此文后續會改為粉絲可見,所以喜歡的請提前關注。
你的點贊和評論是我創作的最大動力,謝謝。
3、單機實現
3.1、數據庫概述
redis服務器將所有數據庫都保存在redis/redisServer中,數組db存放所有數據庫,每一項是一個redisdb結構。dbnum代表數據庫數量。
客戶端有一個指針指向當前數據庫,可以切換,也就是移動指針。
3.1.1鍵空間
現在稍微介紹一下redisdb結構,它的字典保存了所有鍵值對
鍵空間的鍵也就是數據庫的鍵, 每個鍵都是一個字符串對象。
鍵空間的值也就是數據庫的值, 每個值可以是字符串對象、列表對象、哈希表對象、集合對象、有序集合對象
所有數據庫的操作,添加一個鍵值對, 刪除一個鍵值對, 獲取某個鍵值對, 等等,都是通過對鍵空間字典進行操作來實現的。
3.1.2維護
讀寫鍵空間的時候,服務器會執行一些額外操作,比如:
- 讀一個鍵后(讀操作寫操作都要對鍵讀取),?會根據鍵是否存在, 更新鍵空間命中(hit)次數或不命中(miss)次數。
- 讀取一個鍵后, 服務器會更新鍵的 LRU (最后一次使用)時間, 這個值可以用于計算鍵的閑置時間。
- 如果服務器在讀一個鍵時, 該鍵已經過期, 服務器會刪除這個鍵, 然后執行其他操作。
- 如果客戶使用?WATCH?監視某個鍵,在對這個鍵進行修改之后, 會將這個鍵記為臟(dirty),讓事務程序知到這個鍵被修改
- 服務器每次修改一個鍵之后, 都會對臟(dirty)鍵計數器的值增一, 這個計數器會觸發服務器的持久化以及復制操作執行
- 如果服務器開啟了數據庫通知功能, 那么在對鍵進行修改之后, 服務器將按配置發送相應的數據庫通知。
3.1.3時間
用戶可以給某個鍵設置生存時間,過期時間是一個UNIX時間戳,到時間自動刪除這個鍵。
redisdb結構的expires字典保存了所有的鍵的過期時間,我們稱這個字典為過期字典。
3.1.4三種過期鍵刪除策略
1)定時刪除:創建一個定時器,到時間立即執行刪除操作(對內存友好,因為能保證過期了立馬刪除,但是對cpu不友好)
2)惰性刪除:鍵過期不管,每次獲取鍵時檢查是否過期,過期就刪除(對cpu友好,但是只有在使用的時候才可能刪除,對內存不友好)
3)定期刪除:隔一段時間檢查一次(具體算法決定檢查多少刪多少,需要合理設置)
3.1.5淘汰策略
當Redis占用內存超出最大限制 (maxmemory) 時,可采用如下策略 (maxmemory-policy) ,讓Redis淘汰一些數據,以騰出空間繼續提供讀寫服務 :
noeviction: 對可能導致增大內存的命令返回錯誤 (大多數寫命令,DEL除外) ;
volatile-ttl: 在設置了過期時間的key中,選擇剩余壽命 (TTL) 最短的key,將其淘汰;
volatile-lru: 在設置了過期時間的key中,選擇最少使用的key (RU) ,將其淘汰;
volatile-random: 在設置了過期時間的key中,隨機選擇一些key,將其淘汰;
allkeys-1Lru: 在所有的key中,選擇最少使用的key (LRU) ,將其淘汰;
allkeys-random: 在所有的key中,隨機選擇一些key,將其淘汰;
?
3.2、持久化
因為redis是內存數據庫,他把數據都存在內存里,所以要想辦法實現持久化功能。
3.2.1、RDB
RDB持久化可以手動執行,也可以配置定期執行,可以把某個時間的數據狀態保存到RDB文件中,反之,我們可以用RDB文件還原數據庫狀態。
? ? 生成
有兩個命令可以生成RDB文件:
- SAVE?命令由服務器進程直接執行保存操作,所以該命令會阻塞服務器,服務器不能接受其他指令。
- BGSAVE?命令由子進程執行保存操作,所以該命令不會阻塞服務器,服務器可以接受其他指令。。
禁止BGSAVE和SAVE同時執行,也就是說執行其中一個就會拒絕另一個,這是為了避免父進程和子進程同時執行兩個rdbsave,防止產生競爭條件。
? ? 載入
? ? RDB載入工作是服務器啟動時自動執行的。
? ? 自動保存
用戶可以通過save選項設置多個保存條件,服務器狀態中會保存所有用?save?選項設置的保存條件,當任意一個保存條件被滿足時,服務器會自動執行?BGSAVE?命令。
比如
save 900 1
save 300 10
滿足:服務器在900秒之內被修改至少一次或者300秒內修改至少十次。就會執行BGSAVE。
?
當服務器啟動時,用戶可以通過指定配置文件或者傳入啟動參數來設置save選項,服務器會把條件放到一個結構體里,結構體有一個數組,保存了所有條件。
?
serverCron函數默認100毫秒檢查一次,他會遍歷數組依次檢查,符合條件就會執行BGSAVE。
? ? RDB文件結構
一個完整 RDB 文件所包含的各個部分:

REDIS,長度5字節, 保存著?"REDIS"?五個字符。 通過這五個字符, 可以在載入文件時, 快速檢查載入文件是否 RDB 文件。
db_version?,長度?4?字節, 它的值是一個字符串表示的整數, 這個整數記錄了 RDB 文件的版本號
databases?部分包含著零個或任意多個數據庫, 以及各個數據庫中的鍵值對數據
EOF?常量的長度為?1?字節, 這個常量標志著 RDB 文件正文內容的結束
check_sum?是一個?8?字節長的無符號整數, 保存著一個校驗和,以此來檢查 RDB 文件是否出錯或損壞
我并不想深入探究databases的組成。就是知道
- RDB 文件是一個經過壓縮的二進制文件,由多個部分組成。
- 對于不同類型的鍵值對, RDB 文件會使用不同的方式來保存它們即可。
3.2.2、AOF
AOF持久化是通過保存服務器執行的命令來記錄狀態的。還原的時候再執行一遍即可。
功能的實現可以分為命令追加、文件寫入、文件同步三個步驟。
?
當 AOF 持久化功能處于打開狀態時, 服務器在執行完一個寫命令之后, 會以協議格式將被執行的寫命令追加到服務器狀態的?aof_buf?緩沖區的末尾:
struct redisServer {// ...// AOF 緩沖區sds aof_buf;// ...
};Redis 服務器進程就是一個事件循環
循環中的文件事件負責接收客戶端的命令請求, 以及向客戶端發送命令回復,
而時間事件則負責執行像?serverCron?函數這樣需要定時運行的函數。
因為服務器在處理文件事件時可能會執行寫命令, 使得一些內容被追加到?aof_buf?緩沖區里面, 所以在服務器每次結束一個事件循環之前, 它都會調用?flushAppendOnlyFile?函數, 考慮是否需要將?aof_buf?緩沖區中的內容寫入和保存到 AOF 文件里面, 這個過程可以用偽代碼表示:
def eventLoop():while True:# 處理文件事件,接收命令請求以及發送命令回復# 處理命令請求時可能會有新內容被追加到 aof_buf 緩沖區中processFileEvents()# 處理時間事件processTimeEvents()# 考慮是否要將 aof_buf 中的內容寫入和保存到 AOF 文件里面flushAppendOnlyFile()flushAppendOnlyFile?函數的行為由服務器配置的?appendfsync?選項的值來決定

值為?always?時, 服務器在每個事件循環都要將?aof_buf?緩沖區中的所有內容寫入到 AOF 文件并且同步 AOF 文件, 所以?always?的效率最慢的一個, 但從安全性來說,?always?是最安全的, 因為即使出現故障停機, AOF 持久化也只會丟失一個事件循環中所產生的命令數據。
值為?everysec?時, 服務器在每個事件循環都要將?aof_buf?緩沖區中的所有內容寫入到 AOF 文件, 每隔超過一秒就要在子線程中對 AOF 文件進行一次同步: 從效率上來講,?everysec?模式足夠快, 并且就算出現故障停機, 數據庫也只丟失一秒鐘的命令數據。
值為?no?時, 服務器在每個事件循環都要將?aof_buf?緩沖區中的所有內容寫入到 AOF 文件, 至于何時對 AOF 文件進行同步, 則由操作系統控制。
因為處于?no?模式下的?flushAppendOnlyFile?調用無須執行同步操作, 所以該模式下的 AOF 文件寫入速度總是最快的, 不過因為這種模式會在系統緩存中積累一段時間的寫入數據, 所以該模式的單次同步時長通常是三種模式中時間最長的: 從平攤操作的角度來看,no?模式和?everysec?模式的效率類似, 當出現故障停機時, 使用?no?模式的服務器將丟失上次同步 AOF 文件之后的所有寫命令數據。
? ? 重寫
AOF持久化是保存了一堆命令來恢復數據庫,隨著時間流逝,存的會越來越多,如果不加以控制,文件過大可能影響服務器甚至計算機。而且文件過大,恢復時需要時間也太長。
所以redis提供了重寫功能,寫出的新文件不會包含任何浪費時間的冗余命令。
接下來,我們就介紹重寫的原理。
其實重寫不會對現有的AOF文件進行讀取分析等操作,而是通過當前服務器的狀態來實現。
# 假設服務器對鍵list執行了以下命令s;
127.0.0.1:6379> RPUSH list "A" "B"
(integer) 2
127.0.0.1:6379> RPUSH list "C"
(integer) 3
127.0.0.1:6379> RPUSH list "D" "E"
(integer) 5
127.0.0.1:6379> LPOP list
"A"
127.0.0.1:6379> LPOP list
"B"
127.0.0.1:6379> RPUSH list "F" "G"
(integer) 5
127.0.0.1:6379> LRANGE list 0 -1
1) "C"
2) "D"
3) "E"
4) "F"
5) "G"
127.0.0.1:6379> 當前列表鍵list在數據庫中的值就為["C", "D", "E", "F", "G"]。要使用盡量少的命令來記錄list鍵的狀態,最簡單的方式不是去讀取和分析現有AOF文件的內容,,而是直接讀取list鍵在數據庫中的當前值,然后用一條RPUSH list "C" "D" "E" "F" "G"代替前面的6條命令。
- 偽代碼表示如下
def AOF_REWRITE(tmp_tile_name):f = create(tmp_tile_name)# 遍歷所有數據庫for db in redisServer.db:# 如果數據庫為空,那么跳過這個數據庫if db.is_empty(): continue# 寫入 SELECT 命令,用于切換數據庫f.write_command("SELECT " + db.number)# 遍歷所有鍵for key in db:# 如果鍵帶有過期時間,并且已經過期,那么跳過這個鍵if key.have_expire_time() and key.is_expired(): continueif key.type == String:# 用 SET key value 命令來保存字符串鍵value = get_value_from_string(key)f.write_command("SET " + key + value)elif key.type == List:# 用 RPUSH key item1 item2 ... itemN 命令來保存列表鍵item1, item2, ..., itemN = get_item_from_list(key)f.write_command("RPUSH " + key + item1 + item2 + ... + itemN)elif key.type == Set:# 用 SADD key member1 member2 ... memberN 命令來保存集合鍵member1, member2, ..., memberN = get_member_from_set(key)f.write_command("SADD " + key + member1 + member2 + ... + memberN)elif key.type == Hash:# 用 HMSET key field1 value1 field2 value2 ... fieldN valueN 命令來保存哈希鍵field1, value1, field2, value2, ..., fieldN, valueN =\get_field_and_value_from_hash(key)f.write_command("HMSET " + key + field1 + value1 + field2 + value2 +\... + fieldN + valueN)elif key.type == SortedSet:# 用 ZADD key score1 member1 score2 member2 ... scoreN memberN# 命令來保存有序集鍵score1, member1, score2, member2, ..., scoreN, memberN = \get_score_and_member_from_sorted_set(key)f.write_command("ZADD " + key + score1 + member1 + score2 + member2 +\... + scoreN + memberN)else:raise_type_error()# 如果鍵帶有過期時間,那么用 EXPIREAT key time 命令來保存鍵的過期時間if key.have_expire_time():f.write_command("EXPIREAT " + key + key.expire_time_in_unix_timestamp())# 關閉文件f.close()? ? AOF后臺重寫
aof_rewrite函數可以創建新的AOF文件,但是這個函數會進行大量的寫入操作,所以調用這個函數的線程被長時間的阻塞,因為服務器使用單線程來處理命令請求;所以如果直接是服務器進程調用AOF_REWRITE函數的話,那么重寫AOF期間,服務器將無法處理客戶端發送來的命令請求;
Redis不希望AOF重寫會造成服務器無法處理請求,所以將AOF重寫程序放到子進程(后臺)里執行。這樣處理的好處是:?
