什么是Ray
之前花了大概兩到三天把Ray相關的論文,官網文檔看了一遍,同時特意去找了一些中文資料看Ray當前在國內的發展情況(以及目前國內大部分人對Ray的認知程度)。
先來簡單介紹下我對Ray的認知。
首先基因很重要,所以我們先需要探查下Ray最初是為了解決什么問題而產生的。Ray的論文顯示,它最早是為了解決增強學習的挑戰而設計的。增強學習的難點在于它是一個需要邊學習,邊做實時做預測的應用場景,這意味會有不同類型的tasks同時運行,并且他們之間存在復雜的依賴關系,tasks會在運行時動態產生產生新的tasks,現有的一些計算模型肯定是沒辦法解決的。如果Ray只是為了解決RL事情可能沒有那么復雜,但是作者希望它不僅僅能跑增強學習相關的,希望是一個通用的分布式機器學習框架,這就意味著Ray必然要進行分層抽象了,也就是至少要分成系統層和應用層。
系統層面,既然是分布式的應用,那么肯定需要有一個應用內的resource/task調度和管理。首先是Yarn,K8s等資源調度框架是應用程序級別的的調度,Ray作為一個為了解決具體業務問題的應用,應該要跑在他們上面而不是取代他們,而像Spark/Flink雖然也是基于task級別的資源調度框架,但是因為他們在設計的時候是為了解決一個比較具體的抽象問題,所以系統對task/資源都做了比較高的封裝,一般用戶是面向業務編程,很難直接操控task以及對應的resource。我們以Spark為例,用戶定義好了數據處理邏輯,至于如何將這些邏輯分成多少個Job,Stage,Task,最后占用多少Resource (CPU,GPU,Memory,Disk)等等,都是由框架自行決定,而用戶無法染指。這也是我一直詬病Spark的地方。所以Ray在系統層面,是一個通用的以task為調度級別的,同時可以針對每個task控制資源粒度的一個通用的分布式task執行系統。記住,在Ray里,你需要明確定義Task以及Task的依賴,并且為每個task指定合適(數量,資源類型)的資源。比如你需要用三個task處理一份數據,那么你就需要自己啟動三個task,并且指定這些task需要的資源(GPU,CPU)以及數量(可以是小數或者整數)。而在Spark,Flink里這是不大可能的。Ray為了讓我們做這些事情,默認提供了Python的語言接口,你可以像使用Numpy那樣去使用Ray。實際上,也已經有基于Ray做Backend的numpy實現了,當然它屬于應用層面的東西了。Ray系統層面很簡單,也是典型的master-worker模式。類似spark的driver-executor模式,不同的是,Ray的worker類似yarn的worker,是負責Resource管理的,具體任務它會啟動Python worker去執行你的代碼,而spark的executor雖然也會啟動Python worker執行python代碼,但是對應的executor也執行業務邏輯,和python worker有數據交換和傳輸。
應用層面,你可以基于Ray的系統進行編程,因為Ray默認提供了Python的編程接口,所以你可以自己實現增強學習庫(RLLib),也可以整合已有的算法框架,比如tensorflow,讓tensorflow成為Ray上的一個應用,并且輕松實現分布式。我記得知乎上有人說Ray其實就是一個Python的分布式RPC框架,這么說是對的,但是顯然會有誤導,因為這很可能讓人以為他只是“Python分布式RPC框架”。
如何和Spark協作
根據前面我講述的,我們是可以完全基于Ray實現Spark的大部分API的,只是是Ray backend而非Spark core backend。實際上Ray目前正在做流相關的功能,他們現在要做的就是要兼容Flink的API。雖然官方宣稱Ray是一個新一代的機器學習分布式框架,但是他完全可以cover住當前大數據和AI領域的大部分事情,但是任重道遠,還需要大量的事情。所以對我而言,我看中的是它良好的Python支持,以及系統層面對資源和task的控制,這使得:
1.我們可以輕易的把我們的單機Python算法庫在Ray里跑起來(雖然算法自身不是分布式的),但是我們可以很好的利用Ray的資源管理和調度功能,從而解決AI平臺的資源管理問題。
2.Ray官方提供了大量的機器學習算法的實現,以及對當前機器學習框架如Tensorflow,Pytorch的整合,而分布式能力則比這些庫原生提供的模式更靠譜和易用。畢竟對于這些框架而言,支持他們分布式運行的那些輔助庫(比如TensorFlow提供parameter servers)相當簡陋。
