文章目錄
- 問題描述:
- 問題解決
- 分析問題:
- 解決問題
- 第一步:讀取原始數據
- 第二步:觀察原始數據
- 第三步:原始數據的可視化
- 第四步:數據的預處理
- 時間屬性的分解
- 第五步:數據的特征提取
- 特征生成
- 特征選擇
- 第六步:訓練baseline
- 第七步:模型的狀態估計(通過學習曲線)
- 第八步:模型優化
問題描述:
- 在對一個應用使用機器學習算法之前我們應該要分析清楚問題是什么
- 本次項目所要解決的問題是:通過共享單車上的傳感器采集的數據和系統上記錄的用戶的行為數據,用來預測一年中不同時間段某個地區單車的使用情況,從而確定單車在該區域的投放數目,保證單車租賃公司的利益最大化。
- 本項目中收集到的數據中包括:時間(年-月-日-時),季節(春夏秋冬),節日(是/否),工作日(是/否),天氣(四個等級),溫度,體感溫度,濕度,風速,非注冊人員租賃,注冊人員租賃,租賃人數;
問題解決
分析問題:
- 從項目的描述來看,這是一個回歸問題,希望我們通過采集的數據去預測未來某段時間內單車的需求量。
- 從采集的數據的屬性上可以猜測一些:
- 工作日大家應該沒有時間去騎單車出去玩,節假日應該偏多
- 溫度太低或者風速太大都不適合騎單車出去
- 注冊的人員使用單車的頻率應該比非注冊的人員使用單車頻率高
解決問題
第一步:讀取原始數據
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#從本地磁盤讀取數據
