文章目錄
- 前言
- 0. 縮寫名詞解釋
- 1. 頭文件
- 1.1. Self-contained 頭文件
- 1.2. 頭文件保護
- 1.3. 前置聲明
- 1.4 內聯函數
- 1.5. #include 的路徑及順序
- 2. 作用域
- 2.1. 命名空間
- 2.2. 非成員函數、靜態成員函數和全局函數
- 2.3. 局部變量
- 2.4. 靜態和全局變量
- 3. 類
- 3.1. 構造函數的職責
- 3.2. 隱式類型轉換
- 3.3. 可拷貝類型和可移動類型
- 復制消除
- 3.4. struct VS class
- 3.5. 繼承
- 3.6. 多重繼承
- 3.7. 接口
- 3.8. 運算符重載
- 不要
- 而要
- 3.9. 存取控制與聲明順序
- 4. 函數
- 4.1. 引用參數
- 4.2. 函數重載
- 4.3. 缺省參數
- 4.4. 輸入和輸出
- 4.5. 函數返回類型后置語法
- 5. 所有權與智能指針
- 兩種智能指針
- 結論
- 6. 其他 C++ 特性
- 6.1. 右值引用
- 6.2. 變長數組和 alloca()
- 6.3. 友元
- 6.4. 異常
- 6.5. 運行時類型識別
- 6.6. 類型轉換
- 6.7. 流
- 6.8. 前置自增和自減
- 6.9. const 和 constexpr
- 6.10. 整型
- 6.11. 預處理宏
- 6.12. 0、nullptr 和 NULL
- 6.13. sizeof
- 6.14. auto
- 6.15. 列表初始化
- 6.16. Lambda 表達式
- 6.17. 模板編程
- 6.18. C++11
- 7. 命名約定
- 7.1. 少用縮寫
- 7.2. 文件命名
- 7.3. 類型命名
- 7.4. 變量命名
- 7.5. 常量命名
- 7.6. 函數命名
- 7.7. 命名空間命名
- 7.8. 宏命名
- 7.9. 枚舉命名
- 8. 注釋
- 8.1. 文件注釋
- 8.2. 類注釋
- 8.3. 函數注釋
- 8.4. 變量注釋
- 8.5. 實現注釋
- 8.6. TODO 注釋
- 8.7. 棄用注釋
- 9. 格式
- 通用規則
- 9.1. 非 ASCII 字符 / 空格
- 9.2. 函數格式與 Lambda 表達式
- 9.3. 列表初始化格式
- 9.4. 構造函數初始值列表
- 9.5. 條件語句 和 布爾表達式
- 9.6. 循環語句 和 switch 選擇語句
- 9.7. 指針/引用表達式 和 函數返回值
- 9.8. 變量及數組初始化
- 9.9. 預處理指令
前言
雖然在 YuleFox、Yang.Y、acgtyrant等諸位大佬的努力下,Google 開源項目風格指南——中文版已經大幅減輕了我們的學習成本,但是文中部分專業的術語或者表達方式還是讓過于萌新的讀者(比如說我)在流暢的閱讀過程中突遇卡頓,不得不查閱各種資料理清原委,這也是寫學習筆記的初衷。
0. 縮寫名詞解釋
- ODR(One Definition Rule):單一定義規則
- POD(Plain Old Data):原生數據類型
- RVO(Return value optimization):返回值優化
- NRVO(Named Return Value Optimization):具名返回值優化
- RAII(Resource Acquisition Is Initialization):資源獲取就是初始化,保證在任何情況下,使用對象時先構造對象,最后析構對象,是種避免內存泄漏的方法。
- RTTI(Run-Time Type Identification):運行時類型識別
1. 頭文件
1.1. Self-contained 頭文件
Self-contained(自給自足) :所有頭文件要能夠自給自足。換言之,include 該頭文件之后不應該為了使用它而再包含額外的頭文件。舉個例子:
// a.h
class MyClass {
MyClass(std::string s);
};// a.cc
#include “a.h”
int main(){std:string s;MyClass m(s);return 0;
}
a.cc文件會因為沒有 #include <string> 而無法成功編譯。但是,本質原因是因為 a.h 文件用到了 std::string 卻沒有 #include <string>,因此 a.h 文件沒有做到自給自足 (Self-contained )。
特殊情況
- 如果
.h文件聲明并定義了一個模板或內聯函數。那么凡是有用到模版或內聯函數的.cc文件,就必須包含該頭文件(不是.cc文件對應的.h是否包含該頭文件的問題了),否則程序可能會在構建中鏈接失敗。 - 雖然推薦在頭文件中對模版進行聲明并定義,但是如果某函數模板為所有相關模板參數顯式實例化,或本身就是某類的一個私有成員,那么它就只能定義在實例化該模板的
.cc文件里。
1.2. 頭文件保護
頭文件保護旨在防止頭文件被多重包含,當一個頭文件被多次 include 時,可能會出現以下問題:
- 增加編譯工作的工作量;
- 有可能引起錯誤,例如在頭文件中定義了全局變量,重復包含會引起重復定義。
為保證唯一性,通常有兩種解決方法:
- #program once:“同一個文件”指存儲在相同位置的文件,即物理位置下相同;當編譯器意識到文件存儲位置相同時便會跳過“副本文件”,僅僅編譯一次該物理位置的文件;但如果發生拷貝情況,即同一個文件在別的物理位置有“備份”,那么仍然有可能出現重復包含的情況。
- #ifndef—#define—#endif:在#define階段對頭文件進行宏定義(規定別名),頭文件的命名應該基于所在項目源代碼樹的全路徑。注意別名不能重復。
例如,項目 foo 中的頭文件 foo/src/bar/baz.h 可按如下方式保護:
#ifndef FOO_BAR_BAZ_H_ // if not defined,如果FOO_BAR_BAZ_H_沒有被宏定義過
#define FOO_BAR_BAZ_H_ // 那么對FOO_BAR_BAZ_H_進行宏定義
...
