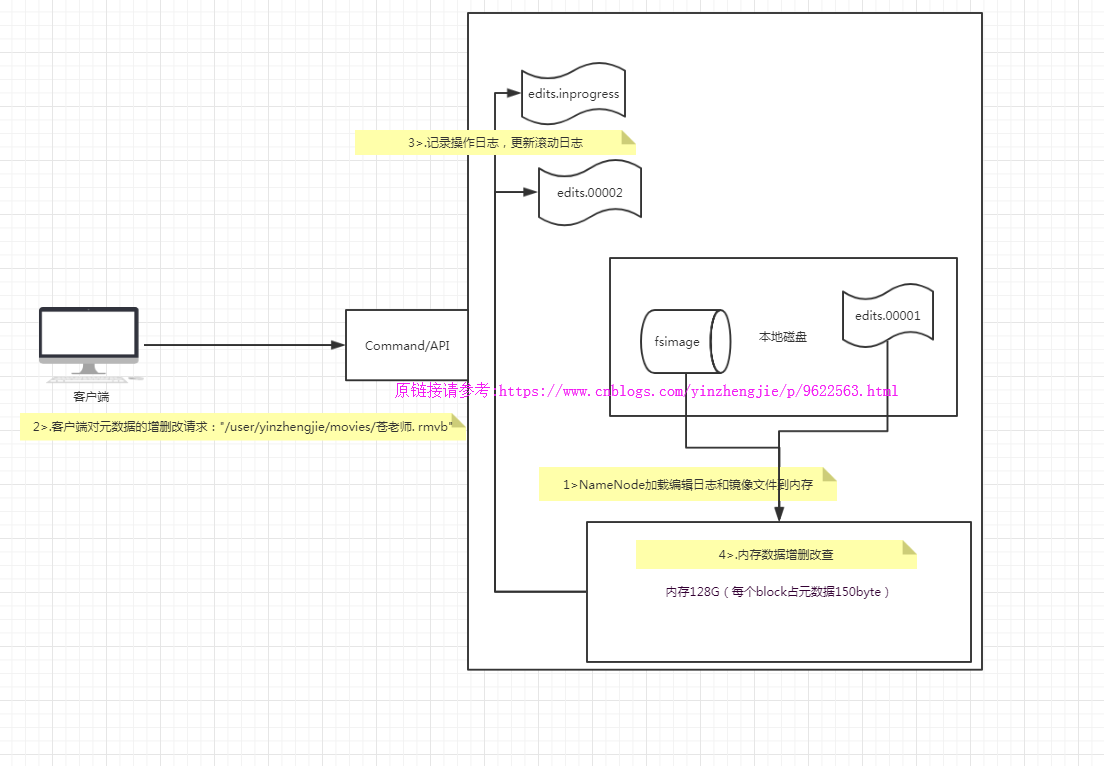
2>.Name啟動流程
?
?
NameNode職責:1>.負責客戶端請求的響應2>.元數據的管理(查詢,修改)NameNode對數據的管理采用了三種存儲形式:1>.內存元數據(NameSystem)2>.磁盤元數據鏡像文件3>.數據操作日志文件(可通過日志運算出元數據)元數據存儲機制:1>.內存中有一份完整的元數據(內存meta data)2>.磁盤有一個“準完整”的元數據鏡像(fsimage)文件(在namenode的工作目錄中)3>.用于銜接內存metadata和持久化元數據鏡像fsimage之間的操作日志(edits文件)NameNode啟動流程概述:1>.第一次啟動NameNode格式化后,創建fsimage和edits文件。如果不是第一次啟動,直接加載編輯日志和鏡像文件到內存。2>.客戶端對元數據進行增刪改的請求3>.NameNode記錄操作日志,更新滾動日志。4>.namenode在內存中對數據進行增刪改查在NameNode端的工作流程如下:1>.Namenode始終在內存中保存metedata,用于處理“讀請求” 