2019獨角獸企業重金招聘Python工程師標準>>> 
InfluxDB 的存儲機制解析
本文介紹了InfluxDB對于時序數據的存儲/索引的設計。由于InfluxDB的集群版已在0.12版就不再開源,因此如無特殊說明,本文的介紹對象都是指 InfluxDB?單機版
1. InfluxDB 的存儲引擎演進
盡管InfluxDB自發布以來歷時三年多,其存儲引擎的技術架構已經做過幾次重大的改動, 以下將簡要介紹一下InfluxDB的存儲引擎演進的過程。
1.1 演進簡史
- 版本0.9.0之前
**基于 LevelDB的LSMTree方案** - 版本0.9.0~0.9.4
**基于BoltDB的mmap COW B+tree方案** - 版本0.9.5~1.2
**基于自研的 WAL + TSMFile 方案**(TSMFile方案是0.9.6版本正式啟用,0.9.5只是提供了原型) - 版本1.3~至今
**基于自研的 WAL + TSMFile + TSIFile 方案**
1.2 演進的考量
InfluxDB的存儲引擎先后嘗試過包括LevelDB, BoltDB在內的多種方案。但是對于InfluxDB的下述訴求終不能完美地支持:
- 時序數據在降采樣后會存在大批量的數據刪除
=> *LevelDB的LSMTree刪除代價過高* - 單機環境存放大量數據時不能占用過多文件句柄
=> *LevelDB會隨著時間增長產生大量小文件* - 數據存儲需要熱備份
=> *LevelDB只能冷備* - 大數據場景下寫吞吐量要跟得上
=> *BoltDB的B+tree寫操作吞吐量成瓶頸* - 存儲需具備良好的壓縮性能
=> *BoltDB不支持壓縮*
此外,出于技術棧的一致性以及部署的簡易性考慮(面向容器部署),InfluxDB團隊希望存儲引擎 與 其上層的TSDB引擎一樣都是用GO編寫,因此潛在的RocksDB選項被排除
基于上述痛點,InfluxDB團隊決定自己做一個存儲引擎的實現。
2 InfluxDB的數據模型
在解析InfluxDB的存儲引擎之前,先回顧一下InfluxDB中的數據模型。
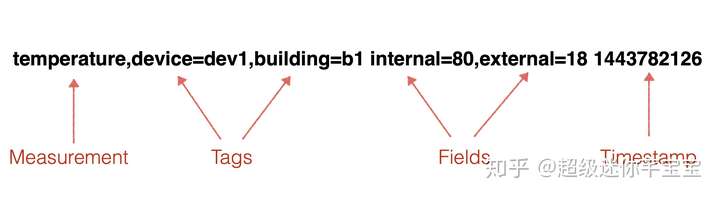
在InfluxDB中,時序數據支持多值模型,它的一條典型的時間點數據如下所示:
圖 1
?
- measurement:
指標對象,也即一個數據源對象。每個measurement可以擁有一個或多個指標值,也即下文所述的**field**。在實際運用中,可以把一個現實中被檢測的對象(如:“cpu”)定義為一個measurement - tags:
概念等同于大多數時序數據庫中的tags, 通常通過tags可以唯一標示數據源。每個tag的key和value必須都是字符串。 - field:
數據源記錄的具體指標值。每一種指標被稱作一個“field”,指標值就是 “field”對應的“value” - timestamp:
數據的時間戳。在InfluxDB中,理論上時間戳可以精確到 **納秒**(ns)級別
此外,在InfluxDB中,measurement的概念之上還有一個對標傳統DBMS的?Database?的概念,邏輯上每個Database下面可以有多個measurement。在單機版的InfluxDB實現中,每個Database實際對應了一個文件系統的?目錄。
2.1 Serieskey的概念
InfluxDB中的SeriesKey的概念就是通常在時序數據庫領域被稱為?時間線?的概念, 一個SeriesKey在內存中的表示即為下述字符串(逗號和空格被轉義)的?字節數組(http://github.com/influxdata/influxdb/model#MakeKey())
{measurement名}{tagK1}={tagV1},{tagK2}={tagV2},...