1)子進程進行AOF重寫期間,主進程可以繼續處理命令請求;
2)子進程帶有主進程的數據副本,使用子進程而不是線程,可以避免在鎖的情況下,保證數據的安全性。
還有一個問題,可能重寫的時候又有新的命令過來,造成信息不對等,所以redis設置了一個緩沖區,重寫期間把命令放到重寫緩沖區。
?
? 總結
AOF重寫的目的是為了解決AOF文件體積膨脹的問題,使用更小的體積來保存數據庫狀態,整個重寫過程基本上不影響Redis主進程處理命令請求;
AOF重寫其實是一個有歧義的名字,實際上重寫工作是針對數據庫的當前狀態來進行的,重寫過程中不會讀寫、也不適用原來的AOF文件;
AOF可以由用戶手動觸發,也可以由服務器自動觸發。
?
3.3、事件
redis服務器是一個事件驅動程序。
需要處理兩類事件:
1)文件事件:redis是通過套接字與客戶端或者其他服務器連接的,而文件事件就是服務器對套接字操作的抽象。
2)時間事件:服務器對一些定時操作的抽象。
3.3.1、文件事件
redis基于reactor模式開發了自己的網絡事件處理器,這個處理器被稱作文件事件處理器,它使用IO多路復用程序來同時監聽多個套接字, 并根據套接字目前執行的任務來為套接字關聯不同的事件處理器,當被監聽的套接字準備好執行連接應答(accept)、讀取(read)、寫入(write)、關閉(close)等操作時, 與操作相對應的文件事件就會產生, 這時文件事件處理器就會調用套接字之前關聯好的事件處理器來處理這些事件。
雖然文件事件處理器以單線程方式運行, 但通過使用 I/O 多路復用程序來監聽多個套接字, 文件事件處理器既實現了高性能的網絡通信模型, 又可以很好地與 Redis 服務器中其他同樣以單線程方式運行的模塊進行對接, 這保持了 Redis 內部單線程設計的簡單性。
文件事件處理器的構成:
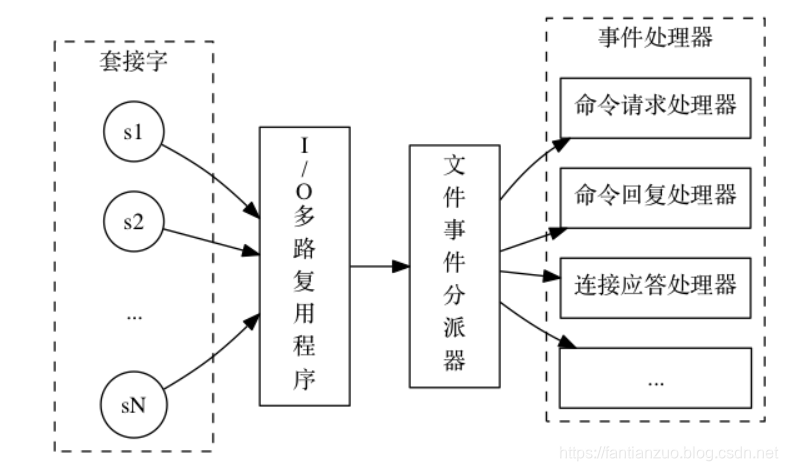
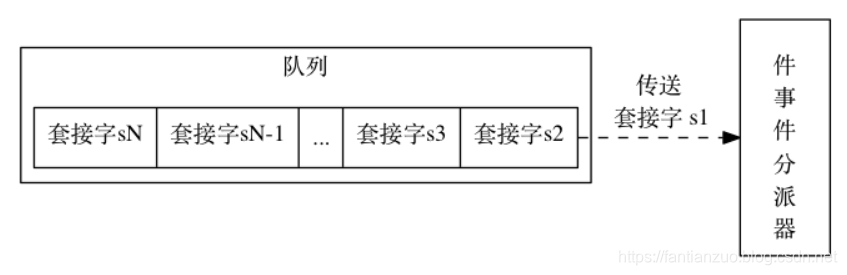
I/O 多路復用程序負責監聽多個套接字, 并向文件事件分派器傳送那些產生了事件的套接字。
?I/O 多路復用程序會把所有產生事件的套接字放到一個隊列, 以有序(sequentially)、同步(synchronously)、每次一個套接字的方式,向文件事件分派器傳送套接字。
I/O 多路復用程序可以監聽多個套接字的?ae.h/AE_READABLE?事件和?ae.h/AE_WRITABLE?事件
1)當套接字變得可讀時(客戶端對套接字執行?write?操作,或者執行?close?操作), 或者有新的可應答(acceptable)套接字出現時(客戶端對服務器的監聽套接字執行?connect?操作), 套接字產生?AE_READABLE?事件。
2)當套接字變得可寫時(客戶端對套接字執行?read?操作), 套接字產生?AE_WRITABLE?事件。
如果一個套接字又可讀又可寫的話, 那么服務器將先讀套接字, 后寫套接字。
下面介紹各種處理器:
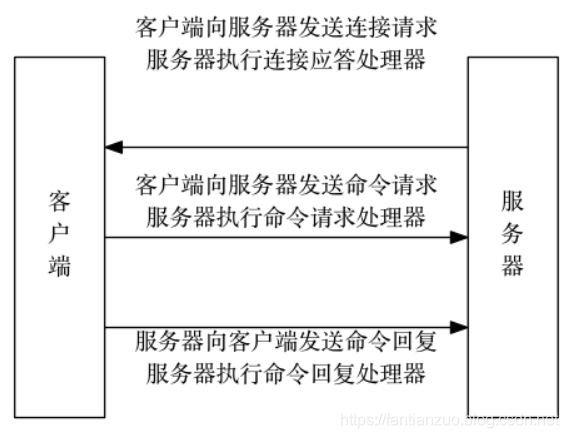
1)連接應答處理器:服務器進行初始化時, 程序會將連接應答處理器和服務器監聽套接字的?AE_READABLE?事件關聯, 當有客戶端連接(connect)服務器監聽套接字的時候, 套接字就會產生?AE_READABLE?事件, 引發連接應答處理器執行, 并執行相應的套接字應答操作。
2)命令請求處理器:客戶端連接到服務器后, 服務器會將客戶端套接字的?AE_READABLE?事件和命令請求處理器關聯起來, 當客戶端發送命令請求時, 套接字就會產生?AE_READABLE?事件, 引發命令請求處理器執行, 并執行相應的套接字讀入操作
3)命令回復處理器:服務器有命令回復需要傳送給客戶端, 服務器會將客戶端套接字的?AE_WRITABLE?事件和命令回復處理器關聯起來, 當客戶端準備好接收服務器傳回的命令回復時, 就會產生?AE_WRITABLE?事件, 引發命令回復處理器執行, 并執行相應的套接字寫入操作。
一次完整的連接事件實例:
3.3.2、時間事件
redis時間事件可以分為兩類:定時事件、周期性事件,他們的特點就像他們的名字一樣。
而一個時間事件主要有三部分:
id:服務器為時間事件創建的全局唯一id,按時間遞增,越新的越大
when:unix時間戳,記錄到達時間
timeProc:時間事件處理器,是一個函數,時間事件到達時,服務器就會調用處理器來處理事件。
目前版本的redis只使用周期性事件
來看看實現:
服務器把所有時間事件放在一個鏈表中,每當時間事件執行器執行時,它就遍歷鏈表,調用相應的事件處理器。
但是注意:鏈表是無序的,不按when屬性來排序,當時間事件執行器運行時,必須遍歷整個鏈表。但是,無序鏈表并不影響時間事件處理器的性能,因為在目前版本中,redis服務器只使用serverCron一個時間事件,就算在benchmark模式下也只有兩個事件,服務器幾乎是把鏈表退化成指針使用了。
?
3.3.3、事件的調度和執行
?
文件事件和時間事件之間是合作關系, 服務器會輪流處理這兩種事件,對兩種事件的處理都是同步、有序、原子地進行的,處理事件的過程中也不會進行搶占,所以時間事件的實際處理時間通常會比設定的到達時間晚一些。
大概流程為:
是否關閉服務器?---->等待文件事件產生---->處理已經產生的文件事件---->處理已經達到的時間事件---->是否關閉服務器?........
?
3.4、客戶端
redis服務器是典型的一對多服務器,通過使用由IO多路復用技術實現的文件事件處理器,redis服務器使用了單線程單進程的方式來處理請求。
3.4.1客戶端的屬性
- 描述符
客戶端狀態的?fd?屬性記錄了客戶端正在使用的套接字描述符:
typedef struct redisClient {// ...int fd;// ...
} redisClient;- 偽客戶端
fd?值為?-1?: 偽客戶端處理的命令請求來源于 AOF 文件或者 Lua 腳本, 而不是網絡, 所以這種客戶端不需要套接字連接。 - 普通客戶端?
fd?值為大于?-1?的整數: 普通客戶端使用套接字來與服務器進行通訊, 所以服務器會用?fd?屬性來記錄客戶端套接字的描述符。?
?
- 標志
客戶端的標志屬性?flags?記錄了客戶端的角色(role), 以及客戶端目前所處的狀態:
typedef struct redisClient {// ...int flags;// ...} redisClient;flags?屬性的值可以是單個標志:
flags = <flag>
也可以是多個標志的二進制或, 比如:
flags = <flag1> | <flag2> | ...
每個標志使用一個常量表示, 一部分標志記錄了客戶端的角色:
- 在主從服務器進行復制操作時, 主服務器會成為從服務器的客戶端, 而從服務器也會成為主服務器的客戶端。?
REDIS_MASTER?標志表示客戶端代表的是一個主服務器,?REDIS_SLAVE?標志表示客戶端代表的是一個從服務器。 REDIS_LUA_CLIENT?標識表示客戶端是專門用于處理 Lua 腳本里面包含的 Redis 命令的偽客戶端。
另一部分標志記錄了客戶端目前所處的狀態:
以下內容為摘抄
REDIS_MONITOR?標志表示客戶端正在執行?MONITOR?命令。REDIS_UNIX_SOCKET?標志表示服務器使用 UNIX 套接字來連接客戶端。REDIS_BLOCKED?標志表示客戶端正在被?BRPOP?、?BLPOP?等命令阻塞。REDIS_UNBLOCKED?標志表示客戶端已經從?REDIS_BLOCKED?標志所表示的阻塞狀態中脫離出來,
不再阻塞。?REDIS_UNBLOCKED?標志只能在?REDIS_BLOCKED?標志已經打開的情況下使用。REDIS_MULTI?標志表示客戶端正在執行事務。REDIS_DIRTY_CAS?標志表示事務使用?WATCH?命令監視的數據庫鍵已經被修改,?