#endif // if范圍結束
#program once 較 #ifndef 出現的晚,因此兼容性會較 #ifndef 差一些,但性能會好一些。
1.3. 前置聲明
「前置聲明」(forward declaration)是類、函數和模板的純粹聲明,沒有定義。
優點:
- 省時間,無需編譯不需要的部分,include 會編譯整個頭文件。
- 還是省時間,使用前置聲明時,如果修改頭文件中的無關部分,不會重新編譯整個頭文件。
缺點 - 很難判斷什么時候該用前置聲明,什么時候該用
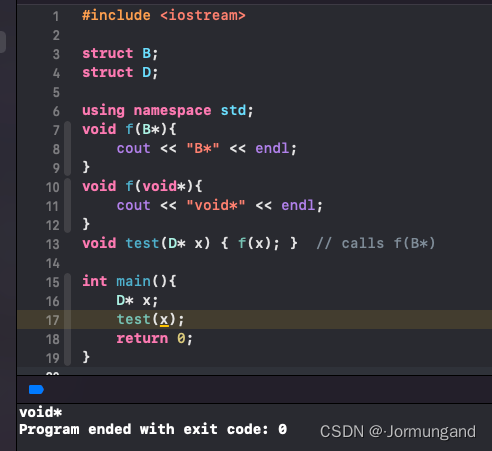
#include。極端情況下,用前置聲明代替#include甚至會改變代碼的含義:
// b.h:
struct B {};
struct D : B {};
// good_user.cc:
#include "b.h"
void f(B*);
void f(void*);
void test(D* x) { f(x); } // calls f(B*)
如果 #include 被 B 和 D 的前置聲明替代,此時由于沒有函數定義,D繼承自B這一關系未顯現,因此調用 test 函數時會調用f(void*)。
實測:
1.4 內聯函數
- 濫用內聯將導致程序變得更慢;
- 最好不要內聯超過
10行的函數; - 謹慎對待析構函數,析構函數往往比其表面看起來要更長,因為有隱含的成員和基類析構函數被調用;
- 內聯那些包含循環或
switch語句的函數常常是得不償失 ; - 有些函數即使聲明為內聯的也不一定會被編譯器內聯:比如虛函數和遞歸函數。
- 通常,遞歸函數不應該聲明成內聯函數。(遞歸調用堆棧的展開并不像循環那么簡單, 比如遞歸層數在編譯時可能是未知的,大多數編譯器都不支持內聯遞歸函數)。
- 虛函數內聯的主要原因則是想把它的函數體放在類定義內,為了圖個方便,亦或是當作文檔描述其行為,比如精短的存取函數。
- 類內部的函數一般會自動內聯。所以某函數一旦不需要內聯,其定義就不要再放在頭文件里,而是放到對應的
.cc文件里。這樣可以使頭文件的類保持精煉,也很好地貫徹了聲明與定義分離的原則。 - 內聯函數必須放在
.h文件中,如果成員函數比較短,也直接放在.h中(讓它成為內聯函數)。
1.5. #include 的路徑及順序
路徑
項目內頭文件應按照項目源代碼目錄樹結構排列,避免使用 UNIX 特殊的快捷目錄: . (當前目錄) 或 .. (上級目錄)。例如,google-awesome-project/src/base/logging.h 應該按如下方式包含:
#include "base/logging.h"
順序
dir/foo.cc 的主要作用是實現或測試 dir2/foo2.h 的功能,foo.cc 中包含頭文件的次序如下:
- 相關頭文件(此處的
dir2/foo2.h) - C 系統文件
- C++ 系統文件
- 其他庫的
.h文件(比如OpenGL和Qt) - 本項目內
.h文件
按字母順序分別對每種類型的頭文件進行二次排序是不錯的主意。
例外:有時,部分 include 語句需要條件編譯(conditional includes),這些代碼可以放到其它 includes 之后。
#include "foo/public/fooserver.h"
#include "base/port.h" // For LANG_CXX11.#ifdef LANG_CXX11
#include <initializer_list>
#endif // LANG_CXX11
內容
- 依賴的符號 (
symbols) 被哪些頭文件所定義,就應該包含(include)哪些頭文件,即使這些頭文件可能已經被已經包含(include)的頭文件包含(include)了。舉例:- 比如要用到
bar.h中的某個符號,哪怕所包含的foo.h已經包含了bar.h,也照樣得包含bar.h, 除非foo.h有明確說明它會自動提供bar.h中的symbol。
- 比如要用到
- 凡是
cc文件所對應的「相關頭文件」已經包含的,就不用再重復包含進cc文件里面了,就像foo.cc只包含foo.h就夠了,不用再管foo.h所包含的其它內容。
2. 作用域
2.1. 命名空間
- 鼓勵在
.cc文件內使用匿名命名空間或static聲明,但不要在.h文件中這么做; - 在頭文件中使用匿名空間違背 C++ 的唯一定義原則 (ODR);
- 不要在頭文件中使用
命名空間別名除非顯式標記內部命名空間使用。 - 使用具名的命名空間時,其名稱可基于項目名或相對路徑;
- 禁止使用
using指示(using-directive); - 禁止使用內聯命名空間(inline namespace);
- 在命名空間的最后注釋出命名空間的名字;
namespace a {
...code for a... // 左對齊 不縮進
} // namespace a/* 即使是匿名空間也需要在最后做出注釋 */
namespace {
...
} // namespace
- 聲明嵌套命名空間時,每個命名空間都獨立成行。
namespace foo {
namespace bar { // 不要有額外縮進
} // namespace bar
} // namespace foo
- 聲明嵌套命名空間時,每個命名空間都獨立成行。
namespace foo {
namespace bar { // 不要有額外縮進
} // namespace bar
} // namespace foo
2.2. 非成員函數、靜態成員函數和全局函數
- 盡量使用 靜態成員函數 或 命名空間內的非成員函數 來代替 裸的(不在命名空間內的)全局函數。對于前兩者而言,如果一個函數跟類沒有密切關系,那么就將它作為非成員函數直接置于命名空間中,即不要隨便用類的靜態方法模擬出命名空間的效果,類的靜態方法應當和類的實例或靜態數據緊密相關。
- 如果必須定義非成員函數,又只是在
.cc文件中使用它,可在.cc文件中使用 匿名命名空間 或 static鏈接關鍵字 限定其作用域。如:
// .cc 文件內
static int Foo() {
...
}
2.3. 局部變量
- 將函數變量盡可能置于最小作用域內,并且不要將初始化分離成 聲明 + 賦值。
- 屬于
if、while和for語句的變量應當在這些語句中聲明,以此將變量的作用域限制在語句中。
有一個例外,如果變量是一個對象,每次進入作用域都要調用其構造函數,每次退出作用域都要調用其析構函數,這會導致效率降低。
// 低效的實現
for (int i = 0; i < 1000000; ++i) {Foo f; // 構造函數和析構函數分別調用 1000000 次!f.DoSomething(i);
}
在循環作用域外面聲明這類變量要高效的多:
Foo f; // 構造函數和析構函數只調用 1 次
for (int i = 0; i < 1000000; ++i) {f.DoSomething(i);
}
2.4. 靜態和全局變量
以下提及的 靜態變量 泛指 靜態生存周期的對象,包括:全局變量、靜態變量、靜態類成員變量以及函數靜態變量。
不定順序問題
同一個編譯單元內初始化順序是明確的,靜態初始化優先于動態初始化(如果動態初始化未被提前),初始化順序按照聲明順序進行,銷毀則逆序。但是不同的編譯單元之間初始化和銷毀順序屬于未明確行為 (unspecified behaviour)。
同時,靜態變量在程序中斷時會被析構,無論所謂中斷是從main()返回還是對exit()的調用。析構順序正好與構造函數調用的順序相反。但如第一段所言,既然構造順序未定義,那么析構順序當然也就不定了。比如,在程序結束時某靜態變量已經被析構了,但代碼還在跑,此時其它線程試圖訪問它且失敗;再比如,一個靜態string變量也許會在一個引用了它的其它變量析構之前被析構掉。
- 靜態生存周期的對象都必須是
POD:即int、char和float,以及POD類型的指針、數組和結構體。即完全禁用vector(可以使用 C 數組替代) 和string(可以使用const char []替代)。 - 如果確實需要一個
class類型的靜態變量,可以考慮在main()函數或pthread_once()內初始化一個指針且永不回收。注意只能用raw(原始) 指針,別用智能指針,畢竟后者的析構函數涉及到不定順序問題。 - 禁止使用類的
static變量:因為它的生命周期不跟隨類的生命周期,因此會導致難以發現的bug。不過constexpr變量除外,畢竟它們又不涉及動態初始化或析構。 - 禁用 類類型的靜態變量。盡量不用全局函數和全局變量,考慮作用域和命名空間限制,盡量單獨形成編譯單元。
- 只能用不涉及任何 靜態變量 的函數其 返回值 來初始化 POD變量。【這里說的不涉及任何靜態變量不包括函數作用域里的靜態變量,畢竟它的初始化順序是有明確定義的,而且只會在指令執行到它的聲明那里才會發生。】
3. 類
3.1. 構造函數的職責
- 構造函數應該只做一件事:初始化成員,但不是一定要初始化全部成員。
- 不要在構造函數中調用虛函數:
- 因為虛函數表指針也是對象的成員之一,是在構造函數初始值列表執行時時才生成的。
- 如果在構造函數內調用了自身的虛函數, 這類調用是不會重定向到子類的虛函數實現。即使當前沒有子類化實現,將來仍是隱患。
