文章目錄
- lecture17:XGBoost(eXtreme Gradient Boosting)
- 目錄
- 1. XGBoost的基本信息
- 2. XGBoost與GBDT的異同點
- 3. XGBoost的原理
- 3.1定義樹的復雜度
- 3.2 分裂節點
- 3.3 自定義損失函數
- 4. XGBoost的使用
lecture17:XGBoost(eXtreme Gradient Boosting)
目錄
1. XGBoost的基本信息
全稱:eXtreme Gradient Boosting
作者:程天奇(華盛頓大學博士)
基礎:GBDT
所屬:boosting 迭代算法、樹類算法
應用類型:分類和回歸
優點:速度快,效果好,可以并行計算處理大量數據,支持多種語言,支持自定義損失函數,正則化,高度靈活性,缺失值處理,剪枝,內置交叉驗證,在已有模型基礎上繼續訓練等等
缺點:發布時間短,工業領域應用較少,需要檢驗
參考博客
2. XGBoost與GBDT的異同點
相同點:
xgboost是在GBDT的基礎上對boosting算法進行的改進,內部決策樹使用的是回歸樹,簡單回顧GBDT如下:
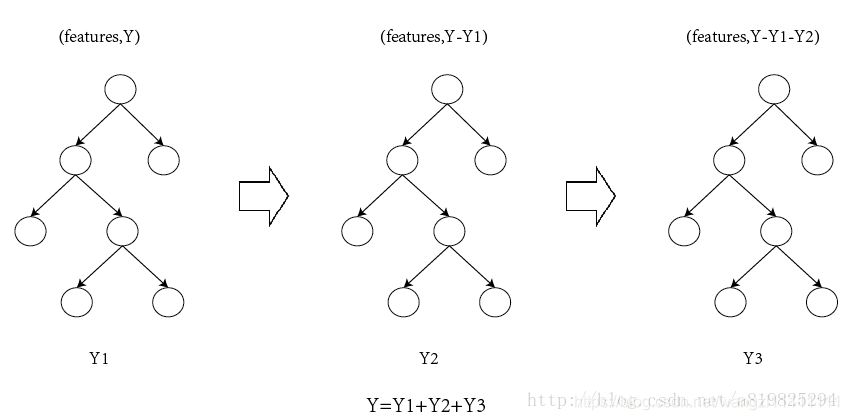
注意:
XGBoost和GBDT本質的思想都是一種殘差學習方式,即當前的弱分類器的主要目標是學習上一個弱分類器的誤差;最后,通過將所有的弱分類器集成在一起,組成一個混合模型,從而降低模型的方差和偏差。
不同點:
如果不考慮工程實現、解決問題上的一些差異,xgboost與gbdt比較大的不同就是目標函數的定義。如下圖是XGBoost目標函數的定義:
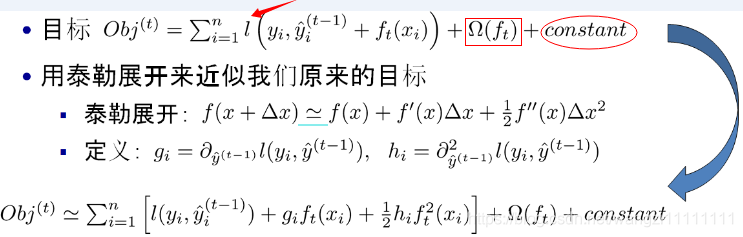
