MySQL數據庫概述
1 SQL
SQL語句大小寫不敏感。
SQL語句末尾應該使用分號結束。
1.1 SQL語句及相關操作示例
- DDL:數據定義語言,負責數據庫定義、數據庫對象定義,由CREATE、ALTER與DROP三個語法所組成
- DML:數據操作語言,負責對數據庫對象的操作,CRUD:create、read、update、delete增查、改、刪
- DCL:數據控制語言,負責數據庫權限訪問控制,由GRANT和REVOKE兩個指令組成
- TCL:事務控制語言,負責處理ACID事務,支持commit、rollback指令
# GRANT授權、REVOKE撤銷:
grant all on crashsource.* to 'test_user'@'%' identified by 'cli*963.'; -- 在所有主機上,對test_user用戶,授權操作數據庫crashsource中的所有表。 .*表示所有表, '%'通配符revoke all on *.* from test_use; -- 撤銷test_user用戶對所有表的配置權限。# 刪除用戶
drop user test_user; -- 刪除用戶test_user,慎用。# 創建數據庫
create database if not exists gogs character set utf8mb4 collate utf8mb4_general_ci; -- 創建數據庫# 刪除數據庫
drop database if exists gogs; -- 如果數據庫gogs存在,則刪除。# 創建表
CREATE TABLE `reg` (`loginname` varchar(48) NOT NULL,`name` varchar(64) NOT NULL,`password` varchar(255) NOT NULL,KEY `ln` (`loginname`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -- 創建表,反引號標注的名稱,被認為是非關鍵字。# DESC查看列信息
desc products; -- 查看列信息
desc products '%name'; -- 查看以name結尾的列信息1.2 主鍵PRIMARY KEY *
主鍵PRIMARY KEY,表中一列或多列(一個字段或多個字段)組成組成唯一的key,通過這個key能唯一的標識一條記錄。主鍵的列不能使用空值NULL。主鍵往往設置為整型、長整型,(字符串、日期型都可以,但是開發中一般不這么做,因為存在性能上的問題);通過自增AUTO_INCREMENT來保證主鍵的唯一性。通常實踐結果表明,也不怎么使用多列組合來組成主鍵。