- 構造函數內僅允許執行不會失敗的初始化行為,因為在沒有使程序崩潰 (因為并不是一個始終合適的方法) 或者使用異常 (因為已經被禁用了) 等方法的條件下,構造函數很難上報錯誤。
- 如果執行失敗,會得到一個初始化失敗的對象,這個對象有可能進入不正常的狀態,必須使用
bool IsValid()或類似這樣的機制才能檢查出來,然而這是一個十分容易被疏忽的方法。 - 我個人的解決方法:如果是可能失敗的初始化,可以放在類中其他成員函數中進行(如
Init()),不過這就要求嚴格遵循預設的調用順序:構造函數——進行可能失敗初始化的函數——使用類內成員的行為。 - 當類的關系并不單一(有子類/父類存在時),考慮使用工廠模式或工廠方法來進行初始化。【資料參考資料1、資料2】
- 如果執行失敗,會得到一個初始化失敗的對象,這個對象有可能進入不正常的狀態,必須使用
舉個例子,假定A的初始化可能會出錯,因此使用命名空間Initialization內的函數InitializationA來初始化A(方便捕捉錯誤信息),假設B中有A這樣的初始化可能會出錯的成員,也有POD成員,那么POD成員的初始化可以放在構造函數中執行,而A這樣的初始化可能會出錯的成員必須放在一個單獨的成員函數InitMember中去執行,并捕捉錯誤信息且返回。在真正構造B的對象時,必須調用構造函數+InitMember才能完整實現構造行為,之后才能使用B中的成員:
class A{...// 類內詳情不表
};namespace Initialization{
std::string InitializationA(){std::string errorInfo;...// 執行 成員a 的初始化,并且將可能出現的錯誤信息保存到變量errorInfo中并輸出return errorInfo;
}
} // namespace Initializationclass B{A a;... // 其他初始化有可能失敗的成員int bi;
public:B(int bi_):bi(bi_){} // 構造函數中不執行B類成員a的初始化,因為a的初始化可能出錯std::string InitMember(){if (!(Initialization::InitializationA().empty())) { // 如果返回值不為空說明初始化 a 失敗return Initialization::InitializationA(); // 返回錯誤說明}... // 執行其他可能失敗的初始化return NULL; // 所有可能失敗的初始化都成功了,返回空}void useA(){...// 使用 成員a 的代碼}
};int main(){// 調用順序B b(3); // 構造函數b.InitA(); // 初始化 aif(b.InitMember().empty()) {b.useA(); // 有可能失敗的初始化都成功才能使用對應的成員}return 0;
}
3.2. 隱式類型轉換
不要定義隱式類型轉換。對于轉換運算符和單參數構造函數,請使用explicit關鍵字。否則會有類型轉換二義性的問題。
- 拷貝、移動構造函數不應當被標記為
explicit,因為它們并不執行類型轉換。 - 不能以一個參數進行調用的構造函數不應當加上
explicit。初始化器列表構造函數(接受一個std::initializer_list作為參數的構造函數)也應當省略explicit,以便支持拷貝初始化(例如MyType m = {1, 2};)。 - 對于設計目的就是用于對其他類型進行透明包裝的類來說,隱式類型轉換有時是必要且合適的。這時應當寫明注釋以便于理解。
3.3. 可拷貝類型和可移動類型
如果類型不需要支持拷貝/ 移動,就把隱式產生的拷貝和移動函數禁用。因為某種情況下(如:通過傳值的方式傳遞對象)編譯器會隱式調用拷貝和移動函數。
禁用隱式產生的拷貝和移動函數有兩種方法:
- 在
public域中通過=delete:
class A{
public:A() = default; // 使用合成的默認構造函數// class A is neither copyable nor movable.A(const A&) = delete; // 阻止拷貝A &operator=(const A&) = delete; // 阻止賦值
};
- 在舊標準中通過 聲明成
private但不定義的方法 來起到新標準中=delete的作用,此時試圖使用該種函數的用戶代碼將在編譯階段被標記為鏈接錯誤。
復制消除
- 對指南中提到的 拷貝/ 移動構造函數支持Copy elision(復制消除)優化 這一項做出介紹。
- cppreference中文版中關于Copy elision的介紹
- CSDN博客——有保證的復制消除(Guaranteed Copy Elision)
- 知乎——C++ 復制消除示例
總結
- 如果拷貝操作不是一眼就能看出來的,那就不要把類型設置為可拷貝。
- 拷貝的兩個操作(拷貝構造函數和賦值操作)應該同時存在/被禁用,移動的兩個操作(移動構造函數和賦值操作)同理。
- 可拷貝對象都是可移動的,但可移動對象未必是可拷貝的,如:
std::unique_ptr<int>。 - 由于存在 對象切割 的風險,不要為基類提供賦值操作或者拷貝/移動構造函數。如果基類需要可復制屬性,請提供一個
public virtual Clone()和一個protected的拷貝構造函數以供派生類實現。 - 拷貝構造函數使用不當會造成過度拷貝,導致性能上的問題。
- 如果定義了拷貝/移動操作, 則要保證這些操作的默認實現是正確的。記得時刻檢查默認操作的正確性,并且在文檔中說明類是可拷貝的且/或可移動的。
3.4. struct VS class
struct 用來定義包含數據的被動式(等待初始化或賦值)對象,也可以包含相關的常量,但除了存取數據成員之外,沒有別的函數功能。并且存取功能是通過直接訪問位域實現的,而非函數調用。除了構造函數、析構函數、Initialize()、Reset()、Validate() 等類似的用于設定數據成員的函數外,不能提供其它功能的函數。
- 如果需要更多的函數功能,
class更適合。如果拿不準,就用class。 - 為了和
STL保持一致,對于仿函數等特性可以不用class而是使用struct。 - 類和結構體的成員變量使用不同的命名規則。
3.5. 繼承
組合 > 實現繼承 > 接口繼承 > 私有繼承
- 繼承主要用于兩種場合:
- 實現繼承,子類繼承父類的實現代碼;
- 接口繼承,子類僅繼承父類的方法名稱。
- 所有繼承必須是
public的。如果想使用私有繼承,可以把基類的實例作為類內成員。 is-a的情況下才實現繼承,has-a的情況下使用組合。即如果Bar的確 “是一種”Foo,Bar才能繼承Foo。- 有虛函數的類的析構函數必須定義為虛析構函數。
- 對于重寫的虛函數或虛析構函數,使用
override或 (較不常用的)final關鍵字顯式地進行標記。早于C++11的代碼可能會使用virtual關鍵字作為不得已的選項。
3.6. 多重繼承
真正需要用到多重實現繼承的情況少之又少。
多重繼承應遵循:最多只有一個基類是非抽象類;其它基類都是以 Interface 為后綴的純接口類。
3.7. 接口
純接口:
- 這些類的類名以
Interface為后綴(不強制)。
class Foo_Interface {... // 類的具體細節
};
- 除帶實現的虛析構函數、靜態成員函數外,其他均為純虛函數。沒有非靜態數據成員。
- 沒有定義任何構造函數。如果有,也不能帶有參數,并且必須為
protected。 - 如果它是一個子類,也只能從滿足上述條件并以
Interface為后綴的類繼承而來。
為確保接口類的所有實現可被正確銷毀,必須為之聲明虛析構函數(因此析構函數不能是純虛函數)。
3.8. 運算符重載
盡量不要重載運算符,也不要創建用戶定義字面量。不得不使用時提供說明文檔。
不要
- 不要將不進行修改的二元運算符定義為成員函數。如果一個二元運算符被定義為類成員,這時隱式轉換會作用于右側的參數卻不會作用于左側。會出現
a < b能夠通過編譯而b < a不能的情況,這是很讓人迷惑的。 - 不要引入用戶定義字面量,即不要重載
operator""。 - 不要重載
&&、||、,、一元運算符 &。重載一元運算符&會導致代碼具有二義性。重載&&、||和,會導致運算順序和內建運算的順序不一致。
而要
- 合理性。不要為了避免重載操作符而走極端。比如說,應當定義
==、=和<<而不是Equals()、CopyFrom()和PrintTo()。但是,不要只是為了滿足函數庫需要而去定義運算符重載。比如說,如果類型沒有自然順序,而又要將它們存入std::set中,最好還是定義一個自定義的比較運算符(比較函數?)而不是重載<。 - 一致性。只有在意義明顯,不會出現奇怪的行為并且與對應的內建運算符的行為一致時才定義重載運算符。例如:
|要作為位或或邏輯或來使用,而不是作為shell中的管道。 - 模塊化。將類型重載運算符和它們所操作的類型定義在同一個
頭文件中、.cc中和命名空間中。這樣做無論類型在哪里都能夠使用定義的運算符,并且最大程度上避免了多重定義的風險。 - 普適性。如果可能的話,請避免將運算符定義為模板,因為此時它們必須對任何模板參數都能夠作用。
- 整體性。如果你定義了一個運算符,請將其相關且有意義的運算符都進行定義,并且保證這些定義的語義是一致的。例如,如果你重載了
