目錄
- 一、引言
- 1.1 背景和重要性
- 1.2 卷積神經網絡概述
- 二、卷積神經網絡層介紹
- 2.1 卷積操作
- 卷積核與特征映射
- 卷積核大小
- 多通道卷積
- 步長與填充
- 步長
- 填充
- 空洞卷積(Dilated Convolution)
- 分組卷積(Grouped Convolution)
- 2.2 激活函數
- ReLU激活函數
- 優勢與劣勢
- Leaky ReLU
- Sigmoid激活函數
- 優勢與劣勢
- Tanh激活函數
- 優勢與劣勢
- Swish激活函數
- 其他激活函數
- 激活函數的選擇
- 2.3 池化層
- 最大池化(Max Pooling)
- 優勢與劣勢
- 平均池化(Average Pooling)
- 優勢與劣勢
- 全局平均池化(Global Average Pooling)
- 池化窗口大小和步長
- 池化的替代方案
- 池化層的選擇
- 2.4 歸一化層
- 批量歸一化(Batch Normalization)
- 優勢與劣勢
- 層歸一化(Layer Normalization)
- 實例歸一化(Instance Normalization)
- 組歸一化(Group Normalization)
- 歸一化層的選擇
- 三、訓練與優化
- 3.1 訓練集準備與增強
- 數據預處理
- 數據增強
- 常見增強技巧
- 訓練集分割
- 3.2 損失函數
- 回歸任務
- 分類任務
- 優化損失函數
- 3.3 優化器
- 隨機梯度下降(SGD)
- 自適應優化器
- 優化器選擇注意事項
- 3.4 學習率調整
- 固定學習率
- 學習率調度
- 預定調整
- 自適應調整
- 學習率預熱
- 3.5 正則化技巧
- L1和L2正則化
- Dropout
- Batch Normalization
- 數據增強
- 3.6 模型評估與調優
- 交叉驗證
- 調參技巧
- 早停技巧
- 模型集成
- 4. 總結
本文全面探討了卷積神經網絡CNN,深入分析了背景和重要性、定義與層次介紹、訓練與優化,詳細分析了其卷積層、激活函數、池化層、歸一化層,最后列出其訓練與優化的多項關鍵技術:訓練集準備與增強、損失函數、優化器、學習率調整、正則化技巧與模型評估調優。旨在為人工智能學者使用卷積神經網絡CNN提供全面的指導。
作者 TechLead,擁有10+年互聯網服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智能實驗室成員,阿里云認證的資深架構師,項目管理專業人士,上億營收AI產品研發負責人
一、引言
卷積神經網絡(Convolutional Neural Networks, CNN)的復雜性和靈活性使其成為深度學習領域的核心研究主題之一。在本引言部分中,我們將深入探討CNN的歷史背景、基本原理、重要性以及其在科學和工業領域的影響。

1.1 背景和重要性
卷積神經網絡的靈感源自人類視覺系統,特別是視覺皮層中的神經元結構。自Hubel和Wiesel在1962年的開創性工作以來,這一理念已經引發了一系列研究和發展。
- 早期發展: 由Yann LeCun等人在上世紀80年代末到90年代初開發的LeNet-5被視為第一個成功的卷積神經網絡。LeNet-5在手寫數字識別方面取得了令人印象深刻的結果。
- 現代崛起: 隨著硬件的快速進展和大數據的涌現,CNN在21世紀初開始重新崛起,并在各個領域實現了突破性進展。
