寫在前面
在MySQL數據庫中,索引對查詢的速度有著至關重要的影響,理解索引也是進行數據庫性能調優的起點,索引就是為了提高數據查詢的效率。今天我們來聊聊在MySQL索引優化中兩種常見的方式,索引覆蓋和索引下推索引覆蓋
要了解索引覆蓋,需要先了解幾個索引的基礎知識
B+樹索引
B+樹索引是InnoDB中的一種很常見的索引類型。關于B+樹,這里不做深入的介紹,不太清楚的小胖友可以看單獨介紹B樹、B+樹的文章。簡單來說,是因為使用B+樹存儲數據可以讓一個查詢盡量少的讀磁盤,從而減少查詢時磁盤I/O的時間。在 InnoDB 中,表都是根據主鍵順序以索引的形式存放的,這種存儲方式的表稱為索引組織表。InnoDB 使用了 B+ 樹索引模型,所以數據都是存儲在 B+ 樹中的。每一個索引在 InnoDB 里面對應一棵 B+ 樹。舉例說明,假設我們有一張表,該表主鍵為id,且有用戶名(user_name)和用戶年齡(age)兩個字段,其中age字段上有索引,所以建表語句如下圖所示: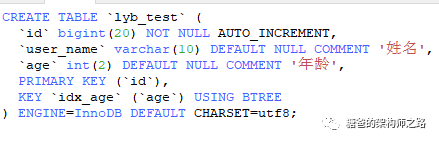
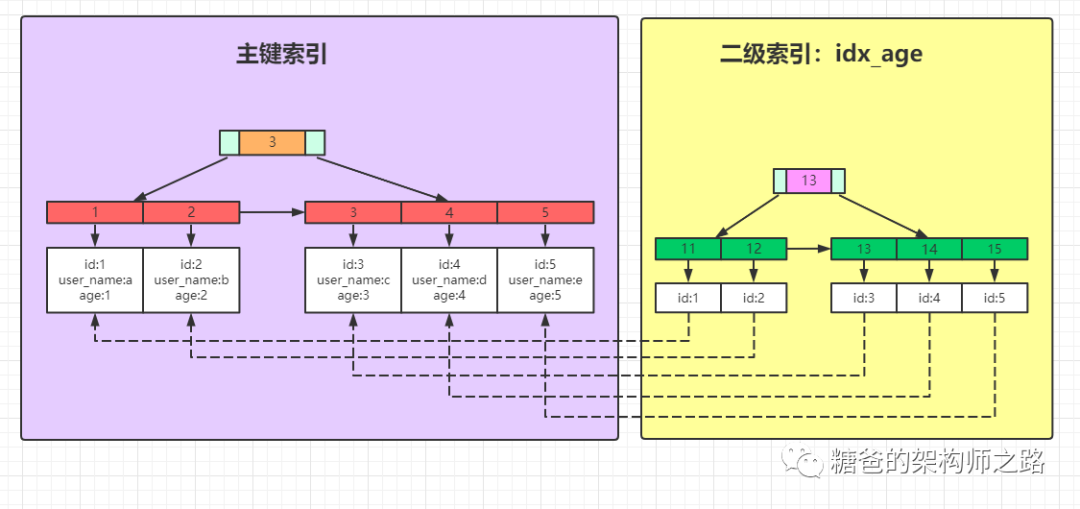
主鍵索引的葉子結點存的是整條記錄,如上圖紫色部分所示
非主鍵索引的葉子結點存的是主鍵的地址值,根據二級索引葉子結點中的地址可以找到主鍵索引中的這一條數據。所以非主鍵索引也被稱為二級索引,如上圖右半邊黃色部分所示
select *from lyb_test where id = 2select?*from?lyb_test?where?age?=?12第一條語句使用主鍵作為檢索條件,即為主鍵查詢,根據上圖所示我們知道,如果是主鍵查詢,我們只需要搜索左邊這顆主鍵索引樹即可快速查詢到id=2的這條數據
第二條語句使用的是二級索引、即age作為檢索條件,這和主鍵查詢有什么區別呢?如果是二級索引查詢,則需要先搜索左側的age索引樹,得到id的值為2,再到右側的主鍵索引樹搜索一次。
像第二種查詢語句這樣,通過非主鍵索引查詢數據時,我們先通過非主鍵索引樹查找到主鍵值,然后再在主鍵索引樹搜索一次(根據rowid再次到數據塊里取數據的操作),這個過程稱為回表,也就是說非主鍵索引查詢會比主鍵查詢多搜索一棵樹
索引覆蓋
結合上面的知識儲備,我們進一步來優化一下剛才的SQL
select *from lyb_test where age = 12select id from lyb_test where age = 12由于查詢的值是ID,而id的值已經在age索引樹上了,因此可以直接提供查詢結果,不需要回表。也就是說,當SQL語句的所有查詢字段(select列)和查詢條件字段(where子句)全都包含在一個索引中,便可以直接使用索引查詢而不需要回表。即在這個查詢里,索引age已經“覆蓋了”我們的查詢需求,故稱為索引覆蓋。
索引下推還是基于剛才的表結構和數據,我們現在針對user_name和age建立聯合索引,索引建立之后,查詢姓名以b開頭且年齡大于等于13的用戶信息,SQL語句如下:
select * from user_table where username like 'b%' and age >= 13根據(username,age)聯合索引查詢所有滿足名稱以"b"開頭的索引,然后回表查詢出相應的全行數據,再篩選出滿足年齡大于等于13的用戶數據。如果表中user_name以b開頭的數據有n條,則需要回表n次
根據(username,age)聯合索引查詢所有滿足名稱以"b"開頭的索引,然后直接再篩選出年齡大于等于13的索引,之后再回表查詢全行數據。經過兩次篩選之后,回表次數一定小于上述第一種情況
SET?optimizer_switch?=?'index_condition_pushdown=off';//?關閉SET?optimizer_switch?=?'index_condition_pushdown=on';//?開啟索引下推一般可用于所求查詢字段(select列)不是/不全是聯合索引的字段,查詢條件為多條件查詢且查詢條件子句(where/order by)字段全是聯合索引。假設表t有聯合索引(a,b),下面語句可以使用索引下推提高效率
select?*?from?t?where?a?>?2?and?b?>?10上述就是索引覆蓋、回表、索引下推的相關概念和使用場景。當然針對MySQL的索引優化還有其他非常多的方式,我們可以在之后的文章中討論。本文到這里就結束啦,謝謝小伙伴們的閱讀~

 - Redis哨兵主備切換的數據丟失問題-阿里云開發者社區...)


(包括模型,增,刪、改等)...)

)











 數據類型)