REDIS_DIRTY_EXEC?標志表示事務在命令入隊時出現了錯誤,
以上兩個標志都表示事務的安全性已經被破壞, 只要這兩個標記中的任意一個被打開,?
EXEC?命令必然會執行失敗。
這兩個標志只能在客戶端打開了?REDIS_MULTI?標志的情況下使用。REDIS_CLOSE_ASAP?標志表示客戶端的輸出緩沖區大小超出了服務器允許的范圍,
服務器會在下一次執行?serverCron?函數時關閉這個客戶端,
以免服務器的穩定性受到這個客戶端影響。
積存在輸出緩沖區中的所有內容會直接被釋放, 不會返回給客戶端。REDIS_CLOSE_AFTER_REPLY?標志表示有用戶對這個客戶端執行了?CLIENT_KILL?命令,
或者客戶端發送給服務器的命令請求中包含了錯誤的協議內容。
服務器會將客戶端積存在輸出緩沖區中的所有內容發送給客戶端, 然后關閉客戶端。REDIS_ASKING?標志表示客戶端向集群節點(運行在集群模式下的服務器)發送了?ASKING?命令。REDIS_FORCE_AOF?標志強制服務器將當前執行的命令寫入到 AOF 文件里面,
REDIS_FORCE_REPL?標志強制主服務器將當前執行的命令復制給所有從服務器。
執行?PUBSUB?命令會使客戶端打開?REDIS_FORCE_AOF?標志,
執行?SCRIPT_LOAD?命令會使客戶端打開?
REDIS_FORCE_AOF標志和?REDIS_FORCE_REPL?標志。在主從服務器進行命令傳播期間, 從服務器需要向主服務器發送?REPLICATION ACK?命令,
在發送這個命令之前, 從服務器必須打開主服務器對應的客戶端的?
REDIS_MASTER_FORCE_REPLY?標志, 否則發送操作會被拒絕執行。以上提到的所有標志都定義在?redis.h?文件里面。
PUBSUB?命令和?SCRIPT?LOAD?命令的特殊性
通常情況下, Redis 只會將那些對數據庫進行了修改的命令寫入到 AOF 文件, 并復制到各個從服務器: 如果一個命令沒有對數據庫進行任何修改, 那么它就會被認為是只讀命令, 這個命令不會被寫入到 AOF 文件, 也不會被復制到從服務器。
以上規則適用于絕大部分 Redis 命令, 但?PUBSUB?命令和?SCRIPT_LOAD?命令是其中的例外。
PUBSUB?命令雖然沒有修改數據庫, 但?PUBSUB?命令向頻道的所有訂閱者發送消息這一行為帶有副作用, 接收到消息的所有客戶端的狀態都會因為這個命令而改變。 因此, 服務器需要使用?REDIS_FORCE_AOF?標志, 強制將這個命令寫入 AOF 文件, 這樣在將來載入 AOF 文件時, 服務器就可以再次執行相同的?PUBSUB?命令, 并產生相同的副作用。
SCRIPT_LOAD?命令的與?PUBSUB?命令類似
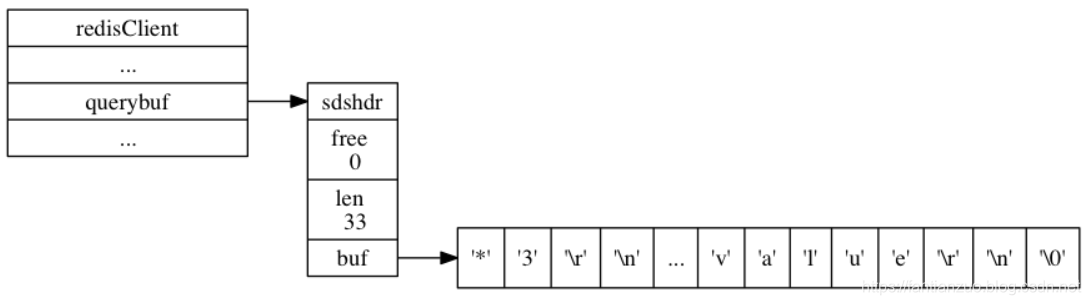
3.4.2輸入緩沖區
客戶端狀態的輸入緩沖區用于保存客戶端發送的命令請求:
typedef struct redisClient {// ...sds querybuf;// ...} redisClient;?redisClient 實例:
3.4.3命令相關
在服務器將客戶端發送的命令請求保存到客戶端狀態的?querybuf?屬性之后, 服務器將對命令請求的內容進行分析, 并將得出的命令參數以及命令參數的個數分別保存到客戶端狀態的?argv?屬性和?argc?屬性:
typedef struct redisClient {// ...robj **argv;int argc;// ...} redisClient;argv?屬性是一個數組, 數組中的每個項都是一個字符串對象: 其中?argv[0]?是要執行的命令, 而之后的其他項則是傳給命令的參數。
argc?屬性則負責記錄?argv?數組的長度。
3.3.4實現函數
?
當服務器從協議內容中分析并得出?argv?屬性和?argc?屬性的值之后, 服務器將根據項?argv[0]?的值, 在命令表中查找命令所對應的命令實現函數。
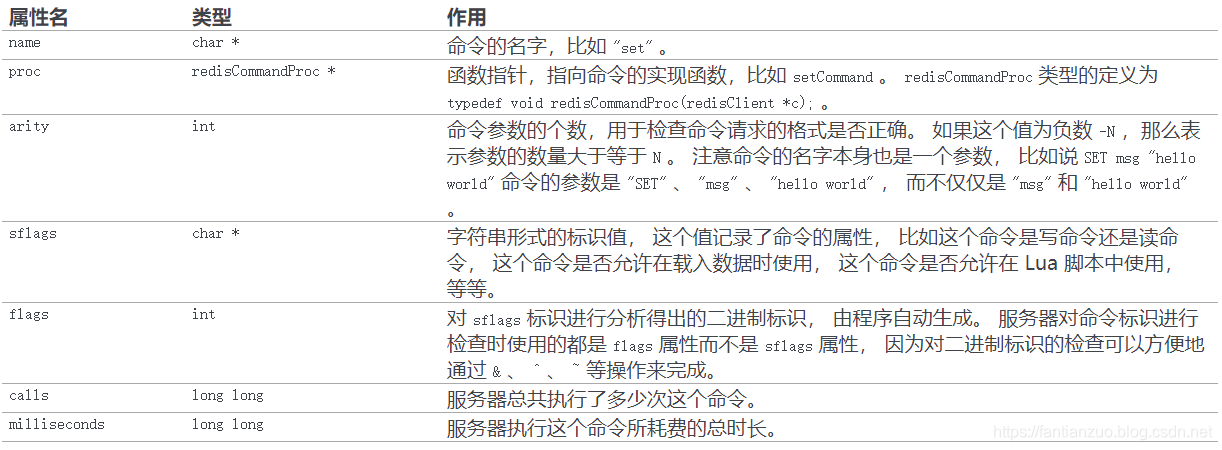
(命令表是一個字典,字典的鍵是一個 SDS 結構, 保存了命令的名字, 字典的值是命令所對應的?redisCommand?結構, 這個結構保存了命令的實現函數、 命令的標志、 命令應該給定的參數個數、 命令的總執行次數和總消耗時長等統計信息。)
3.3.5、輸出緩沖區
執行命令所得的命令回復會被保存在客戶端狀態的輸出緩沖區里面, 每個客戶端都有兩個輸出緩沖區:
- 固定大小的緩沖區用于保存那些長度比較小的回復, 比如?
OK?、簡短的字符串值、整數值、錯誤回復,等等。 - 可變大小的緩沖區用于保存那些長度比較大的回復, 比如一個非常長的字符串值, 一個由很多項組成的列表, 一個包含了很多元素的集合, 等等。
3.3.6、其它
客戶端狀態的?authenticated?屬性用于記錄客戶端是否通過了身份驗證,還有幾個和時間有關的屬性,敘述是一件挺無聊的事情,不再寫。
?
3.4、命令的執行過程
3.4.1發送命令請求
當用戶在客戶端中鍵入一個命令請求時, 客戶端會將這個命令請求轉換成協議格式, 然后通過連接到服務器的套接字, 將協議格式的命令請求發送給服務器。
3.4.2讀取命令請求
當客戶端與服務器之間的連接套接字因為客戶端的寫入而變得可讀時, 服務器將調用命令請求處理器來執行以下操作:
- 讀取套接字中協議格式的命令請求, 并將其保存到客戶端狀態的輸入緩沖區里面。
- 對輸入緩沖區中的命令請求進行分析, 提取出命令請求中包含的命令參數, 以及命令參數的個數, 然后分別將參數和參數個數保存到客戶端狀態的?
argv?屬性和?argc?屬性里面。 - 調用命令執行器, 執行客戶端指定的命令。
3.4.3命令執行器:查找命令實現
命令執行器要做的第一件事就是根據客戶端狀態的?argv[0]?參數, 在命令表(command table)中查找參數所指定的命令, 并將找到的命令保存到客戶端狀態的?cmd?屬性里面。
命令表是一個字典, 字典的鍵是一個個命令名字,比如?"set"?、?"get"?、?"del"?,等等; 而字典的值是一個個?redisCommand?結構, 每個?redisCommand?結構記錄了一個 Redis 命令的實現信息。
命令名字的大小寫不影響命令表的查找結果
因為命令表使用的是大小寫無關的查找算法, 無論輸入的命令名字是大寫、小寫或者混合大小寫, 只要命令的名字是正確的, 就能找到相應的 redisCommand 結構。
比如說, 無論用戶輸入的命令名字是 "SET" 、 "set" 、 "SeT" 又或者 "sEt" , 命令表返回的都是同一個 redisCommand 結構。
redis> SET msg "hello world"
OKredis> set msg "hello world"
OKredis> SeT msg "hello world"
OKredis> sEt msg "hello world"
OK3.4.4命令執行器:執行預備操作
到目前為止, 服務器已經將執行命令所需的命令實現函數(保存在客戶端狀態的?cmd?屬性)、參數(保存在客戶端狀態的?argv?屬性)、參數個數(保存在客戶端狀態的?argc?屬性)都收集齊了, 但是在真正執行命令之前, 程序還需要進行一些預備操作, 從而確保命令可以正確、順利地被執行, 這些操作包括:
- 檢查客戶端狀態的?
cmd?指針是否指向?NULL?, 如果是的話, 那么說明用戶輸入的命令名字找不到相應的命令實現, 服務器不再執行后續步驟, 并向客戶端返回一個錯誤。 - 根據客戶端?
cmd?屬性指向的?redisCommand?結構的?arity?屬性, 檢查命令請求所給定的參數個數是否正確, 當參數個數不正確時, 不再執行后續步驟, 直接向客戶端返回一個錯誤。 比如說, 如果?redisCommand?結構的?arity?屬性的值為?-3?, 那么用戶輸入的命令參數個數必須大于等于?3?個才行。 - 檢查客戶端是否已經通過了身份驗證, 未通過身份驗證的客戶端只能執行?AUTH?命令, 如果未通過身份驗證的客戶端試圖執行除?AUTH?命令之外的其他命令, 那么服務器將向客戶端返回一個錯誤。
- 如果服務器打開了?
maxmemory?功能, 那么在執行命令之前, 先檢查服務器的內存占用情況, 并在有需要時進行內存回收, 從而使得接下來的命令可以順利執行。 如果內存回收失敗, 那么不再執行后續步驟, 向客戶端返回一個錯誤。 - 如果服務器上一次執行?BGSAVE?命令時出錯, 并且服務器打開了?