<,那么請將所有的比較運算符都進行重載,并且保證對于同一組參數,<和>不會同時返回true。
3.9. 存取控制與聲明順序
- 不要將大段的函數定義內聯在類定義中。
- 將 所有 數據成員聲明為
private,除非是static const類型成員。 - 類定義一般應以
public:開始,后跟protected:,最后是private:; - 除
public外,其他關鍵詞前要空一行。如果類比較小的話也可以不空。但是關鍵詞后不要保留空行。 - 將類似的聲明放在一起,并且建議以如下的順序:
- 類型 (包括
typedef、using和嵌套的結構體與類) - 常量
- 工廠函數
- 構造函數
- 賦值運算符
- 析構函數
- 其它函數
- 數據成員
- 類型 (包括
4. 函數
如果函數超過 40 行,可以思索一下能不能在不影響程序結構的前提下對其進行分割。
4.1. 引用參數
所有按引用傳遞的參數必須加上 const。
- 在 C 語言中,如果函數需要修改變量的值,參數必須為指針,如
int foo(int *pval)。 - 在 C++ 中,函數還可以聲明為引用參數
int foo(int &val)。
引用參數的優點
- 可以防止在函數體中出現
(*pval)++這樣丑陋的代碼。 - 對于拷貝構造函數而言是必需的。
- 更明確地表示不接受空指針。
引用參數不使用的情況
有時候,在輸入形參中用 const T* 指針比 const T& 更明智。比如:
- 有傳空指針的需求。
- 函數要把指針或對地址(而不是對象)的引用賦值給輸入形參。
- 換言之,可以有指向指針/引用的指針,沒有綁定指針/引用的引用。
- 或者說指針可以操作復合類型,但是引用不可以。
double a = 3.0;
double *p = &a;
double &b = p; // 引用不能綁定地址的引用(指針本身)
double &b = *p; // 引用可以綁定指針指向的對象
4.2. 函數重載
在同一個作用域下,對于相同的函數名:
- 參數類型不同
- 參數順序不同
- 參數個數不同
都可以形成函數的重載。
- 參數名不同
- 返回值不同
不形成重載。
缺點
- 如果函數重載是根據參數順序和參數類型不同,使用時就得十分熟悉 C++ 五花八門的匹配規則,以了解匹配過程。
- 如果派生類只重載了某個函數的部分變體,繼承語義就容易令人困惑。
結論
- 將重載行為改為在函數名里加上參數信息。例如,用
AppendString()和AppendInt()等而不是一口氣重載多個Append()。 - 如果重載函數的目的是為了支持不同數量的同一類型參數,則優先考慮使用
std::vector作為形參以便使用者可以用 列表初始化 傳入實參。
4.3. 缺省參數
- 只允許在非虛函數中使用缺省參數,且必須保證(子類重定義的)缺省參數的值(與父類的同名函數缺省參數的值)始終一致。
- 一般情況下建議使用函數重載,除非缺省函數帶來的可讀性提升彌補了它的缺點。
- 可讀性:更好地區別了 必要參數 和 可選參數(有缺省值的就是可選參數)。
缺點
- 在一個現有函數添加缺省參數,就會改變它的函數簽名,這會干擾函數指針,導致函數簽名與調用點的簽名不一致。而函數重載不會導致這樣的問題。
- C 函數簽名只有函數名
- C++ 函數簽名是函數名 + 參數類型
- 函數簽名在同一作用域內唯一
// Before change.
void func(int a);
func(42);
void (*func_ptr)(int) = &func; // After change.
void func(int a, int b = 10);
func(42); // Still works.
void (*func_ptr)(int) = &func; // Error, wrong function signature./* 此外把自帶缺省參數的函數地址賦值給指針時,會丟失缺省參數信息。*/
void optimize(int level=3);void (*fp)() = &optimize; // 即使參數是缺省的,也不可以省略對類型的說明
// 錯誤 error: invalid conversion from ‘int (*)(int)’ to ‘int (*)()’
void (*fpi)(int) = &optimize; // 正確
- 缺省實參并不一定是常量表達式,可以是任意表達式,甚至可以通過函數調用給出。如果缺省實參是任意表達式,則函數每次被調用時該表達式被重新求值,這會造成生成的代碼迅速膨脹。尤其不要寫像
void f(int n = counter++);這樣的代碼。
int my_rand() {srand(time(NULL));int ra = rand() % 100;return ra;
}void fun(int a, int b = my_rand()) { // 缺省實參是表達式cout << "a = " << a << " b= " << b << endl;
}
- 虛函數調用的缺省參數取決于目標對象的靜態類型,而綁定的具體函數是動態綁定,因此即使基類與派生類缺省參數值是一致的,就會造成閱讀障礙。舉個例子:
#include <iostream>using namespace std;class A {
public: virtual void Fun(int number = 10) { cout << "A::Fun with number " << number; }
}; class B: public A {
public: virtual void Fun(int number = 20){ cout << "B::Fun with number " << number << endl; }
}; int main() { B b; A &a = b; a.Fun(); // 輸出結果是 B::Fun with number 10return 0;
}
輸出結果是B::Fun with number 10。調用虛函數Fun時,A類指針a指向了B類對象b,這就導致缺省值靜態綁定了A類成員函數Fun的缺省值number = 10,而函數內容動態綁定了指向對象B類的成員函數Fun。
結論
可以在以下情況使用缺省參數:
- 位于
.cc文件里的靜態函數或匿名空間函數,畢竟他們的生命周期被限定在局部文件里。 - 可以在構造函數里用缺省參數,畢竟不可能取得構造函數的地址。
- 可以用來模擬變長數組(詳見6.2):
// b、c、d 作為變長數組,維度根據 gEmptyAlphaNum 指定
string StrCat(const AlphaNum &a,const AlphaNum &b = gEmptyAlphaNum,const AlphaNum &c = gEmptyAlphaNum,const AlphaNum &d = gEmptyAlphaNum);
4.4. 輸入和輸出
按值返回 > 按引用返回。 避免返回指針,除非可以為空。
- C++ 函數的輸出可以由返回值提供也可以通過輸出參數提供。盡量使用返回值,因為它的可讀性高,性能更好。
- 某些參數既是輸出參數同時又是輸入參數, Google 開源項目風格指南 中稱之為輸出/輸入參數,而這里將其單純稱之為輸出參數。舉個例子:
void foo (int input1, double input2, int &output){output = output - (input1 + input2); // 函數外繼續使用output對應的實參進行后續操作即可// 什么是純輸出參數呢?// 個人理解就是 outpet 不參與類型運算,僅接受輸入參數運算結果的情況吧// 即上面的語句變更為 output = input1 + input2;
}
- 避免定義需要const引用參數超出生命周期的函數, 比如const引用參數需要與臨時變量綁定的情況。要盡量消除生命周期限制:
- 通過復制參數代替const引用參數;
- 通過const指針傳遞臨時變量并記錄生命周期和非空要求。
- 在給函數參數排序時,將所有輸入參數放在所有輸出參數之前。加入新參數時不要置于參數列表最后,仍然要按照前述的規則,即將新的輸入參數也置于輸出參數之前。
函數參數的類型選擇
- 對于非可選的參數(該參數沒有缺省值):
- 輸入參數通常是值參或const引用;(若用
const T*則說明有特殊情況【詳見4.1】,所以應在注釋中給出相應的理由。) - 輸出參數通常應該是不為空的引用;
- 輸入參數通常是值參或const引用;(若用
- 對于可選的參數:
- 通常使用
std::optional來表示按值輸入; - 使用
const指針來表示其他輸入; - 使用
非const指針來表示輸出參數。 - C++17之
std::optional詳見兩篇博客:- 【C++17之std::optional全方位詳解】
- 【C++17之std::optional】
- 通常使用
4.5. 函數返回類型后置語法
- 前置返回類型:
int foo(int x);
- 在函數名前使用
auto關鍵字,在參數列表之后說明后置返回類型:
auto foo(int x) -> int;
優點
- 后置返回類型是顯式地指定 Lambda 表達式 的返回值的唯一方式。
- 在返回類型依賴于模板參數時,后置返回類型比前置可讀性更高,例如:
// 后置
