
?
Elasticsearch 是一個強大且可擴展的搜索和分析引擎,可用于索引和搜索大量數據。 Elasticsearch 通常用于集群環境中,以提高性能、提供高可用性并實現數據冗余。 在本文中,我們將討論如何在 Ubuntu 20.04 上安裝和配置具有多節點集群的 Elasticsearch 版本 8。

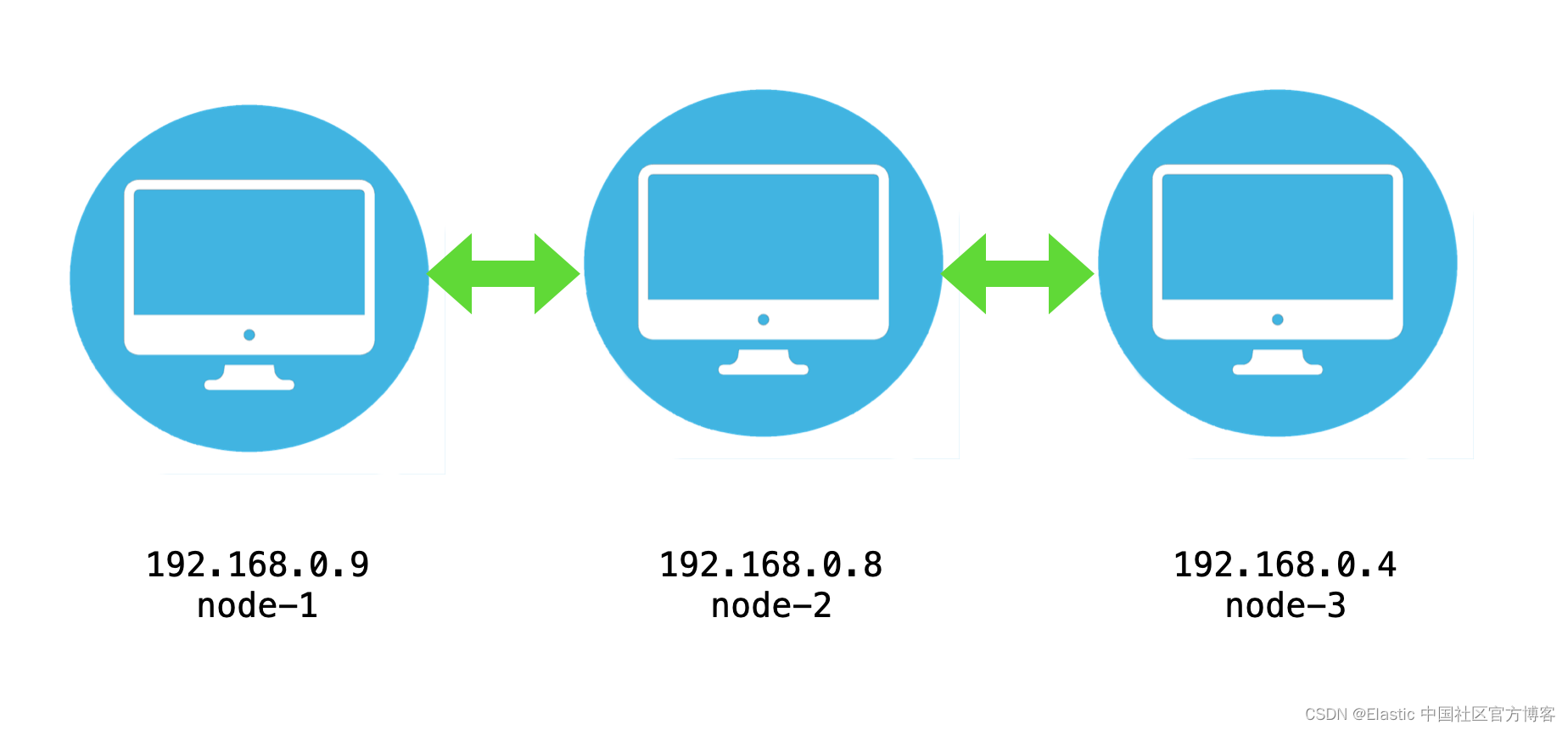
得益于 Elasticsearch 版本 8 的功能,現在部署 Elasticsearch 集群變得更加容易。 你可以在此處查看有關安裝的官方文檔。 在本文中,我們將使用 ubuntu deb 安裝。?在我之前的文章 “Elasticsearch: 使用 Debian 安裝包來安裝 Elasticsearch 8.x” 我詳述了如何使用 Debian 安裝包來安裝具有一個節點的集群。在今天的文章中,我來詳細介紹如何在 Ubuntu 系統上安裝具有三個節點的 Elasticsearch 集群。我的系統配置如下:
?