stop-writes-on-bgsave-error?功能, 而且服務器即將要執行的命令是一個寫命令, 那么服務器將拒絕執行這個命令, 并向客戶端返回一個錯誤。 - 如果客戶端當前正在用?SUBSCRIBE?命令訂閱頻道, 或者正在用?PSUBSCRIBE?命令訂閱模式, 那么服務器只會執行客戶端發來的?SUBSCRIBE?、?PSUBSCRIBE?、?UNSUBSCRIBE?、?PUNSUBSCRIBE?四個命令, 其他別的命令都會被服務器拒絕。
- 如果服務器正在進行數據載入, 那么客戶端發送的命令必須帶有?
l?標識(比如?INFO?、?SHUTDOWN?、?PUBLISH?,等等)才會被服務器執行, 其他別的命令都會被服務器拒絕。 - 如果服務器因為執行 Lua 腳本而超時并進入阻塞狀態, 那么服務器只會執行客戶端發來的?SHUTDOWN nosave?命令和?SCRIPT KILL?命令, 其他別的命令都會被服務器拒絕。
- 如果客戶端正在執行事務, 那么服務器只會執行客戶端發來的?EXEC?、?DISCARD?、?MULTI?、?WATCH?四個命令, 其他命令都會被放進事務隊列中。
- 如果服務器打開了監視器功能, 那么服務器會將要執行的命令和參數等信息發送給監視器。
當完成了以上預備操作之后, 服務器就可以開始真正執行命令了。
3.4.5命令執行器:調用命令的實現函數
在前面的操作中, 服務器已經將要執行命令的實現保存到了客戶端狀態的?cmd?屬性里面, 并將命令的參數和參數個數分別保存到了客戶端狀態的?argv?屬性和?argc?屬性里面, 當服務器決定要執行命令時, 它只要執行以下語句就可以了:
// client 是指向客戶端狀態的指針client->cmd->proc(client);因為執行命令所需的實際參數都已經保存到客戶端狀態的?argv?屬性里面了, 所以命令的實現函數只需要一個指向客戶端狀態的指針作為參數即可。
3.4.6命令執行器:執行后續工作
在執行完實現函數之后, 服務器還需要執行一些后續工作:
- 如果服務器開啟了慢查詢日志功能, 那么慢查詢日志模塊會檢查是否需要為剛剛執行完的命令請求添加一條新的慢查詢日志。
- 根據剛剛執行命令所耗費的時長, 更新被執行命令的?
redisCommand?結構的?milliseconds?屬性, 并將命令的?redisCommand?結構的?calls?計數器的值增一。 - 如果服務器開啟了 AOF 持久化功能, 那么 AOF 持久化模塊會將剛剛執行的命令請求寫入到 AOF 緩沖區里面。
- 如果有其他從服務器正在復制當前這個服務器, 那么服務器會將剛剛執行的命令傳播給所有從服務器。
當以上操作都執行完了之后, 服務器對于當前命令的執行到此就告一段落了, 之后服務器就可以繼續從文件事件處理器中取出并處理下一個命令請求了。
3.4.7將命令回復發送給客戶端
前面說過, 命令實現函數會將命令回復保存到客戶端的輸出緩沖區里面, 并為客戶端的套接字關聯命令回復處理器, 當客戶端套接字變為可寫狀態時, 服務器就會執行命令回復處理器, 將保存在客戶端輸出緩沖區中的命令回復發送給客戶端。
當命令回復發送完畢之后, 回復處理器會清空客戶端狀態的輸出緩沖區, 為處理下一個命令請求做好準備。
3.4.8客戶端接收并打印命令回復
當客戶端接收到協議格式的命令回復之后, 它會將這些回復轉換成人類可讀的格式, 并打印給用戶觀看(假設使用的是 Redis 自帶的?客戶端)
?
3.5、事務
Redis 事務可以一次執行多個命令, 并且帶有以下三個重要的保證:
- 批量操作在發送 EXEC 命令前被放入隊列緩存。
- 收到 EXEC 命令后進入事務執行,事務中任意命令執行失敗,其余的命令依然被執行。
- 在事務執行過程,其他客戶端提交的命令請求不會插入到事務執行命令序列中。
一個事務從開始到執行會經歷以下三個階段:
- 開始事務。
- 命令入隊。
- 執行事務。
以下是一個事務的例子, 它先以?MULTI?開始一個事務, 然后將多個命令入隊到事務中, 最后由?EXEC?命令觸發事務, 一并執行事務中的所有命令:
redis 127.0.0.1:6379> MULTI
OKredis 127.0.0.1:6379> SET book-name "Mastering C++ in 21 days"
QUEUEDredis 127.0.0.1:6379> GET book-name
QUEUEDredis 127.0.0.1:6379> SADD tag "C++" "Programming" "Mastering Series"
QUEUEDredis 127.0.0.1:6379> SMEMBERS tag
QUEUEDredis 127.0.0.1:6379> EXEC
1) OK
2) "Mastering C++ in 21 days"
3) (integer) 3
4) 1) "Mastering Series"2) "C++"3) "Programming"詳細介紹:
3.5.1事務開始
MULTI?命令的執行標志著事務的開始:
redis> MULTI
OK
MULTI?命令可以將執行該命令的客戶端從非事務狀態切換至事務狀態, 這一切換是通過在客戶端狀態的?flags?屬性中打開?REDIS_MULTI?標識來完成的,?MULTI?命令的實現可以用以下偽代碼來表示:
def MULTI():# 打開事務標識client.flags |= REDIS_MULTI# 返回 OK 回復replyOK()3.5.2命令入隊
當一個客戶端處于非事務狀態時, 這個客戶端發送的命令會立即被服務器執行:
redis> SET "name" "Practical Common Lisp"
OKredis> GET "name"
"Practical Common Lisp"redis> SET "author" "Peter Seibel"
OKredis> GET "author"
"Peter Seibel"與此不同的是, 當一個客戶端切換到事務狀態之后, 服務器會根據這個客戶端發來的不同命令執行不同的操作:
- 如果客戶端發送的命令為?EXEC?、?DISCARD?、?WATCH?、?MULTI?四個命令的其中一個, 那么服務器立即執行這個命令。
- 與此相反, 如果客戶端發送的命令是?EXEC?、?DISCARD?、?WATCH?、?MULTI?四個命令以外的其他命令, 那么服務器并不立即執行這個命令, 而是將這個命令放入一個事務隊列里面, 然后向客戶端返回?
QUEUED?回復。
3.5.3事務隊列
每個 Redis 客戶端都有自己的事務狀態, 這個事務狀態保存在客戶端狀態的?mstate?屬性里面:
typedef struct redisClient {// ...// 事務狀態multiState mstate; /* MULTI/EXEC state */// ...} redisClient;事務狀態包含一個事務隊列, 以及一個已入隊命令的計數器 (也可以說是事務隊列的長度):
typedef struct multiState {// 事務隊列,FIFO 順序multiCmd *commands;// 已入隊命令計數int count;} multiState;事務隊列是一個?multiCmd?類型的數組, 數組中的每個?multiCmd?結構都保存了一個已入隊命令的相關信息, 包括指向命令實現函數的指針, 命令的參數, 以及參數的數量:
typedef struct multiCmd {// 參數robj **argv;// 參數數量int argc;// 命令指針struct redisCommand *cmd;} multiCmd;事務隊列以先進先出(FIFO)的方式保存入隊的命令: 較先入隊的命令會被放到數組的前面, 而較后入隊的命令則會被放到數組的后面。
舉個例子, 如果客戶端執行以下命令:
redis> MULTI
OKredis> SET "name" "Practical Common Lisp"
QUEUEDredis> GET "name"
QUEUEDredis> SET "author" "Peter Seibel"
QUEUEDredis> GET "author"
QUEUED
那么服務器將為客戶端創建事務狀態:
- 最先入隊的?SET?命令被放在了事務隊列的索引?
0?位置上。 - 第二入隊的?GET?命令被放在了事務隊列的索引?
1?位置上。 - 第三入隊的另一個?SET?命令被放在了事務隊列的索引?
2?位置上。 - 最后入隊的另一個?GET?命令被放在了事務隊列的索引?
3?位置上。
3.5.4執行事務
當一個處于事務狀態的客戶端向服務器發送?EXEC?命令時, 這個?EXEC?命令將立即被服務器執行: 服務器會遍歷這個客戶端的事務隊列, 執行隊列中保存的所有命令, 最后將執行命令所得的結果全部返回給客戶端。
EXEC?命令的實現原理可以用以下偽代碼來描述:
def EXEC():# 創建空白的回復隊列reply_queue = []# 遍歷事務隊列中的每個項# 讀取命令的參數,參數的個數,以及要執行的命令for argv, argc, cmd in client.mstate.commands:# 執行命令,并取得命令的返回值reply = execute_command(cmd, argv, argc)# 將返回值追加到回復隊列末尾reply_queue.append(reply)# 移除 REDIS_MULTI 標識,讓客戶端回到非事務狀態client.flags &= ~REDIS_MULTI# 清空客戶端的事務狀態,包括:# 1)清零入隊命令計數器# 2)釋放事務隊列client.mstate.count = 0release_transaction_queue(client.mstate.commands)# 將事務的執行結果返回給客戶端send_reply_to_client(client, reply_queue)3.5.5WATCH命令的實現
WATCH命令是一個樂觀鎖,它可以在EXEC命令執行之前,監視任意數量的數據庫鍵,并在EXEC執行后,檢查被監視的鍵是否至少有一個被修改,如果是,服務器拒絕執行事務,并向客戶端返回代表事務執行失敗的回復。
/* Redis database representation. There are multiple databases identified* by integers from 0 (the default database) up to the max configured* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {dict *dict; /* The keyspace for this DB 數據庫鍵空間,保存數據庫中所有的鍵值對*/dict *expires; /* Timeout of keys with a timeout set 保存過期時間*/dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */dict *ready_keys; /* Blocked keys that received a PUSH 已經準備好數據的阻塞狀態的key*/dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS 事物模塊,用于保存被WATCH命令所監控的鍵*/// 當內存不足時,Redis會根據LRU算法回收一部分鍵所占的空間,而該eviction_pool是一個長為16數組,保存可能被回收的鍵// eviction_pool中所有鍵按照idle空轉時間,從小到大排序,每次回收空轉時間最長的鍵struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */// 數據庫IDint id; /* Database ID */// 鍵的平均過期時間long long avg_ttl; /* Average TTL, just for stats */
} redisDb;在每個代表數據庫的 server.h/redisDb?結構類型中, 都保存了一個?watched_keys?字典, 字典的鍵是這個數據庫被監視的鍵, 而字典的值則是一個鏈表, 鏈表中保存了所有監視這個鍵的客戶端。比如說,以下字典就展示了一個?watched_keys?字典的例子:
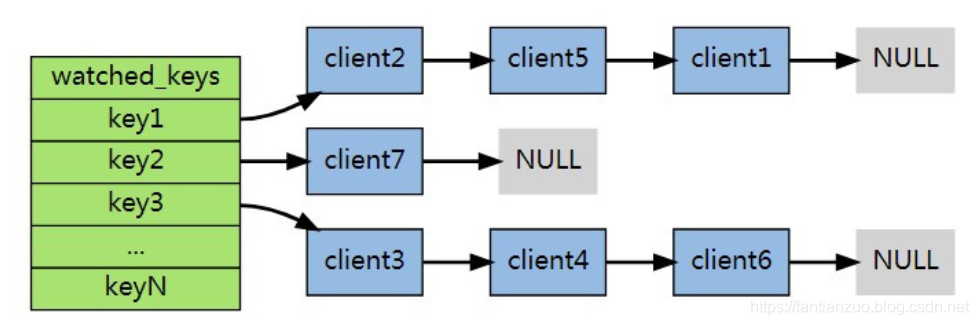
每個key后掛著監視自己的客戶端。
3.5.6監控的觸發
在任何對數據庫鍵空間(key space)進行修改的命令成功執行之后 (比如?FLUSHDB?、?SET?、?DEL?、?LPUSH?、?SADD?、?ZREM?,諸如此類),?multi.c/touchWatchedKey?函數都會被調用 (修改命令會調用signalModifiedKey()函數來處理數據庫中的鍵被修改的情況,該函數直接調用touchWatchedKey()函數)—— 它檢查數據庫的?watched_keys?字典, 看是否有客戶端在監視已經被命令修改的鍵, 如果有的話, 程序將所有監視這個/這些被修改鍵的客戶端的?REDIS_DIRTY_CAS?選項打開:
?