template <class T, class U> auto add(T t, U u) -> decltype(t + u);
// 前置
template <class T, class U> decltype(declval<T&>() + declval<U&>()) add(T t, U u);
5. 所有權與智能指針
動態分配對象的所有者是一個對象或函數,所有者負責確保當前者無用時就自動銷毀前者。
兩種智能指針
std::unique_ptr離開作用域時(其本身被銷毀),對象就會被銷毀。std::unique_ptr不能被復制,但可以把所指對象移動(move)給新所有者。std::shared_ptr同樣表示動態分配對象的所有權,但可以被共享和復制;對象的所有權由所有復制者共同擁有,最后一個復制者被銷毀時,對象也會隨著被銷毀。
結論
- 對于
const對象來說,智能指針簡單易用,也比深拷貝高效。 - 值語義的開銷經常被高估,所以所有權傳遞帶來的性能提升不一定能彌補可讀性和復雜度的損失。
- 智能指針是一把雙刃劍,雖然不會忘記釋放資源,但是釋放資源的位置不明顯。
- 某些極端情況下 (例如循環引用),所有權被共享的對象永遠不會被銷毀。
- 只有在為避免開銷昂貴的拷貝操作、性能提升非常明顯,并且操作的對象是不可變的(比如說
std::shared_ptr<const Foo>)時候,才該使用std::shared_ptr。
6. 其他 C++ 特性
6.1. 右值引用
- 只在定義移動構造函數與移動賦值操作時使用右值引用,不要使用
std::forward。 - 要高效率地使用某些標準庫類型,例如
std::unique_ptr,std::move是必需的。
6.2. 變長數組和 alloca()
變長數組中的“變”指的是:在創建數組時,可以使用變量指定數組的維度。而不是可以修改已創建數組的大小。一旦創建了變長數組,它的大小則保持不變。
- 變長數組和
alloca()不是標準 C++ 的組成部分(C99中變長數組作為函數形參)。 - 變長數組和
alloca()根據數據大小動態分配堆棧內存,會引起難以發現的內存越界bug: “在我的機器上運行的好好的,發布后卻莫名其妙的掛掉了。”
6.3. 友元
- 友元擴大了(但沒有打破)類的封裝邊界。部分情況下,相對于將類的
private、protected成員聲明為public,使用友元是更好的選擇。尤其是只允許另一個類訪問該類的私有成員時。下面列舉兩個情景:- 將
FooBuilder聲明為Foo的友元,以便FooBuilder正確構造Foo的內部狀態。 - 另一種情景是將一個單元測試類聲明成待測類的友元。
- 將
- 通常友元應該定義在同一文件內,避免代碼讀者跑到其它文件查找使用私有成員的友元。
friend實際上只對函數/類賦予了對其所在類的訪問權限,并不是有效的聲明語句。所以除了在頭文件類內部寫friend函數/類,還要在類作用域之外正式地聲明一遍,最后在對應的.cc文件加以定義。
6.4. 異常
- 禁止使用 C++ 異常.
優點
- 異常是處理構造函數失敗的唯一途徑。雖然可以用工廠函數(
factory function,即「簡單工廠模式」)或Init()方法代替異常,但是前者要求在堆棧分配內存,后者會導致構造函數創建的實例處于“無效”狀態。(調用Init()方法真正完成對類內成員的構造后才能叫做“有效”)
缺點
- 啟用異常會增加二進制文件數據,延長編譯時間(或許影響小),還可能加大地址空間的壓力。
- 濫用異常會變相鼓勵開發者去捕捉不合時宜,或本來就已經沒法恢復的「偽異常」。比如,用戶的輸入不符合格式要求時,也用不著拋異常。如此之類的偽異常列都列不完。
- 在現有函數中添加
throw語句時,必須檢查所有調用點。要么讓所有調用點統統具備最低限度的異常安全保證,要么眼睜睜地看異常一路歡快地往上跑,最終中斷掉整個程序。舉例:f()調用g()、g()又調用h()、且h拋出的異常被f捕獲,忽略了g。
結論
- 對于異常處理,顯然不是短短幾句話能夠說清楚的,以構造函數為例,很多 C++ 書籍上都提到當構造失敗時只有異常可以處理。
- Google 禁止使用異常這一點,說大了,無非是考慮到軟件管理成本,實際使用中還是自己決定。
- 對使用 C++ 異常處理應具有怎樣的態度? 非常值得一讀。
6.5. 運行時類型識別
RTTI 允許程序員在運行時識別 C++ 類對象的類型。它通過使用 typeid 或者 dynamic_cast 完成。
RTTI 有合理的用途但是容易被濫用,因此在使用時請務必注意。
- 在運行時判斷類型通常意味著設計問題。請考慮用以下的兩種替代方案之一來查詢類型:
- 虛函數:把查詢類型交給對象本身去處理,可以根據調用對象的不同而執行不同代碼。
- 類型判斷需要在對象之外完成時,可以考慮使用雙重分發的方案。例如使用訪問者設計模式。
- 如果能夠保證給定的基類實例實際上都是某個派生類的實例,(確保不會發生對象切割)那么就可以使用
dynamic_cast。 - 隨意地使用 RTTI 會使代碼難以維護。它使得基于類型的判斷樹或者
switch語句散布在代碼各處,不方便后續修改。基于類型的判斷樹:
if (typeid(*data) == typeid(D1)) {
...
} else if (typeid(*data) == typeid(D2)) {
...
} else if (typeid(*data) == typeid(D3)) {
...
}
一旦在類層級中加入新的子類,像這樣的代碼往往會崩潰。而且,一旦某個子類的屬性改變了,很難找到并修改所有受影響的代碼塊。
6.6. 類型轉換
不要使用 C 風格類型轉換,而應該使用 C++ 風格。詳見。
6.7. 流
- 流用來替代
printf()和scanf()。 - 不要使用流,除非是日志接口需要,使用
printf + read/write代替。
6.8. 前置自增和自減
- 前置(
++i)通常要比后置(i++)效率更高。因為后置自增/自減會對表達式的值i進行一次拷貝。如果i是迭代器或其他非數值類型,拷貝的代價是比較大的。 - 對簡單數值(非對象),兩種都無所謂。對迭代器和模板類型,使用前置(
++i)自增 / 自減。
6.9. const 和 constexpr
在有需要的情況下都要使用 const,有時改用 C++11 推出的 constexpr 更好。
注意初始化 const 對象時,必須在初始化的同時值初始化。
const 用法
- 為類中的函數加上
const限定符表明該函數不會修改類成員變量的狀態:
class Foo { int Bar(char c) const;
};
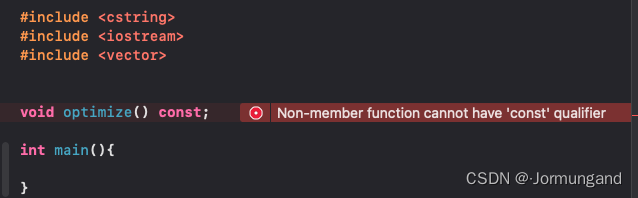
- 非成員函數不能有
const限定符。
const 使用場景
- 如果函數不會修改你傳入的引用或指針類型參數,該參數應聲明為 const。
- 用來訪問成員的函數應該總是 const。
- 不會修改任何數據成員、函數體內未調用非 const 函數、只會返回數據成員 const 指針或引用的函數應該聲明成 const。
- 如果數據成員在對象構造之后不再發生變化,可將其定義為 const。
- 注意修飾指針、引用變量時const有頂層和底層之分。
- 關鍵字 mutable 可以使用,但是在多線程中是不安全的,使用時首先要考慮線程安全。
constexpr
詳見 constexpr和常量表達式
6.10. 整型
<stdint.h>定義了int16_t、uint32_t、int64_t等整型,在需要確保整型大小時可以使用它們代替short、unsigned long long等。在合適的情況下,推薦使用標準類型如size_t和ptrdiff_t。- 不要使用
uint32_t等無符號整型,除非是在表示一個位組而不是一個數值,或是需要定義二進制補碼溢出。尤其是不要為了指出數值永不為負而使用無符號類型,而應使用斷言。 - 如果代碼涉及容器返回的大小(
size),確保接收變量的類型足以應付容器各種可能的用法。拿不準時,類型越大越好。 - 小心整型類型轉換和整型提升(
integer promotions),比如int與unsigned int運算時,前者被提升為unsigned int可能導致溢出。
6.11. 預處理宏
盡量以內聯函數,枚舉和常量代替宏。
這樣代替宏
- 以往用宏展開性能關鍵的代碼,現在可以用內聯函數替代。
- 用宏表示常量可被
const變量代替。 - 用宏 “縮寫” 長變量名可被引用代替。
- 用宏進行條件編譯……這個,千萬別這么做,會令測試更加痛苦 (
#define防止頭文件重包含當然是個特例)。
如果無法避免使用宏
- 宏可以做一些其他技術無法實現的事情,在一些代碼庫 (尤其是底層庫中) 可以看到用
#字符串化,用##連接等等。
如果非要用宏,請遵守:
- 不要在
.h文件中定義宏; - 在馬上要使用時才進行
#define,使用后要立即#undef; - 不要只是對已經存在的宏使用
#undef,也可以選擇一個不會沖突的名稱; - 不要試圖使用展開后會導致 C++ 構造不穩定的宏,非要使用也至少要附上文檔說明其行為;
- 不要用
##處理函數,類和變量的名字。
6.12. 0、nullptr 和 NULL
整數用 0,實數用 0.0,字符 (串) 用 '\0'。
對于指針(地址值),到底是用 0、NULL 還是 nullptr?