其中,SeriesKey的長度不能超過 65535 字節
2.2 支持的Field類型
InfluxDB的Field值支持以下數據類型:
DatatypeSize in MemValue RangeFloat8 bytes1.797693134862315708145274237317043567981e+308 ~ 4.940656458412465441765687928682213723651e-324Integer8 bytes-9223372036854775808 ~ 9223372036854775807String0~64KBString with length less than 64KBBoolean1 bytetrue 或 false
在InfluxDB中,Field的數據類型在以下范圍內必須保持不變,否則寫數據時會報錯?類型沖突。
同一Serieskey + 同一field + 同一shard
2.3 Shard的概念
在InfluxDB中,?能且只能?對一個Database指定一個?Retention Policy?(簡稱:RP)。通過RP可以對指定的Database中保存的時序數據的留存時間(duration)進行設置。而?Shard?的概念就是由duration衍生而來。一旦一個Database的duration確定后, 那么在該Database的時序數據將會在這個duration范圍內進一步按時間進行分片從而時數據分成以一個一個的shard為單位進行保存。
shard分片的時間 與 duration之間的關系如下
Duration of RPShard Duration< 2 Hours1 Hour>= 2 Hours 且 <= 6 Months1 Day> 6 Months7 Days
新建的Database在未顯式指定RC的情況下,默認的RC為?數據的Duration為永久,Shard分片時間為7天
注: 在閉源的集群版Influxdb中,用戶可以通過RC規則指定數據在基于時間分片的基礎上再按SeriesKey為單位進行進一步分片
3. InfluxDB的存儲引擎分析
時序數據庫的存儲引擎主要需滿足以下三個主要場景的性能需求
- 大批量的時序數據寫入的高性能
- 直接根據時間線(即Influxdb中的?Serieskey?)在指定時間戳范圍內掃描數據的高性能
- 間接通過measurement和部分tag查詢指定時間戳范圍內所有滿足條件的時序數據的高性能
InfluxDB在結合了1.2所述考量的基礎上推出了他們的解決方案,即下面要介紹的?WAL + TSMFile + TSIFile的方案
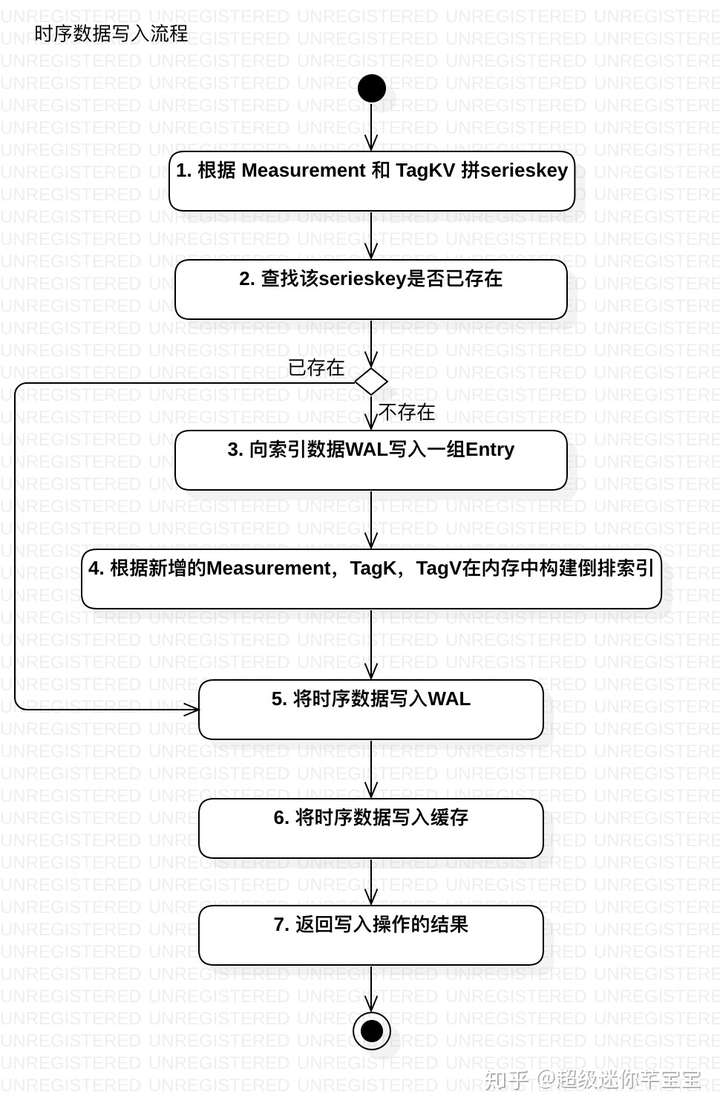
3.1 WAL解析
InfluxDB寫入時序數據時為了確保數據完整性和可用性,與大部分數據庫產品一樣,都是會先寫WAL,再寫入緩存,最后刷盤。對于InfluxDB而言,寫入時序數據的主要流程如同下圖所示:
圖 2
?