/* "Touch" a key, so that if this key is being WATCHed by some client the* next EXEC will fail. */
// Touch 一個 key,如果該key正在被監視,那么客戶端會執行EXEC失敗
void touchWatchedKey(redisDb *db, robj *key) {list *clients;listIter li;listNode *ln;// 字典為空,沒有任何鍵被監視if (dictSize(db->watched_keys) == 0) return;// 獲取所有監視這個鍵的客戶端 clients = dictFetchValue(db->watched_keys, key);// 沒找到返回if (!clients) return;/* Mark all the clients watching this key as CLIENT_DIRTY_CAS *//* Check if we are already watching for this key */// 遍歷所有客戶端,打開他們的 REDIS_DIRTY_CAS 標識listRewind(clients,&li);while((ln = listNext(&li))) {client *c = listNodeValue(ln);// 設置CLIENT_DIRTY_CAS標識c->flags |= CLIENT_DIRTY_CAS;}
}3.5.7事務的ACID性質
?在傳統的關系式數據庫中,常常用?ACID 性質來檢驗事務功能的安全性。
redis事物總是具有前三個性質。
a)原子性atomicity:redis事務保證事務中的命令要么全部執行要不全部不執行。
但是redis不同于傳統關系型數據庫,不支持回滾,即使出現了錯誤,事務也會繼續執行下去。
因為redis作者認為,這種復雜的機制和redis追求的簡單高效不符。并且,redis事務錯誤通常是編程錯誤,只會出現在開發環境中,而不會出現在實際生產環境中,所以沒必要支持回滾。
b)一致性consistency:redis事務可以保證命令失敗的情況下得以回滾,數據能恢復到沒有執行之前的樣子,是保證一致性的,除非redis進程意外終結。
Redis 的一致性問題可以分為三部分來討論:入隊錯誤、執行錯誤、Redis 進程被終結。
入隊錯誤
在命令入隊的過程中,如果客戶端向服務器發送了錯誤的命令,比如命令的參數數量不對,等等, 那么服務器將向客戶端返回一個出錯信息, 并且將客戶端的事務狀態設為?REDIS_DIRTY_EXEC?。
因此,帶有不正確入隊命令的事務不會被執行,也不會影響數據庫的一致性。
執行錯誤
如果命令在事務執行的過程中發生錯誤,比如說,對一個不同類型的 key 執行了錯誤的操作, 那么 Redis 只會將錯誤包含在事務的結果中, 這不會引起事務中斷或整個失敗,不會影響已執行事務命令的結果,也不會影響后面要執行的事務命令, 所以它對事務的一致性也沒有影響。
Redis 進程被終結
如果 Redis 服務器進程在執行事務的過程中被其他進程終結,或者被管理員強制殺死,那么根據 Redis 所使用的持久化模式,可能有以下情況出現:
內存模式:如果 Redis 沒有采取任何持久化機制,那么重啟之后的數據庫總是空白的,所以數據總是一致的。
RDB 模式:在執行事務時,Redis 不會中斷事務去執行保存 RDB 的工作,只有在事務執行之后,保存 RDB 的工作才有可能開始。所以當 RDB 模式下的 Redis 服務器進程在事務中途被殺死時,事務內執行的命令,不管成功了多少,都不會被保存到 RDB 文件里。恢復數據庫需要使用現有的 RDB 文件,而這個 RDB 文件的數據保存的是最近一次的數據庫快照(snapshot),所以它的數據可能不是最新的,但只要 RDB 文件本身沒有因為其他問題而出錯,那么還原后的數據庫就是一致的。
AOF 模式:因為保存 AOF 文件的工作在后臺線程進行,所以即使是在事務執行的中途,保存 AOF 文件的工作也可以繼續進行,因此,根據事務語句是否被寫入并保存到 AOF 文件,有以下兩種情況發生:
1)如果事務語句未寫入到 AOF 文件,或 AOF 未被 SYNC 調用保存到磁盤,那么當進程被殺死之后,Redis 可以根據最近一次成功保存到磁盤的 AOF 文件來還原數據庫,只要 AOF 文件本身沒有因為其他問題而出錯,那么還原后的數據庫總是一致的,但其中的數據不一定是最新的。
2)如果事務的部分語句被寫入到 AOF 文件,并且 AOF 文件被成功保存,那么不完整的事務執行信息就會遺留在 AOF 文件里,當重啟 Redis 時,程序會檢測到 AOF 文件并不完整,Redis 會退出,并報告錯誤。需要使用 redis-check-aof 工具將部分成功的事務命令移除之后,才能再次啟動服務器。還原之后的數據總是一致的,而且數據也是最新的(直到事務執行之前為止)。
?
c)隔離性Isolation:redis事務是嚴格遵守隔離性的,原因是redis是單進程單線程模式,可以保證命令執行過程中不會被其他客戶端命令打斷。
因為redis使用單線程執行事務,并且保證不會中斷,所以肯定有隔離性。
d)持久性Durability:持久性是指:當一個事務執行完畢,結果已經保存在永久介質里,比如硬盤,所以即使服務器后來停機了,結果也不會丟失
redis事務是不保證持久性的,這是因為redis持久化策略中不管是RDB還是AOF都是異步執行的,不保證持久性是出于對性能的考慮。
3.5.8重點提煉
- 事務提供了一種將多個命令打包, 然后一次性、有序地執行的機制。
- 多個命令會被入隊到事務隊列中, 然后按先進先出(FIFO)的順序執行。
- 事務在執行過程中不會被中斷, 當事務隊列中的所有命令都被執行完畢之后, 事務才會結束。
- 帶有?WATCH?命令的事務會將客戶端和被監視的鍵在數據庫的?
watched_keys?字典中進行關聯, 當鍵被修改時, 程序會將所有監視被修改鍵的客戶端的?REDIS_DIRTY_CAS?標志打開。 - 只有在客戶端的?
REDIS_DIRTY_CAS?標志未被打開時, 服務器才會執行客戶端提交的事務, 否則的話, 服務器將拒絕執行客戶端提交的事務。 - Redis 的事務總是保證 ACID 中的原子性、一致性和隔離性, 當服務器運行在 AOF 持久化模式下, 并且?
appendfsync?選項的值為?always?時, 事務也具有耐久性。
?
以上就是 Redis 客戶端和服務器執行命令請求的整個過程了。
?
3.6、發布和訂閱
3.6.1頻道的訂閱和退訂
當一個客戶端執行?SUBSCRIBE?命令, 訂閱某個或某些頻道的時候, 這個客戶端與被訂閱頻道之間就建立起了一種訂閱關系。
Redis 將所有頻道的訂閱關系都保存在服務器狀態的?pubsub_channels?字典里面, 這個字典的鍵是某個被訂閱的頻道, 而鍵的值則是一個鏈表, 鏈表里面記錄了所有訂閱這個頻道的客戶端:
struct redisServer {// ...// 保存所有頻道的訂閱關系dict *pubsub_channels;// ...};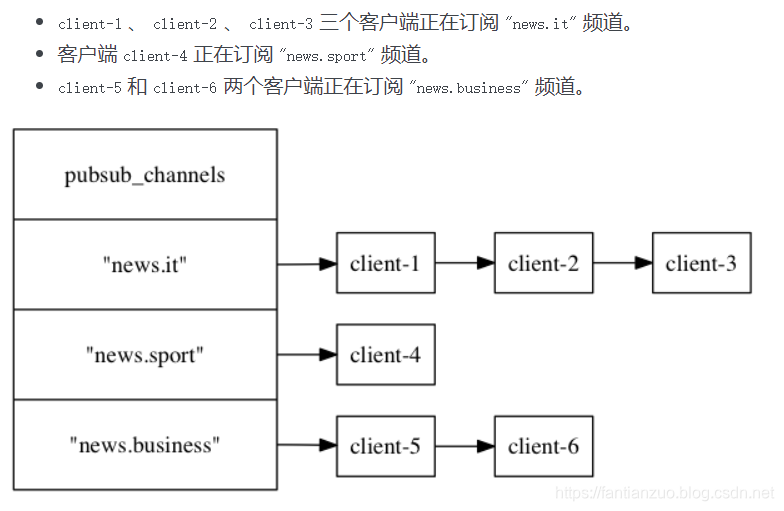
每當客戶端執行?SUBSCRIBE?命令, 訂閱某個或某些頻道的時候, 服務器都會將客戶端與被訂閱的頻道在?pubsub_channels?字典中進行關聯。
根據頻道是否已經有其他訂閱者, 關聯操作分為兩種情況執行:
- 如果頻道已經有其他訂閱者, 那么它在?
pubsub_channels?字典中必然有相應的訂閱者鏈表, 程序唯一要做的就是將客戶端添加到訂閱者鏈表的末尾。 - 如果頻道還未有任何訂閱者, 那么它必然不存在于?
pubsub_channels?字典, 程序首先要在?pubsub_channels?字典中為頻道創建一個鍵, 并將這個鍵的值設置為空鏈表, 然后再將客戶端添加到鏈表, 成為鏈表的第一個元素。
SUBSCRIBE?命令的實現可以用以下偽代碼來描述:
def subscribe(*all_input_channels):# 遍歷輸入的所有頻道for channel in all_input_channels:# 如果 channel 不存在于 pubsub_channels 字典(沒有任何訂閱者)# 那么在字典中添加 channel 鍵,并設置它的值為空鏈表if channel not in server.pubsub_channels:server.pubsub_channels[channel] = []# 將訂閱者添加到頻道所對應的鏈表的末尾server.pubsub_channels[channel].append(client)?