自增AUTO_INCREMENT:自己管理一個數字,每增加一行,數字+1,刪除一行這個數字不變。數字絕不回頭。
表中也可以沒有主鍵,但不符合慣例。
1.3 索引INDEX *
索引可以看做是一本大字典的目錄,為了快速檢索用的。空間換時間,顯著提高查詢效率(同時會帶來插入、刪除、修改的效率問題,比如要修改某一個字段,可能需要同時去更新索引)。
可以對一列或多列設定索引。
**主鍵索引:**主鍵會自動建立主鍵索引,主鍵本身就是為了快速定位唯一記錄的。
**唯一索引:**表中的索引列組成的索引必須唯一,但可以為空,非空值必須唯一。 主鍵索引和唯一索引的顯著差異,就是主鍵不可以為NULL,唯一鍵可以為NULL。
**普通索引:**沒有唯一性的要求,就是建立了一個字典的目錄而已。
1.4 約束Constraint *
unique約束(唯一鍵約束):定義了唯一鍵索引,就定義了唯一鍵約束。唯一約束就是不允許重復,但是可以為NULL,為NULL只允許某一行的一個字段為NULL。
primary key約束:定義了主鍵,就定義了主鍵約束。主鍵約束就是不允許為NULL,而且不允許重復。
外鍵約束Foreign Key
**外鍵:**在表B中的列,關聯表A中的主鍵,表B中的列就是外鍵。
1、如果在表B插入一條數據,B的外鍵列插入了一個值,這個值必須是表A中存在的主鍵值。
2、修改表B的外鍵值,同樣要在表A中存在。
3、如果表A要刪除一條記錄,那么就等于刪除了一個主鍵,那么如果表B中引用了這個主鍵,就必須先刪除表B中引用這個主鍵的記錄,然后才能刪除表A的記錄,否則刪除失敗。
4、修改表A的主鍵,由于主鍵的唯一性,修改的主鍵相當于插入新的主鍵,那么表B引用過這個主鍵,將組織表A的主鍵修改,必須刪除表B的相關記錄后,才能修改表A的主鍵。
外鍵約束,為了保證數據完整性、一致性,杜絕數據冗余、數據訛誤。
1.5 視圖
視圖,也稱續表,看起來像表。它是由查詢語句生成的。可以通過視圖進行CRUD增刪改查操作。
視圖的作用:
- 簡化操作,將復雜的SQL查詢語句定義為視圖,可以簡化查詢。
- 數據安全,視圖可以只顯示真實表的部分列,或計算后的結果,隱藏真實表的數據。
# 創建視圖示例
create view ProductCustomers AS select cust_name, cust_contact, prod_id FROM customers, orders, orderitems WHERE customers.cust_id=orders.cust_id AND orderitems.order_num=orders.order_num; 2 MySQL數據類型 *