注意:從目標函數的表達式可以看出,XGBoost的目標函數主要分為:加入一顆新樹后模型的誤差,正則化項和一個常數項;其中模型誤差項,可以將加入的新樹看成?X,然后對L函數求泰勒展開,就得到最下面的公式了,從最下面的公式可以看出,目標函數中的損失項包括:上一顆樹所在模型的損失,當前加入新樹后模型的一階導數和加入新樹后的二階導數。XGBoost利用泰勒展開三項,做一個近似,我們可以很清晰地看到,最終的目標函數只依賴于每個數據點的在誤差函數上的一階導數和二階導數。正則化項包括對當前新加入的樹葉子結點個數的約束(L1正則化項)和當前新加入樹的葉子結點的權重的約束(L2正則化項)。
3. XGBoost的原理
對于上面給出的目標函數,我們可以進一步化簡
3.1定義樹的復雜度
對于f的定義做一下細化,把樹拆分成結構部分q和葉子權重部分w。下圖是一個具體的例子。結構函數q把輸入映射到葉子的索引號上面去,而w給定了每個索引號對應的葉子分數是什么
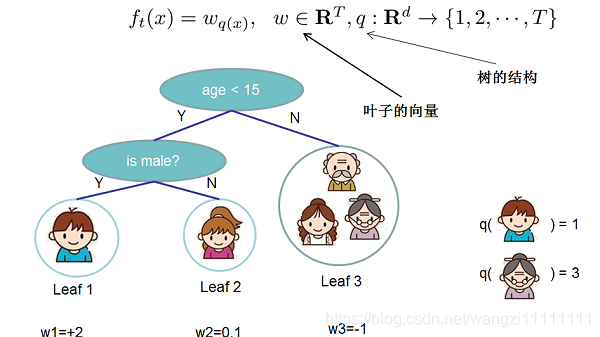
定義這個復雜度包含了一棵樹里面節點的個數,以及每個樹葉子節點上面輸出分數的L2模平方。
當然這不是唯一的一種定義方式,不過這一定義方式學習出的樹效果一般都比較不錯。下圖還給出了復雜度計算的一個例子
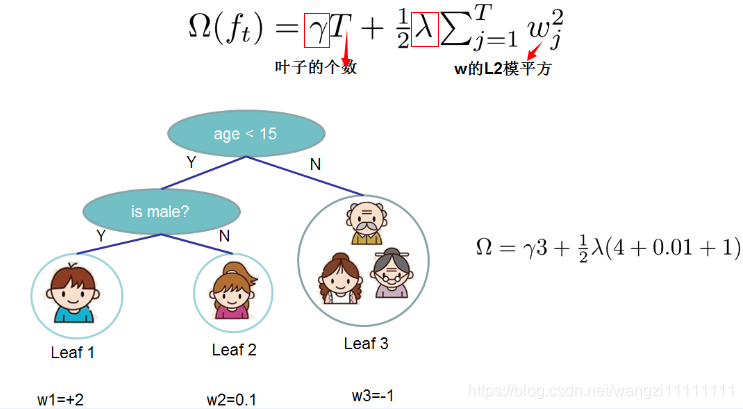
在這種新的定義下,我們可以把目標函數進行如下改寫,其中I被定義為每個葉子上面樣本集合
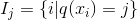
g是一階導數,h是二階導數
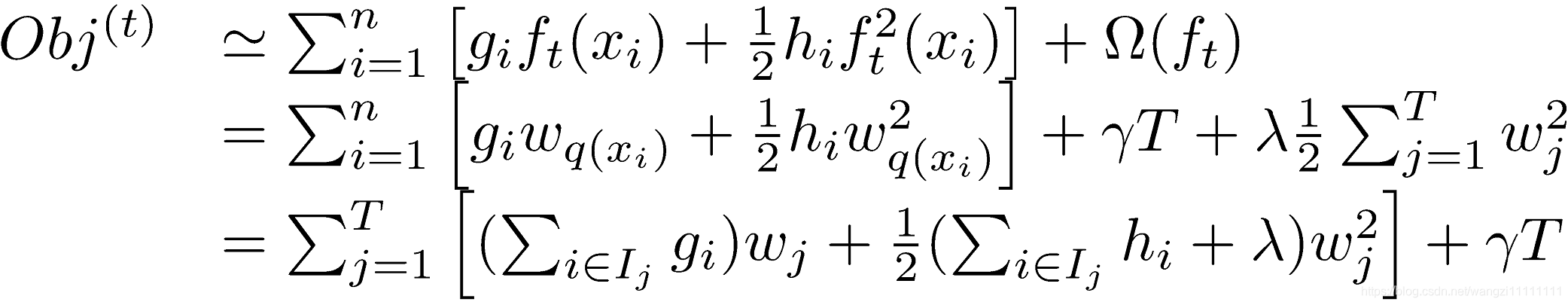
注意:
在上面的公式中,由于誤差項中的第一項是上一個樹所在模型的誤差,與當前新加入的樹無關,所以為一個常數,與目標函數的優化(優化的目標是找到一顆最佳的樹(f(t)),將誤差降低)無關,可以省略,于是誤差項變成了一階導數和二階導數之和;由于最終的樣本都會劃分到每個葉子節點上,所以可以將最開始的樣本的遍歷換成葉子結點的遍歷,從而可以和正則化項中的L2項進行合并,得到最終的公式如上圖。