到有“寫請求”到來時,namenode會首先寫edits到磁盤,即向edits文件中寫日志,當客戶端操作成功后,相應的元數據會更新到內存matedata中,并且向客戶端返回.2>.Hadoop會維護一個fsimage文件,也就是namenode中metedata的鏡像,但是fsimage不會隨時與namenode內存中的metedata保持一致,而是每隔一段時間通過合并edits文件來更新內容。查看namenode版本號1>.在/home/yinzhengjie/data/hadoop/hdfs/ha/dfs/name1/current這個目錄下查看VERSION文件,[yinzhengjie@s101 ~]$ cat /home/yinzhengjie/data/hadoop/hdfs/ha/dfs/name1/current/VERSION #Mon Aug 13 14:45:15 EDT 2018namespaceID=1555352651clusterID=CID-58730c19-c019-4f4c-97f1-0eb80eab6071cTime=0storageType=NAME_NODEblockpoolID=BP-1140132172-172.30.1.101-1534178655035layoutVersion=-63[yinzhengjie@s101 ~]$ 2>.namenode版本號具體解釋2.1>.namespaceID在HDFS上,會有多個Namenode,所以不同Namenode的namespaceID是不同的,分別管理一組blockpoolID。2.2>.clusterID集群id,全局唯一2.3>.cTime屬性標記了namenode存儲系統的創建時間,對于剛剛格式化的存儲系統,這個屬性為0;但是在文件系統升級之后,該值會更新到新的時間戳。2.4>.storageType屬性說明該存儲目錄包含的是namenode的數據結構。2.5>.blockpoolID:一個block pool id標識一個block pool,并且是跨集群的全局唯一。當一個新的Namespace被創建的時候(format過程的一部分)會創建并持久化一個唯一ID。在創建過程構建全局唯一的BlockPoolID比人為的配置更可靠一些。NN將BlockPoolID持久化到磁盤中,在后續的啟動過程中,會再次load并使用。