數據庫操作:
在MongoDB中,文檔集合存在數據庫中。
要選擇使用的數據庫,請在mongo?shell程序中發出 use <db> 語句
// 查看有哪些數據庫
show dbs;// 如果數據庫不存在,則創建并切換到該數據庫,存在則直接切換到指定數據庫。
use school;// 查看當前所在庫
db;// 刪除 先切換到要刪的庫下
use school;// 刪除當前庫
db.dropDatabase();集合操作:
MongoDB將文檔存儲在集合中。集合類似于關系數據庫中的表。
如果不存在集合,則在您第一次為該集合存儲數據時,MongoDB會創建該集合。
// 選擇所在數據庫
// 如果數據庫不存在,則創建并切換到該數據庫,存在則直接切換到指定數據庫。
use dbdb;// 增加集合
// 方式一:當第一個文檔插入時,集合就會被創建并包含該文檔
db.student.insertOne({"name": "張三","age": 12});// 方式二:創建一個空集合
db.student1;// 查看數據庫中有哪些集合
// 方式一:
show collections;// 方式二:
show tables;// 刪除數據庫中的集合
db.student.drop();文檔操作:
MongoDB將數據記錄存儲為BSON文檔。BSON是 ?{
?{
? ?field1: value1,
? ?field2: value2,
? ?field3: value3,
? ?...
? ?fieldN: valueN
}
?字段的值可以是任何BSON 數據類型,包括其他文檔,數組和文檔數組。例如,以下文檔包含各種類型的值:
var mydoc = {
? ? ? ? ? ? ? ?_id: ObjectId("5099803df3f4948bd2f98391"),
? ? ? ? ? ? ? ?name: { first: "Alan", last: "Turing" },
? ? ? ? ? ? ? ?birth: new Date('Jun 23, 1912'),
? ? ? ? ? ? ? ?death: new Date('Jun 07, 1954'),
? ? ? ? ? ? ? ?contribs: [ "Turing machine", "Turing test", "Turingery" ],
? ? ? ? ? ? ? ?views : NumberLong(1250000)
? ? ? ? ? ? }
?上面的字段具有以下數據類型:
-
_id擁有一個ObjectId。
-
name包含一個包含字段first和last的_嵌入式文檔_。
-
birth和death保留_Date_類型的值。
-
contribs擁有_字符串數組_。
-
views擁有_NumberLong_類型的值
字段名稱
段名稱是字符串。
文檔對字段名稱有以下限制:
-
字段名稱
_id保留用作主鍵;它的值在集合中必須是唯一的,不可變的,并且可以是數組以外的任何類型。
-
字段名稱不能包含
null字符。
-
頂級字段名稱不能以美元符號(
$)字符開頭。否則,從MongoDB 3.6開始,服務器允許存儲包含點(即
.)和美元符號(即$)的字段名稱。
重要
MongoDB查詢語言不能總是有效地表達對字段名稱包含這些字符的文檔的查詢(請參閱SERVER-30575)
在查詢語句中添加支持之前,不推薦在字段名稱中使用$和 .,官方MongoDB的驅動程序不支持。
BSON文檔可能有多個具有相同名稱的字段。但是,大多數MongoDB接口都使用不支持重復字段名稱的結構(例如,哈希表)來表示MongoDB。如果需要處理具有多個同名字段的文檔,請參見驅動程序文檔。
內部MongoDB流程創建的某些文檔可能具有重復的字段,但是_任何_ MongoDB流程都_不會_向現有的用戶文檔添加重復的字段。
字段值限制
MongoDB 2.6至MongoDB版本,并將featureCompatibilityVersion(fCV)設置為"4.0"或更早版本
對于索引集合,索引字段的值有一個最大索引鍵長度限制。有關詳細信息,請參見Maximum Index Key Length。
點符號
MongoDB使用_點符號_訪問數組的元素并訪問嵌入式文檔的字段。
數組
要通過從零開始的索引位置指定或訪問數組的元素,請將數組
名稱與點(.)和從零開始的索引位置連接起來,并用引號引起來:
"<array>.<index>"
例如,給定文檔中的以下字段:
{
...
contribs: [ "Turing machine", "Turing test", "Turingery" ],
...
}
要指定contribs數組中的第三個元素,請使用點符號"contribs.2"。
有關查詢數組的示例,請參見:
-
查詢數組
-
查詢嵌入式文檔數組
也可以看看
-
$[\]用于更新操作的所有位置運算符,
-
$[/<identifier/>]過濾后的位置運算符,用于更新操作,
-
$ 用于更新操作的位置運算符,
-
$ 數組索引位置未知時的投影運算符
-
在數組中查詢帶數組的點符號示例。
嵌入式文檔
要使用點符號指定或訪問嵌入式文檔的字段,請將嵌入式文檔名稱與點(.)和字段名稱連接在一起,并用引號引起來:
"<embedded document>.<field>"
例如,給定文檔中的以下字段:
{
...
name: { first: "Alan", last: "Turing" },
contact: { phone: { type: "cell", number: "111-222-3333" } },
...