InfluxDB對于時間線數據和時序數據本身分開,分別寫入不同的WAL中,其結構如下所示:
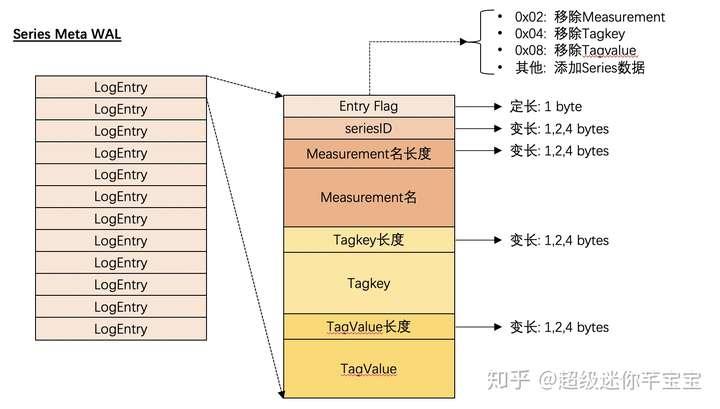
索引數據的WAL
由于InfluxDB支持對Measurement,TagKey,TagValue的刪除操作,當然隨著時序數據的不斷寫入,自然也包括?增加新的時間線,因此索引數據的WAL會區分當前所做的操作具體是什么,它的WAL的結構如下圖所示
圖 3
?
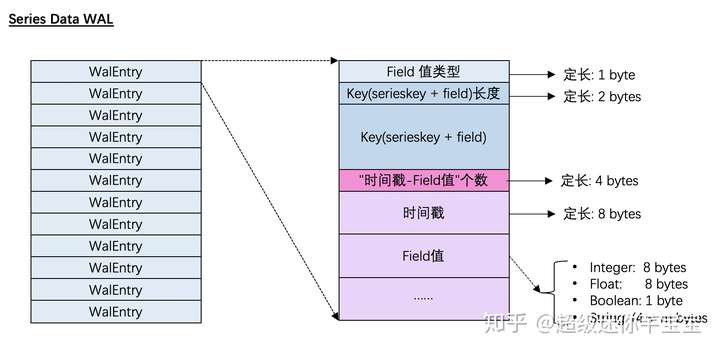
時序數據的WAL
由于InfluxDB對于時序數據的寫操作永遠只有單純寫入,因此它的Entry不需要區分操作種類,直接記錄寫入的數據即可
圖 4
?
3.2 TSMFile解析
TSMFile是InfluxDB對于時序數據的存儲方案。在文件系統層面,每一個TSMFile對應了一個?Shard。
TSMFile的存儲結構如下圖所示:
圖 5
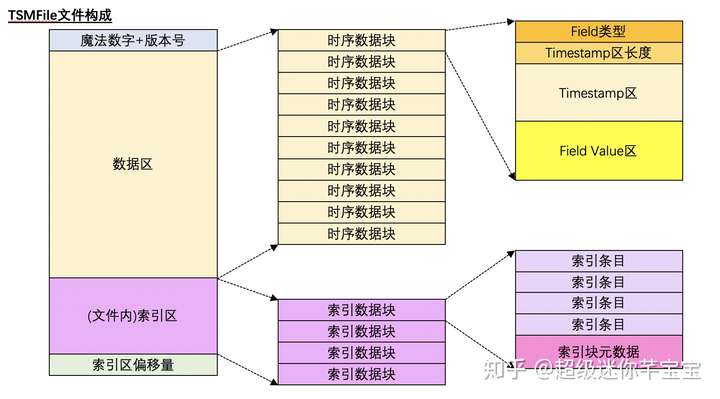
?
其特點是在一個TSMFile中將 時序數據(i.e Timestamp + Field value)保存在數據區;將Serieskey 和 Field Name的信息保存在索引區,通過一個基于 Serieskey + Fieldkey構建的形似B+tree的文件內索引快速定位時序數據所在的?數據塊
注: 在當前版本中,單個TSMFile的最大長度為2GB,超過時即使是同一個Shard,也會繼續新開一個TSMFile保存數據。本文的介紹出于簡單化考慮,以下內容不考慮同一個Shard的TSMFile分裂的場景
- 索引塊的構成
上文的索引塊的構成,如下所示:?*圖 6*
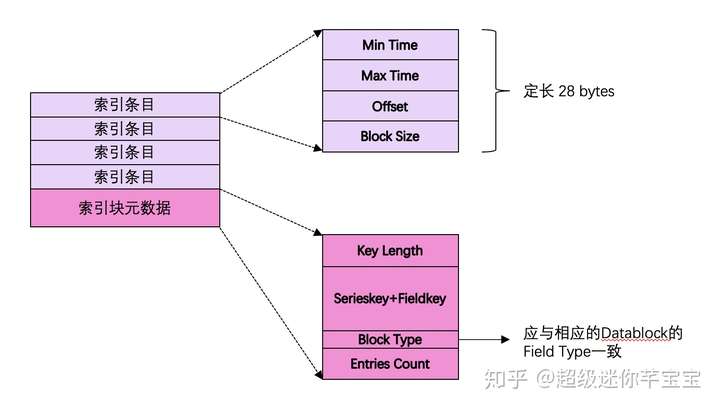
?