如上所示,我們在 Ubuntu 系統上的 IP 地址如上所示。我們可以使用如下的命令來獲得當前的系統的 IP 地址:
ifconfig | grep "inet " | grep -Fv 127.0.0.1 | awk '{print $2}'$ ifconfig | grep "inet " | grep -Fv 127.0.0.1 | awk '{print $2}'
192.168.0.9如果你曾經在自己的電腦上安裝過 Elasticsearch,你可以使用如下的命令把之前的安裝全部刪除:
remove.sh
sudo apt remove elasticsearch
sudo apt purge elasticsearch
sudo rm -rf /var/lib/elasticsearchchmod a+x remove.sh
sudo ./remove.sh一旦之前的 Elasticsearch 都被成功地刪除了,那么我們就可開始下面的安裝工作了。安裝 Elasticsearch 集群的簡單步驟如下:
- 在 node-1 上安裝 elasticsearch
- 更新 node-1 的 elasticsearch.yml
- 啟動 elasticsearch 節點1
- 檢查節點健康狀況
- 在 node-2 上安裝 elasticsearch
- 使用節點 1 中的令牌在節點 2 上運行 “elasticsearch-reconfigure-node --enrollment-token <token-here>” 命令
- 更新 node-2 的 elasticsearch.yml
- 啟動 elasticsearch 節點2
- 檢查節點數 GET _cat/nodes
- 在相同或不同節點上安裝 Kibana
- 為 Kibana 創建注冊令牌 elasticsearch-create-enrollment-token -s kibana
- 啟動Kibana
安裝
安裝 node-1
參照官方文檔,我們創建如下的安裝腳本,以便在各個節點上運行:
install.sh
#!/bin/bashwget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo gpg --dearmor -o /usr/share/keyrings/elasticsearch-keyring.gpgapt-get install apt-transport-httpsecho "deb [signed-by=/usr/share/keyrings/elasticsearch-keyring.gpg] https://artifacts.elastic.co/packages/8.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-8.x.listsudo apt-get update && sudo apt-get install elasticsearch我們使用如下的命令來進行安裝:
chmod a+x install.sh
sudo ./install.sh?