}
-
要指定在字段中命名
last的name字段,請使用點符號"name.last"。
-
要在字段
number中的phone文檔中 指定contact,請使用點號"contact.phone.number"。
有關查詢嵌入式文檔的示例,請參見:
-
查詢嵌入/嵌套文檔
-
查詢嵌入式文檔數組
文件限制
文檔具有以下屬性:
文檔大小限制
BSON文檔的最大大小為16 MB。
最大文檔大小有助于確保單個文檔不會使用過多的RAM或在傳輸過程中占用過多的帶寬。要存儲大于最大大小的文檔,MongoDB提供了GridFS API。有關GridFS的更多信息,請參見mongofiles和驅動程序的文檔。
文檔字段順序
除_以下情況_外,MongoDB會在執行寫操作后保留文檔字段的順序:
-
該
_id字段始終是文檔中的第一個字段。
-
包含renaming字段名稱的更新可能會導致文檔中字段的重新排序。
_id字段
在MongoDB中,存儲在集合中的每個文檔都需要一個唯一的 _id字段作為主鍵。如果插入的文檔省略了該_id字段,則MongoDB驅動程序會自動為該_id字段生成一個ObjectId。
這也適用于通過使用upsert:true更新操作插入的文檔。
該_id字段具有以下行為和約束:
-
默認情況下,MongoDB 在創建集合期間會在
_id字段上創建唯一索引。
-
該
_id字段始終是文檔中的第一個字段。如果服務器首先接收到沒有該_id字段的文檔,則服務器會將字段移到開頭。
-
該
_id字段可以包含除數組之外的任何BSON數據類型的值。
警告
為確保復制正常進行,請勿在_id 字段中存儲BSON正則表達式類型的值。
以下是用于存儲值的常用選項_id:
-
使用一個ObjectId。
-
使用自然的唯一標識符(如果有)。這樣可以節省空間并避免附加索引。
-
生成一個自動遞增的數字。
-
在您的應用程序代碼中生成一個UUID。為了在集合和
_id索引中更有效地存儲UUID值,請將UUID存儲為BSONBinData類型的值。在以下情況下,
BinData更有效地將類型為索引的鍵存儲在索引中:-
二進制子類型的值在0-7或128-135的范圍內,并且
-
字節數組的長度為:0、1、2、3、4、5、6、7、8、10、12、14、16、20、24或32。
-
-
使用驅動程序的BSON UUID工具生成UUID。請注意,驅動程序實現可能會以不同的方式實現UUID序列化和反序列化邏輯,這可能與其他驅動程序不完全兼容。有關UUID互操作性的信息,請參閱驅動程序文檔。
注意
大多數MongoDB驅動程序客戶端將包括該_id字段,并ObjectId在將插入操作發送到MongoDB之前生成一個;但是,如果客戶發送的文檔中沒有_id 字段,則mongod會添加該_id字段并生成ObjectId。
文檔結構的其他用途
除了定義數據記錄外,MongoDB還在整個文檔結構中使用,包括但不限于:查詢過濾器,更新規范文檔和索引規范文檔。
查詢過濾器文檔
查詢過濾器文檔指定確定用于選擇哪些記錄以進行讀取,更新和刪除操作的條件。
您可以使用 <field>:<value> 表達式指定相等條件和查詢運算符 表達式。
{
? <field1>: <value1>,
? <field2>: { <operator>: <value> },
? ...
}
有關示例,請參見:
-
查詢文檔
-
查詢嵌入/嵌套文檔
-
查詢數組
-
查詢嵌入式文檔數組
更新規范文檔
更新規范文檔使用更新運算符來指定要在db.collection.update()操作期間在特定字段上執行的數據修改。
{
<operator1>: { <field1>: <value1>, ... },
<operator2>: { <field2>: <value2>, ... },
...
}
有關示例,請參閱更新規范。
索引規范文檔
索引規范文檔定義了要索引的字段和索引類型:
{ <field1>: <type1>, <field2>: <type2>, ... }
原文鏈接:
Documents — MongoDB Manual
MongoDB CRUD操作
創建操作
創建或插入操作會將新文檔添加到集合中。 如果該集合當前不存在,則插入操作將創建該集合。
MongoDB提供以下將文檔插入集合的方法:
-
db.collection.insertOne() 3.2版中的新功能
-
?db.collection.insertMany() 3.2版中的新功能
在MongoDB中,插入操作針對單個集合。 MongoDB中的所有寫操作都是單個文檔級別的原子操作。
單條增加
db.test.insertOne({Key:Value,......,Key:Value})
user={"name":"egon","age":10,'hobbies':['music','read','dancing'],'addr':{'country':'China','city':'BJ'}
}db.test.insertOne(user)db.test.insertOne({"name":"egon","age":10,'hobbies':['music','read','dancing'],'adder':{'country':'China','city':'BJ'}
});多條批量增加:
db.user.insertMany([ , , , , ,])的形式
// 多條批量增加
// db.user.insertMany([ , , , , ,])的形式
user1={"_id":11,"name":"alex","age":8,'hobbies':['music','read','dancing'],'addr':{'country':'China','city':'weifang'}
}user2={"_id":12,"name":"wupeiqi","age":8,'hobbies':['music','read','run'],'addr':{'country':'China','city':'hebei'}
}user3={"_id":13,"name":"yuanhao","age":8,'hobbies':['music','drink'],'addr':{'country':'China','city':'heibei'}
}user4={"_id":14,"name":"jingliyang","age":8,'hobbies':['music','read','dancing','tea'],'addr':{'country':'China','city':'BJ'}
}user5={"_id":15,"name":"jinxin","age":8,'hobbies':['music','read',],'addr':{'country':'China','city':'henan'}
}
db.user.insertMany([user1,user2,user3,user4,user5]);db.user.insertMany([{"_id":6,"name":"alex","age":10,'hobbies':['music','read','dancing'],'addr':{'country':'China','city':'weifang'}