- C++11 項目用
nullptr; - C++03 項目則用
NULL,畢竟它看起來像指針。實際上,一些 C++ 編譯器對NULL的定義比較特殊,可以用來輸出警告,比如sizeof(NULL)就和sizeof(0)不一樣。
6.13. sizeof
盡可能用 sizeof(varname) 代替 sizeof(type):
Struct data;
// 如果要使用 sizeof
memset(&data, 0, sizeof(data)); // 這樣做
memset(&data, 0, sizeof(Struct)); // 而不是
- 使用
sizeof(varname)是因為當代碼中變量類型改變時會自動更新。 - 可以用
sizeof(type)處理不涉及任何變量的代碼,比如處理來自外部或內部的數據格式,這時用變量名就不合適了。
if (raw_size < sizeof(int)) {LOG(ERROR) << "compressed record not big enough for count: " << raw_size;return false;
}
6.14. auto
只要可讀性好就可以用 auto 繞過繁瑣的類型名,但別用在局部變量之外的地方。
缺點
- 區分
auto和const auto&的不同之處,否則會復制錯東西。 - 對一般不可見的代理類型(
normally-invisible proxy types)使用auto會有意想不到的陷阱。比如auto和 C++11 列表初始化的合體:
auto x(3); // 圓括號。
auto y{3}; // 大括號。
- 最終結果:
x的類型是int,y的類型則是std::initializer_list<int>。 - 代理人類型詳見:Why is vector not a STL container?
總結
auto還可以和 C++11 特性「尾置返回類型」一起用,不過后者只能用在lambda表達式里。
6.15. 列表初始化
詳見 列表初始化。
6.16. Lambda 表達式
適當使用 lambda 表達式。禁用默認 lambda 捕獲,所有捕獲都要顯式寫出來。
[=](int x) {return x + n;} // 差,可讀性不高
[n](int x) {return x + n;} // 好,讀者一眼看出 n 是被捕獲的值。
C++11 首次提出Lambdas,還提供了一系列處理函數對象的工具,比如多態包裝器 std::function。Lambda 表達式是創建匿名函數對象的一種簡易途徑,常用于把函數當參數傳,例如:
std::sort(v.begin(), v.end(), [](int x, int y) {return Weight(x) < Weight(y);
});
優點
- 傳函數對象給 STL 算法,
Lambdas最簡易,可讀性也好。 Lambdas、std::functions和std::bind可以搭配成通用回調機制;寫接收有界函數為參數的函數也很容易了。
缺點
- Lambdas 的變量捕獲略旁門左道,可能會造成懸空指針。
- Lambdas 可能會失控;層層嵌套的匿名函數難以閱讀。
結論
- 匿名函數始終要簡短,如果函數體超過了五行,那么還不如起名(即把 lambda 表達式賦值給對象),或改用函數。
- 如果可讀性更好,就顯式寫出
lambda的尾置返回類型,就像auto。
6.17. 模板編程
因為模板的維護成本較高,因此最好只用在少量的基礎組件、基礎數據結構上,這樣模版的使用率高,維護模版就是值得的。(如果一個東西用得少,成本還高你會買嗎?)
如果無法避免使用模版編程
- 如果不得不使用模板編程,必須把復雜度最小化,并且盡量不要讓模板對外暴露。最好只在實現里面使用模板,然后給用戶暴露的接口里面并不使用模板,以提高接口的可讀性。
- 在使用模板的代碼上寫盡可能詳細的注釋,注釋應該包含這些代碼是怎么用的,這些模板生成出來的代碼大概是什么樣子的。
- 在用戶錯誤使用你的模板代碼的時候需要輸出更人性化的出錯信息,因為這些出錯信息也是接口的一部分,所以必須做到錯誤信息是易于理解且修改的。
6.18. C++11
C++11 以下特性能不用就不要用:
- 編譯時合數
<ratio>,因為它涉及一個重模板的接口風格。 <cfenv>和<fenv.h>頭文件,因為編譯器尚不支持。- 尾置返回類型,比如用
auto foo() -> int代替int foo()。 - Should the trailing return type syntax style become the default for new C++11 programs? 討論了
auto與尾置返回類型一起用的全新編碼風格,值得一看。
7. 命名約定
這些約定是Google開發團隊遵守的,如果和你的開發團隊的規則相沖突,請遵循你的團隊的規則。
7.1. 少用縮寫
好的做法:
int price_count_reader; // 無縮寫
int num_errors; // "num" 是一個常見的寫法
int num_dns_connections; // 人人都知道 "DNS" 是什么
此外,一些特定的廣為人知的縮寫是允許的,例如用
i表示迭代變量和用T表示模板參數。
壞的做法:
int n; // 毫無意義.
int nerr; // 含糊不清的縮寫.
int n_comp_conns; // 含糊不清的縮寫.
int wgc_connections; // 只有貴團隊知道是什么意思.
int pc_reader; // "pc" 有太多可能的解釋了.
int cstmr_id; // 刪減了若干字母.
7.2. 文件命名
- 文件名要全部小寫,可以包含下劃線 (_) 或連字符 (-)。好的做法:
my_useful_class.cc/my-useful-class.cc/ myusefulclass.ccmyusefulclass_test.cc已棄用。(部分詞語以符號隔開,部分不隔開,不統一)_unittest和_regtest已棄用。(不以符號開頭)
- C++ 文件要以
.cc結尾,頭文件以.h結尾,專門插入文本的文件則以.inc結尾。 - 不要使用已經存在于
/usr/include下的文件名(即編譯器搜索系統頭文件的路徑)。 - 通常應盡量讓文件名更加明確。
http_server_logs.h就比logs.h要好。定義類時文件名一般成對出現,如foo_bar.h和foo_bar.cc。
7.3. 類型命名
類、結構體、類型定義 (typedef)、枚舉、類型模板參數名稱 的每個單詞首字母均大寫,不包含下劃線:
// 類和結構體
class UrlTable { ...
class UrlTableTester { ...
struct UrlTableProperties { ...// 類型定義
typedef hash_map<UrlTableProperties *, string> PropertiesMap;// using 別名
using PropertiesMap = hash_map<UrlTableProperties *, string>;// 枚舉
enum UrlTableErrors { ...
7.4. 變量命名
普通變量命名 / 結構體變量
變量(包括函數參數)和數據成員名一律小寫,單詞之間用下劃線連接。
string table_name; // 好 - 用下劃線.
string tablename; // 好 - 全小寫.string tableName; // 差 - 混合大小寫// 結構體
struct UrlTableProperties {string name;int num_entries;static Pool<UrlTableProperties>* pool;
};
類數據成員
類的成員變量以下劃線結尾。
class TableInfo {...
private:string table_name_; // 好 - 后加下劃線.string tablename_; // 好.static Pool<TableInfo>* pool_; // 好.