下列常用的數據類型必須牢記:
| 類型 | 含義 |
|---|---|
tinyint | 1字節,帶符號的范圍是128到127。無符號的范圍是0到255。bool或boolean,就是tinyint,0表示假,非0表示真 |
smallint | 2字節,帶符號的范圍是-32768到32767。無符號的范圍是0到65535 |
int | 整型,4字節,同Integer,帶符號的范圍是-2147483648到2147483647。無符號的范圍是0到4294967295 |
bigint | 長整型,8字節,帶符號的范圍是-9223372036854775808到9223372036854775807。無符號的范圍是0到18446744073709551615 |
float | 單精度浮點數精確到大約7位小數位 |
double | 雙精度浮點數精確到大約15位小數位 |
DATE | 日期。支持的范圍為1000-01-01到9999-12-31 |
DATETIME | 支持的范圍是1000-01-0100:00:00到9999-12-3123:59:59 |
TIMESTAMP | 時間戳。范圍是1970-01-0100:00:00到2037年 |
char(M) | 固定長度,右邊填充空格以達到長度要求。M為長度,范圍為0~255。M指的是字符個數 |
varchar(M) | 變長字符串。M表示最大列長度。M的范圍是0到65535。但不能突破行最大字節數65535 |
text | 大文本。最大長度為65535(2^16-1)個字符 |
BLOB | 大字節。最大長度為65535(2^16-1)字節的BLOB列 |
LENGTH函數:返回字節數。而char和varchar定義的M是字符數限制。
char可以將字符串變成等長的,空間換時間,效率略高(查詢、存儲效率)
varchar變長,省了空間。但是會帶來效率問題。因為存的數據參差不齊,帶來讀取的問題,比如存了一百萬條記錄,單要對前面的數據進行修改,而這個數據恰恰引起了長度的變化,導致整個IO開始變動,上百萬條整體挪動。。。
所以到底用什么,要根據實際項目評估。比如數據庫經常修改,還不如用char呢。但是用char,一個主從、多從的數據庫架構,那要浪費多少磁盤空間啊。。。
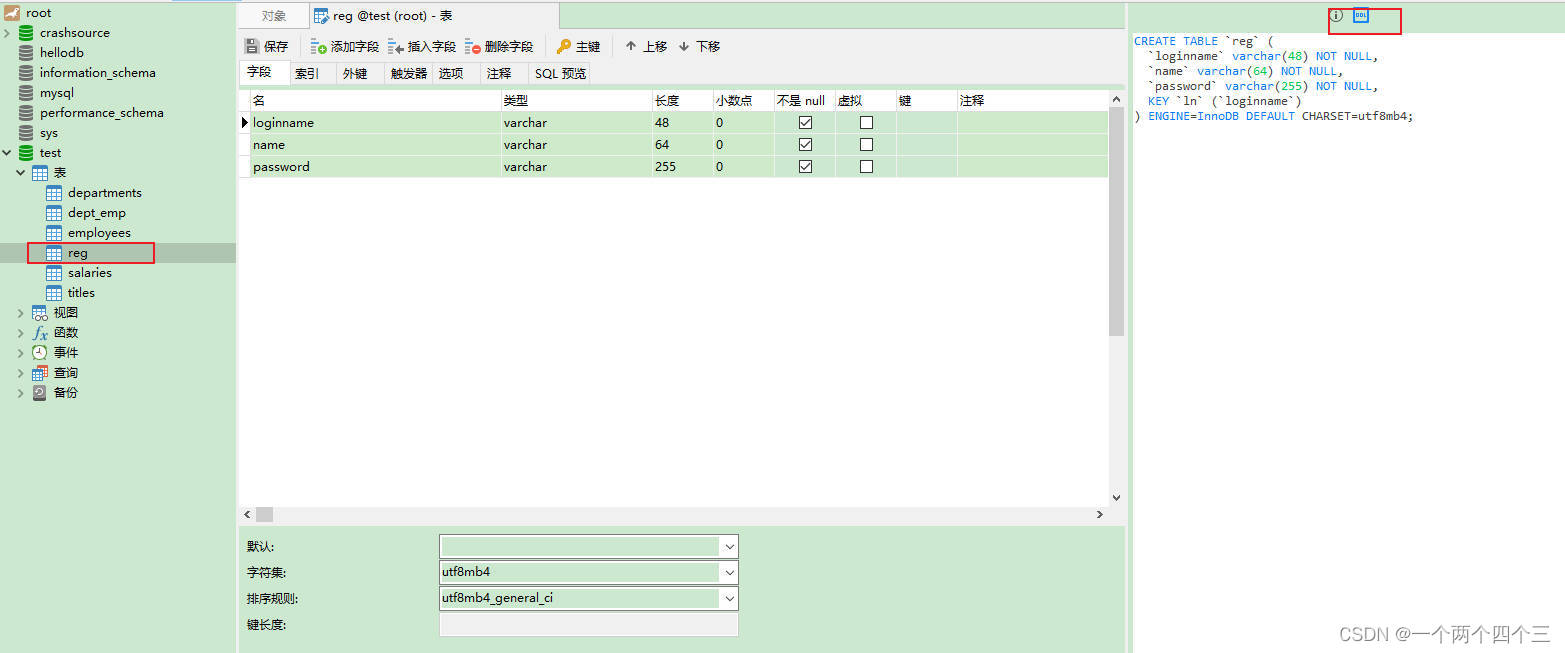