},{"_id":7,"name":"wupeiqi","age":20,'hobbies':['music','read','run'],'addr':{'country':'China','city':'hebei'}
},{"_id":8,"name":"yuanhao","age":30,'hobbies':['music','drink'],'addr':{'country':'China','city':'heibei'}
},{"_id":9,"name":"jingliyang","age":40,'hobbies':['music','read','dancing','tea'],'addr':{'country':'China','city':'BJ'}
},{"_id":10,"name":"jinxin","age":50,'hobbies':['music','read',],'addr':{'country':'China','city':'henan'}
}]);讀取操作
讀取操作從集合中檢索文檔; 即查詢集合中的文檔。 MongoDB提供了以下方法來從集合中讀取文檔:
-
db.collection.find()
您可以指定查詢過濾器或條件以標識要返回的文檔。
查的形式有很多,如比較運算、邏輯運算、成員運算、取指定字段、 對數組的查詢、使用正則、獲取數量,還有排序、分頁等等
注:在MongoDB中,用到方法都得用 $ 符號開頭
一、比較運算:
=,!= ('$ne') ,> ('$gt') ,< ('$lt') ,>= ('$gte') ,<= ('$lte')
等于:{ " _id " : 3 }
// select * from db1.user where id = 3
db.user.find({"_id":3
});不等于:?{ " _id " : { " $ne " : 3 }}
// select * from db1.user where id != 3
db.user.find({"_id":{"$ne":3}
});大于:{ " _id " : { " $gt " : 3 }}
// select * from db1.user where id > 3
db.user.find({"_id":{"$gt":3}
});大于等于:{" _id " :? { " $gte " : 3 }}
// select * from db1.user where id >= 3
db.user.find({"_id":{"$gte":3}
});小于: {" age " : {" $lt " : 3 }}
// select * from db1.user where age < 3
db.user.find({"age":{"$lt":3}
});小于等于: {" _id " : {" $lte " : 9 }}
// select * from db1.user where id <= 9
db.user.find({"_id":{"$lte":9}
});二、邏輯運算:
MongoDB中字典內用逗號分隔多個條件是and關系,或者直接用$and,$or,$not(與或非)
$and? 和:
MongoDB中字典內用逗號分隔多個條件是and關系,
// select * from db1.user where id >=3 and id <=6;
db.user.find({"_id":{"$gte":3,"$lte":6}
});
// select * from db1.user where id >=3 and id <=4 and age >=40;
db.user.find({"_id":{"$gte":3,"$lte":4},"age":{"$gte":40}});db.user.find({"$and":[{"_id":{"$gte":3,"$lte":4}},{"age":{"$gte":40}}]
});
$or? ?或:
// select * from db1.user where id >=0 and id <=1 or id >=4 or name = "yuanhao";
db.user.find({"$or":[{"_id":{"$lte":1,"$gte":0}},{"_id":{"$gte":4}},{"name":"yuanhao"}]
})$mod 取余:
// select * from db1.user where id % 2 = 1;
db.user.find({"_id":{"$mod":[2,1]}
});
$not 或:
// select * from db1.user where id % 2 != 1;
db.user.find({"_id":{"$not":{"$mod":[2,1]}}
});三、成員運算:
成員運算無非in和not in,MongoDB中形式為$in , $nin
$in[ ]? 包含列表中的數據
// select * from db1.user where age in (20,30,31);
db.user.find({"age":{"$in":[20,30,31]}
});$nin[ ]? ?不包含列表中的數據???
// select * from db1.user where name not in ('alex','yuanhao');
db.user.find({"name":{"$nin":['Stefan','Damon']}
});??四、正則:正則定義在/ /內
// MongoDB: /正則表達/i
// select * from db1.user where name regexp '^j.*?(g|n)$';
// 匹配規則:j開頭、g或n結尾,不區分大小寫
db.user.find({'name':/^j.*?(g|n)$/i
});?五、查看指定字段:0表示不顯示1表示顯示
// 查詢_id 等于 7 數據,只展示 name、age 字段
// select name,age from db1.user where id=7;
db.user.find({'_id':7
},{'_id':0,'name':1,'age':1
});
六、對數組的查詢:
查hobbies中有dancing的人
db.user.find({"hobbies":"dancing"
});查詢子文檔有"country" : "China"的人
addr? 字段中 {key = country? value = China}
db.user.find({"addr.country":"China"
});

查看既有dancing愛好又有tea愛好的人?
$all : [ " dancing " , " tea " ]? 包含集合中所有的數據
db.user.find({"hobbies":{"$all":["dancing","tea"]}
});查看第2個愛好為dancing的人
. 1 是數組中的下標
db.user.find({"hobbies.1":"dancing"
});?查看所有人的第2個到第3個愛好?