df_train = pd.read_csv('kaggle_bike_competition_train.csv',header = 0)
df_train.head(10) #查看前10項內容
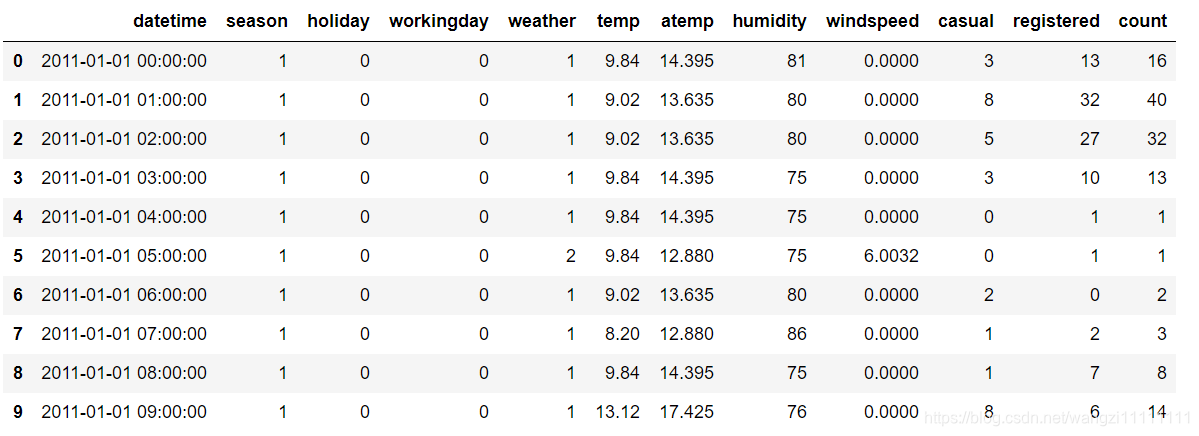
通過查看原始數據發現,datatime這一項數據包括了年月日時分秒,后續可以將其拆分開來。雖然將數據打印出來,但是這樣的方式不太直觀,我們可以通過調用df.info()和df.describe()函數查看數據的統計信息。
第二步:觀察原始數據
df_train.dtypes #查看數據中每行的屬性值
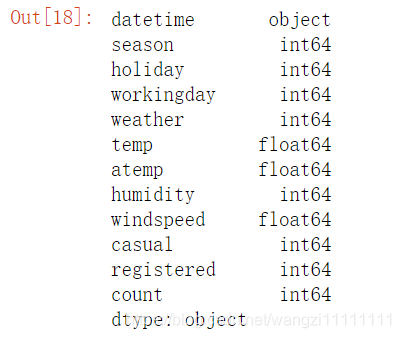
可以看出數據中大部分都是數值型的數據,只有datatime是類別型的數據。
df_train.info()
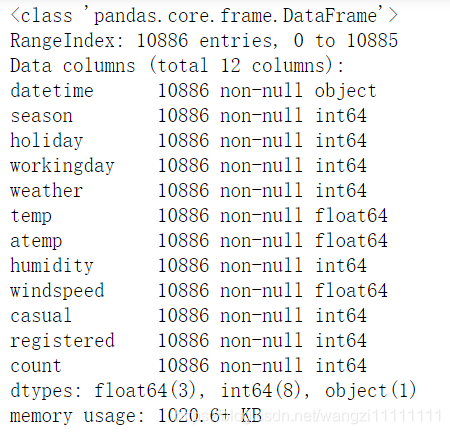
數據的完整性非常好。所有屬性的數據都沒有缺失值,那么接下我們看一下數值型數據的取值范圍吧!
df_train.describe()
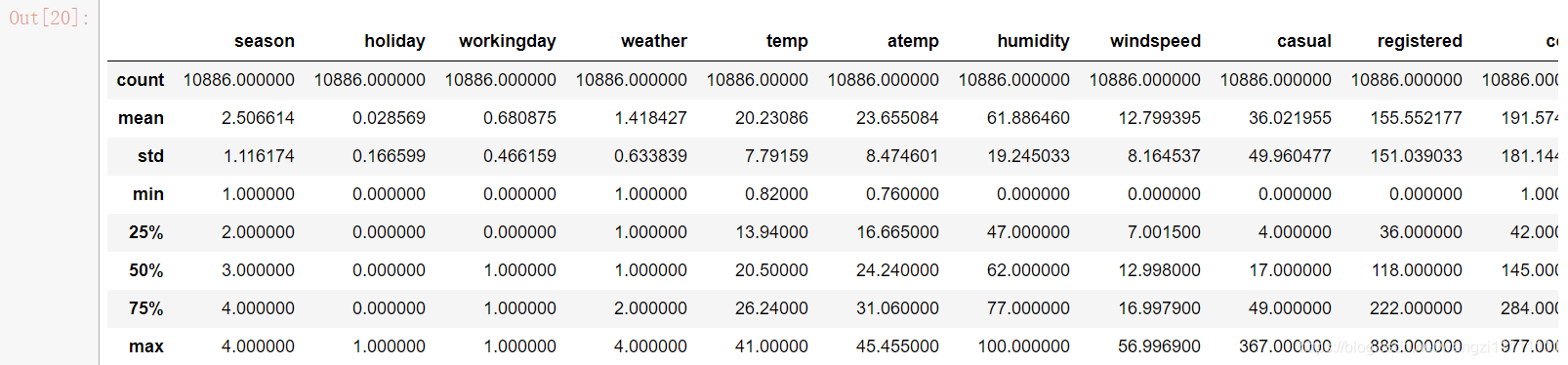
數據中的數值型數據的取值范圍相差不大,每個屬性內部的取值范圍也不大,所以覺得對數據做縮放意義不大。接下來我們通過可視化看看每個屬性與預測值之間的關系吧!