但是,我們知道,數據處理它自身有一個很大的生態,比如你的用戶畫像數據都在數據湖里,你需要把這些數據進行非常復雜的計算才能作為特征喂給你的機器學習算法。而如果這個時候,你還要面向資源編程(或者使用一個還不夠成熟的上層應用)而不是面向“業務”編程,這就顯得很難受了,比如我就想用SQL處理數據,我只關注處理的業務邏輯,這個當前Ray以及之上的應用顯然還是做不到如Spark那么便利的(畢竟Spark就是為了數據處理而生的),所以最好的方式是,數據的獲取和加工依然是在Spark之上,但是數據準備好了就應該丟給用戶基于Ray寫的代碼處理了。Ray可以通過Arrow項目讀取HDFS上Spark已經處理好的數據,然后進行訓練,然后將模型保存為HDFS。當然對于預測,Ray可以自己消化掉或者丟給其他系統完成。我們知道Spark 在整合Python生態方面做出了非常多的努力,比如他和Ray一樣,也提供了python 編程接口,所以spark也較為容易的整合譬如Tensorflow等框架,但是沒辦法很好的管控資源(比如GPU),而且,spark 的executor 會在他所在的服務器上啟動python worker,而spark一般而言是跑在yarn上的,這就對yarn造成了很大的管理麻煩,而且通常yarn 和hdfs之類的都是在一起的,python環境還有資源(CPU/GPU)除了管理難度大以外,還有一個很大的問題是可能會對yarn的集群造成比較大的穩定性風險。
所以最好的模式是按如下步驟開發一個機器學習應用:
寫一個python腳本,在數據處理部分,使用pyspark,在程序的算法訓練部分,使用ray,spark 運行在yarn(k8s)上,ray運行在k8s里好處顯而易見:用戶完全無感知他的應用其實是跑在兩個集群里的,對他來說就是一個普通python腳本。
從架構角度來講,復雜的python環境管理問題都可以丟給ray集群來完成,spark只要能跑基本的pyspark相關功能即可,數據銜接通過數據湖里的表(其實就是一堆parquet文件)即可。當然,如果最后結果數據不大,也可以直接通過client完成pyspark到ray的交互。
Spark和Ray的架構和部署
現在我們來思考一個比較好的部署模式,架構圖大概類似這樣:
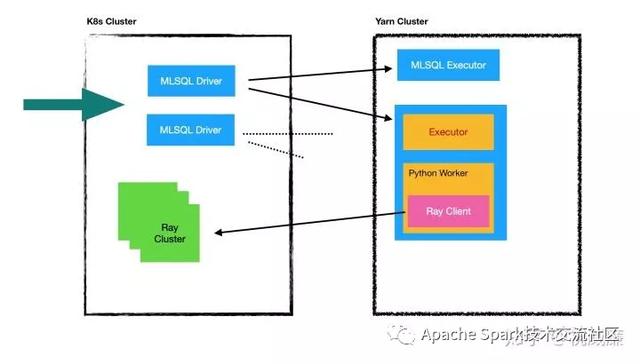
首先,大家可以理解為k8s已經解決一切了,我們spark,ray都跑在K8s上。但是,如果我們希望一個spark 是實例多進程跑的時候,我們并不希望是像傳統的那種方式,所有的節點都跑在K8s上,而是將executor部分放到yarn cluster. 在我們的架構里,spark driver 是一個應用,我們可以啟動多個pod從而獲得多個spark driver實例,對外提供負載均衡,roll upgrade/restart 等功能。也就是k8s應該是面向應用的。但是復雜的計算,我們依然希望留給Yarn,尤其是還涉及到數據本地性,計算和存儲放到一起(yarn和HDFS通常是在一起的),避免k8s和HDFS有大量數據交換。
因為Yarn對Java/Scala友好,但是對Python并不友好,尤其是在yarn里涉及到Python環境問題會非常難搞(主要是Yarn對docker的支持還是不夠優秀,對GPU支持也不好),而機器學習其實一定重度依賴Python以及非常復雜的本地庫以及Python環境,并且對資源調度也有比較高的依賴,因為算法是很消耗機器資源的,必須也有資源池,所以我們希望機器學習部分能跑在K8s里。但是我們希望整個數據處理和訓練過程是一體的,算法的同學應該無法感知到k8s/yarn的區別。為了達到這個目標,用戶依然使用pyspark來完成計算,然后在pyspark里使用ray的API做模型訓練和預測,數據處理部分自動在yarn中完成,而模型訓練部分則自動被分發到k8s中完成。并且因為ray自身的優勢,算法可以很好的控制自己需要的資源,比如這次訓練需要多少GPU/CPU/內存,支持所有的算法庫,在做到對算法最少干擾的情況下,算法的同學們有最好的資源調度可以用。
下面展示一段MLSQL代碼片段展示如何利用上面的架構:
-- python 訓練模型的代碼set py_train='''import rayray.init()@ray.remote(num_cpus=2, num_gpus=1)def f(x): return x * xfutures = [f.remote(i) for i in range(4)]print(ray.get(futures))''';load script.`py_train` as py_train;-- 設置需要的python環境描述set py_env='''''';load script.`py_env` as py_env;-- 加載hive的表load hive.`db1.table1` as table1;-- 對Hive做處理,比如做一些特征工程select features,label from table1 as data;-- 提交Python代碼到Ray里,此時是運行在k8s里的train data as PythonAlg.`/tmp/tf/model`where scripts="py_train"and entryPoint="py_train"and condaFile="py_env"and keepVersion="true"and fitParam.0.fileFormat="json" -- 還可以是parquetand `fitParam.0.psNum`="1";下面是PySpark的示例代碼:
from pyspark.ml.linalg import Vectors, SparseVectorfrom pyspark.sql import SparkSessionimport loggingimport rayfrom pyspark.sql.types import StructField, StructType, BinaryType, StringType, ArrayType, ByteTypefrom sklearn.naive_bayes import GaussianNBimport osfrom sklearn.externals import joblibimport pickleimport scipy.sparse as spfrom sklearn.svm import SVCimport ioimport codecsos.environ["PYSPARK_PYTHON"] = "/Users/allwefantasy/deepavlovpy3/bin/python3"logger = logging.getLogger(__name__)base_dir = "/Users/allwefantasy/CSDNWorkSpace/spark-deep-learning_latest"spark = SparkSession.builder.master("local[*]").appName("example").getOrCreate()data = spark.read.format("libsvm").load(base_dir + "/data/mllib/sample_libsvm_data.txt")## 廣播數據dataBr = spark.sparkContext.broadcast(data.collect())## 訓練模型 這部分代碼會在spark executor里的python worker執行def train(row): import ray ray.init() train_data_id = ray.put(dataBr.value) ## 這個函數的python代碼會在K8s里的Ray里執行 @ray.remote def ray_train(x): X = [] y = [] for i in ray.get(train_data_id): X.append(i["features"]) y.append(i["label"]) if row["model"] == "SVC": gnb = GaussianNB() model = gnb.fit(X, y) # 為什么還需要encode一下? pickled = codecs.encode(pickle.dumps(model), "base64").decode() return [row["model"], pickled] if row["model"] == "BAYES": svc = SVC() model = svc.fit(X, y) pickled = codecs.encode(pickle.dumps(model), "base64").decode() return [row["model"], pickled] result = ray_train.remote(row) ray.get(result) ##訓練模型 將模型結果保存到HDFS上rdd = spark.createDataFrame([["SVC"], ["BAYES"]], ["model"]).rdd.map(train)spark.createDataFrame(rdd, schema=StructType([StructField(name="modelType", dataType=StringType()), StructField(name="modelBinary", dataType=StringType())])).write. format("parquet"). mode("overwrite").save("/tmp/wow")這是一個標準的Python程序,只是使用了pyspark/ray的API,我們就完成了上面所有的工作,同時訓練兩個模型,并且數據處理的工作在spark中,模型訓練的在ray中。
完美結合!最重要的是解決了資源管理的問題!
作者:祝威廉
本文為阿里云原創內容,未經允許不得轉載。






)




)






_學小易找答案...)