$slice : [ 1 , 2 ]? 取下標為 1 , 2? 的數據
db.user.find({},{"_id":0,"name":0,"age":0,"addr":0,"hobbies":{"$slice":[1,2]},
});?查看所有人最后兩個愛好,第一個{}表示查詢條件為所有,第二個是顯示條件
$slice : -2? 取后倆位
db.user.find({},{"_id":0,"name":0,"age":0,"addr":0,"hobbies":{"$slice":-2},
});
七、對查詢結果進行排序:
sort() 1代表升序、-1代表降序
// 按name字段升序
db.user.find().sort({"name":1,});// 按_id字段升序 age 降序
db.user.find().sort({"age":-1,'_id':1});八、分頁:
limit表示取多少個document(文件),
skip代表跳過幾個document(文件)
// 前兩個
db.user.find().limit(2).skip(0); // 第三個和第四個
db.user.find().limit(2).skip(2); // 第五個和第六個
db.user.find().limit(2).skip(4);
九、獲取數量:count()
// 查詢年齡大于30的人數
// 方式一:
db.user.count({'age':{"$gt":30}
});// 方式二:
db.user.find({'age':{"$gt":30}
}).count();
十、查找所有
db.user.find(); db.user.find({})十一、去重 distinct()
db.user.distinct("age");十二、查找key為null的項
db.t2.find({"b":null
});十三、MongoDB聚合
| 表達式 | 描述 | 實例 |
|---|---|---|
| $sum | 計算總和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 計算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 獲取集合中所有文檔對應值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 獲取集合中所有文檔對應值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 將值加入一個數組中,不會判斷是否有重復的值。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 將值加入一個數組中,會判斷是否有重復的值,若相同的值在數組中已經存在了,則不加入。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根據資源文檔的排序獲取第一個文檔數據。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根據資源文檔的排序獲取最后一個文檔數據 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}] |
管道的概念
管道在Unix和Linux中一般用于將當前命令的輸出結果作為下一個命令的參數。
MongoDB的聚合管道將MongoDB文檔在一個管道處理完畢后將結果傳遞給下一個管道處理。管道操作是可以重復的。
表達式:處理輸入文檔并輸出。表達式是無狀態的,只能用于計算當前聚合管道的文檔,不能處理其它的文檔。
這里我們介紹一下聚合框架中常用的幾個操作:
- $project:修改輸入文檔的結構。可以用來重命名、增加或刪除域,也可以用于創建計算結果以及嵌套文檔。
- $match:用于過濾數據,只輸出符合條件的文檔。$match使用MongoDB的標準查詢操作。
- $limit:用來限制MongoDB聚合管道返回的文檔數。
- $skip:在聚合管道中跳過指定數量的文檔,并返回余下的文檔。
- $unwind:將文檔中的某一個數組類型字段拆分成多條,每條包含數組中的一個值。
- $group:將集合中的文檔分組,可用于統計結果。
- $sort:將輸入文檔排序后輸出。
- $geoNear:輸出接近某一地理位置的有序文檔。
管道操作符實例
1、$project實例
db.article.aggregate({ $project : {title : 1 ,author : 1 ,}});這樣的話結果中就只還有_id,tilte和author三個字段了,默認情況下_id字段是被包含的,如果要想不包含_id話可以這樣:
db.article.aggregate({ $project : {_id : 0 ,title : 1 ,author : 1}});2、$match實例
db.articles.aggregate( [{ $match : { score : { $gt : 70, $lte : 90 } } },{ $group: { _id: null, count: { $sum: 1 } } }] );$match用于獲取分數大于70小于或等于90記錄,然后將符合條件的記錄送到下一階段$group管道操作符進行處理。
3、$skip實例
db.article.aggregate({ $skip : 5 });經過$skip管道操作符處理后,前五個文檔被"過濾"掉。
更新操作
更新操作會修改集合中的現有文檔。 MongoDB提供了以下更新集合文檔的方法:
-
db.collection.updateOne() 3.2版中的新功能
-
db.collection.updateMany() 3.2版中的新功能
-
db.collection.replaceOne() 3.2版中的新功能
列子1:
$$NOW? 當前時間
創建一個示例students學生集合(如果該集合當前不存在,則插入操作將創建該集合):
db.students.insertMany([{ _id: 1, test1: 95, test2: 92, test3: 90, modified: new Date("01/05/2020") },{ _id: 2, test1: 98, test2: 100, test3: 102, modified: new Date("01/05/2020") },{ _id: 3, test1: 95, test2: 110, modified: new Date("01/04/2020") }
])查詢集合:?
db.students.find()?以下db.collection.updateOne()操作使用聚合管道使用**_id**更新文檔:3
db.students.updateOne( { _id: 3
}, [ { $set: {"test3": 98, modified: "$$NOW"}
} ]
);具體地說,管道包括$set階段,該階段將test3字段(并將其值設置為98)添加到文檔中,并將修改后的字段設置為當前日期時間。 對于當前日期時間,該操作將聚合變量NOW 用于(以訪問變量,以**$$**為前綴并用引號引起來)。
列子2:
$replaceRoot???
$mergeObjects?
$$ROOT
創建一個示例students2集合(如果該集合當前不存在,則插入操作將創建該集合):
db.students2.insertMany([{"_id": 1,quiz1: 8,test2: 100,quiz2: 9,modified: new Date("01/05/2020")},{"_id": 2,quiz2: 5,test1: 80,test2: 89,modified: new Date("01/05/2020")},])db.students2.updateMany({}, [{$replaceRoot: {newRoot:{$mergeObjects: [{quiz1: 0,quiz2: 0,test1: 0,test2: 0}, "$$ROOT"]}}},{$set: {modified: "$$NOW"}}
])?具體來說,管道包括:
-
$replaceRoot 階段,帶有 $mergeObjects表達式,可為quiz1,quiz2,test1和test2字段設置默認值。 聚集變量ROOT 指的是正在修改的當前文檔(以訪問變量,以**$$**為前綴并用引號引起來)。 當前文檔字段將覆蓋默認值。
-
$set 階段用于將修改的字段更新到當前日期時間。 對于當前日期時間,該操作將聚合變量NOW用于(以訪問變量,以**$$**為前綴并用引號引起來)。
列子3:
$switch
$switch :{?