2.1 使用Navicat設計表示例
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-uAF2gcKc-1692374636464)(設計表示例.jpg)]
保存后生成的SQL語句:
CREATE TABLE `reg` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`loginname` varchar(48) NOT NULL,`name` varchar(64) NOT NULL,`password` varchar(255) NOT NULL,`reserved1` varchar(255) DEFAULT NULL,`reserved2` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `ln` (`loginname`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
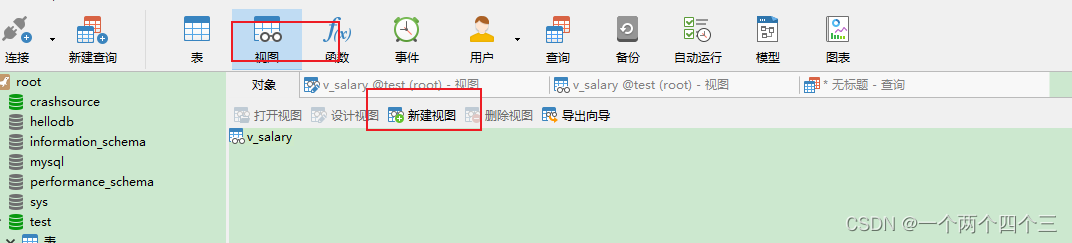
2.2 使用Navicat創建視圖示例
-
點擊視圖-> 新建視圖
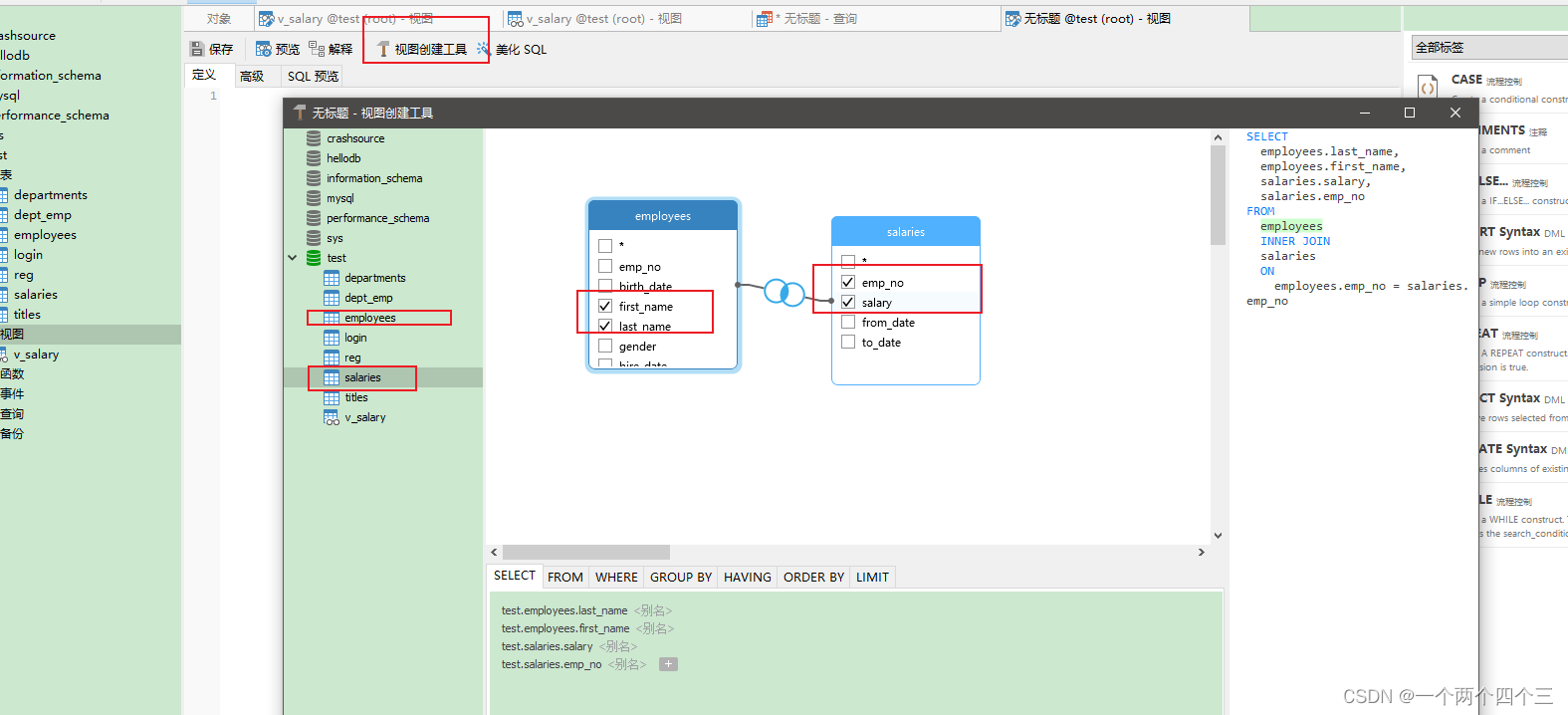
-
點擊視圖創建工具 -> 拖拽需要創建視圖的表
salaries、employees到窗口,勾選需要查看的字段first_name、last_name、salary、emp_no -> 構建:
-
預覽:
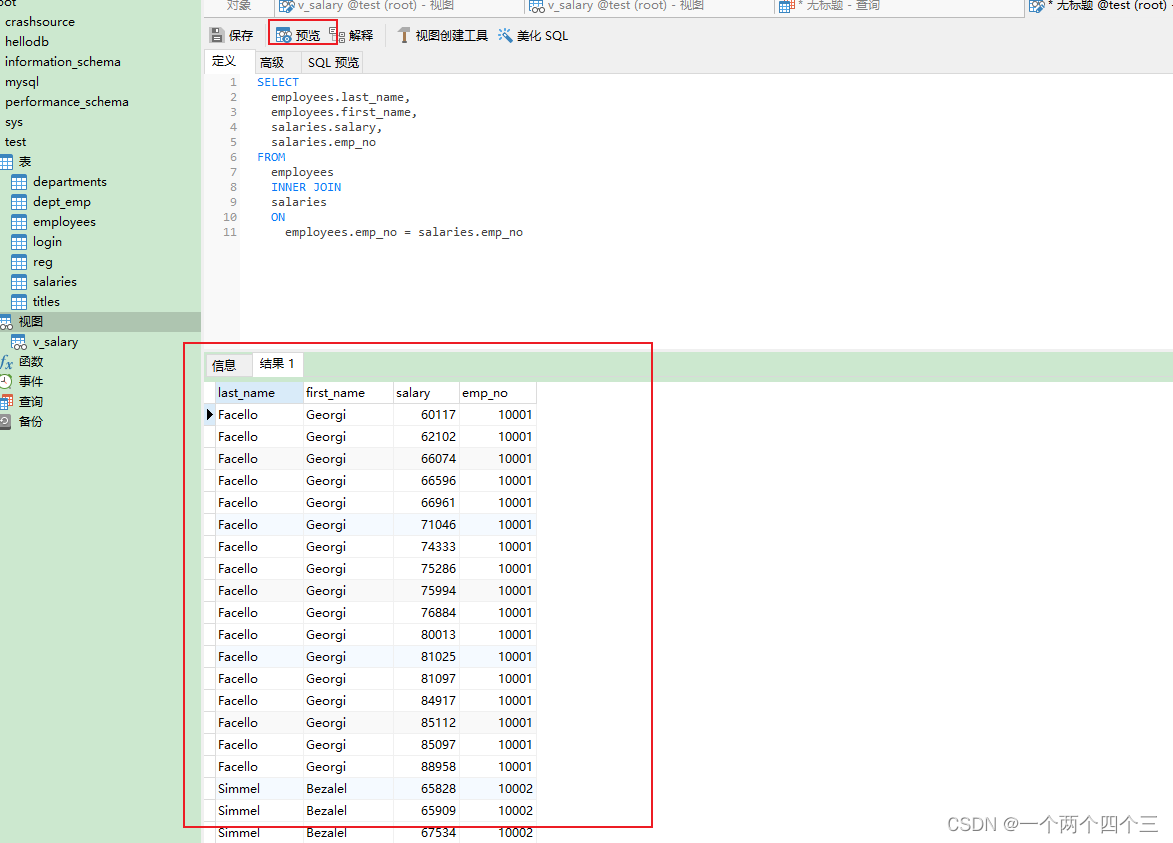
-
點擊保存,然后雙擊打開保存的視圖,新建視圖查詢語句-> 點擊運行:
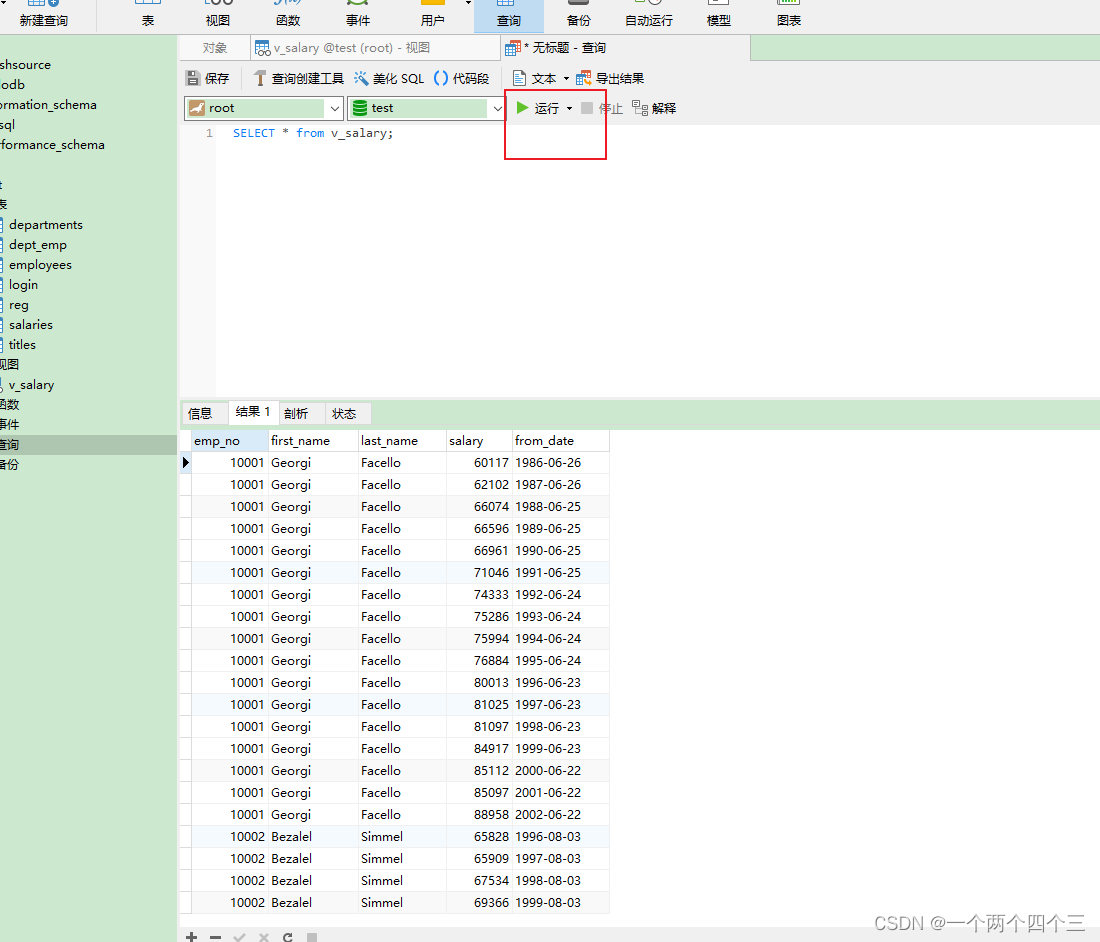
3 關系操作
關系:在關系型數據庫中,關系就是二維表。關系操作就是對表的操作。
- 選擇:selection,又稱為限制,是從關系中選擇出滿足給定條件的元組。
- 投影:projection,在關系上投影就是從選擇出若干屬性列組成新的關系。
- 連接,join,將不同的兩個關系連接成一個關系。
3.1 DML
CRUD:增create、查read、改update、刪delete。
3.1.1 Insert語句
INSERT INTOcustomers (cust_name, cust_address, cust_city, cust_country, cust_contact, cust_email)