2.6>.layoutVersion是一個負整數。通常只有HDFS增加新特性時才會更新這個版本號。namenode的本地目錄可以配置成多個,且每個目錄存放內容相同,增加了可靠性。具體配置如下:[hdfs-site.xml]<property><name>dfs.namenode.name.dir</name><value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value> <--注意,這個值咱們也可以寫絕對路徑,我測試過好使!--></property>
3>.NameNode注意事項
第一:如下圖所示,第一次啟動namenode格式化后,創建fsimage和edits文件
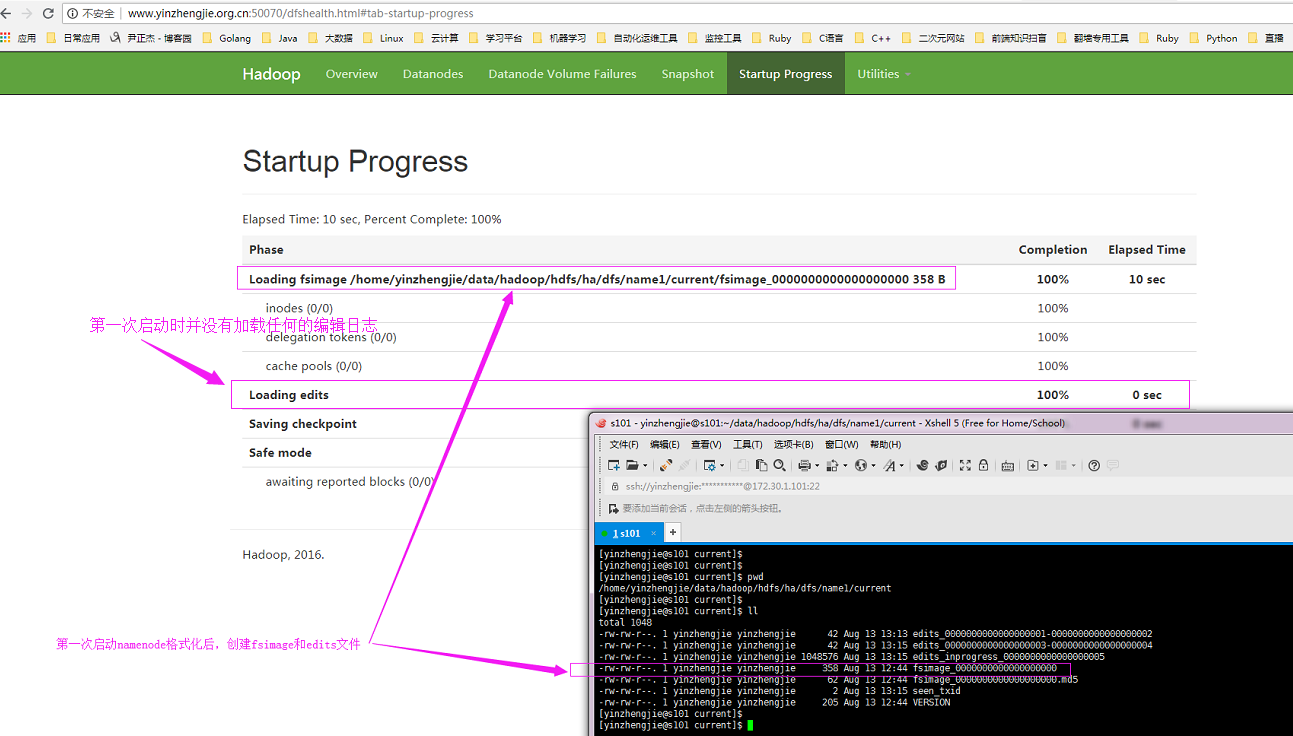
第二:重啟hdfs分布式文件系統時,默認會自動滾動編輯日志,如下圖所示:
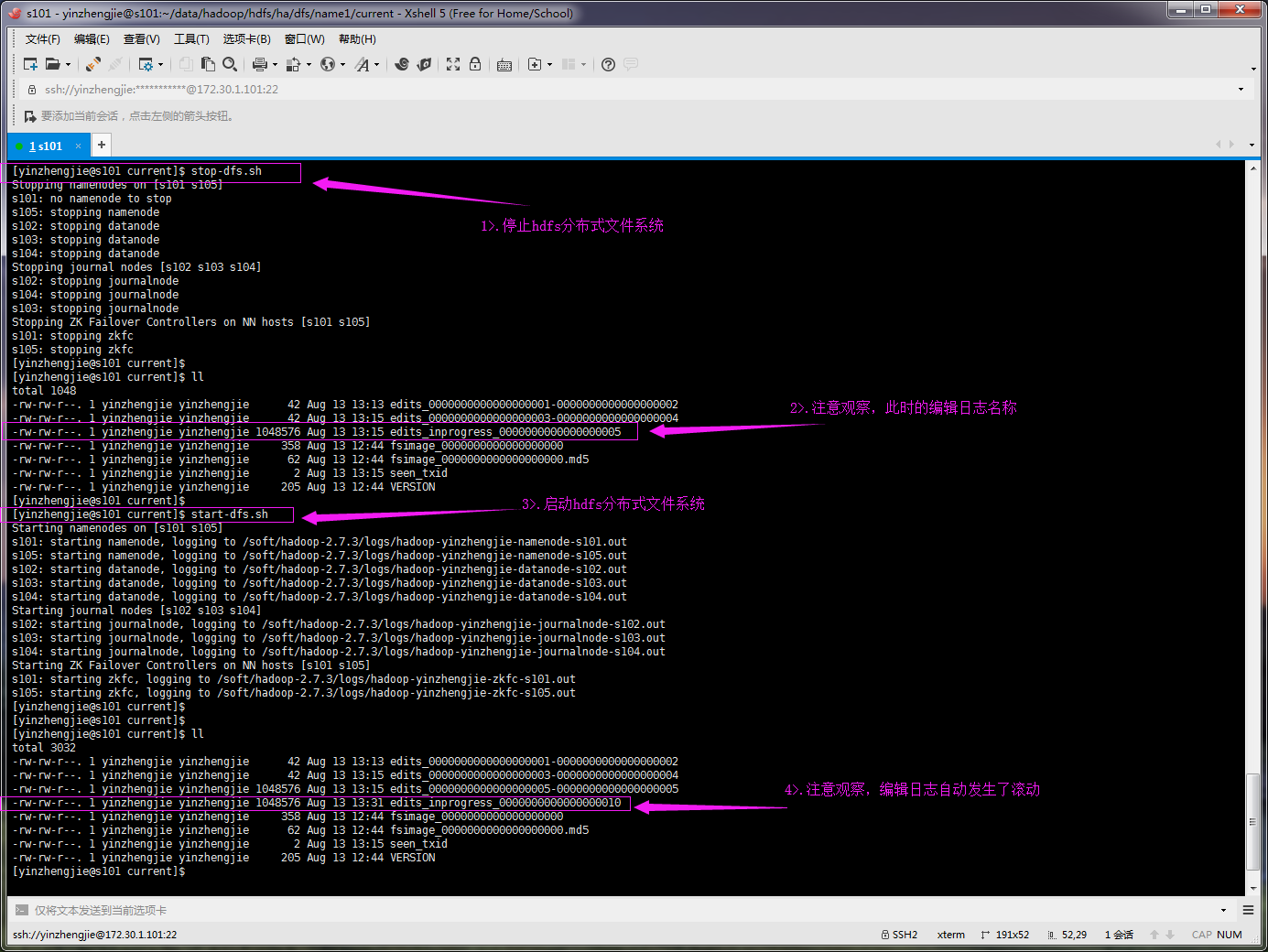
? 第三:如果不是第一次啟動,直接加載編輯日志和鏡像文件到內存,如下圖所示:
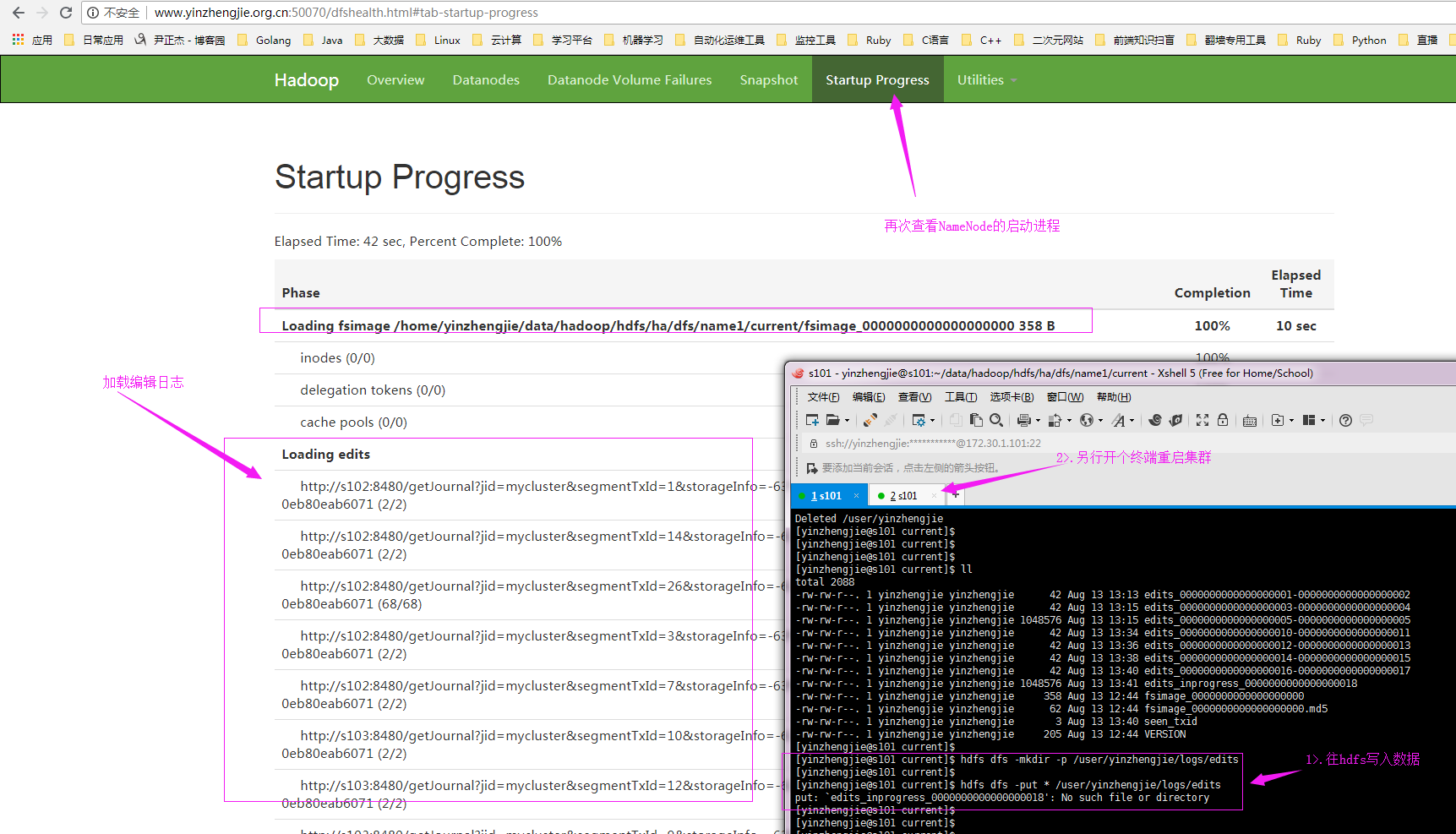
?