UNSUBSCRIBE?命令的行為和?SUBSCRIBE?命令的行為正好相反 —— 當一個客戶端退訂某個或某些頻道的時候, 服務器將從?pubsub_channels?中解除客戶端與被退訂頻道之間的關聯:
- 程序會根據被退訂頻道的名字, 在?
pubsub_channels?字典中找到頻道對應的訂閱者鏈表, 然后從訂閱者鏈表中刪除退訂客戶端的信息。 - 如果刪除退訂客戶端之后, 頻道的訂閱者鏈表變成了空鏈表, 那么說明這個頻道已經沒有任何訂閱者了, 程序將從?
pubsub_channels?字典中刪除頻道對應的鍵。
UNSUBSCRIBE?命令的實現可以用以下偽代碼來描述:
def unsubscribe(*all_input_channels):# 遍歷要退訂的所有頻道for channel in all_input_channels:# 在訂閱者鏈表中刪除退訂的客戶端server.pubsub_channels[channel].remove(client)# 如果頻道已經沒有任何訂閱者了(訂閱者鏈表為空)# 那么將頻道從字典中刪除if len(server.pubsub_channels[channel]) == 0:server.pubsub_channels.remove(channel)3.6.2模式的訂閱和退訂
前面說過,服務器將所有頻道的訂閱關系保存起來,與此類似,服務器也將所有模式的訂閱關系存在了pubsub_Patterns屬性里。
struct redisServer {// ...// 保存所有頻道的訂閱關系list *pubsub_patterns;// ...};pubsub_Patterns屬性是一個鏈表,每個結點是被訂閱的模式,節點內記錄了模式,節點內的client屬性記錄了訂閱模式的客戶端。
typedef struct pubsubPattern{//訂閱模式的客戶端redisClient *client;//被訂閱的模式robj *pattern;
}pubsubPattern;每當客戶端執行PSUBSCRIBE這個命令來訂閱某個或某些模式時,服務器會對每個被訂閱的模式執行下面的操作:
1)新建一個pubsubPattern結構,設置好兩個屬性
2)將新節點加到pubsub_patterns尾部
偽代碼實現:
def osubscribe(*all_input_patterns):#遍歷所有輸入的模式#記錄被訂閱的模式和對應的客戶端pubsubPattern=create()pubsubPattern.client=clientpubsubPattern.pattern=pattern#插入鏈表末尾server.pub_patterns.append(pubsubPattern)模式退訂命令PUNSUBSCRIBE是PSUBSCRIBE的反操作
服務器將找到并刪除那些被退訂的模式
偽代碼如下:(我想吐槽一下這樣時間復雜度。。。沒有更好的辦法嗎?)
def osubscribe(*all_input_patterns):#遍歷所有退訂的模式for pattern in all_input_patterns:#遍歷每一個節點for pubsubPattern in server.pubsub_patterns:#如果客戶端和模式都相同if client==pubsubPattern.client:if pattern==pubsubPattern.pattern:#刪除server.pub_patterns.remove(pubsubPattern)3.6.3、發送消息
當一個客戶端執行PUBLISH<channel> <message>命令將消息發送給頻道時,服務器需要:
1)把消息發送給所有本頻道的訂閱者
具體做法就是去pubsub_channels字典找到本頻道的鏈表,也就是訂閱名單,然后發消息
2)將消息發給,包含本頻道的所有模式中的所有訂閱者
具體做法就是去pubsub_patterns查找包含本頻道的模式,并且把消息發送給訂閱它們的客戶端。
3.6.4、查看訂閱信息
redis2.8新增三個命令,用來查看頻道和模式的相關信息。
PUBLISH CHANNELS[pattern]用于返回服務器當前被訂閱的頻道,pattern可寫可不寫,不寫就查看所有,否則查看與pattern匹配的對應頻道
這個子命令是通過遍歷pubsub_channels字典實現的。
PUBLISH NUMSUB[CHANNEL-1 CHANNEL-2.....]返回這些頻道的訂閱者數量
這個子命令是通過遍歷pubsub_channels字典,查看對應鏈表長度實現的。
PUBLISH NUMPAT返回被訂閱模式數量
這個子命令是通過返回pubsub_patterns的長度實現的。
總而言之,PUBSUB?命令的三個子命令都是通過讀取?pubsub_channels?字典和?pubsub_patterns?鏈表中的信息來實現的。
?
4、多機實現
4.1、舊版復制
Redis 的復制功能分為同步(sync)和命令傳播(command propagate)兩個操作:
- 同步操作用于將從服務器的數據庫狀態更新至主服務器當前所處的數據庫狀態。
- 命令傳播操作用于在主服務器的數據庫狀態被修改, 導致主從服務器的數據庫狀態出現不一致時, 讓主從服務器的數據庫重新回到一致狀態。
同步
當客戶端向從服務器發送?SLAVEOF?命令, 要求從服務器復制主服務器時, 從服務器首先需要執行同步操作, 也即是, 將從服務器的數據庫狀態更新至主服務器當前所處的數據庫狀態。
從服務器對主服務器的同步操作需要通過向主服務器發送?SYNC?命令來完成, 以下是?SYNC?命令的執行步驟:
- 從服務器向主服務器發送?SYNC?命令。
- 收到?SYNC?命令的主服務器執行?BGSAVE?命令, 在后臺生成一個 RDB 文件, 并使用一個緩沖區記錄從現在開始執行的所有寫命令。
- 當主服務器的?BGSAVE?命令執行完畢時, 主服務器會將?BGSAVE?命令生成的 RDB 文件發送給從服務器, 從服務器接收并載入這個 RDB 文件, 將自己的數據庫狀態更新至主服務器執行?BGSAVE?命令時的數據庫狀態。
- 主服務器將記錄在緩沖區里面的所有寫命令發送給從服務器, 從服務器執行這些寫命令, 將自己的數據庫狀態更新至主服務器數據庫當前所處的狀態。
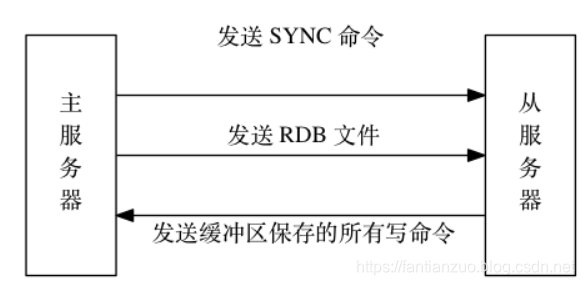 。
。
命令傳播
在同步操作執行完畢之后, 主從服務器兩者的數據庫將達到一致狀態, 但這種一致并不是一成不變的 —— 每當主服務器執行客戶端發送的寫命令時, 主服務器的數據庫就有可能會被修改, 并導致主從服務器狀態不再一致。
舉個例子, 假設一個主服務器和一個從服務器剛剛完成同步操作, 它們的數據庫都保存了相同的五個鍵?k1?至?k5
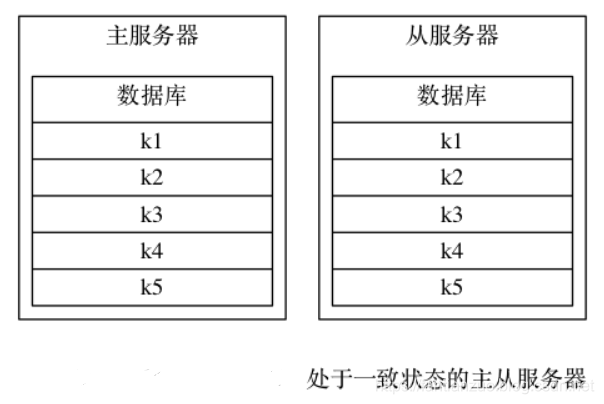
如果這時, 客戶端向主服務器發送命令?DEL?k3?, 那么主服務器在執行完這個?DEL?命令之后, 主從服務器的數據庫將出現不一致: 主服務器的數據庫已經不再包含鍵?k3?, 但這個鍵卻仍然包含在從服務器的數據庫里面
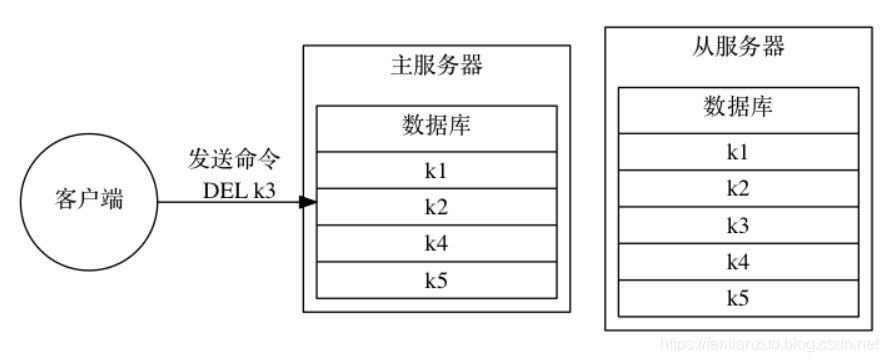
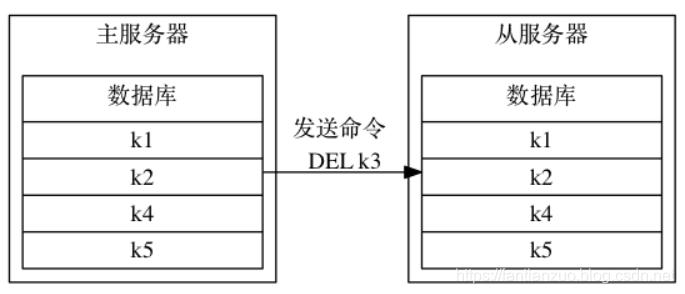
為了讓主從服務器再次回到一致狀態, 主服務器需要對從服務器執行命令傳播操作: 主服務器會將自己執行的寫命令 —— 也即是造成主從服務器不一致的那條寫命令 —— 發送給從服務器執行, 當從服務器執行了相同的寫命令之后, 主從服務器將再次回到一致狀態。
缺陷

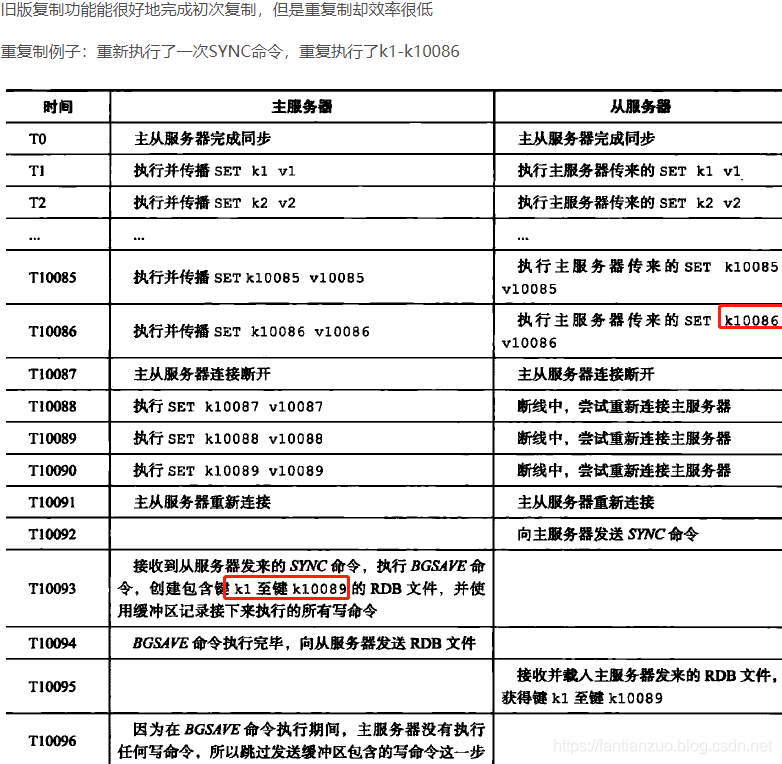 。
。
其中可以明顯看出重新連接主服務器之后,SYNC命令創建包含k1-k10089的RDB文件。而事實上只需要再同步斷線后的k10087-k10089即可。SYNC的“全同步”對于從服務來說是不必要的。
? ? ? ? ? ?SYNC命令非常消耗資源,原因有三點:
1)主服務器執行BGSAVE命令生成RDB文件,這個生成過程會大量消耗主服務器資源(CPU、內存和磁盤I/O資源)
2)主服務器需要將自己生成的RBD文件發送給從從服務器,這個發送操作會消耗主從服務器大量的網絡資源(帶寬與流量)
3)接收到RDB文件你的從服務器需要載入RDB文件,載入期間從服務器會因為阻塞而導致沒辦法處理命令請求。
4.2新版復制
sync雖然解決了數據同步問題,但是在數據量比較大情況下,從庫斷線從來依然采用全量復制機制,無論是從數據恢復、寬帶占用來說,sync所帶來的問題還是很多的。于是redis從2.8開始,引入新的命令psync。
psync有兩種模式:完整重同步和部分重同步。
部分重同步主要依賴三個方面來實現,依次介紹。
offset(復制偏移量):
主庫和從庫分別各自維護一個復制偏移量(可以使用info replication查看),用于標識自己復制的情況:
在主庫中代表主節點向從節點傳遞的字節數,在從庫中代表從庫同步的字節數。
每當主庫向從節點發送N個字節數據時,主節點的offset增加N
從庫每收到主節點傳來的N個字節數據時,從庫的offset增加N。
因此offset總是不斷增大,這也是判斷主從數據是否同步的標志,若主從的offset相同則表示數據同步量,不通則表示數據不同步。
replication backlog buffer(復制積壓緩沖區):
復制積壓緩沖區是一個固定長度的FIFO隊列,大小由配置參數repl-backlog-size指定,默認大小1MB。
需要注意的是該緩沖區由master維護并且有且只有一個,所有slave共享此緩沖區,其作用在于備份最近主庫發送給從庫的數據。
在主從命令傳播階段,主節點除了將寫命令發送給從節點外,還會發送一份到復制積壓緩沖區,作為寫命令的備份。
?