在當前的 terminal 下,我們可以看到如下的輸出:

安裝完成后,你需要創建一個數據目錄并將其所有者更改為 Elasticsearch 用戶。 接下來,使用以下設置更新 Elasticsearch 配置文件:
/etc/elasticsearch/elasticsearch.yml
cluster.name: elk-logs
node.name: node-1
network.host: 192.168.0.9
discovery.seed_hosts: ["192.168.0.9"]
cluster.initial_master_nodes: ["192.168.0.9"]
重新加載 systemctl 守護進程,啟用 Elasticsearch 服務,并通過運行以下命令啟動 Elasticsearch 服務:
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearchsystemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch
Created symlink /etc/systemd/system/multi-user.target.wants/elasticsearch.service → /lib/systemd/system/elasticsearch.service.你可以使用以下命令檢查 Elasticsearch 服務的狀態:
systemctl status elasticsearch
你也可以使用如下的命令來進行查看:
service elasticsearch status如果需要的話,我們可以使用如下的命令來重置內置 elastic?用戶的密碼,請運行以下命令:
/usr/share/elasticsearch/bin/elasticsearch-reset-password -i -u elastic比你可以使用以下命令檢查 Elasticsearch 集群健康狀況和節點信息:
curl -k -u elastic:<password> "https://localhost:9200/_cluster/health?pretty"
curl -k -u elastic:<password> "https://localhost:9200/_cat/nodes?v"root@ubuntu2204:~# curl -k -u elastic:password "https://localhost:9200/_cluster/health?pretty"
{"cluster_name" : "elk-logs","status" : "green","timed_out" : false,"number_of_nodes" : 1,"number_of_data_nodes" : 1,"active_primary_shards" : 1,"active_shards" : 1,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}
root@ubuntu2204:~# curl -k -u elastic:password "https://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
127.0.0.1 10 98 7 0.41 0.34 0.26 cdfhilmrstw * ubuntu2204從上面的輸出中,我們可以看到有一個節點的集群已經運行起來了。
你需要創建一個注冊令牌,以便稍后在其他節點中使用以加入現有的 Elasticsearch 集群。 運行以下命令在 Node-1 上創建注冊令牌:
/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node我們可以通過如下的命令來查看 Elasticsearch 的輸出日志:
journalctl -u elasticsearch
如果你覺得歷史日志太長不便于查看,你可以使用如下的命令來清除之前的日志:
sudo journalctl --rotate
sudo journalctl --vacuum-time=1s安裝 node-2
要在 node-2 上安裝 Elasticsearch,我們仿照上面的步驟創建 install.sh,并在它們的機器上運行。
sudo ./install.sh不要啟動 Elasticsearch。 首先,你需要運行以下命令。 以下命令將修改證書、密鑰庫和 elasticsearch.yml。

安裝后,你可以通過運行以下命令將 Elasticsearch 服務配置為使用你在 node-1 中創建的注冊令牌。我們在 node-1 的 terminal 中打入如下的命令:
/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s noderoot@ubuntu2204:~# /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node
eyJ2ZXIiOiI4LjkuMCIsImFkciI6WyIxOTIuMTY4LjAuOTo5MjAwIl0sImZnciI6IjQ5ODRmZDM0ZGJjMTkyNGZjMGI4YmZlZjM4ZTg3NjdjNmUxMzFmNWIxYjAxZGE0MDc4MzI2N2NlODFiMjI5NzQiLCJrZXkiOiI3eGRwLVlrQkhGcVEtMlRPMU1lYTp6dk9rbjEtSFQ1dVEzR3R6MGd4bW5nIn0=我們在 node-2 的 terminal 中打入如下的命令:
/usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token <token-here>root@ubuntu2004:~# /usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token eyJ2ZXIiOiI4LjkuMCIsImFkciI6WyIxOTIuMTY4LjAuOTo5MjAwIl0sImZnciI6IjQ5ODRmZDM0ZGJjMTkyNGZjMGI4YmZlZjM4ZTg3NjdjNmUxMzFmNWIxYjAxZGE0MDc4MzI2N2NlODFiMjI5NzQiLCJrZXkiOiI3eGRwLVlrQkhGcVEtMlRPMU1lYTp6dk9rbjEtSFQ1dVEzR3R6MGd4bW5nIn0=This node will be reconfigured to join an existing cluster, using the enrollment token that you provided.