第三步:原始數據的可視化
# 風速
df_train_origin.groupby('windspeed').mean().plot(y='count', marker='o') #畫出風速和租車次數的關系
plt.show()
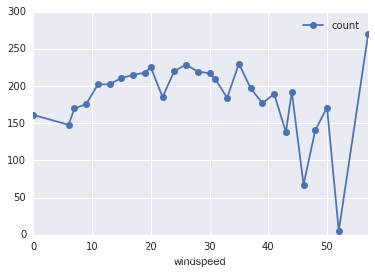
圖中的結果似乎與我們一開始的猜測有些出入,尤其是圖中風速大于50后,單車租賃次數反而劇增,這是一個比較特別的地方,后面可以著重考慮
# 濕度
df_train_origin.groupby('humidity').mean().plot(y='count', marker='o') #畫出濕度值與租車次數的關系
plt.show()
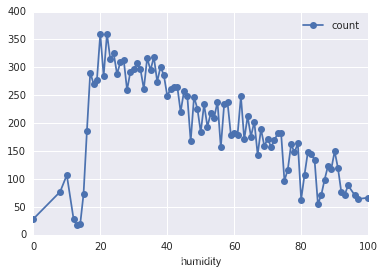
從圖中可以看出過干和過濕都會導致單車租賃的減少。
# 溫度
df_train_origin.groupby('temp').mean().plot(y='count', marker='o') #畫出溫度與租車次數的關系
plt.show()
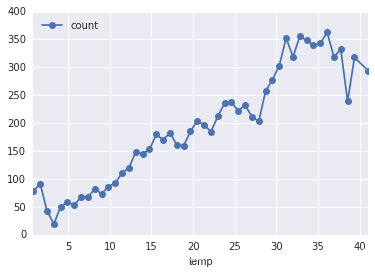
從圖中的結構似乎可以看出隨著溫度的升高,單車租賃次數也越多,這是符合我們之前的猜測的。
#溫度濕度變化
df_train_origin.plot(x='temp', y='humidity', kind='scatter')
plt.show()
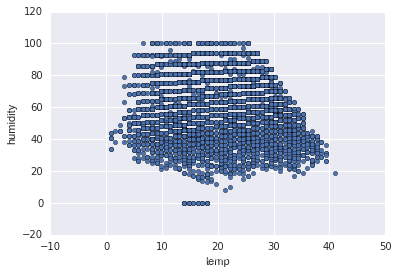
無法看出任何規律,只能說該地區的溫度和濕度的一個分布范圍。
# scatter一下各個維度
fig, axs = plt.subplots(2, 3, sharey=True)
df_train_origin.plot(kind='scatter', x='temp', y='count', ax=axs[0, 0], figsize=(16, 8), color='magenta')
df_train_origin.plot(kind='scatter', x='atemp', y='count', ax=axs[0, 1], color='cyan')
df_train_origin.plot(kind='scatter', x='humidity', y='count', ax=axs[0, 2], color='red')
df_train_origin.plot(kind='scatter', x='windspeed', y='count', ax=axs[1, 0], color='yellow')
df_train_origin.plot(kind='scatter', x='month', y='count', ax=axs[1, 1], color='blue')
df_train_origin.plot(kind='scatter', x='hour', y='count', ax=axs[1, 2], color='green')
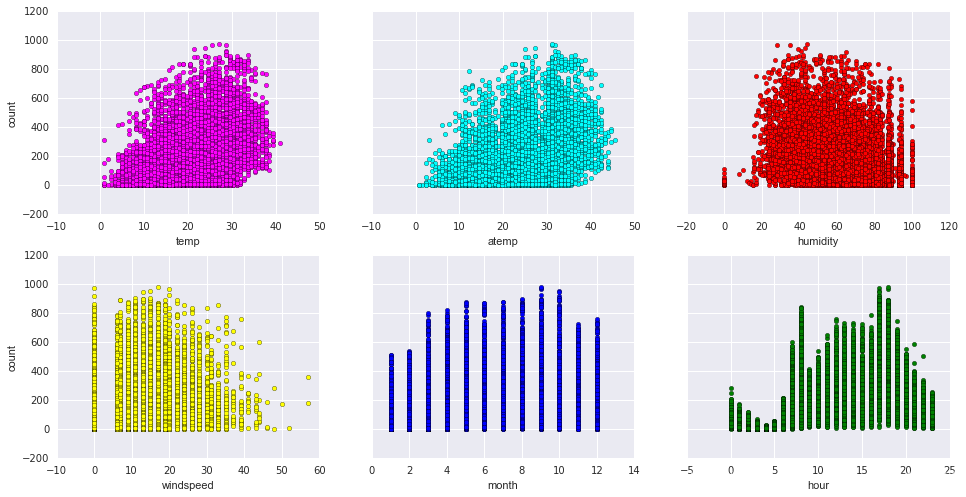
從圖中結果似乎只能看出溫度,體感溫度和租車次數呈現一定的正相關,風速與租車次數是負相關
