文章目錄
- 分布式理論
- CAP定理
- BASE理論
- 分布式存儲與一致性哈希
- 簡單哈希
- 一致性哈希
- 虛擬節點
分布式理論
CAP定理
- 一致性(Consistency): 在分布式系統中的所有數據副本,在同一時刻是否一致(所有節點訪問同一份最新的數據副本)。
- 可用性(Availability): 分布式系統在面對各種異常時可以提供正常服務的能力(非故障的節點在有限的時間內返回合理的響應)。
- 分區容錯性(Partition Tolerance): 分布式系統在遇到任何網絡分區故障的時候,仍然需要能對外提供一致性和可用性的服務,除非是整個網絡環境都發生了故障。
一個分布式系統不可能同時滿足一致性、可用性、分區容錯性這三個基本需求,最多只能滿足其中的兩項,不可能三者兼顧。
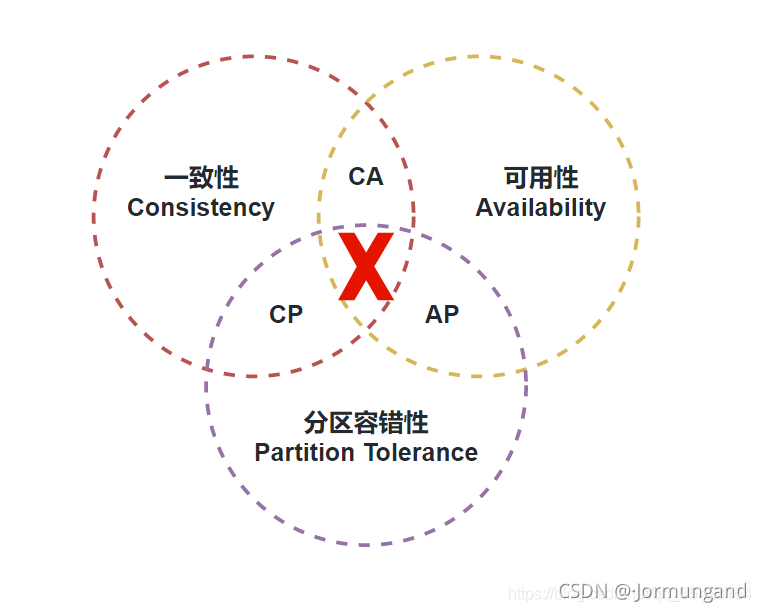
為什么三者不可兼顧呢?
這跟 網絡分區 這一概念有關:在分布式系統中,不同的節點分布在不同的子網絡(機房或異地網絡等)中,由于一些特殊的原因導致這些子網絡之間出現網絡不連通的狀況(但各個子網絡的內部網絡是連通的),從而導致了整個系統的網絡環境被切分成了若干個孤立的區域。
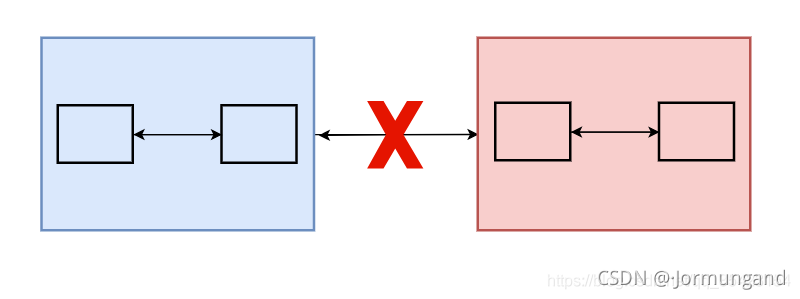
此時,每個區域內部可以通信,但是區域之間無法通信。
對于一個分布式系統而言,組件必然要被部署到不同的節點上,因此必然會出現子網絡。我們無法保證網絡始終可靠,那么網絡分區則是必定會產生的異常情況。當發生網絡分區的時候,如果我們要繼續提供服務,那么 分區容錯性P 是必定要滿足的。
那么一致性C和可用性A可以兼顧嗎?