};
7.5. 常量命名
聲明為 constexpr 或 const 的變量,或在程序運行期間其值始終保持不變的,命名時以 k 開頭,大小寫混合。例如:
const int kDaysInAWeek = 7;
- 所有具有靜態存儲類型的變量(參見 存儲類型)都應當以此方式命名。
- 對于非靜態的存儲類型的變量,如自動變量等,如果不采用這條規則,就按照一般的變量命名規則。
7.6. 函數命名
- 常規函數使用大小寫混合,取值和設值函數則要求與變量名匹配。
MyExcitingFunction();
my_exciting_member_variable();
set_my_exciting_member_variable();
- 函數名的每個單詞首字母大寫(即 “駝峰變量名” 或 “帕斯卡變量名”),沒有下劃線。對于首字母縮寫的單詞,更傾向于將它們視作一個單詞進行首字母大寫。
StartRpc(); // 好的
StartRPC(); // 不好
- 命名規則同樣適用于類作用域與命名空間作用域的常量,因為它們是作為 API 的一部分暴露對外的,因此應當讓它們看起來像是一個函數。
7.7. 命名空間命名
- 命名空間以小寫字母命名。
- 頂級命名空間的名稱應當是項目名或者是該命名空間中的代碼所屬的團隊的名字。命名空間中的代碼應當存放于和命名空間的名字匹配的文件夾或其子文件夾中。
- 要避免嵌套的命名空間與常見的頂級命名空間發生名稱沖突,尤其是不要創建嵌套的
std命名空間。由于名稱查找規則的存在,命名空間之間的沖突完全有可能導致編譯失敗。 - 要當心加入到同一
internal命名空間的代碼之間發生沖突。 在這種情況下,請使用文件名使內部名稱獨一無二(例如frobber.h,使用websearch::index::frobber_internal)。
7.8. 宏命名
通常 不應該 使用宏,如果不得不用,其命名要像枚舉命名一樣全部大寫,使用下劃線:
#define ROUND(x) ...
#define PI_ROUNDED 3.0
7.9. 枚舉命名
- 單獨的枚舉值應該優先采用 常量 的命名方式(如
kEnumName),但 宏 方式的命名也可以接受。 - 枚舉名
UrlTableErrors/ AlternateUrlTableErrors是類型,所以要用大小寫混合的方式:
enum UrlTableErrors {kOK = 0,kErrorOutOfMemory,kErrorMalformedInput,...
};enum AlternateUrlTableErrors {OK = 0,OUT_OF_MEMORY = 1,MALFORMED_INPUT = 2,...
};
8. 注釋
8.1. 文件注釋
- 每個文件都應該包含許可證引用。為項目選擇合適的許可證版本。
- 如果你對原始作者的文件做了重大修改,請考慮刪除原作者信息。
8.2. 類注釋
- 類注釋應當提供如何使用與何時使用的說明,以及使用的注意事項。
- 如果類有同步前提,請用文檔說明。
- 如果該類的實例可被多線程訪問,要說明多線程環境下相關的規則和常量使用。
- 如果想用一小段代碼演示這個類的基本用法,放在類注釋里也非常合適。
- 如果類的聲明和定義分開了(例如分別放在了
.h和.cc文件中),此時,描述類用法的注釋應當和接口定義放在一起,描述類的操作的注釋應當和實現放在一起。
// Iterates over the contents of a GargantuanTable.
// Example:
// GargantuanTableIterator* iter = table->NewIterator();
// for (iter->Seek("foo"); !iter->done(); iter->Next()) {
// process(iter->key(), iter->value());
// }
// delete iter;
class GargantuanTableIterator {...
};
8.3. 函數注釋
- 基本上每個函數聲明處前都應當加上注釋,描述函數的功能和用途。只有在函數的功能簡單而明顯時才能省略這些注釋。詳細來講應該包含:
- 函數的輸入輸出。
- 對類成員函數而言:函數調用期間對象是否需要保持引用參數,是否會釋放這些參數。
- 函數是否分配了必須由調用者釋放的空間。
- 參數是否可以為空指針。
- 是否存在函數使用上的性能隱患。
- 函數定義部分注釋描述函數如何工作。
- 解釋編程技巧的步驟或實現理由,如:為什么函數的前半部分要加鎖而后半部分不需要。
- 注釋函數重載時,注釋的重點應該是函數中被重載的部分,而不是簡單的重復被重載的函數的注釋。多數情況下,函數重載不需要額外注釋。
- 注釋構造/析構函數時,“銷毀這一對象” 這樣的注釋是沒有意義的,應當注明構造函數對參數做了什么(例如,是否取得指針所有權)以及析構函數清理了什么。如果都是些無關緊要的內容,直接省掉注釋。
8.4. 變量注釋
類數據成員
- 每個成員變量都應該用注釋說明用途。如果變量類型與變量名已經足以描述一個變量,那么就不再需要加上注釋。
- 特別地,如果變量可以接受
NULL或-1等警戒值,須加以說明。比如:
private:// Used to bounds-check table accesses. -1 means// that we don't yet know how many entries the table has.int num_total_entries_;
全局變量
- 所有全局變量也要注釋說明含義及用途,以及作為全局變量的原因。
// The total number of tests cases that we run through in this regression test.
const int kNumTestCases = 6;
8.5. 實現注釋
對于代碼中巧妙的、晦澀的、有趣的、重要的地方加以注釋。
代碼前注釋
// Divide result by two, taking into account that x
// contains the carry from the add.
for (int i = 0; i < result->size(); i++) {x = (x << 8) + (*result)[i];(*result)[i] = x >> 1;x &= 1;
}
行注釋
// If we have enough memory, mmap the data portion too.
mmap_budget = max<int64>(0, mmap_budget - index_->length());
if (mmap_budget >= data_size_ && !MmapData(mmap_chunk_bytes, mlock))return; // Error already logged.
如果你需要連續進行多行注釋,可以使之對齊獲得更好的可讀性:
DoSomething(); // Comment here so the comments line up.
DoSomethingElseThatIsLonger(); // Two spaces between the code and the comment.
{ // One space before comment when opening a new scope is allowed,// thus the comment lines up with the following comments and code.DoSomethingElse(); // Two spaces before line comments normally.
}
std::vector<string> list{// Comments in braced lists describe the next element..."First item",// .. and should be aligned appropriately.
"Second item"};
DoSomething(); /* For trailing block comments, one space is fine. */
函數參數注釋
萬不得已時,才考慮在調用點用注釋闡明參數的意義。
// 參數意義不明,單獨加注釋并不是一個好的解決方案
const DecimalNumber product = CalculateProduct(values, 7, false, nullptr);
不如:
// 用變量options接收上面第二、第三個參數
// 并用變量名解釋他們的含義,這比為兩者添加注釋要好
ProductOptions options;
options.set_precision_decimals(7);
options.set_use_cache(ProductOptions::kDontUseCache);
const DecimalNumber product =CalculateProduct(values, options, /*completion_callback=*/nullptr);
不允許的行為
- 不要描述顯而易見的現象,要假設讀代碼的人 C++ 水平比你高。比如:
// Find the element in the vector. <-- 差: 這太明顯了!
// 或者下面這樣的注釋
// Process "element" unless it was already processed.
auto iter = std::find(v.begin(), v.end(), element);
if (iter != v.end()) {Process(element);
}
- 最好是讓代碼自文檔化,即代碼本身不需要注釋來額外說明。比如:
if (!IsAlreadyProcessed(element)) {Process(element);
}
8.6. TODO 注釋
- 對那些臨時的解決方案,或已經寫好但仍不完美的代碼使用
TODO注釋。 TODO注釋使用全大寫的字符串,在隨后的圓括號里寫上身份標識和與TODO相關的issue。
// TODO(kl@gmail.com): Use a "*" here for concatenation operator.
// TODO(Zeke) change this to use relations.
// TODO(bug 12345): remove the "Last visitors" feature
- 如果加
TODO是為了在 “將來某一天做某事”,可以附上一個非常明確的時間,或者一個明確的事項。
// TODO(bug 12345): Fix by November 2022
// TODO(kl@gmail.com): Remove this code when all clients can handle XML responses.