? 想要了解更多關于鏡像文件和編輯日志信息,可參考:https://www.cnblogs.com/yinzhengjie/p/9098092.html。
?
二.SecondaryNameNode工作原理(默認端口號:50090)
1>.什么是SecondaryNameNode
它是輔助namenode的進程,Secondary NameNode,為主namenode內存中的文件系統元數據創建檢查點,Secondary NameNode所做的不過是在文件系統中設置一個檢查點來幫助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的備份。
2>.SecondaryNameNode有兩個作用
2.1>.鏡像備份,即備份fsimage(fsimage是元數據發送檢查點時寫入文件);
2.2>.日志與鏡像的定期合并。簡單的說是將Namenode中edits日志和fsimage合并,防止如果Namenode節點故障,namenode下次啟動的時候,會把fsimage加載到內存中,應用edits log,edits log往往很大,導致操作往往很耗時。(這也是namenode容錯的一套機制)
以上兩個過程同時進行,稱為checkpoint(檢查點)。?
3>.NameNode+SecondaryNameNode的工作原理
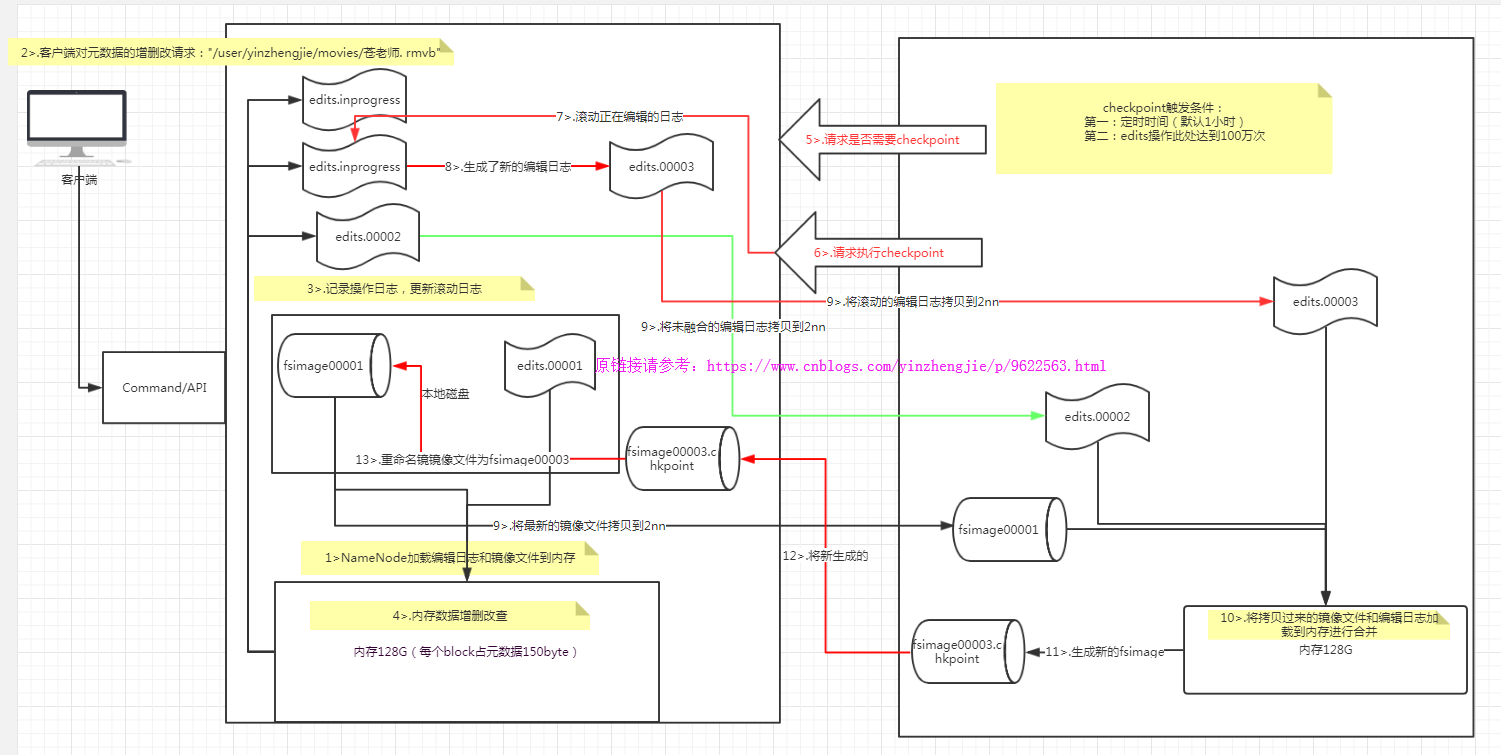
第一階段:NameNode啟動1>.第一次啟動NameNode格式化后,創建fsimage和edits文件。如果不是第一次啟動,直接加載編輯日志和鏡像文件到內存。2>.客戶端對元數據進行增刪改的請求3>.NameNode記錄操作日志,更新滾動日志。4>.NameNode在內存中對數據進行增刪改查第二階段:Secondary NameNode工作1>.Secondary NameNode詢問NameNode是否需要checkpoint。直接帶回NameNode是否檢查結果。2>.Secondary NameNode請求執行checkpoint。3>.NameNode滾動正在寫的edits日志4>.將滾動前的編輯日志和鏡像文件拷貝到Secondary NameNode5>.Secondary NameNode加載編輯日志和鏡像文件到內存,并合并。6>.生成新的鏡像文件fsimage.chkpoint7>.拷貝fsimage.chkpoint到NameNode8>.NameNode將fsimage.chkpoint重新命名成fsimage