VALUES ('Li Ming', 'JIN NIU', 'ChengDU', 'China', '02811111', 'test@email.com'); -- 基本的insert語句。主鍵自動遞增可以不指定。INSERT INTOorders (order_date, cust_id)
VALUES (database(), 123)
ON DUPLICATE KEYUPDATE order_date=database(); -- 如果主鍵沖突、唯一鍵沖突就執行Upgdate后的設置。主鍵不在新增記錄,主鍵存在更新部分字段。INSERT IGNORE INTOvendors (vend_name, vend_address, vend_city, vend_state, vend_zip, vend_country)
VALUES ('Huawei', 'PIDU', 'CHENGDU', 'SICHUAN', 123454, 'CHINA'); -- 如果主鍵沖突、唯一建沖突就忽略錯誤,返回一個告警。
3.1.2 Update語句
UPDATE IGNORE vendors SET vend_address='Pi DU', vend_city='CHENG DU' where vend_name='Huawei'; -- 要有where語句,否則就會更新所有行。ignore同上
3.1.3 DELETE語句
DELETE IGNORE FROM vendors WHERE vend_name='HUAWEI'; -- 刪除符合條件的記錄; 沒有where子句將刪除所有行,可以通過日志恢復。delete不會刪除表本身。
truncate語句:
作用是清空表或者說是截斷表,只能作用于表。truncate的語法很簡單,后面直接跟表名即可 truncate是DDL語句。
TRUNCATE vendors -- 不記錄數據的變動,可以通過日志恢復
truncate與drop,delete的對比
truncate與delete,drop很相似,其實這三者還是與很大的不同的,下面簡單對比下三者的異同。
- truncate與drop是DDL語句,執行后無法回滾;delete是DML語句,可回滾。
- truncate只能作用于表;delete,drop可作用于表、視圖等。
- truncate會清空表中的所有行,但表結構及其約束、索引等保持不變;drop會刪除表的結構及其所依賴的約束、索引等。
- truncate會重置表的自增值;delete不會。
- truncate不會激活與表有關的刪除觸發器;delete可以。