# scatter一下各個維度
sns.pairplot(df_train_origin[["temp", "month", "humidity", "count"]], hue="count")
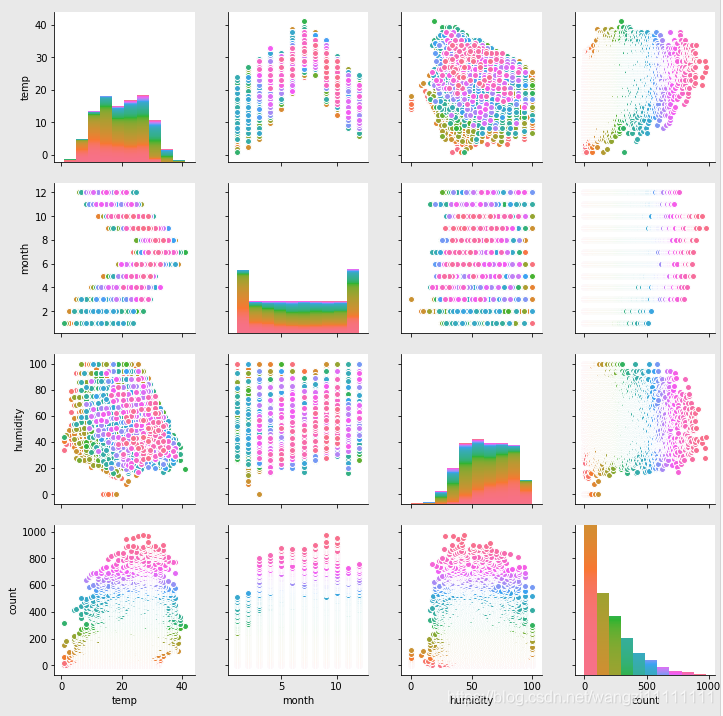
各個屬性之間的相關性不是很強。
# 來看看相關度咯
corr = df_train_origin[['temp','weather','windspeed','day', 'month', 'hour','count']].corr()
corr
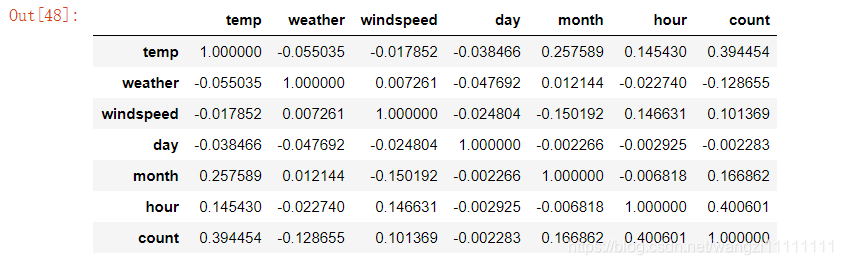
似乎這樣比上面的圖像的結果理解起來更加方便,從表格的結果可知:溫度和小時與汽車租賃的相關性最大。
第四步:數據的預處理
由于原始數據不存在缺失值,類別屬性特征也較少,數值型數據比較規范,所以不需要太多的數據預處理,只需要對時間屬性進行處理進行。
時間屬性的分解
# 把月、日、和 小時單獨拎出來,放到3列中
df_train['month'] = pd.DatetimeIndex(df_train.datetime).month
df_train['day'] = pd.DatetimeIndex(df_train.datetime).dayofweek
df_train['hour'] = pd.DatetimeIndex(df_train.datetime).hour
# 再看
df_train.head(10)
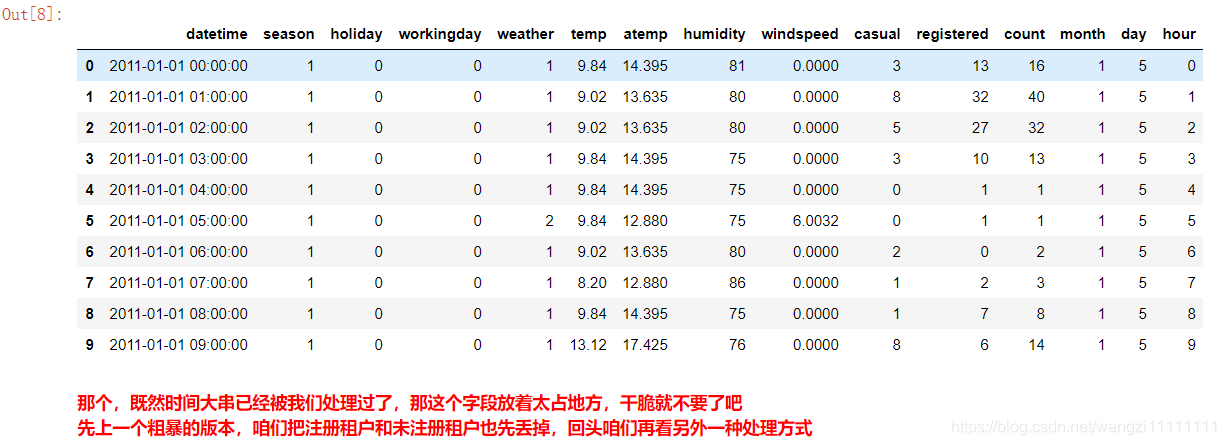
# 那個,保險起見,咱們還是先存一下吧
df_train_origin = df_train
# 拋掉不要的字段
df_train = df_train.drop(['datetime','casual','registered'], axis = 1) #刪除'datetime','casual','registered'等列的數據
# 看一眼
df_train.head(5)
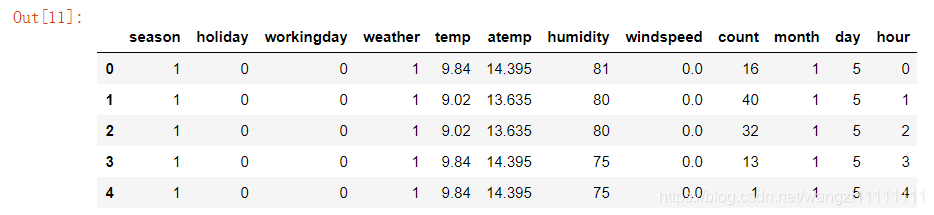
# 得到X和Y
df_train_target = df_train['count'].values
df_train_data = df_train.drop(['count'],axis = 1).values
print 'df_train_data shape is ', df_train_data.shape
print 'df_train_target shape is ', df_train_target.shape
df_train_data shape is (10886L, 11L)
df_train_target shape is (10886L,)
第五步:數據的特征提取
特征生成
由于原始戶數比較規范,暫時先不做特征生成
特征選擇
由于數據比較規范,暫時不做特征選擇
第六步:訓練baseline
from sklearn import linear_model
from sklearn import cross_validation
from sklearn import svm