3.2 分裂節點
論文中給出了兩種分裂節點的方法
(1)貪心法
每一次嘗試去對已有的葉子加入一個分割,且每次分割的目標就是使得損失函數最小
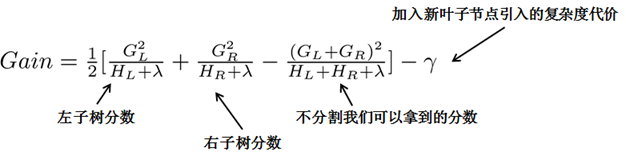
注意:
XGBoost和決策樹的構造準則不同,它不在基于gini系數或者熵,而是通過比較劃分前和劃分后對模型的損失(之前推到的那個目標函數)的影響,來選出最佳的樹節點的劃分。
對于每次擴展,我們還是要枚舉所有可能的分割方案,如何高效地枚舉所有的分割呢?我假設我們要枚舉所有x < a 這樣的條件,對于某個特定的分割a我們要計算a左邊和右邊的導數和
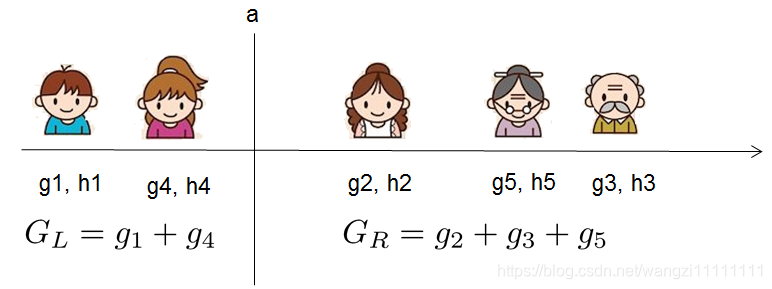
我們可以發現對于所有的a,我們只要做一遍從左到右的掃描就可以枚舉出所有分割的梯度和GL和GR。然后用上面的公式計算每個分割方案的分數就可以了。
觀察這個目標函數,大家會發現第二個值得注意的事情就是引入分割不一定會使得情況變好,因為我們有一個引入新葉子的懲罰項。優化這個目標對應了樹的剪枝, 當引入的分割帶來的增益小于一個閥值的時候,我們可以剪掉這個分割。大家可以發現,當我們正式地推導目標的時候,像計算分數和剪枝這樣的策略都會自然地出現,而不再是一種因為heuristic(啟發式)而進行的操作了。
**下面是論文中的算法 **