This operation will overwrite the existing configuration. Specifically: - Security auto configuration will be removed from elasticsearch.yml- The [certs] config directory will be removed- Security auto configuration related secure settings will be removed from the elasticsearch.keystore
Do you want to continue with the reconfiguration process [y/N]y將你在 node-1 上生成的注冊令牌粘貼到 上面的命令中,?并運行命令。 該命令將修改 node-2 中的證書和 elasticsearch.yml
?我們同時對 elasticsearch.yml 文件進行修改:
cluster.name: elk-logs
node.name: node-2
network.host: 192.168.0.8重新加載 systemctl 守護進程,啟用 Elasticsearch 服務,并通過運行以下命令啟動 Elasticsearch 服務:
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch我們通過如下的命令來查看 elasticsearch 服務的狀態:
service elasticsearch status
?同樣地,我們使用如下的命令來查看集群的節點:
curl -k -u elastic:<password> "https://localhost:9200/_cat/nodes?v"curl -k -u elastic:-K2s_i2nsG62iphpNOvY "https://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.0.8 20 98 9 0.09 0.16 0.17 cdfhilmrstw - node-2
192.168.0.9 12 98 5 0.10 0.17 0.18 cdfhilmrstw * node-1請注意在上面,我們使用的密碼和之前的 node-1 中的不同,這是因為我使用了如下的命令修改了 elastic 超級用戶的密碼:
oot@ubuntu2004:/etc/elasticsearch# /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic
This tool will reset the password of the [elastic] user to an autogenerated value.
The password will be printed in the console.
Please confirm that you would like to continue [y/N]yPassword for the [elastic] user successfully reset.
New value: -K2s_i2nsG62iphpNOvY從上面的 node 顯示結果中,我們可以看出來,已經有兩個節點組成了集群。
我們按照上面的步驟,在 node-3 上進行安裝。安裝完畢后,我們使用同樣的命令來進行查看:
root@liuxgu:/etc/elasticsearch# curl -k -u elastic:-K2s_i2nsG62iphpNOvY "https://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.0.8 17 98 7 0.19 0.21 0.18 cdfhilmrstw - node-2
192.168.0.4 4 99 3 0.50 0.53 0.32 cdfhilmrstw - node-3
192.168.0.9 15 98 5 0.11 0.19 0.18 cdfhilmrstw * node-1從上面的顯示中,我們可以看到有三個節點的 Elasticsearch 已經安裝完畢。
重新配置各個節點
添加所有節點后,刪除 node-1 的 Elasticsearch 配置文件中的 “cluster.initial_master_nodes” 設置。 然后,使用主節點的 IP 或主機名將 “discovery.seed_hosts”設置添加到 node-1 的 Elasticsearch 配置文件中。
比如:
刪除節點 1 上的 elasticsearch.yml 文件中的以下設置:
cluster.initial_master_nodes: ["..."]然后,將以下設置添加到 node-1 上的 elasticsearch.yml 文件中:
discovery.seed_hosts: ["192.168.0.9:9300", "192.168.0.8:9300", "192.168.0.4:9300"]請注意,seed_hosts 列表中的 IP 地址和端口號應與集群中符合主節點資格的節點的 IP 地址和端口號相匹配。
首次成功形成集群后,從每個節點的配置中刪除 cluster.initial_master_nodes 設置。 重新啟動集群或向現有集群添加新節點時不應使用此設置。
接下來,更新所有節點上的 elasticsearch.yml 文件中的 discovery.seed_hosts 設置,以包含集群中所有節點(包括該文件所在節點)的 IP 地址和端口號。
最后,創建一個示例 elasticsearch.yml 文件,其中包含集群所需的配置。 此文件應包含 cluster.name、path.data 和 path.logs 設置,以及任何其他必要的設置,例如安全和傳輸設置。
cluster.name: elk-logsxpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:enabled: truekeystore.path: certs/http.p12