from sklearn.ensemble import RandomForestRegressor
from sklearn.learning_curve import learning_curve
from sklearn.grid_search import GridSearchCV
from sklearn.metrics import explained_variance_score# 總得切分一下數據咯(訓練集和測試集)
cv = cross_validation.ShuffleSplit(len(df_train_data), n_iter=3, test_size=0.2,random_state=0) #使用3折交叉驗證的方法# 各種模型來一圈print "嶺回歸"
for train, test in cv: svc = linear_model.Ridge().fit(df_train_data[train], df_train_target[train])print("train score: {0:.3f}, test score: {1:.3f}\n".format(svc.score(df_train_data[train], df_train_target[train]), svc.score(df_train_data[test], df_train_target[test])))print "支持向量回歸/SVR(kernel='rbf',C=10,gamma=.001)"
for train, test in cv:svc = svm.SVR(kernel ='rbf', C = 10, gamma = .001).fit(df_train_data[train], df_train_target[train])print("train score: {0:.3f}, test score: {1:.3f}\n".format(svc.score(df_train_data[train], df_train_target[train]), svc.score(df_train_data[test], df_train_target[test])))print "隨機森林回歸/Random Forest(n_estimators = 100)"
for train, test in cv: svc = RandomForestRegressor(n_estimators = 100).fit(df_train_data[train], df_train_target[train])print("train score: {0:.3f}, test score: {1:.3f}\n".format(svc.score(df_train_data[train], df_train_target[train]), svc.score(df_train_data[test], df_train_target[test])))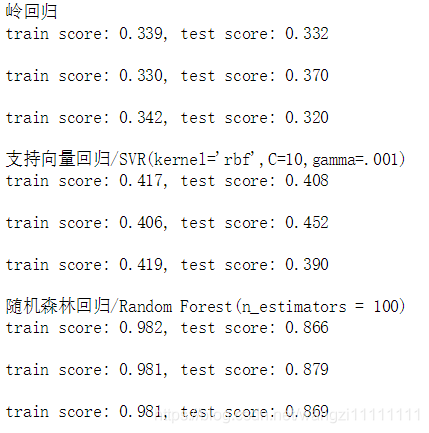
上面簡單的比較了幾種常用的回歸算法在數據集上的表現,從實驗的結果可以看出,隨機森林的結果是最佳的。
第七步:模型的狀態估計(通過學習曲線)