8.7. 棄用注釋
- 通過棄用注釋(
DEPRECATED:comments)以標記某接口點已棄用。注釋可以放在接口聲明前,或者同一行。 - 同樣的在隨后的圓括號里寫上身份標識。
- 在 C++ 中,你可以將一個棄用函數改造成一個內聯函數,這一函數將調用新的接口。
9. 格式
通用規則
- 書寫格式為可讀性服務。
- 左圓括號和左大括號不要新起一行。
- 右圓括號和左大括號間總是有一個空格。
9.1. 非 ASCII 字符 / 空格
- 盡量不使用非
ASCII字符,使用時必須使用UTF-8編碼。盡量不將字符串常量耦合到代碼中,比如獨立出資源文件,這不僅僅是風格問題了; UNIX/Linux下無條件使用空格,MSVC的話使用Tab也無可厚非;
9.2. 函數格式與 Lambda 表達式
函數參數格式
- 要么一行寫完函數調用:
bool retval = DoSomething(argument1, argument2, argument3);
- 要么在圓括號里對參數分行,后面每一行都和第一個實參對齊,左圓括號后和右圓括號前不要留空格:
bool retval = DoSomething(averyveryveryverylongargument1,argument2, argument3);
- 要么參數另起一行且縮進四格.:
if (...) {DoSomething( // 兩格縮進argument1, argument2, // 4 空格縮進argument3, argument4);
}// 或者
ReturnType LongClassName::ReallyReallyReallyLongFunctionName(Type par_name1, // 4 space indentType par_name2,Type par_name3) {DoSomething(); // 2 space indent...
}
- 如果參數是復雜的表達式,那么可以創建臨時變量描述該表達式,并傳遞給函數:
int my_heuristic = scores[x] * y + bases[x];
bool retval = DoSomething(my_heuristic, x, y, z);
- 或者放著不管,補充上注釋:
bool retval = DoSomething(scores[x] * y + bases[x], // Score heuristic.x, y, z);
- 如果一系列參數本身就有一定的結構,可以酌情地按其結構來決定參數格式:
// 通過 3x3 矩陣轉換 widget.
my_widget.Transform(x1, x2, x3,y1, y2, y3,z1, z2, z3);
函數體格式
// 對于單行函數的實現,在大括號內加上空格,然后是函數實現
void Foo() {} // 大括號里面是空的話, 不加空格.
void Reset() { baz_ = 0; } // 用空格把大括號與實現分開.
void 函數里要不要用 return 語句
從 本討論 來看return;比return ;更約定俗成(事實上cpplint會對后者報錯,指出分號前有多余的空格),且可用來提前跳出函數棧。
Lambda 表達式
- 若用引用捕獲,在變量名和
&之間不留空格:
int x = 0;
auto add_to_x = [&x](int n) { x += n; };
- 短
lambda就寫得和內聯函數一樣:
std::set<int> blacklist = {7, 8, 9};
std::vector<int> digits = {3, 9, 1, 8, 4, 7, 1};
digits.erase(std::remove_if(digits.begin(), digits.end(), [&blacklist](int i) {return blacklist.find(i) != blacklist.end();}),digits.end());
9.3. 列表初始化格式
下面的示例應該可以涵蓋大部分情景:
// 一行列表初始化示范.
return {foo, bar};
functioncall({foo, bar});
pair<int, int> p{foo, bar};// 當不得不斷行時.
SomeFunction({"assume a zero-length name before {"}, // 假設在 { 前有沒有其他參數some_other_function_parameter);SomeType variable{some, other, values,{"assume a zero-length name before {"}, // 假設在 { 前有其他參數SomeOtherType{"Very long string requiring the surrounding breaks.", // 非常長的字符串, 前后都需要斷行.some, other values},SomeOtherType{"Slightly shorter string", // 稍短的字符串.some, other, values}};SomeType variable{"This is too long to fit all in one line"}; // 字符串過長, 因此無法放在同一行.MyType m = { // 注意了, 您可以在 { 前斷行.superlongvariablename1,superlongvariablename2,{short, interior, list},{interiorwrappinglist,interiorwrappinglist2}};
9.4. 構造函數初始值列表
// 如果初始值列表能放在同一行:
MyClass::MyClass(int var) : some_var_(var) {DoSomething();
}// 如果不能放在同一行,
// 必須置于冒號后, 并縮進 4 個空格
MyClass::MyClass(int var): some_var_(var), some_other_var_(var + 1) {DoSomething();
}// 如果初始化列表需要置于多行, 將每一個成員放在單獨的一行
// 并逐行對齊
MyClass::MyClass(int var): some_var_(var), // 4 space indentsome_other_var_(var + 1) { // lined upDoSomething();
}// 右大括號 } 可以和左大括號 { 放在同一行
// 如果這樣做合適的話
MyClass::MyClass(int var): some_var_(var) {}
9.5. 條件語句 和 布爾表達式
if 判斷句的空格要求
if(condition) // 差 - IF 后面沒空格.
if (condition){ // 差 - { 前面沒空格.
if(condition){ // 變本加厲地差.if (condition) { // 好 - IF 和 { 都與空格緊鄰.
執行語句只有一句
只有當語句簡單并且沒有使用 else 子句時允許將簡短的條件語句寫在同一行來增強可讀性:
if (x == kFoo) return new Foo();
if (x == kBar) return new Bar();
如果語句有 else 分支則不允許:
// 不允許 - 當有 ELSE 分支時 IF 塊卻寫在同一行
if (x) DoThis();
else DoThat();
{} - 大括號的使用
Apple 因為沒有正確使用大括號栽過跟頭 ,因此除非 條件語句能寫在一行,否則一定要有大括號。
布爾表達式
邏輯操作符總位于行尾:
if (this_one_thing > this_other_thing &&a_third_thing == a_fourth_thing &&yet_another && last_one) {...
}
9.6. 循環語句 和 switch 選擇語句
循環語句
空循環體應使用 {} 或 continue,而不是一個簡單的分號:
while (condition) {// 反復循環直到條件失效.
}
for (int i = 0; i < kSomeNumber; ++i) {} // 可 - 空循環體.
while (condition) continue; // 可 - contunue 表明沒有邏輯.while (condition); // 差 - 看起來僅僅只是 while/loop 的部分之一.
switch 選擇語句
如果有不滿足 case 條件的枚舉值,switch 應該總是包含一個 default 匹配(如果有輸入值沒有case去處理,編譯器將給出warning)。如果default永遠執行不到,簡單的加條 assert:
switch (var) {case 0: { // 2 空格縮進... // 4 空格縮進break;}case 1: {...break;}default: {assert(false);}
}
9.7. 指針/引用表達式 和 函數返回值
指針/引用表達式
int x, *y; // 不允許 - 在多重聲明中不能使用 & 或 *
char * c; // 差 - * 兩邊都有空格
const string & str; // 差 - & 兩邊都有空格.
函數返回值
return result; // 返回值很簡單, 沒有圓括號.// 可以用圓括號把復雜表達式圈起來, 改善可讀性.
return (some_long_condition &&another_condition);
9.8. 變量及數組初始化
- 用
=、()和{}均可:
int x = 3;
int x(3);
int x{3};
string name("Some Name");
string name = "Some Name";
string name{"Some Name"};
- 小心列表初始化
{...}用std::initializer_list 構造函數初始化出的類型:
vector<int> v(100, 1); // 內容為 100 個 1 的向量.
vector<int> v{100, 1}; // 內容為 100 和 1 的向量.
- 列表初始化不允許整型類型的四舍五入,這可以用來避免一些類型上的編程失誤:
int pi(3.14); // 好 - pi == 3.
int pi{3.14}; // 編譯錯誤: 縮窄轉換.
9.9. 預處理指令
即使位于縮進代碼塊中,預處理指令也應從行首開始:
// 差 - 指令縮進if (lopsided_score) {#if DISASTER_PENDING // 差 - "#if" 應該放在行開頭DropEverything();#endif // 差 - "#endif" 不要縮進BackToNormal();}// 好 - 指令從行首開始if (lopsided_score) {
#if DISASTER_PENDING // 正確 - 從行首開始DropEverything();
# if NOTIFY // 非必要 - # 后跟空格NotifyClient();
# endif
#endifBackToNormal();}








)