xpack.security.transport.ssl:enabled: trueverification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12discovery.seed_hosts: ["192.168.0.9:9300", "192.168.0.8:9300", "192.168.0.4:9300"]
http.host: 0.0.0.0
transport.host: 0.0.0.0不要嘗試將 elasticsearch.yml 復制并粘貼到此處,因為它不起作用。 證書和密鑰庫需要在節點之間匹配:)。
檢查 Elasticsearch 安裝的操作系統級別設置也很重要。 Elasticsearch 文檔提供了有關此主題的指導。
如果需要指定 node.role,可以更新 elasticsearch.yml 文件并重新啟動 Elasticsearch。 node.roles 設置可用于指定節點的角色,例如數據節點或主節點。 Elasticsearch 文檔提供了有關此主題的更多信息。
一旦 Elasticsearch 集群啟動并運行,就可以安裝并配置 Kibana 以連接到集群。 這涉及使用 elasticsearch-create-enrollment-token 命令在其中一個節點上為 Kibana 創建注冊令牌,然后使用注冊令牌在 Kibana 服務器上運行 kibana-setup 命令。 最后就可以啟動Kibana服務了。
如果安裝過程中出現任何問題,可能需要完全刪除 Elasticsearch 并從頭開始。 Elasticsearch 文檔提供了在各種操作系統(包括基于 Debian 的系統)上刪除 Elasticsearch 的說明。
安裝 Kibana
我們將在 node-1 機器上安裝 Kibana。我們運行如下的命令:
sudo apt remove --purge kibana接下來,我們可以運行以下命令來安裝 Kibana:
sudo apt install kibana安裝后,我們需要在其中一個節點上為 Kibana 創建注冊令牌。 為此,請運行以下命令:
sudo /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibanaparallels@ubuntu2204:~$ sudo /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
[sudo] password for parallels:
eyJ2ZXIiOiI4LjkuMCIsImFkciI6WyIxOTIuMTY4LjAuOTo5MjAwIl0sImZnciI6Ijg2NWViYmRmMmQyNDBiMzJjMzI3NDI5MjBmZDBmOGVkMmJlZWZiODlkNzliM2QwODAyYWEwZmNlOGVlZjQ4ZjUiLCJrZXkiOiJmX0MxLVlrQlBZcnJLUkJJMWNPQjpYTzAwN081b1FES1AtWmdNWWkxXzhBIn0=
接下來,我們需要在安裝的節點上運行以下命令,以使用注冊令牌配置 Kibana:
sudo /usr/share/kibana/bin/kibana-setup --enrollment-token <enrollment-token>parallels@ubuntu2204:~$ sudo /usr/share/kibana/bin/kibana-setup --enrollment-token eyJ2ZXIiOiI4LjkuMCIsImFkciI6WyIxOTIuMTY4LjAuOTo5MjAwIl0sImZnciI6Ijg2NWViYmRmMmQyNDBiMzJjMzI3NDI5MjBmZDBmOGVkMmJlZWZiODlkNzliM2QwODAyYWEwZmNlOGVlZjQ4ZjUiLCJrZXkiOiJmX0MxLVlrQlBZcnJLUkJJMWNPQjpYTzAwN081b1FES1AtWmdNWWkxXzhBIn0=? Kibana configured successfully.To start Kibana run:bin/kibana將 <enrollment-token> 替換為上一步中生成的注冊令牌。
最后,我們可以使用以下命令在節點上啟動 Kibana 服務:
sudo systemctl start kibana這是 kibana.yml 的示例:
server.host: 0.0.0.0
elasticsearch.hosts: ['https://192.168.0.9:9200']
logging.appenders.file.type: file
logging.appenders.file.fileName: /var/log/kibana/kibana.log
logging.appenders.file.layout.type: json
logging.root.appenders: [default, file]
pid.file: /run/kibana/kibana.pid
elasticsearch.serviceAccountToken: long-token
elasticsearch.ssl.certificateAuthorities: [/var/lib/kibana/ca_1692111671076.crt]
xpack.fleet.outputs: [{id: fleet-default-output, name: default, is_default: true, is_default_monitoring: true, type: elasticsearch, hosts: ['https://192.168.0.9:9200'], ca_trusted_fingerprint: 865ebbdf2d240b32c32742920fd0f8ed2beefb89d79b3d0802aa0fce8eef48f5}]我們可以在該集群的瀏覽器中打開 Kibana:

 ?
?
 ?
?
這樣我們的 Kibana 的安裝已經完成了。










-計算N個數值的和)