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):plt.figure()plt.title(title)if ylim is not None:plt.ylim(*ylim)plt.xlabel("Training examples")plt.ylabel("Score")train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)train_scores_mean = np.mean(train_scores, axis=1)train_scores_std = np.std(train_scores, axis=1)test_scores_mean = np.mean(test_scores, axis=1)test_scores_std = np.std(test_scores, axis=1)plt.grid()plt.fill_between(train_sizes, train_scores_mean - train_scores_std,train_scores_mean + train_scores_std, alpha=0.1,color="r")plt.fill_between(train_sizes, test_scores_mean - test_scores_std,test_scores_mean + test_scores_std, alpha=0.1, color="g")plt.plot(train_sizes, train_scores_mean, 'o-', color="r",label="Training score")plt.plot(train_sizes, test_scores_mean, 'o-', color="g",label="Cross-validation score")plt.legend(loc="best")return plttitle = "Learning Curves (Random Forest, n_estimators = 100)"
cv = cross_validation.ShuffleSplit(df_train_data.shape[0], n_iter=10,test_size=0.2, random_state=0)
estimator = RandomForestRegressor(n_estimators = 100)
plot_learning_curve(estimator, title, X, y, (0.0, 1.01), cv=cv, n_jobs=4)plt.show()
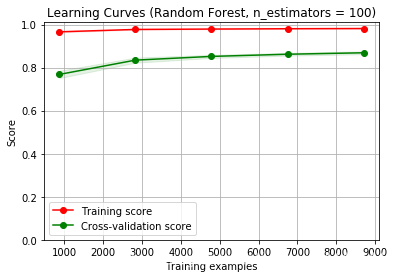
從圖中的結果可以看出,模型處于過擬合狀態
第八步:模型優化
從上面的記過可以看出,模型處于過擬合狀態,可以從模型的參數,特征兩方面來解決。

-XGBoost)
--(介紹,環境配置,基本語法,注釋))


--(數據類型,變量類型,變量作用域,常量,修飾符類型))

--(存儲類,運算符,循環,判斷))

--(函數、數字、數組、字符串))


--(指針,引用))

--(時間,輸入輸出,數據結構))


--(類))

--(繼承、重載、多態、虛函數))