(2)近似算法:
主要針對數據太大,不能直接進行計算
3.3 自定義損失函數
(1)常用損失函數
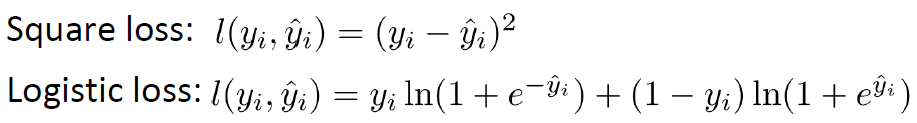
(2)一階導數和二階導數的推到:
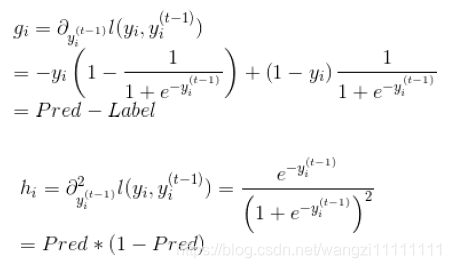
4. XGBoost的使用
(1)官方代碼
#!/usr/bin/python
import numpy as np
import xgboost as xgb
###
# advanced: customized loss function
#
print ('start running example to used customized objective function')dtrain = xgb.DMatrix('../data/agaricus.txt.train')
dtest = xgb.DMatrix('../data/agaricus.txt.test')# note: for customized objective function, we leave objective as default
# note: what we are getting is margin value in prediction
# you must know what you are doing
param = {'max_depth': 2, 'eta': 1, 'silent': 1}
watchlist = [(dtest, 'eval'), (dtrain, 'train')]
num_round = 2# user define objective function, given prediction, return gradient and second order gradient
# this is log likelihood loss
def logregobj(preds, dtrain):labels = dtrain.get_label()preds = 1.0 / (1.0 + np.exp(-preds))grad = preds - labelshess = preds * (1.0-preds)return grad, hess# user defined evaluation function, return a pair metric_name, result
# NOTE: when you do customized loss function, the default prediction value is margin
# this may make builtin evaluation metric not function properly
# for example, we are doing logistic loss, the prediction is score before logistic transformation
# the builtin evaluation error assumes input is after logistic transformation
# Take this in mind when you use the customization, and maybe you need write customized evaluation function
def evalerror(preds, dtrain):labels = dtrain.get_label()# return a pair metric_name, result# since preds are margin(before logistic transformation, cutoff at 0)return 'error', float(sum(labels != (preds > 0.0))) / len(labels)# training with customized objective, we can also do step by step training
# simply look at xgboost.py's implementation of train
bst = xgb.train(param, dtrain, num_round, watchlist, logregobj, evalerror)
(2)XGBoost調參
通用參數
這些參數用來控制XGBoost的宏觀功能。
- booster[默認gbtree]
- 選擇每次迭代的模型,有兩種選擇:gbtree:基于樹的模型 ; gbliner:線性模型