答案是否定的。倘若分布式系統中出現了網絡分區的情況,假設此時某一個節點在進行寫操作,為了保證一致性,那么就必須要禁止其他節點的讀寫操作以防止數據沖突,而此時就導致其他的節點無法正常工作,即與可用性發生沖突。而如果讓其他節點都正常進行讀寫操作的話,那就無法保證數據的一致,影響了數據的一致性。
BASE理論
- 基本可用(Basically Available): 基本可用是指分布式系統在出現不可預知故障的時候,允許損失部分可用性(響應時間上的損失、系統功能上的損失)。但是,這絕不等價于系統不可用。
- 軟狀態(Soft-state): 允許系統中的數據存在中間狀態(數據不一致),并認為該中間狀態的存在不會影響系統的整體可用性。即允許系統在不同節點的數據副本之間進行數據同步時存在延時。
- 最終一致性(Eventually Consistent): 最終一致性強調的是系統中所有的數據副本最終能夠達到一致,而不需要實時保證系統數據的強一致性。
BASE理論 是基本可用 、軟狀態和最終一致性 三個短語的縮寫。是對 CAP 中的一致性和可用性權衡后的結果。
總的來說,BASE理論 面向的是大型高可用可擴展的分布式系統,它完全不同于 ACID 的強一致性模型,而是提出通過犧牲強一致性來獲得可用性,并允許數據在一段時間內是不一致的,但最終達到一致狀態。 但同時,在實際的分布式場景中,ACID特性 與 BASE理論 往往又會結合在一起使用。
分布式存儲與一致性哈希
如果我們需要存儲QQ號與個人信息,建立起 <QQ號, 個人信息> 的 KV 模型。
假設 QQ 有 10億 用戶,并且每個用戶的個人信息占據了 100M,如果要存儲這些數據,所需要的空間就得 (100億* 100M) = 10WT,這么龐大的數據是不可能在單機環境下存儲的,只能采用分布式的方法,用多個機器進行存儲,但是即使使用多機,這些數據也至少要 10w 臺機器(假設每臺服務器存 1T )才能存儲。那么我們如何確定哪些數據應該放在哪個機器呢?這時就需要用到哈希算法。