? 檢查點和編輯日志存放位置:
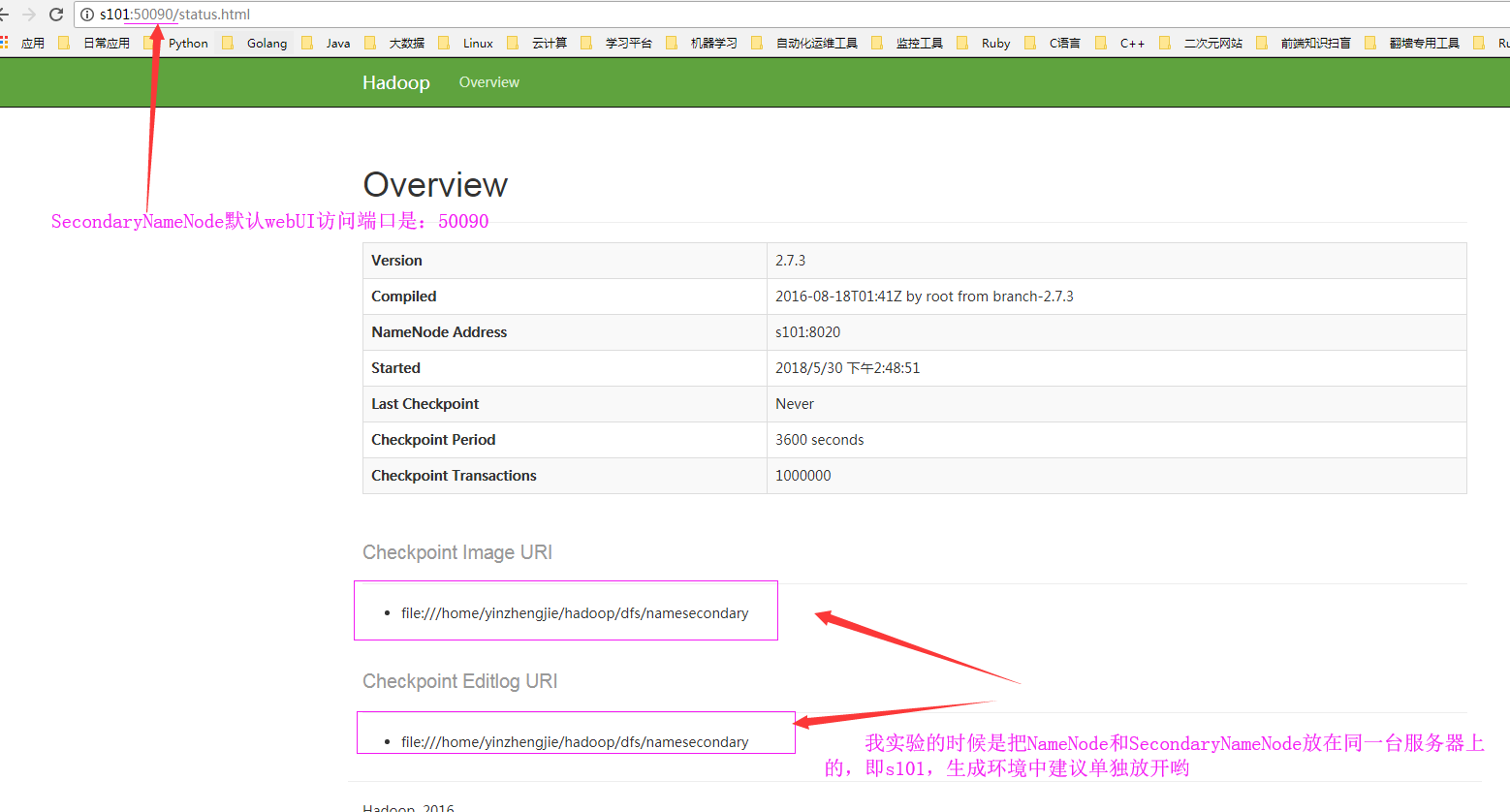
chkpoint檢查時間參數設置1>.通常情況下,SecondaryNameNode每隔一小時執行一次。[hdfs-default.xml]<property><name>dfs.namenode.checkpoint.period</name><value>3600</value></property>2>.一分鐘檢查一次操作次數,當操作次數達到1百萬時,SecondaryNameNode執行一次。<property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value><description>操作動作次數</description></property><property><name>dfs.namenode.checkpoint.check.period</name><value>60</value><description> 1分鐘檢查一次操作次數</description></property>SecondaryNameNode目錄結構Secondary NameNode用來監控HDFS狀態的輔助后臺程序,每隔一段時間獲取HDFS元數據的快照。在/home/yinzhengjie/hadoop-2.7.3/data/hdfs/dfs/namesecondary/current這個目錄中查看SecondaryNameNode目錄結構。edits_0000000000000000001-0000000000000000002fsimage_0000000000000000002fsimage_0000000000000000002.md5VERSIONSecondaryNameNode的namesecondary/current目錄和主namenode的current目錄的布局相同。好處:在主namenode發生故障時(假設沒有及時備份數據),可以從SecondaryNameNode恢復數據。方法一:將SecondaryNameNode中數據拷貝到namenode存儲數據的目錄;方法二:使用-importCheckpoint選項啟動namenode守護進程,從而將SecondaryNameNode中數據拷貝到namenode目錄中。