? ? ? ? 元素:[?
? ? ? ? ? ? ? ? {case:? { $get:[ 元素,數值?] },then:" 數值?"},
????????????????{case:? { $get:[ 元素,數值?] },then:" 數值?"},?
????????????????{case:? { $get:[ 元素,數值?] },then:" 數值?"},??
? ? ? ? ? ? ? ? ? ? ? ],
????????????????????????default: "F"
? ? ? ? ? ? ? ? }
創建一個示例students3集合(如果該集合當前不存在,則插入操作將創建該集合):
db.students3.insert([{ "_id" : 1, "tests" : [ 95, 92, 90 ], "modified" : ISODate("2019-01-01T00:00:00Z") },{ "_id" : 2, "tests" : [ 94, 88, 90 ], "modified" : ISODate("2019-01-01T00:00:00Z") },{ "_id" : 3, "tests" : [ 70, 75, 82 ], "modified" : ISODate("2019-01-01T00:00:00Z") }
]);?以下 db.collection.updateMany()操作使用聚合管道以計算的平均成績和字母成績更新文檔。
db.students3.updateMany({ }, [{ $set: { average : { $trunc: [ { $avg: "$tests" }, 0 ] }, modified: "$$NOW" } }, { $set: { grade: { $switch: { branches: [ { case: { $gte: [ "$average", 90 ] }, then: "A" }, { case: { $gte: [ "$average", 80 ] }, then: "B" }, { case: { $gte: [ "$average", 70 ] }, then: "C" }, { case: { $gte: [ "$average", 60 ] }, then: "D" } ],default: "F" } } } }])-
$set階段來計算測試數組元素的截斷平均值,并將修改后的字段更新為當前日期時間。 要計算截斷的平均值,此階段使用**$avg和$trunc 表達式。 對于當前日期時間,該操作將聚合變量NOW 用于(以訪問變量,以$$**為前綴并用引號引起來).
-
一個$set 階段,用于使用$switch 表達式根據平均值添加年級字段。
例子4:
$concatArrays
創建一個示例students4集合(如果該集合當前不存在,則插入操作將創建該集合):
db.students4.insertMany([{ "_id" : 1, "quizzes" : [ 4, 6, 7 ] },{ "_id" : 2, "quizzes" : [ 5 ] },{ "_id" : 3, "quizzes" : [ 10, 10, 10 ] }
])?以下db.collection.updateOne()操作使用聚合管道將測驗分數添加到具有**_id**的文檔中:2
db.students4.updateOne( { _id: 2 },[ { $set: { quizzes: { $concatArrays: [ "$quizzes", [ 8, 6 ] ] } } } ]
)?例子5:
$addFields
$map
$add
$multiply
$$celsius
創建一個示例temperatures集合,其中包含攝氏溫度(如果該集合當前不存在,則插入操作將創建該集合):
db.temperatures.insertMany([{ "_id" : 1, "date" : ISODate("2019-06-23"), "tempsC" : [ 4, 12, 17 ] },{ "_id" : 2, "date" : ISODate("2019-07-07"), "tempsC" : [ 14, 24, 11 ] },{ "_id" : 3, "date" : ISODate("2019-10-30"), "tempsC" : [ 18, 6, 8 ] }
])?以下db.collection.updateMany()操作使用聚合管道以華氏度中的相應溫度更新文檔:
db.temperatures.updateMany( { },[{ $addFields: { "tempsF": {$map: {input: "$tempsC",as: "celsius",in: { $add: [ { $multiply: ["$$celsius", 9/5 ] }, 32 ] }}} } }]
)?具體來說,管道由$addFields階段組成,以添加一個新的數組字段tempsF,其中包含華氏溫度。 要將tempsC數組中的每個攝氏溫度轉換為華氏溫度,該階段將$map表達式與$add和 $multiply表達式一起使用。
// 常規修改操作:
// 設數據為{'name':'武松','age':18,'hobbies':['做煎餅','吃煎餅','賣煎餅'],'addr':{'country':'song','province':'shandong'}}
// update db1.user set age=23,name="武大郎" where name="武松";
// 覆蓋式
db.user.updateOne({"name":"潘金蓮"},{$set:{"age":23,"name":"武大郎"}});
// 得到的結果為{"age":23,"name":"武大郎"}// 局部修改:$set
db.user.updateOne({"name":"武松"},{"$set":{"age":15,"name":"潘金蓮"}});
// 得到的結果為{"name":"潘金蓮","age":15,'hobbies':['做煎餅','吃煎餅','賣煎餅']}// 改多條:將multi參數設為true
db.user.updateMany({"_id":{"$gte":5,"$lte":7}},{$set:{"age":53}},{multi: true,upsert: false, writeConcern: true });
db.getCollection("user").find({}).sort({_id: 1}).limit(21)
// 有則修改,無則添加:upsert參數設為true
db.user.updateOne({"name":"EGON"},{"$set":{"name":"EGON","age":28,}},{"upsert":true});// 修改嵌套文檔:將國家改為日本
db.user.updateOne({"name":"潘金蓮"},{"$set":{"addr.country":"Japan"}});// 修改數組:將第一個愛好改為洗澡