簡單哈希
我們可以采用除留余數法來完成一個映射:
機器編號 = hash(QQ號) % 機器數量
使用時再根據機器編號進入對應的機器進行增刪查改即可。
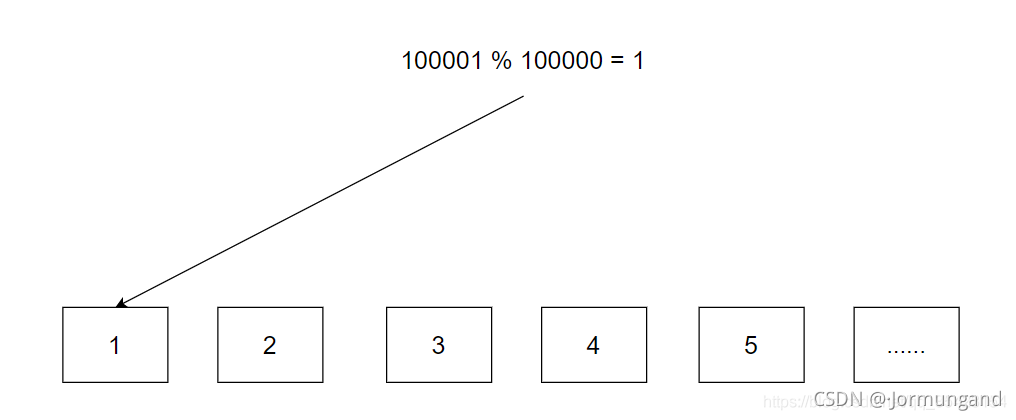
但是這個方法存在著一個致命的缺陷,如果后續用戶信息增加,10w 臺機器就會不夠用,此時就需要將機器數量擴容至 15w 臺。
當進行擴容后,由于機器數量發生變化,數據的映射關系也會變化,我們就需要進行 rehash 來將所有數據重新映射到正確的位置上。
但是問題來了,這 10w 臺機器的數據如果需要進行重新映射,花費的時間幾乎是不可想象的,我們不可能說為了遷移數據而讓服務器宕機數月之久,所以這種方法是不可能行得通的。
一致性哈希
為了彌補簡單哈希的缺陷,引入了一致性哈希算法。以避免擴容后 rehash 帶來的所有數據遷移問題。一致性哈希將哈希構造成一個 0~232-1 的環形結構,并將余數從原來的機器數量修改值為整型最大值(也可以是比這個更大的):
機器編號 = hash(QQ號) % 2^32
因為這個數據足夠大,所以無需擔心后續機器數增加導致的 rehash 問題。我們將環中的某一區間映射到某臺服務器,讓這臺服務器管理這個區間,這樣就能讓這 10w 臺服務器來切分這個閉環結構。
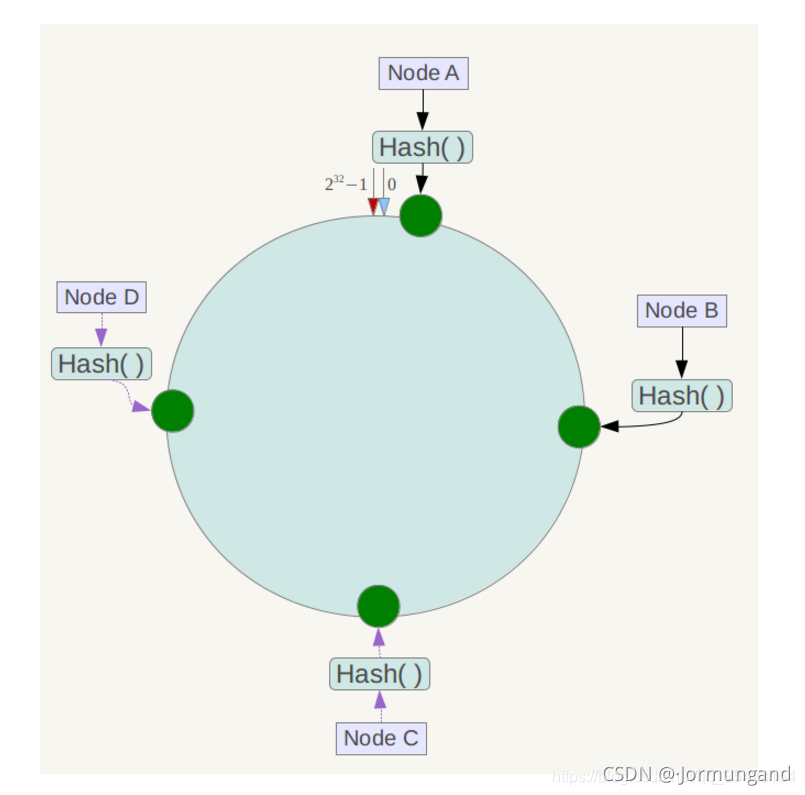
哈希環上的數據節點向順時針方向尋找到的第一個服務器就是管理它的服務器。
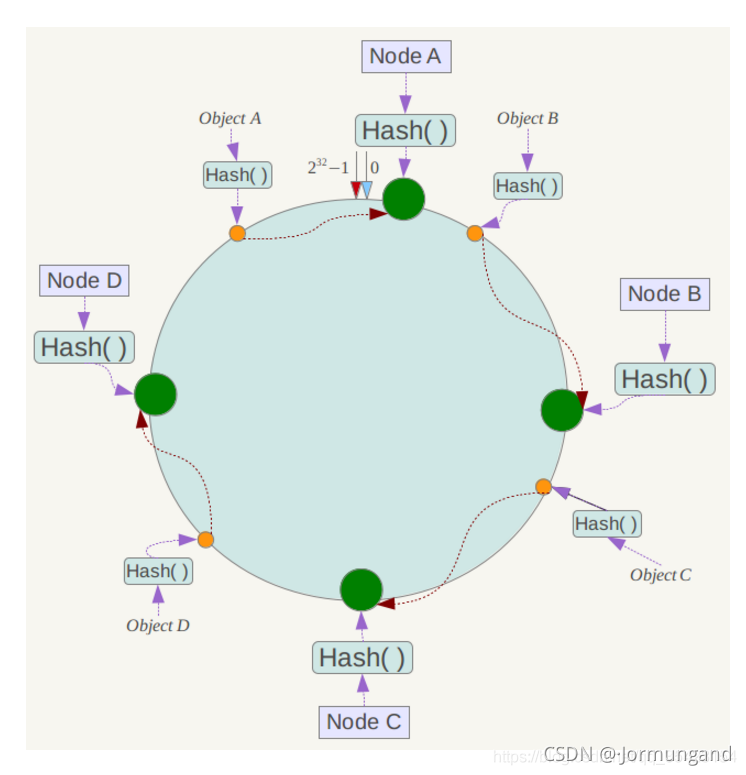