除了存儲最近的寫命令,復制積壓緩沖區中還存儲了每個字節相應的復制偏移量,由于復制積壓緩沖區固定大小先進先出的隊列,所以它總是保存的是最近redis執行的命令。
所以,重連服務器后,從服務器會發送自己的復制偏移量offset給主服務器,
如果offset偏移量之后的數據仍然存在于復制擠壓緩沖區,就執行部分重同步操作。
相反,執行完整重同步操作。
run_id(服務器運行的唯一ID)?
每個redis實例在啟動時候,都會隨機生成一個長度為40的唯一字符串來標識當前運行的redis節點,查看此id可通過命令info server查看。
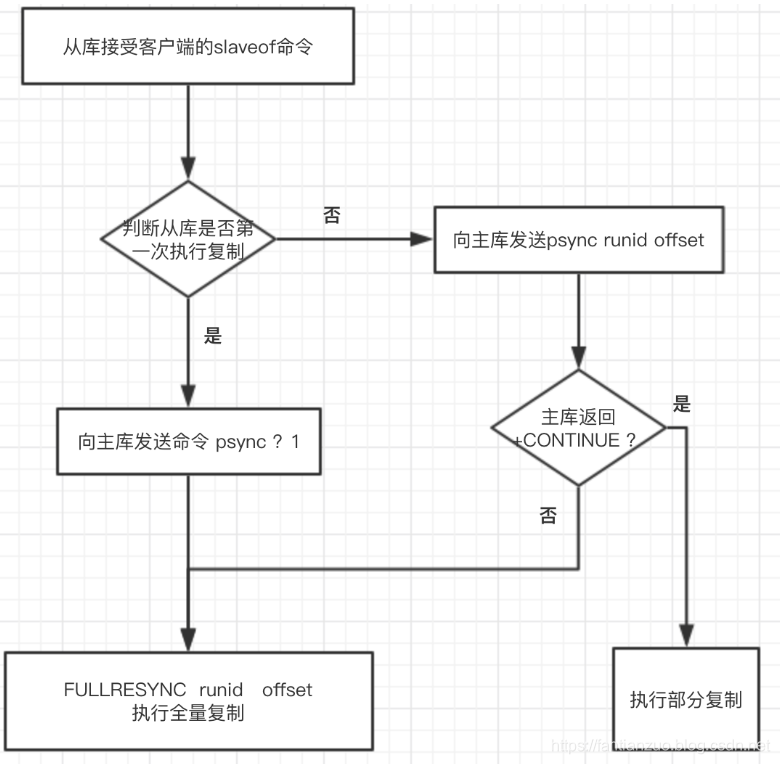
當主從復制在初次復制時,主節點將自己的runid發送給從節點,從節點將這個runid保存起來,當斷線重連時,從節點會將這個runid發送給主節點。主節點根據runid判斷能否進行部分復制:
- 如果從節點保存的runid與主節點現在的runid相同,說明主從節點之前同步過,主節點會更具offset偏移量之后的數據判斷是否執行部分復制,如果offset偏移量之后的數據仍然都在復制積壓緩沖區里,則執行部分復制,否則執行全量復制;
- 如果從節點保存的runid與主節點現在的runid不同,說明從節點在斷線前同步的redis節點并不是當前的主節點,只能進行全量復制;
?
psync流程:
復制
客戶端向服務器端發送:SLAVEOF
1、設置主服務器的地址和端口
存到masterhost和mastterport兩個屬性里之后,向客戶端發送ok,然后開始復制工作。
2、建立套接字鏈接
從服務器根據命令設置的地址和端口,創建鏈接,并且為這個套接字創建一個專門處理復制工作的文件事件處理器。
主服務器也會為套接字創建相應的客戶端狀態,并且把從服務器當作一個客戶端來對待。
3、發送ping命令(檢查)
檢查套接字狀態是否正常
檢查主服務器是否能正確處理請求。(如果不能,就重連)
4、身份認證
?
5、發送端口信息
從服務器向主服務器發送信息,主服務器記錄。
6、同步
從服務器向主服務器發送psync命令。(主服務器也成為從服務器的客戶端,因為主服務器會發送寫命令給從服務器)
7、命令傳播
完成同步后,進入傳播階段,主服務器一直發送寫命令,從服務器一直接受,保證和主服務器一致。
心跳檢測
默認一秒一次,從服務器向主服務器發送命令:REPLCONF ACK <offset>
三個作用:
檢測網絡連接狀態:如果主服務器一秒沒收到命令,就說明出問題了
輔助實現min-slaves配置:min-slaves-to-write 3? ?min-slaves-max-log 10:當從服務器小于3個或延遲都大于10,主服務器拒絕寫命令。
檢測命令丟失:如果命令丟失,主服務器會發現偏移量不一樣,然后它就會根據偏移量,去積壓緩沖區找到缺少的數據并發給從服務器。
4.3、哨兵
4.3.1什么是哨兵機制
Redis的哨兵(sentinel)?系統用于管理/多個?Redis?服務器,該系統執行以下三個任務:
·????????監控:?哨兵(sentinel)?會不斷地檢查你的Master和Slave是否運作正常。
·????????提醒:當被監控的某個?Redis出現問題時,?哨兵(sentinel)?可以通過?API?向管理員或者其他應用程序發送通知。
·????????自動故障遷移:當一個Master不能正常工作時,哨兵(sentinel)?會開始一次自動故障遷移操作,它會將失效Master的其中一個Slave升級為新的Master,?并讓失效Master的其他Slave改為復制新的Master;?當客戶端試圖連接失效的Master時,集群也會向客戶端返回新Master的地址,使得集群可以使用Master代替失效Master。
例如下圖所示:
在Server1 掉線后:
升級Server2 為新的主服務器:
4.3.2、哨兵模式修改配置
實現步驟:
1.拷貝到etc目錄
cp sentinel.conf? /usr/local/redis/etc
2.修改sentinel.conf配置文件
sentinel monitor mymast? 192.168.110.133 6379 1? #主節點 名稱 IP 端口號 選舉次數
sentinel auth-pass mymaster 123456?
3. 修改心跳檢測 5000毫秒
sentinel down-after-milliseconds mymaster 5000
4.sentinel parallel-syncs mymaster 2 --- 做多多少合格節點
5. 啟動哨兵模式
./redis-server /usr/local/redis/etc/sentinel.conf --sentinel &
1)Sentinel(哨兵) 進程是用于監控 Redis 集群中 Master 主服務器工作的狀態
2)在 Master 主服務器發生故障的時候,可以實現 Master 和 Slave 服務器的切換,保證系統的高可用(High Availability)
工作方式
1)每個 Sentinel(哨兵)進程以每秒鐘一次的頻率向整個集群中的 Master 主服務器,Slave 從服務器以及其他 Sentinel(哨兵)進程發送一個 PING 命令。
2. 如果一個實例(instance)距離最后一次有效回復 PING 命令的時間超過 down-after-milliseconds 選項所指定的值, 則這個實例會被 Sentinel(哨兵)進程標記為主觀下線。
3. 如果一個 Master 主服務器被標記為主觀下線,則正在監視這個 Master 主服務器的所有 Sentinel(哨兵)進程要以每秒一次的頻率確認 Master 主服務器的確進入了主觀下線狀態。
4. 當有足夠數量的 Sentinel(哨兵)進程(大于等于配置文件指定的值)在指定的時間范圍內確認 Master 主服務器進入了主觀下線狀態, 則Master 主服務器會被標記為客觀下線(ODOWN)。
5. 在一般情況下, 每個 Sentinel(哨兵)進程會以每 10 秒一次的頻率向集群中的所有Master 主服務器、Slave 從服務器發送 INFO 命令。
6. 當 Master 主服務器被 Sentinel(哨兵)進程標記為客觀下線時,Sentinel(哨兵)進程向下線的 Master 主服務器的所有 Slave 從服務器發送 INFO 命令的頻率會從 10 秒一次改為每秒一次。
7. 若沒有足夠數量的 Sentinel(哨兵)進程同意 Master 主服務器下線, Master 主服務器的客觀下線狀態就會被移除。若 Master 主服務器重新向 Sentinel(哨兵)進程發送 PING 命令返回有效回復,Master 主服務器的主觀下線狀態就會被移除。
哨兵(sentinel)?的一些設計思路和zookeeper非常類似
我們從啟動并初始化說起
4.3.3啟動并初始化 Sentinel
啟動一個 Sentinel 可以使用命令:
$ redis-sentinel /path/to/your/sentinel.conf
或者命令:
$ redis-server /path/to/your/sentinel.conf --sentinel當一個 Sentinel 啟動時, 它需要執行以下步驟:
初始化服務器。
首先, 因為 Sentinel 本質上只是一個運行在特殊模式下的 Redis 服務器, 所以啟動 Sentinel 的第一步, 就是初始化一個普通的 Redis 服務器.