db.user.updateOne({"name":"潘金蓮"},{"$set":{"hobbies.1":"洗澡"}});// 刪除字段:不要愛好了
db.user.updateOne({"name":"潘金蓮"},{"$unset":{"hobbies":""}});加減操作:$inc
// 年齡都+1
db.user.updateMany({},{"$inc":{"age":1}});// 年齡都-10
db.user.updateMany({},{"$inc":{"age":-10}},);添加刪除數組內元祖$push $pop $pull
// $push的功能是往現有數組內添加元素
// 為名字為武大郎的人添加一個愛好read
db.user.updateOne({"name":"武大郎"},{"$push":{"hobbies":"read"}});// 為名字為武大郎的人一次添加多個愛好tea,dancing
db.user.updateOne({"name":"武大郎"},{"$push":{"hobbies":{"$each":["tea","dancing"]}}});// $pop的功能是按照位置只能從頭或從尾即兩端刪元素,
// 類似于隊列。1代表尾,-1代表頭
// {"$pop":{"key":1}} 從數組末尾刪除一個元素db.user.updateOne({"name":"武大郎"},{"$pop":{"hobbies":1}
});// {"$pop":{"key":-1}} 從頭部刪除
db.user.updateOne({"name":"武大郎"},{"$pop":{ "hobbies":-1}
});// $pull可以自定義條件刪除
db.user.updateMany({'addr.country':"China"},{"$pull":{"hobbies":"read"}});避免重復添加 $addToSet 即多個相同元素要求插入時只插入一條
db.urls.insertOne({"_id":1,"urls":[]});db.urls.updateOne({"_id":1},{"$addToSet":{"urls":{"$each":['http://www.baidu.com','http://www.baidu.com','http://www.xxxx.com']}}});
限制大小"$slice",只留最后n個
db.user.updateOne({"_id":6},{"$push":{"hobbies":{"$each":["read",'music','dancing'],"$slice":-2 // 保留后兩位}}
});排序The $sort element value must be either 1 or -1"
注意:不能只將"$slice"或者"$sort"與"$push"配合使用,且必須使用"$each"
db.user.updateOne({"_id":7},{"$push":{"hobbies":{"$each":["read",'music','dancing'],// 保留后一位"$slice":-1, // 倒序"$sort":-1}}
});附加方法
以下方法還可以更新集合中的文檔:
-
db.collection.findOneAndReplace().
-
db.collection.findOneAndUpdate().
-
db.collection.findAndModify().
-
db.collection.save().
-
db.collection.bulkWrite().
聚合管道更新
從MongoDB 4.2開始,您可以將聚合管道用于更新操作。 通過更新操作,聚合管道可以包括以下階段:
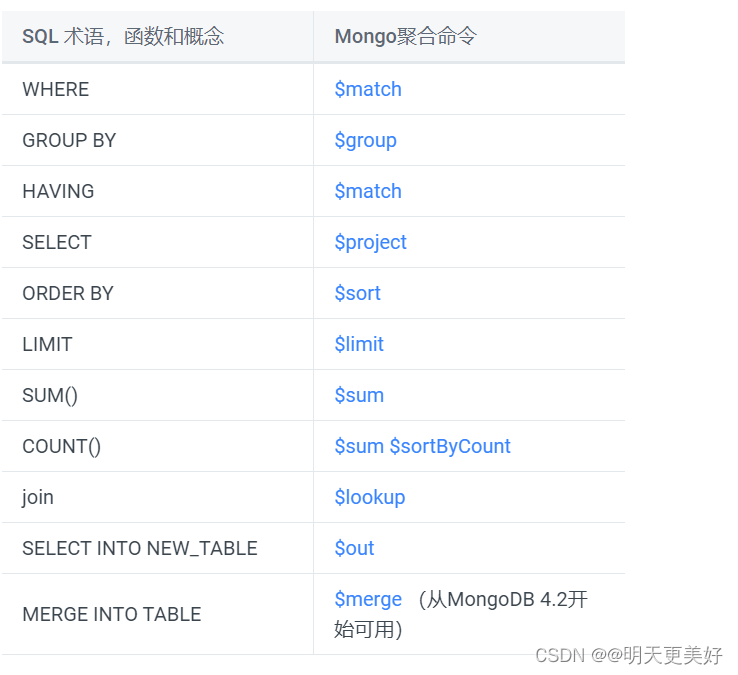
| ?$addFields? | ?$set? |
| ?$project? | ?$unset? |
| ?$replaceRoot? | ?$replaceWith? |
使用聚合管道允許使用表達性更強的update語句,比如根據當前字段值表示條件更新,或者使用另一個字段的值更新一個字段。
在MongoDB中,更新操作針對單個集合。 MongoDB中的所有寫操作都是單個文檔級別的原子操作。
您可以指定標準或過濾器,以標識要更新的文檔。 這些過濾器使用與讀取操作相同的語法。
聚合操作:
我們在查詢時肯定會用到聚合,在MongoDB中聚合為aggregate,聚合函數主要用到
????????$match ????????$group ????????$avg???????? $project???????? $concat
$match和 $group:相當于sql語句中的where和group by{"$match":{"字段":"條件"}},可以使用任何常用查詢操作符$gt,$lt,$in等
// select * from db1.emp where post='公務員';
db.emp.aggregate({"$match":{"post":"公務員"}});// select * from db1.emp where id > 3 group by post;
db.emp.aggregate({"$match":{"_id":{"$gt":3}}},{$group:{"_id":"$post",'avg_salary':{$avg:"$salary"}}});
db.emp.aggregate({"$match":{"_id":{"$gt":5}}},{"$group":{"_id":"$post"}})
// select * from db1.emp where id > 3 group by post having avg(salary) > 10000;
db.emp.aggregate({"$match":{"_id":{"$gt":3}}},{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}},{"$match":{"avg_salary":{"$gt":10000}}});
//可將分組字段傳給$group函數的_id字段即
{"$group":{"_id":分組字段,"新的字段名":聚合操作符}}// 按照性別分組
{"$group":{"_id":"$sex"}}; // 按照職位分組
{"$group":{"_id":"$post"}}; 按照多個字段分組,比如按照州市分組
{"$group":{"_id":{"state":"$state","city":"$city"}}}; 分組后聚合得結果,類似于sql中聚合函數的聚合操作符:$sum、$avg、$max、$min、$first、$last
// select post,max(salary) from db1.emp group by post;