當我們要查詢某個數據的時候,根據哈希函數算出的映射位置來找到包含該位置的區間所對應的服務器,然后在那個服務器中進行操作即可。
如果原先的服務器不夠用了,此時增加 5w 個服務器,也不需要像之前一樣對所有機器的數據進行遷移,我們只需要遷移負載重的機器即可。
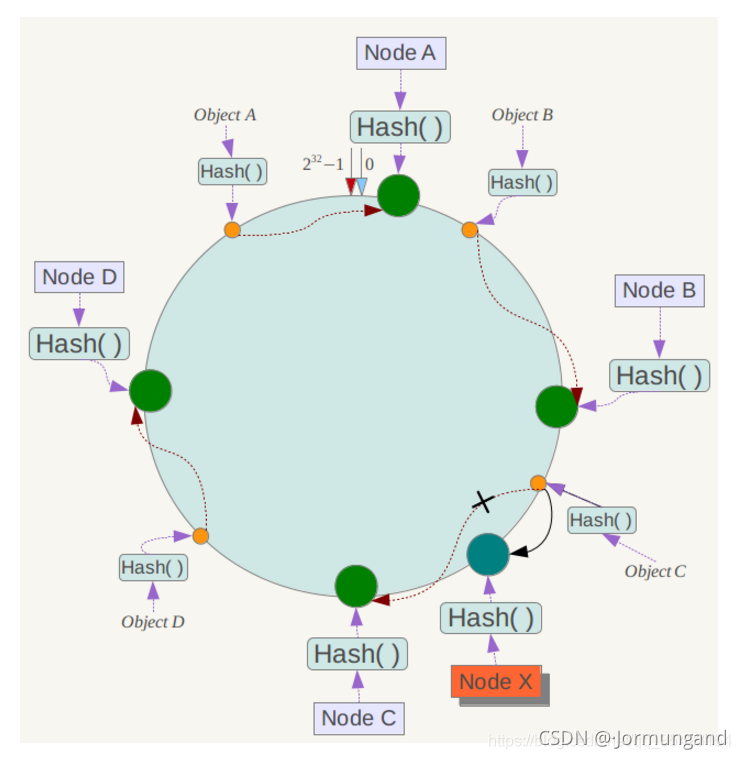
同理,如果一個服務器宕機了,那么該服務器的上的數據就會被順時針方向的下一個服務器接管:
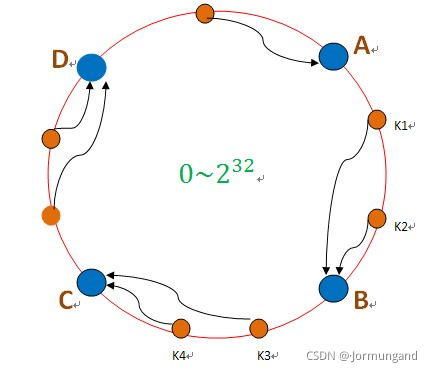
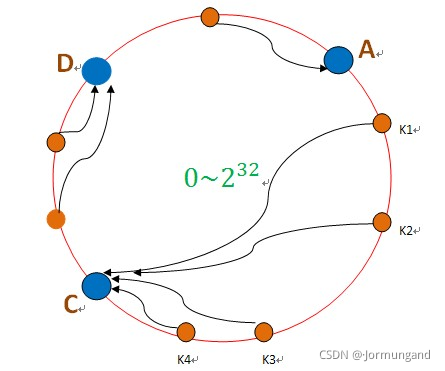
但是這樣的接管容易引發雪崩,即C節點由于承擔了B節點的數據,所以C節點的負載會變高,C節點很容易也宕機,這樣依次下去,這樣造成整個集群都掛了。
虛擬節點
為此,引入了虛擬節點的概念:即把想象在這個環上有很多虛擬節點,數據的存儲是沿著環的順時針方向找一個虛擬節點,每個虛擬節點都會關聯到一個真實節點。
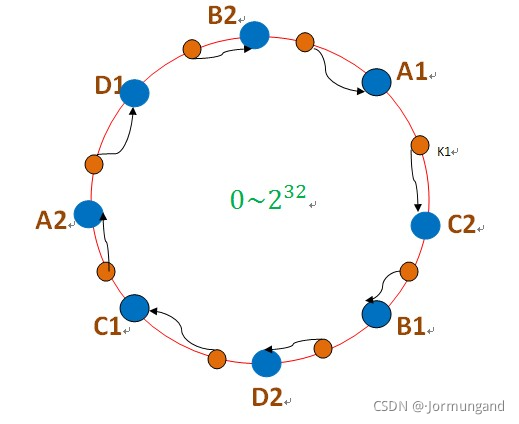
圖中的A1、A2、B1、B2、C1、C2、D1、D2都是虛擬節點,機器A負載存儲A1、A2的數據,機器B負載存儲B1、B2的數據,機器C負載存儲C1、C2的數據。由于這些虛擬節點數量很多,均勻分布,因此不會造成“雪崩”現象。
通過虛擬節點,我們可以做到不增加真實的服務器數量即可解決數據分布不均勻。










算法(圖解))

 | Android Studio的配置與使用)
 | Intent 實現 Activity 切換)
 | 項目目錄及主要文件作用分析)
 | Android 的日志工具 Logcat)

 | Activity 的生命周期)
 | Activity 的啟動模式 及 生產環境中關于 Activity 的小技巧)
 | 常用控件)