?
?
三.DataNode工作原理
1>.什么是DataNode
用大白話來說,NameNode用來存儲一些元數據信息的,而DataNode卻是用來存放真實數據的。
2>.DataNode的工作機制
?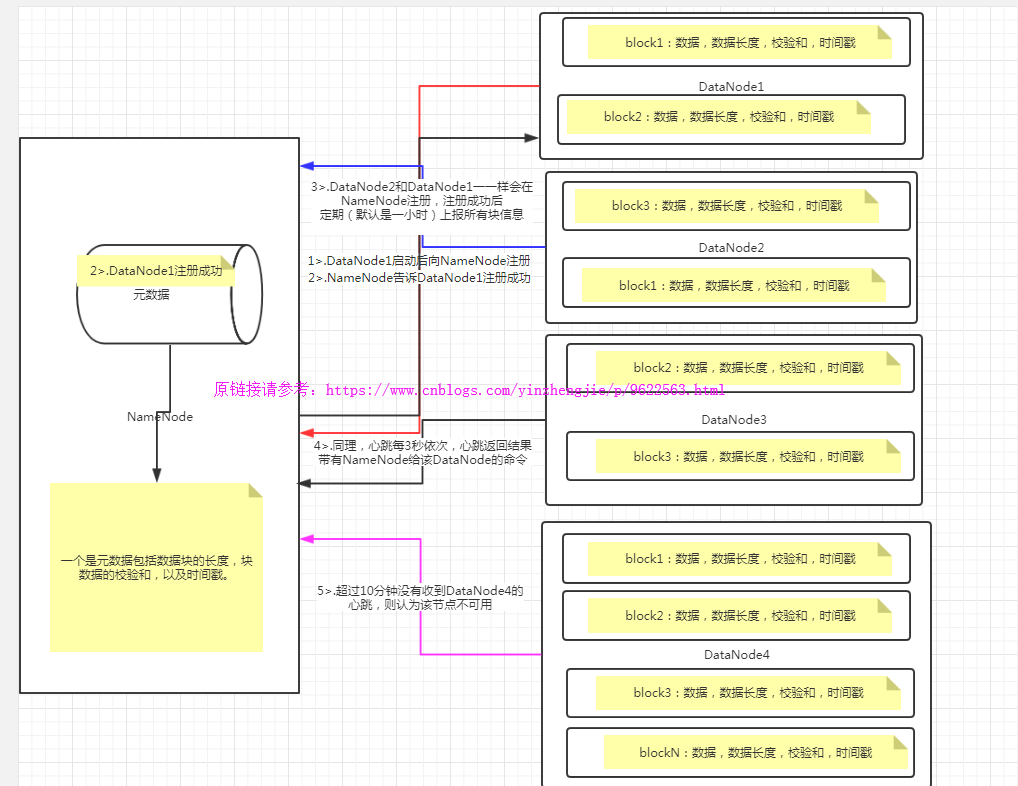
? 如上圖所示,DataNode和NameNode的通信機制如下:
1>.一個數據塊在datanode上以文件形式存儲在磁盤上,包括兩個文件,一個是數據本身,一個是元數據包括數據塊的長度,塊數據的校驗和,以及時間戳。
2>.DataNode啟動后向namenode注冊,通過后,周期性(1小時)的向namenode上報所有的塊信息。
3>.心跳是每3秒一次,心跳返回結果帶有namenode給該datanode的命令如復制塊數據到另一臺機器,或刪除某個數據塊。如果超過10分鐘沒有收到某個datanode的心跳,則認為該節點不可用。
集群運行中可以安全加入和退出一些機器。這種專業術語叫做集群的服役和退役。關于如何服役和退役詳情請參考我之前分享的筆記:https://www.cnblogs.com/yinzhengjie/p/9101070.html
DataNode的校驗和是為了保證數據的完整性:1>.當DataNode讀取block的時候,它會計算checksum;2>.如果計算后的checksum,與block創建時值不一樣,說明block已經損壞;3>.client此時會讀取其他DataNode上的block;4>.datanode在其文件創建后周期驗證checksum;5>.不論數據是否發生改變,DataNode都會定期(默認是一小時)上報數據;掉線時限參數設置datanode進程死亡或者網絡故障造成datanode無法與namenode通信,namenode不會立即把該節點判定為死亡,要經過一段時間,這段時間暫稱作超時時長。HDFS默認的超時時長為10分鐘+30秒。如果定義超時時間為timeout,則超時時長的計算公式為:timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。而默認的dfs.namenode.heartbeat.recheck-interval 大小為5分鐘,dfs.heartbeat.interval默認為3秒。