- truncate后會使表和索引所占用的空間會恢復到初始大小;delete操作不會減少表或索引所占用的空間,drop語句將表所占用的空間全釋放掉。
3.1.4 select語句
查詢的結果稱為結果集record set。
/*SELECT[DISTINCT]select_expr,...[FROM table_references[WHERE where_definition][GROUP BY {col_name | expr | position}[ASC | DESC],... [WITH ROLLUP]][HAVING where_definition][ORDER BY {col_name I expr I position][ASC I DESC],..][LIMIT ([offset,] row count I row_count OFFSET offset}][FOR UPDATE | LOCK IN SHARE MODE]]*/
for update 會把進行寫鎖定,這是排他鎖。
SELECTDISTINCTvend_name, vend_address
FROM vendors
WHERE vend_country IN('USA', 'ENGLISH', 'CHINA')
GROUP BY vend_country DESC
HAVING vend_country IN('USA', 'ENGLISH', 'CHINA')
ORDER BY vend_country
LIMIT 5 OFFSET 2
FOR UPDATE;SELECT 1;
-- 最簡單的查詢
SELECT * FROM vendors;-- 字符串合并
SELECT vend_id, vend_name + vend_address FROM vendors;
SELECT vend_id, COUNT(vend_name, ' ', vend_address, ' ', vend_city) FROM vendors;
-- as 定義別名
SELECT vend_id, COUNT(vend_name, ' ', vend_address, ' ', vend_city) as vend_info FROM vendors;-- limit子句
SELECT * FROM orders LIMIT 5; -- 提取前5行
SELECT * FROM orders LIMIT 5 OFFSET 4; -- 提取5條記錄,偏移4條。偏移可以用作分頁讀取;比如每次偏移20,讀取20條記錄,每讀取一次偏移增加20.