db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"}}
});// 取每個部門最大薪資與最低薪資
db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}
});// 如果字段是排序后的,那么$first,$last會很有用,比用$max和$min效率高
db.emp.aggregate({"$group":{"_id":"$post","first_id":{"$first":"$_id"}}
});// 求每個部門的總工資
db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":"$salary"}}
});// 求每個部門的人數
db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":1}}
});// 數組操作符
// {"$addToSet":expr};// 不重復
// {"$push":expr};// 重復// 查詢崗位名以及各崗位內的員工姓名:select post,group_concat(name) from db1.emp group by post;
db.emp.aggregate({"$group":{"_id":"$post","names":{"$push":"$name"}}
});
db.emp.aggregate({"$group":{"_id":"$post","names":{"$addToSet":"$name"}}
});// $project:用于投射,即設定該鍵值對是否保留。1為保留,0為不保留,可對原有鍵值對做操作后增加自定義表達式
// {"$project":{"要保留的字段名":1,"要去掉的字段名":0,"新增的字段名":"表達式"}}// #select name,post,(age+1) as new_age from db1.emp;
db.emp.aggregate({$project:{"name":1,"post":1,"new_age":{$add:["$age",1]}}
});
排序:$sort、限制:$limit、跳過:$skip
// {"$sort":{"字段名":1,"字段名":-1}} #1升序,-1降序
// {"$limit":n}
// {"$skip":n} #跳過多少個文檔//例1、取平均工資最高的前兩個部門
db.emp.aggregate({"$group":{"_id":"$post","平均工資":{"$avg":"$salary"}}},{"$sort":{"平均工資":-1}},{"$limit":2})
//例2、
db.emp.aggregate({"$group":{"_id":"$post","平均工資":{"$avg":"$salary"}}},{"$sort":{"平均工資":-1}},{"$limit":2},{"$skip":1})// 隨機選取n個:$sample
// 集合users包含的文檔如下
db.users.insertMany(
[{ "_id" : 1, "name" : "dave123", "q1" : true, "q2" : true },
{ "_id" : 2, "name" : "dave2", "q1" : false, "q2" : false },
{ "_id" : 3, "name" : "ahn", "q1" : true, "q2" : true },
{ "_id" : 4, "name" : "li", "q1" : true, "q2" : false },
{ "_id" : 5, "name" : "annT", "q1" : false, "q2" : true },
{ "_id" : 6, "name" : "li", "q1" : true, "q2" : true },
{ "_id" : 7, "name" : "ty", "q1" : false, "q2" : true }]);// 下述操作時從users集合中隨機選取3個文檔
db.users.aggregate([ { $sample: { size: 3 } } ]);// CREATE TABLE USERS(a Number, b Number)
db.users// INSERT INTO USERS VALUES(1, 1)
db.users.insertOne({'a':1, 'b':1});//SELECT a, b FROM USERS
db.users.find({}, {'a':1, 'b':1});//SELECT * FROM USERS
db.users.find();//SELECT a, b FROM USERS WHERE age=33 and name='Jack'
db.users.find({'age':33, 'name':'Jack'}, {'a':1, 'b':1});//SELECT * FROM USERS WHERE age=33 ORDER BY name
db.users.find({'age':33}).sort({'name': 1});//SELECT * FROM USERS WHERE age>33
db.users.find({'age':{'$gt':33}});//SELECT * FROM USERS WHERE age<33
db.users.find({'age':{'$lt':33}});//SELECT * FROM USERS WHERE name LIKE '%Jack%'
db.users.find({'name': '/Jack/'});//SELECT * FROM USERS WHERE name LIKE 'Jack%'
db.users.find({'name': '/^Jack/'});//SELECT * FROM USERS WHERE age>33 AND age < 40
db.users.find({'age':{'$gt':33, '$lt':40}});//SELECT * FROM USERS ORDER BY name DESC
db.users.find().sort({'name': -1});//SELECT * FROM USERS LIMIT 1
db.users.findOne();//SELECT * FROM USERS LIMIT 10 SKIP 20
db.users.find().limit(1).skip(1);//SELECT * FROM USERS WHERE age=33 or name='Jack'
db.users.find({
$or:[{"q1":true},{"name":"Jack"}
]});//SELECT DISTINCT last_name FROM USERS
db.users.distinct('name');//SELECT COUNT(*) FROM USERS