不過, 因為 Sentinel 執行的工作和普通 Redis 服務器執行的工作不同, 所以 Sentinel 的初始化過程和普通 Redis 服務器的初始化過程并不完全相同。
比如說, 普通服務器在初始化時會通過載入 RDB 文件或者 AOF 文件來還原數據庫狀態, 但是因為 Sentinel 并不使用數據庫, 所以初始化 Sentinel 時就不會載入 RDB 文件或者 AOF 文件。
將普通 Redis 服務器使用的代碼替換成 Sentinel 專用代碼。
第二個步驟就是將一部分普通 Redis 服務器使用的代碼替換成 Sentinel 專用代碼。
比如說, 普通 Redis 服務器使用?redis.h/REDIS_SERVERPORT?常量的值作為服務器端口:
#define REDIS_SERVERPORT 6379
而 Sentinel 則使用?sentinel.c/REDIS_SENTINEL_PORT?常量的值作為服務器端口:
#define REDIS_SENTINEL_PORT 26379為什么在 Sentinel 模式下, Redis 服務器不能執行諸如?SET?、?DBSIZE?、?EVAL?等等這些命令 —— 因為服務器根本沒有在命令表中載入這些命令。
初始化 Sentinel 狀態。
在應用了 Sentinel 的專用代碼之后, 接下來, 服務器會初始化一個?sentinel.c/sentinelState?結構(后面簡稱“Sentinel 狀態”), 這個結構保存了服務器中所有和 Sentinel 功能有關的狀態 (服務器的一般狀態仍然由?redis.h/redisServer?結構保存):
struct sentinelState {// 當前紀元,用于實現故障轉移uint64_t current_epoch;// 保存了所有被這個 sentinel 監視的主服務器// 字典的鍵是主服務器的名字// 字典的值則是一個指向 sentinelRedisInstance 結構的指針dict *masters;// 是否進入了 TILT 模式?int tilt;// 目前正在執行的腳本的數量int running_scripts;// 進入 TILT 模式的時間mstime_t tilt_start_time;// 最后一次執行時間處理器的時間mstime_t previous_time;// 一個 FIFO 隊列,包含了所有需要執行的用戶腳本list *scripts_queue;} sentinel;初始化 Sentinel 狀態的?masters?屬性
Sentinel 狀態中的?masters?字典記錄了所有被 Sentinel 監視的主服務器的相關信息:
- 字典的鍵是被監視主服務器的名字。
- 而字典的值則是被監視主服務器對應的?
sentinel.c/sentinelRedisInstance?結構。
每個?sentinelRedisInstance?結構代表一個被 Sentinel 監視的 Redis 服務器實例(instance), 這個實例可以是主服務器、從服務器、或者另外一個 Sentinel 。
實例結構包含的屬性非常多, 以下代碼展示了一部分屬性
typedef struct sentinelRedisInstance {// 標識值,記錄了實例的類型,以及該實例的當前狀態int flags;// 實例的名字// 主服務器的名字由用戶在配置文件中設置// 從服務器以及 Sentinel 的名字由 Sentinel 自動設置// 格式為 ip:port ,例如 "127.0.0.1:26379"char *name;// 實例的運行 IDchar *runid;// 配置紀元,用于實現故障轉移uint64_t config_epoch;// 實例的地址sentinelAddr *addr;// SENTINEL down-after-milliseconds 選項設定的值// 實例無響應多少毫秒之后才會被判斷為主觀下線(subjectively down)mstime_t down_after_period;// SENTINEL monitor <master-name> <IP> <port> <quorum> 選項中的 quorum 參數// 判斷這個實例為客觀下線(objectively down)所需的支持投票數量int quorum;// SENTINEL parallel-syncs <master-name> <number> 選項的值// 在執行故障轉移操作時,可以同時對新的主服務器進行同步的從服務器數量int parallel_syncs;// SENTINEL failover-timeout <master-name> <ms> 選項的值// 刷新故障遷移狀態的最大時限mstime_t failover_timeout;// ...} sentinelRedisInstance;創建連向主服務器的網絡連接。
?Sentinel 將成為主服務器的客戶端, 它可以向主服務器發送命令, 并從命令回復中獲取相關的信息。
對于每個被 Sentinel 監視的主服務器來說, Sentinel 會創建兩個連向主服務器的異步網絡連接:
- 一個是命令連接, 這個連接專門用于向主服務器發送命令, 并接收命令回復。
- 另一個是訂閱連接, 這個連接專門用于訂閱主服務器的?
__sentinel__:hello?頻道。
為什么有兩個連接?在 Redis 目前的發布與訂閱功能中, 被發送的信息都不會保存在Redis 服務器里面, 如果在信息發送時, 想要接收信息的客戶
端不在線或者斷線, 那么這個客戶端就會丟失這條信息。因此, 為了不丟失 __sentinel__:hello 頻道的任何信息,
Sentinel 必須專門用一個訂閱連接來接收該頻道的信息。而另一方面, 除了訂閱頻道之外, Sentinel 還又必須向主服務
器發送命令, 以此來與主服務器進行通訊, 所以 Sentinel 還
必須向主服務器創建命令連接。并且因為 Sentinel 需要與多個實例創建多個網絡連接, 所以Sentinel 使用的是異步連接。接下來介紹 Sentinel 如何通過命令連接和訂閱連接與被監視主服務器進行通訊。
4.3.4、獲取服務器信息
sentinel默認每十秒鐘發送一次INFO命令給主服務器,并獲取信息:
1)關于主服務器本身的信息
2)主服務器屬下所有從服務器信息
sentinel發現主服務器有新的從服務器時,會創建相應的實例結構和命令連接,訂閱連接
4.3.5、給服務器發送消息
4.3.6、主觀下線
指的是單個Sentinel實例對服務器做出的下線判斷,即單個sentinel認為某個服務下線(有可能是接收不到訂閱,之間的網絡不通等等原因)。
如果服務器在down-after-milliseconds給定的毫秒數之內, 沒有返回 Sentinel 發送的 PING 命令的回復, 或者返回一個錯誤, 那么 Sentinel 將這個服務器標記為主觀下線(SDOWN )。
sentinel會以每秒一次的頻率向所有與其建立了命令連接的實例(master,從服務,其他sentinel)發ping命令,通過判斷ping回復是有效回復,還是無效回復來判斷實例時候在線(對該sentinel來說是“主觀在線”)。
sentinel配置文件中的down-after-milliseconds設置了判斷主觀下線的時間長度,如果實例在down-after-milliseconds毫秒內,返回的都是無效回復,那么sentinel回認為該實例已(主觀)下線,修改其flags狀態為SRI_S_DOWN。如果多個sentinel監視一個服務,有可能存在多個sentinel的down-after-milliseconds配置不同,這個在實際生產中要注意。
4.3.7、客觀下線
客觀下線(Objectively Down, 簡稱 ODOWN)指的是多個 Sentinel 實例在對同一個服務器做出 SDOWN 判斷, 并且通過 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服務器下線判斷,然后開啟failover。
客觀下線就是說只有在足夠數量的 Sentinel 都將一個服務器標記為主觀下線之后, 服務器才會被標記為客觀下線(ODOWN)。
只有當master被認定為客觀下線時,才會發生故障遷移。
當sentinel監視的某個服務主觀下線后,sentinel會詢問其它監視該服務的sentinel,看它們是否也認為該服務主觀下線,接收到足夠數量(這個值可以配置)的sentinel判斷為主觀下線,既任務該服務客觀下線,并對其做故障轉移操作。
sentinel通過發送 SENTINEL is-master-down-by-addr ip port current_epoch runid
(ip:主觀下線的服務id,port:主觀下線的服務端口,current_epoch:sentinel的紀元,runid:*表示檢測服務下線狀態,如果是sentinel 運行id,表示用來選舉領頭sentinel)
來詢問其它sentinel是否同意服務下線。
一個sentinel接收另一個sentinel發來的is-master-down-by-addr后,提取參數,根據ip和端口,檢測該服務時候在該sentinel主觀下線,并且回復is-master-down-by-addr,回復包含三個參數:down_state(1表示已下線,0表示未下線),leader_runid(領頭sentinal id),leader_epoch(領頭sentinel紀元)。
sentinel接收到回復后,根據配置設置的下線最小數量,達到這個值,既認為該服務客觀下線。
客觀下線條件只適用于主服務器: 對于任何其他類型的 Redis 實例, Sentinel 在將它們判斷為下線前不需要進行協商, 所以從服務器或者其他 Sentinel 永遠不會達到客觀下線條件。只要一個 Sentinel 發現某個主服務器進入了客觀下線狀態, 這個 Sentinel 就可能會被其他 Sentinel 推選出, 并對失效的主服務器執行自動故障遷移操作。
4.3.8、選舉大哥sentinel
一個redis服務被判斷為客觀下線時,多個監視該服務的sentinel協商,選舉一個領頭sentinel,對該redis服務進行故障轉移操作。選舉領頭sentinel遵循以下規則:
1)所有的sentinel都有公平被選舉成領頭的資格。
2)所有的sentinel都只有一次將某個sentinel選舉成領頭的機會(在一輪選舉中),一旦選舉,不能更改。
3)先到先得,一旦當前sentinel設置了領頭sentinel,以后要求設置sentinel為領頭請求都會被拒絕。
4)每個發現服務客觀下線的sentinel,都會要求其他sentinel將自己設置成領頭。
5)當一個sentinel(源sentinel)向另一個sentinel(目sentinel)發送is-master-down-by-addr ip port current_epoch runid命令的時候,runid參數不是*,而是sentinel運行id,就表示源sentinel要求目標sentinel選舉其為領頭。
6)源sentinel會檢查目標sentinel對其要求設置成領頭的回復,如果回復的leader_runid和leader_epoch為源sentinel,表示目標sentinel同意將源sentinel設置成領頭。
7)如果某個sentinel被半數以上的sentinel設置成領頭,那么該sentinel既為領頭。
8)如果在限定時間內,沒有選舉出領頭sentinel,暫定一段時間,再選舉。
為什么要選?
簡單來說,就是因為只能有一個sentinel節點去完成故障轉移。
sentinel is-master-down-by-addr這個命令有兩個作用,一是確認下線判定,二是進行領導者選舉。
過程:
1)每個做主觀下線的sentinel節點向其他sentinel節點發送上面那條命令,要求將它設置為領導者。
2)收到命令的sentinel節點如果還沒有同意過其他的sentinel發送的命令(還未投過票),那么就會同意,否則拒絕。
3)如果該sentinel節點發現自己的票數已經過半且達到了quorum的值,就會成為領導者
4)如果這個過程出現多個sentinel成為領導者,則會等待一段時間重新選舉。
4.3.9、轉移
1)挑一個新的主服務器
2)把其它從服務器的主服務器改成新的
3)把之前的主服務器改為新主服務器的從服務器
4.3.10、怎么挑新的主服務器
1)刪除所有下線服務器
2)刪除五秒內沒回復INOF命令的服務器
3)刪除數據舊的服務器(連接斷開超過down-after-millseconds*10)
4)根據優先級,選出最高的。
4.3.11、重點提煉
?
- Sentinel 是一個特殊模式下的 Redis 服務器, 它使用了不同的命令表, 所以 Sentinel 能使用的命令和普通服務器不同。
- Sentinel 會讀入用戶指定的配置文件, 為每個要被監視的主服務器創建相應的實例結構, 并創建連向主服務器的命令連接和訂閱連接, 其中命令連接用于向主服務器發送命令請求, 而訂閱連接則用于接收指定頻道的消息。
- Sentinel 向主服務器發送?INFO?命令獲得屬下從服務器信息, 為這些從服務器創建實例結構、命令連接和訂閱連接。
- 默認 Sentinel 十秒一次向被監視的主服務器和從服務器發送?INFO?命令, 當主服務器處于下線狀態, 或者 Sentinel 正在對主服務器進行故障轉移操作時, Sentinel 向從服務器發送?INFO?命令的頻率會改為每秒一次。
- 對于監視同一個主服務器和從服務器的多個 Sentinel 來說, 它們會以每兩秒一次的頻率, 通過向被監視服務器的?
__sentinel__:hello?頻道發送消息來向其他 Sentinel 宣告自己的存在。 - 每個 Sentinel 也會從?
__sentinel__:hello?頻道中接收其他 Sentinel 發來的信息, 并根據這些信息為其他 Sentinel 創建相應的實例結構, 以及命令連接。 - Sentinel 只會與主服務器和從服務器創建命令連接和訂閱連接, Sentinel 與 Sentinel 之間則只創建命令連接。
- Sentinel 以每秒一次的頻率向實例(包括主服務器、從服務器、其他 Sentinel)發送?PING?命令, 并根據實例對?PING?命令的回復來判斷實例是否在線
- 當 Sentinel 將一個主服務器判斷為主觀下線時, 它會向同樣監視這個主服務器的其他 Sentinel 進行詢問, 看它們是否同意這個主服務器已經進入主觀下線狀態。
- 當 Sentinel 收集到足夠多的主觀下線投票之后, 它會將主服務器判斷為客觀下線, 并發起一次針對主服務器的故障轉移操作。
?





)





)





)

)