SELECT * FROM orders LIMIT 4, 5; -- 上條語句的另外一種寫法。
– where子句
where子句涉及的運算符:
| 運算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| >,<,>=,<= | 大于、小于、大于等于、小于等于 |
| BETWEEN | 在某個范圍之內,between a andb等價于[a,b] |
| LIKE | 字符串模式匹配,%表示任意多個字符,表示一個字符 |
| IN | 指定針對某個列的多個可能值 |
| AND | 與 |
| OR | 或 |
**注意:**如果很多表達式需要使用AND、OR計算邏輯表示式的值的時候,由于結合律問題,可以使用小括號來避免錯誤。
-- 條件查詢
SELECT * FROM vendors WHERE vend_id<1006 and vend_city in ('New York', 'Pairs', 'London') and vend_name like 'J%';
SELECT * FROM vendors WHERE vend_id BETWEEN 1000 AND 1005 AND vend_name LIKE 'J%';
SELECT * FROM vendors WHERE vend_id IN (1003, 1004, 1005);-- order by子句
# 對查詢結果進行排序,可以升序ASC、降序DESC
-- 降序
SELECT * FROM vendors WHERE vend_id IN (1003, 1004, 1005) ORDER BY vend_id DESC;-- DISTINCT
# 不返回重復記錄
SELECT DISTINCT vend_id FROM vendors;
SELECT DISTINCT vend_id, vend_city FROM vendors;
聚合函數
| 函數 | 描述 |
|---|---|
COUNT(expr) | 返回記錄中記錄的數目,如果指定列,則返回非NULL值的行數 |
COUNT(DISTINCT expr,[expr..) | 返回不重復的非NULL值的行數 |
AVG(IDISTINCT]expr) | 返回平均值,返回不同值的平均值 |
MIN(expr), MAX(expr) | 最小值,最大值 |
SUM(IDISTINCT]expr) | 求和,Distinct返回不同值求和 |
-- 聚合函數
SELECT COUNT(*), AVG(quantity), SUM(quantity), MIN(quantity), MAX(quantity) FROM orderitems;
分組查詢
使用group by子句,如果有條件,使用HAVING子句過濾分組、聚合過濾后的結果。
-- 聚合所有
SELECT SUM(item_price), AVG(item_price), COUNT(order_item) FROM orderitems;
-- 聚合被選擇的記錄
SELECT order_item, SUM(quantity), AVG(item_price), COUNT(order_item) FROM orderitems WHERE order_item=1;
-- 按照不同的order_item分組,分組分別聚合
SELECT order_item, SUM(quantity), AVG(item_price), COUNT(order_item) FROM orderitems WHERE item_price<10 GROUP BY order_item;
-- HAVING子句對分組結果過濾
SELECT order_item, SUM(quantity), AVG(item_price), COUNT(order_item) FROM orderitems GROUP BY order_item HAVING AVG(quantity)>3;
-- 使用別名
SELECT order_item, SUM(quantity), AVG(item_price) as avg_q FROM orderitems GROUP BY order_item HAVING AVG(quantity)>3;
-- 最后對分組過濾后的結果進行排序
SELECT order_item, SUM(quantity), AVG(item_price) as avg_q FROM orderitems GROUP BY order_item HAVING AVG(quantity)>3 ORDER BY avg_q;
子查詢
查詢語句可以嵌套,內部查詢就是子查詢。子查詢必須在一組小括號中。子查詢不能使用order by。
SELECT *
FROM orderitems
where item_price IN (SELECT item_price FROM orderitems WHERE item_price<10)
ORDER BY item_price
DESC;SELECT order_item
FROM (SELECT * FROM orderitems WHERE item_price<10) as ord_items
where item_price<9
ORDER BY order_item
DESC;
子查詢存在性能問題,建議少用,改用join。
連接join
在聯結兩個表時,實際要做的是將第一個表中的每一行與第二個表中的每一行配對。WHERE子句作為過濾條件,只包含那些匹配給定條件(這里是聯結條件)的行。
沒有WHERE子句,第一個表中的每一行將與第二個表中的每一行配對,而不管它們邏輯上是否能配在一起,這種聯結就是笛卡爾聯結。
內聯結:
- 沒有where限定的內聯結,就是笛卡爾聯結,又稱叉聯結。有的說法,叉聯結是叉聯結,使用CROSS JOIN;內聯結是內聯結,使用INNER JOIN;只是兩種聯結的語法相同。