db.users.count();//SELECT COUNT(*) FROM USERS WHERE age=33
db.user.find({'age':21}).count();// UPDATE USERS SET name='LEE' WHERE age=33
db.user.updateOne({'age':33}, {'$set':{'name':'LEE'}}, false, true);// UPDATE USERS SET age=age+10 WHERE name='LEE'
db.user.updateOne({'name':'LEE'}, {'$inc':{'age':10}}, false, true);// CREATE INDEX myindex ON users(name)
// 如果索引尚不存在,則在指定字段上創建索引。
db.user.ensureIndex({'name':1});// CREATE INDEX myindex ON users(name, ts DESC)
db.user.ensureIndex({'name':1, 'ts':-1});// DELETE FROM USERS WHERE name='Alex'
db.users.deleteMany({'name':'Alex'});刪除操作
刪除操作從集合中刪除文檔。 MongoDB提供以下刪除集合文檔的方法:
-
db.collection.deleteOne() 3.2版中的新功能
-
db.collection.deleteMany() 3.2版中的新功能
在MongoDB中,刪除操作只針對單個集合。MongoDB中的所有寫操作都是單個文檔級別的原子 操作。
你可以指定查詢過濾器或條件來標識要更新的文檔,這里的過濾器和讀操作的語法是一致的。
// 刪
// 刪除某個字段為空的, 會刪除整條數據
db.getCollection("test").deleteOne({"adder": null});db.test.deleteOne({"adder": null});// 刪除符合條件的第一個文檔
// 第一個包含有 'age': 8的文檔
db.user.deleteOne({ 'age': 8 });// 刪除符合條件的全部
// 只要有內嵌文檔,且內容含有country': 'China'的全都刪除
db.user.deleteMany( {'addr.city': 'henan'} );// 刪除id大于等于9的所有
db.user.deleteMany({"_id":{"$gte":9}});// 刪除id大于7的所有
db.user.deleteMany({"_id":{"$gt":7}});// 刪除id小于等于3的所有
db.user.deleteMany({"_id":{"$lte":3}});// 刪除id小于5的所有
db.user.deleteMany({"_id":{"$lt":5}});// 刪除全部 等于是清空該集合(表)
db.user.deleteMany({});增刪改查練習
// 查詢崗位名以及各崗位內的員工姓名
db.emp.aggregate({"$group":{"_id":"$post","names":{"$push":"$name"}}})
// 查詢崗位名以及各崗位內包含的員工個數
db.emp.aggregate({$group:{"_id":"$post","count":{"$sum":1}}})
// 查詢公司內男員工和女員工的個數
db.emp.aggregate({$group:{"_id":"$sex","count":{"$sum":1}}})
// 查詢崗位名以及各崗位的平均薪資、最高薪資、最低薪資
db.emp.aggregate({$group:{"_id":"$post","avg":{"$avg":"$salary"},"max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}});
// 查詢男員工與男員工的平均薪資,女員工與女員工的平均薪資
db.emp.aggregate({$group:{"_id":"$sex","avg":{$avg:"$salary"}}})
db.emp.aggregate({"$group":{"_id":"$sex","avg_salary":{"$avg":"$salary"}}})
// 查詢各崗位內包含的員工個數小于2的崗位名、崗位內包含員工名字、個數
db.emp.aggregate({$group:{"_id":"$post","count":{$sum:1},"names":{"$push":"$name"}}},{$match:{count:{$lt:2}}},{$project:{"_id":0,"names":1,"count":1}});// 查詢各崗位平均薪資大于10000的崗位名、平均工資
db.emp.aggregate({$group:{"_id":"$post","avg":{$avg:"$salary"}}
},{$match:{"avg":{$gt:10000}}},{$project:{"_id":1,"avg":1}});
// 查詢各崗位平均薪資大于10000且小于20000的崗位名、平均工資
db.emp.aggregate({"$group":{"_id":"$post","avg":{"$avg":"$salary"}}
},);db.emp.aggregate({"$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}}},{"$match":{"avg_salary":{"$gt":10000,"$lt":20000}}},{"$project":{"_id":1,"avg_salary":1}});// 查詢所有員工信息,先按照age升序排序,如果age相同則按照hire_date降序排序
db.emp.aggregate({"$sort":{"age":1,"hire_date":-1}
});
// 查詢各崗位平均薪資大于10000的崗位名、平均工資,結果按平均薪資升序排列
db.emp.aggregate({"$group":{"_id":"$post","avg":{$avg:"$salary"}}
},{"$match":{"avg":{"$gt":10000}}},{"$sort":{"avg":1}})
// 查詢各崗位平均薪資大于10000的崗位名、平均工資,結果按平均薪資降序排列,取前1個
db.emp.aggregate({$group:{"_id":"$post","avg":{$avg:"$salary"}}
},{$match:{"avg":{$gt:10000}}},{$sort:{"avg":-1}},{$limit:1},{$project:{"date":new Date,"平均工資":"$avg","_id":0}})



)








)