需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的單位為毫秒,dfs.heartbeat.interval的單位為秒。[hdfs-site.xml]<property><name>dfs.namenode.heartbeat.recheck-interval</name><value>300000</value></property><property><name> dfs.heartbeat.interval </name><value>3</value></property>datanode也可以配置成多個目錄,每個目錄存儲的數據不一樣。即:數據不是副本。具體配置如下:[hdfs-site.xml]<property><name>dfs.datanode.data.dir</name><value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value></property>
?
?
四.HDFS掃盲(跟你們小伙伴聊天別被他這些簡單問題問到了)
1>.請列出正常工作的Hadoop集群中Hadoop都分別需要啟動哪些進程,它們的作用分別是什么?
?
1>.NameNode它是hadoop中的主服務器,管理文件系統名稱空間和對集群中存儲的文件的訪問,保存有metadate。 2>.SecondaryNameNode它不是namenode的冗余守護進程,而是提供周期檢查點和清理任務。幫助NN合并editslog,減少NN啟動時間。 3>.DataNode它負責管理連接到節點的存儲(一個集群中可以有多個節點)。每個存儲數據的節點運行一個datanode守護進程。 4>.ResourceManager(JobTracker)JobTracker負責調度DataNode上的工作。每個DataNode有一個TaskTracker,它們執行實際工作。 5>.NodeManager(TaskTracker)執行任務。 6>.DFSZKFailoverController高可用時它負責監控NN的狀態,并及時的把狀態信息寫入ZK。它通過一個獨立線程周期性的調用NN上的一個特定接口來獲取NN的健康狀態。FC也有選擇誰作為Active NN的權利,因為最多只有兩個節點,目前選擇策略還比較簡單(先到先得,輪換)。 7>.JournalNode 高可用情況下存放namenode的editlog文件。
2>.
?
3>.
?
)


