SELECT vend_name, prod_name, prod_price FROM vendors, products;
SELECT vend_name, prod_name, prod_price FROM vendors CROSS JOIN products; -- 叉聯結,使用CROSS JOIN
SELECT vend_name, prod_name, prod_price FROM vendors INNER JOIN products; -- 內聯結,使用INNER JOIN,因為沒有where限定,得出的結果也是叉聯結的結果。
- 等值聯結,有where限定的內聯結
在聯結兩個表時,實際要做的是將第一個表中的每一行與第二個表中的每一行配對。WHERE 子句作為過濾條件,只包含那些匹配給定條件(這里是聯結條件)的行。
沒有 WHERE子句,第一個表中的每一行將與第二個表中的每一行配對,而不管它們邏輯上是否能配在一起。
SELECT vend_name, prod_name, prod_price FROM vendors, products WHERE vendors.vend_id = products.vend_id;
SELECT vend_name, prod_name, prod_price FROM vendors INNER JOIN products ON vendors.vend_id = products.vend_id; -- 更推薦使用inner join... on... 語法
-- 自聯結,特殊的等值聯結
-- 找出與Mr Wang在同一個國家的所有顧客,然后給他們發郵件。先使用子查詢
SELECT cust_id, cust_name, cust_email
FROM Customers
WHERE cust_country = (SELECT cust_countryFROM CustomersWHERE cust_contact = 'Mr Wang');
-- 使用自聯結
SELECT a.cust_id, a.cust_name, a.cust_email
FROM customers AS a INNER JOIN customers AS b ON a.cust_country = b.cust_country AND b.cust_name='Mr Wang';-- 自然聯結:等值連接中,若干個聯結的表,會產生重復的列。自然聯結就是沒有重復的列,是一種特殊的等值連接。
-- 沒有內置的DBMS語法支持自然聯結,需要用戶自己實現。一般通過對一個表使用通配符(SELECT *),而對其他表的列使用明確的子集來完成
SELECT C.*, O.order_num, O.order_date,OI.prod_id, OI.quantity, OI.item_price
FROM Customers AS C, Orders AS O,OrderItems AS OI
WHERE C.cust_id = O.cust_id
AND OI.order_num = O.order_num
AND prod_id = 'RGAN01';
- 外聯結:分為左外聯結,右外聯結
許多聯結將一個表中的行與另一個表中的行相關聯,但有時候需要包含沒有關聯行的那些行。
例如,對每個顧客下的訂單進行計數,包括那些至今尚未下訂單的顧客;列出所有產品以及訂購數量,包括沒有人訂購的產品。
-- 使用 LEFT OUTER JOIN 從 FROM 子句左邊的表(Customers 表)中選擇所有行.檢索包括沒有訂單顧客在內的所有顧客
SELECT customers.cust_id, orders.order_num FROM customers LEFT OUTER JOIN orders ON customers.cust_id = orders.cust_id;
-- 使用 RIGHT OUTER JOIN 從 FROM 子句右邊的表(Customers 表)中選擇所有行.檢索包括沒有訂單顧客在內的所有顧客
SELECT customers.cust_id, orders.order_num FROM orders RIGHT OUTER JOIN customers ON customers.cust_id = orders.cust_id;-- 帶聚集函數的聯結
SELECT Customers.cust_id, COUNT(Orders.order_num) AS num_ord
FROM Customers
INNER JOIN Orders ON Customers.cust_id = Orders.cust_id
GROUP BY Customers.cust_id; -- 先執行INNER JOIN... ON...,將兩張表關聯;然后按顧客ID分組;最后通過聚集函數,統計出每個顧客的訂單數。-- 聯結多個表
-- 使用子查詢
SELECT cust_name, cust_contact
FROM Customers
WHERE cust_id IN (SELECT cust_id FROM Orders WHERE order_num IN (SELECT order_num FROM OrderItems WHERE prod_id = 'RGAN01'));
-- 使用聯結
SELECT cust_name, cust_contact
FROM Customers, Orders, OrderItems
WHERE Customers.cust_id = Orders.cust_id
AND OrderItems.order_num = Orders.order_num
AND prod_id = 'RGAN01';



