- silent[默認0]
- 當這個參數值為1時,靜默模式開啟,不會輸出任何信息。
- 一般這個參數就保持默認的0,因為這樣能幫我們更好地理解模型
- nthread[默認值為最大可能的線程數]
- 這個參數用來進行多線程控制,應當輸入系統的核數。
- 如果你希望使用CPU全部的核,那就不要輸入這個參數,算法會自動檢測它。
還有兩個參數,XGBoost會自動設置,目前你不用管它。接下來咱們一起看booster參數
booster參數
盡管有兩種booster可供選擇,我這里只介紹tree booster,因為它的表現遠遠勝過linear booster,所以linear booster很少用到
- eta[默認0.3]
- 和GBM中的 learning rate 參數類似。
- 通過減少每一步的權重,可以提高模型的魯棒性。
- 典型值為0.01-0.2。
- min_child_weight[默認1]
- 決定最小葉子節點樣本權重和。
- 和GBM的 min_child_leaf 參數類似,但不完全一樣。XGBoost的這個參數是最小樣本權重的和,而GBM參數是最小樣本總數。
- 這個參數用于避免過擬合。當它的值較大時,可以避免模型學習到局部的特殊樣本。
- 但是如果這個值過高,會導致欠擬合。這個參數需要使用CV來調整。
- max_depth[默認6]
- 和GBM中的參數相同,這個值為樹的最大深度
- 這個值也是用來避免過擬合的。max_depth越大,模型會學到更具體更局部的樣本。
- 需要使用CV函數來進行調優。
- 典型值:3-10
- max_leaf_nodes
- 樹上最大的節點或葉子的數量。
- 可以替代max_depth的作用。因為如果生成的是二叉樹,一個深度為n的樹最多生成n^2個葉子
- 如果定義了這個參數,GBM會忽略max_depth參數。
- gamma[默認0]
- 在節點分裂時,只有分裂后損失函數的值下降了,才會分裂這個節點。Gamma指定了節點分裂所需的最小損失函數下降值。
- 這個參數的值越大,算法越保守。這個參數的值和損失函數息息相關,所以是需要調整的。
- max_delta_step[默認0]
- 這參數限制每棵樹權重改變的最大步長。如果這個參數的值為0,那就意味著沒有約束。如果它被賦予了某個正值,那么它會讓這個算法更加保守。
- 通常,這個參數不需要設置。但是當各類別的樣本十分不平衡時,它對邏輯回歸是很有幫助的。
- 這個參數一般用不到,但是你可以挖掘出來它更多的用處
- subsample[默認1]
- 和GBM中的subsample參數一模一樣。這個參數控制對于每棵樹,隨機采樣的比例。
- 減小這個參數的值,算法會更加保守,避免過擬合。但是,如果這個值設置得過小,它可能會導致欠擬合。
- 典型值:0.5-1
- 典型值:0.5-1
- 和GBM里面的max_features參數類似。用來控制每棵隨機采樣的列數的占比(每一列是一個特征)。
- 典型值:0.5-1
- colsample_bylevel[默認1]
- 用來控制樹的每一級的每一次分裂,對列數的采樣的占比。
- 我個人一般不太用這個參數,因為subsample參數和colsample_bytree參數可以起到相同的作用。但是如果感興趣,可以挖掘這個參數更多的用處。
- lambda[默認1]
- 權重的L2正則化項。(和Ridge regression類似)。
- 這個參數是用來控制XGBoost的正則化部分的。雖然大部分數據科學家很少用到這個參數,但是這個參數在減少過擬合上還是可以挖掘出更多用處的
- alpha[默認1]
- 權重的L1正則化項。(和Lasso regression類似)。
- 可以應用在很高維度的情況下,使得算法的速度更快。
- scale_pos_weight[默認1]
- 在各類別樣本十分不平衡時,把這個參數設定為一個正值,可以使算法更快收斂。
學習目標參數
這個參數用來控制理想的優化目標和每一步結果的度量方法。
- objective[默認reg:linear]
這個參數定義需要被最小化的損失函數。最常用的值有:- binary:logistic 二分類的邏輯回歸,返回預測的概率(不是類別)。
- multi:softmax 使用softmax的多分類器,返回預測的類別(不是概率)。
- 在這種情況下,你還需要多設一個參數:num_class(類別數目)。
- multi:softprob 和multi:softmax參數一樣,但是返回的是每個數據屬于各個類別的概率。
- eval_metric[默認值取決于objective參數的取值]
- 對于有效數據的度量方法。
- 對于回歸問題,默認值是rmse,對于分類問題,默認值是error。
- 典型值有:

- seed(默認0)
- 隨機數的種子
- 設置它可以復現隨機數據的結果,也可以用于調整參數
(3)Python中對XGBoost的使用
- 任務:二分類,存在樣本不均衡問題(scale_pos_weight參數可以加快訓練速度)
def xgboost_predict():import xgboost as xgb#xgboost start heredtest = xgb.DMatrix(test_x)dval = xgb.DMatrix(val_x , label = val_y)dtrain = xgb.DMatrix(x,label = y)params = {'booster':'gbtree','silent':1 ,#設置成1則沒有運行信息輸出,最好是設置為0.#'nthread':7,# cpu 線程數 默認最大'eta': 0.007, # 如同學習率'min_child_weight':3, # 這個參數默認是 1,是每個葉子里面 h 的和至少是多少,對正負樣本不均衡時的 0-1 分類而言#,假設 h 在 0.01 附近,min_child_weight 為 1 意味著葉子節點中最少需要包含 100 個樣本。#這個參數非常影響結果,控制葉子節點中二階導的和的最小值,該參數值越小,越容易 overfitting。'max_depth':6, # 構建樹的深度,越大越容易過擬合'gamma':0.1, # 樹的葉子節點上作進一步分區所需的最小損失減少,越大越保守,一般0.1、0.2這樣子。'subsample':0.7, # 隨機采樣訓練樣本'colsample_bytree':0.7, # 生成樹時進行的列采樣 'lambda':2, # 控制模型復雜度的權重值的L2正則化項參數,參數越大,模型越不容易過擬合。#'alpha':0, # L1 正則項參數#'scale_pos_weight':1, #如果取值大于0的話,在類別樣本不平衡的情況下有助于快速收斂。#'objective': 'multi:softmax', #多分類的問題#'num_class':10, # 類別數,多分類與 multisoftmax 并用'seed':1000, #隨機種子#'eval_metric': 'auc'}watchlist = [(dval,"val"),(dtrain,"train")] xgboost_model = xgb.train(params , dtrain , num_boost_round = 3000 , evals = watchlist)#xgboost_model.save_model("./xgboost.model")#predict the test setxgboost_predict_y = xgboost_model.predict(dtest , ntree_limit = xgboost_model.best_ntree_limit)
- DART:將dropput思想引入XGBoost
import xgboost as xgb
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train')
dtest = xgb.DMatrix('demo/data/agaricus.txt.test')
# specify parameters via map
param = {'booster': 'dart','max_depth': 5, 'learning_rate': 0.1,'objective': 'binary:logistic', 'silent': True,'sample_type': 'uniform','normalize_type': 'tree','rate_drop': 0.1,'skip_drop': 0.5}
num_round = 50
bst = xgb.train(param, dtrain, num_round)
# make prediction
# ntree_limit must not be 0
preds = bst.predict(dtest, ntree_limit=num_round)- XGBoost在sklearn中的例子:
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.datasets import make_hastie_10_2
import xgboost as xgb
#記錄程序運行時間
import time start_time = time.time()
X, y = make_hastie_10_2(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)##test_size測試集合所占比例#xgb矩陣賦值
xgb_train = xgb.DMatrix(X_train, label=y_train)
xgb_test = xgb.DMatrix(X_test,label=y_test)##參數
params={
'booster':'gbtree',
'silent':1 ,#設置成1則沒有運行信息輸出,最好是設置為0.
#'nthread':7,# cpu 線程數 默認最大
'eta': 0.007, # 如同學習率
'min_child_weight':3,
# 這個參數默認是 1,是每個葉子里面 h 的和至少是多少,對正負樣本不均衡時的 0-1 分類而言
#,假設 h 在 0.01 附近,min_child_weight 為 1 意味著葉子節點中最少需要包含 100 個樣本。
#這個參數非常影響結果,控制葉子節點中二階導的和的最小值,該參數值越小,越容易 overfitting。
'max_depth':6, # 構建樹的深度,越大越容易過擬合
'gamma':0.1, # 樹的葉子節點上作進一步分區所需的最小損失減少,越大越保守,一般0.1、0.2這樣子。
'subsample':0.7, # 隨機采樣訓練樣本
'colsample_bytree':0.7, # 生成樹時進行的列采樣
'lambda':2, # 控制模型復雜度的權重值的L2正則化項參數,參數越大,模型越不容易過擬合。
#'alpha':0, # L1 正則項參數
#'scale_pos_weight':1, #如果取值大于0的話,在類別樣本不平衡的情況下有助于快速收斂。
#'objective': 'multi:softmax', #多分類的問題
#'num_class':10, # 類別數,多分類與 multisoftmax 并用
'seed':1000, #隨機種子
#'eval_metric': 'auc'
}plst = list(params.items())
num_rounds = 100 # 迭代次數watchlist = [(xgb_train, 'train'),(xgb_test, 'val')]#訓練模型并保存
# early_stopping_rounds 當設置的迭代次數較大時,early_stopping_rounds 可在一定的迭代次數內準確率沒有提升就停止訓練
model = xgb.train(plst, xgb_train, num_rounds, watchlist,early_stopping_rounds=100)#model.save_model('./model/xgb.model') # 用于存儲訓練出的模型
print("best best_ntree_limit",model.best_ntree_limit)y_pred = model.predict(xgb_test,ntree_limit=model.best_ntree_limit)
print('error=%f' % ( sum(1 for i in range(len(y_pred)) if int(y_pred[i]>0.5)!=y_test[i]) /float(len(y_pred))))
#輸出運行時長
cost_time = time.time()-start_time
print("xgboost success!",'\n',"cost time:",cost_time,"(s)......")```
--(介紹,環境配置,基本語法,注釋))


--(數據類型,變量類型,變量作用域,常量,修飾符類型))

--(存儲類,運算符,循環,判斷))

--(函數、數字、數組、字符串))


--(指針,引用))

--(時間,輸入輸出,數據結構))


--(類))

--(繼承、重載、多態、虛函數))

--(數據抽象、數據封裝、接口))