其中 **索引條目** 在InfluxDB的源碼中被稱為`directIndex`。在TSMFile中,索引塊是按照 Serieskey + Fieldkey **排序** 后組織在一起的。明白了TSMFile的索引區的構成,就可以很自然地理解InfluxDB如何高性能地在TSMFile掃描時序數據了:1. 根據用戶指定的時間線(Serieskey)以及Field名 在 **索引區** 利用二分查找找到指定的Serieskey+FieldKey所處的 **索引數據塊**
2. 根據用戶指定的時間戳范圍在 **索引數據塊** 中查找數據落在哪個(*或哪幾個*)**索引條目**
3. 將找到的 **索引條目** 對應的 **時序數據塊** 加載到內存中進行進一步的Scan*注:上述的1,2,3只是簡單化地介紹了查詢機制,實際的實現中還有類似掃描的時間范圍跨索引塊等一系列復雜場景*<br>
- 時序數據的存儲
在圖 2中介紹了時序數據塊的結構:即同一個 Serieskey + Fieldkey 的 所有時間戳 - Field值對被拆分開,分成兩個區:Timestamps區和Value區分別進行存儲。它的目的是:實際存儲時可以分別對時間戳和Field值按不同的壓縮算法進行存儲以減少時序數據塊的大小
采用的壓縮算法如下所示:- Timestamp:?Delta-of-delta encoding
- Field Value:由于單個數據塊的Field Value必然數據類型相同,因此可以集中按數據類型采用不同的壓縮算法
- Float類:?Gorrila's Float Commpression
- Integer類型: Delta Encoding + Zigzag Conversion + RLE / Simple8b / None
- String類型:?Snappy Compression
- Boolean類型: Bit packing
?
做查詢時,當利用TSMFile的索引找到文件中的時序數據塊時,將數據塊載入內存并對Timestamp以及Field Value進行解壓縮后以便繼續后續的查詢操作。
3.3 TSIFile解析
有了TSMFile,第3章開頭所說的三個主要場景中的場景1和場景2都可以得到很好的解決。但是如果查詢時用戶并沒有按預期按照Serieskey來指定查詢條件,而是指定了更加復雜的條件,該如何確保它的查詢性能?通常情況下,這個問題的解決方案是依賴倒排索引(Inverted Index)。
InfluxDB的倒排索引依賴于下述兩個數據結構
map<SeriesID, SeriesKey>map<tagkey, map<tagvalue, List<SeriesID>>>
它們在內存中展現如下:
圖 7
?
圖 8
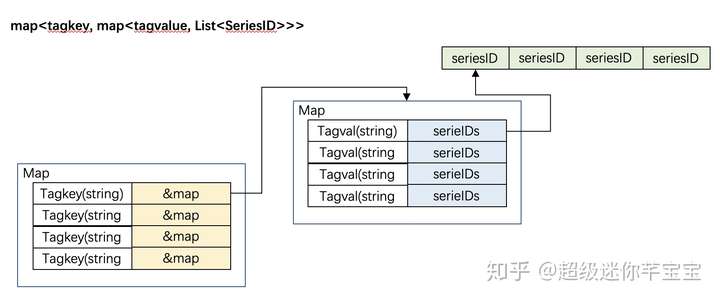
?
但是在實際生產環境中,由于用戶的時間線規模會變得很大,因此會造成倒排索引使用的內存過多,所以后來InfluxDB又引入了?TSIFile
TSIFile的整體存儲機制與TSMFile相似,也是以?Shard?為單位生成一個TSIFile。具體的存儲格式就在此不贅述了。
4. 總結
以上就是對InfluxDB的存儲機制的粗淺解析,由于目前所見的只有單機版的InfluxDB,所以尚不知道集群版的InfluxDB在存儲方面有哪些不同。但是,即便是這單機版的存儲機制,也對我們設計時序數據庫有著重要的參考意義。
?
#阿里云開年Hi購季#幸運抽好禮!
點此抽獎:【阿里云】開年Hi購季,幸運抽好禮
?
原文鏈接
本文為云棲社區原創內容,未經允許不得轉載。


)




)




![[AHOI2009]最小割(最大流+tarjan)](http://pic.xiahunao.cn/[AHOI2009]最小割(最大流+tarjan))


)



)