CNN的重要性不僅體現在其精度和效率上,而且還體現在其理論洞見上。例如,卷積層通過共享權重減少了參數數量,這有助于更有效地訓練模型,還增強了模型對平移不變性的理解。
1.2 卷積神經網絡概述
卷積神經網絡是一種前饋神經網絡,它的人工神經元可以響應周圍單元的局部區域,從而能夠識別視覺空間的部分結構特征。以下是卷積神經網絡的關鍵組成部分:
- 卷積層: 通過卷積操作檢測圖像的局部特征。
- 激活函數: 引入非線性,增加模型的表達能力。
- 池化層: 減少特征維度,增加模型的魯棒性。
- 全連接層: 在處理空間特征后,全連接層用于進行分類或回歸。
卷積神經網絡的這些組件協同工作,使得CNN能夠從原始像素中自動學習有意義的特征層次結構。隨著深度增加,這些特征從基本形狀和紋理逐漸抽象為復雜的對象和場景表現。
卷積神經網絡的獨特優勢在于其能夠自動化許多傳統機器學習中需要人工干預的特征工程部分。這一點不僅使其在許多任務中取得了優越性能,還激發了廣泛的學術和工業界的興趣。
二、卷積神經網絡層介紹
卷積神經網絡由多個層組成,每個層具有特定的目的和功能。這一部分將探討卷積操作、激活函數、池化層、歸一化層基本概念。
2.1 卷積操作
卷積操作是卷積神經網絡的核心,涉及多個復雜的概念和細節。我們將逐一介紹它們。
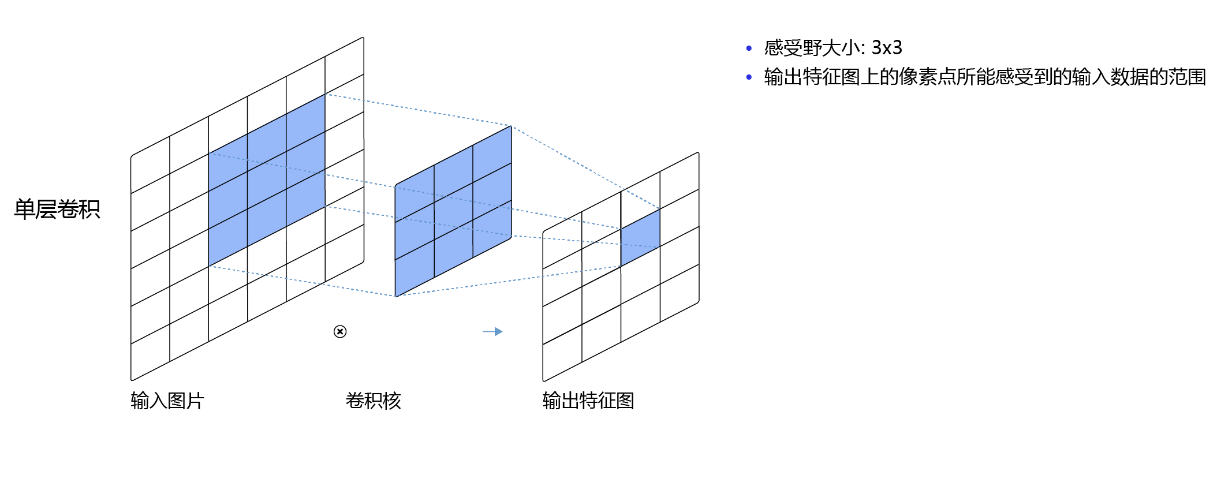
卷積核與特征映射
卷積核是一個小型的矩陣,通過在輸入上滑動來生成特征映射。每個卷積核都能捕獲不同的特征,例如邊緣、角點等。
卷積核大小
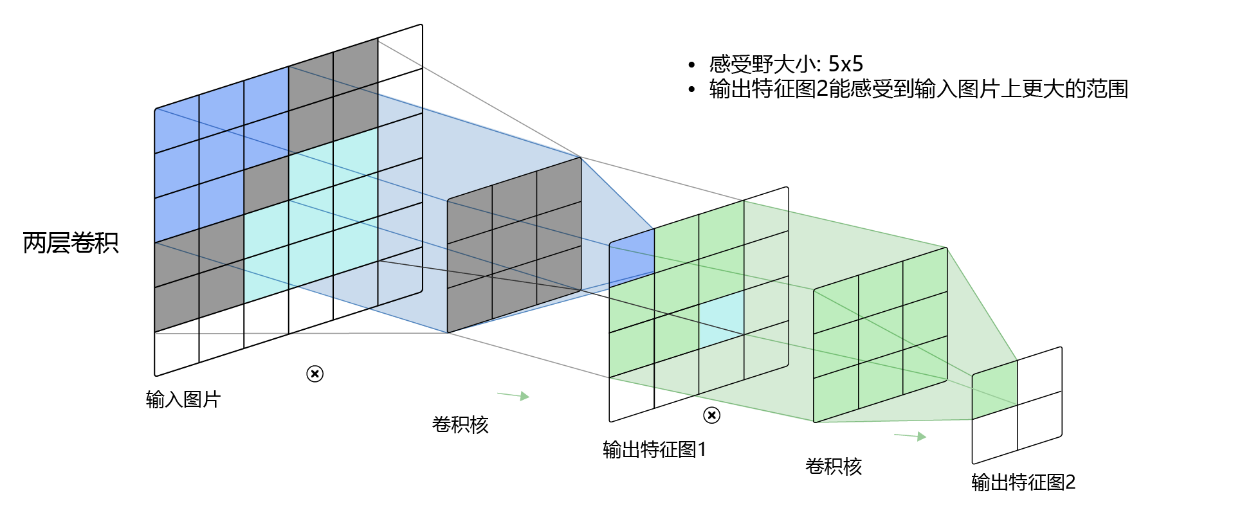
卷積核的大小影響了它能捕獲的特征的尺度。較小的卷積核可以捕獲更細致的特征,而較大的卷積核可以捕獲更廣泛的特征。
# 使用3x3的卷積核
conv_layer_small = nn.Conv2d(3, 64, 3)
# 使用5x5的卷積核
conv_layer_large = nn.Conv2d(3, 64, 5)
多通道卷積
在多通道輸入下進行卷積,每個輸入通道與一個卷積核進行卷積,然后所有的結果相加。這允許模型從不同的通道捕獲不同的特征。
步長與填充
步長和填充控制卷積操作的幾何屬性。
步長
步長定義了卷積核在輸入上移動的速度。較大的步長可以減少輸出的尺寸,而較小的步長則保持尺寸不變。
# 使用步長2
conv_layer_stride2 = nn.Conv2d(3, 64, 3, stride=2)
填充
填充通過在輸入邊緣添加零來控制輸出的尺寸。這有助于控制信息在卷積操作中的丟失。
# 使用填充1,使得輸出尺寸與輸入尺寸相同(假設步長為1)
conv_layer_padding1 = nn.Conv2d(3, 64, 3, padding=1)
空洞卷積(Dilated Convolution)
空洞卷積是一種擴展卷積核感受野的方法,它在卷積核的元素之間插入空白。這允許網絡捕獲更廣泛的信息,而不增加卷積核的大小或計算量。
# 使用空洞率2的卷積核
conv_layer_dilated = nn.Conv2d(3, 64, 3, dilation=2)
分組卷積(Grouped Convolution)
分組卷積通過將輸入通道分組并對每組使用不同的卷積核來擴展卷積操作。這增加了模型的容量,并使其能夠學習更復雜的表示。
# 使用2個分組
conv_layer_grouped = nn.Conv2d(3, 64, 3, groups=2)
2.2 激活函數
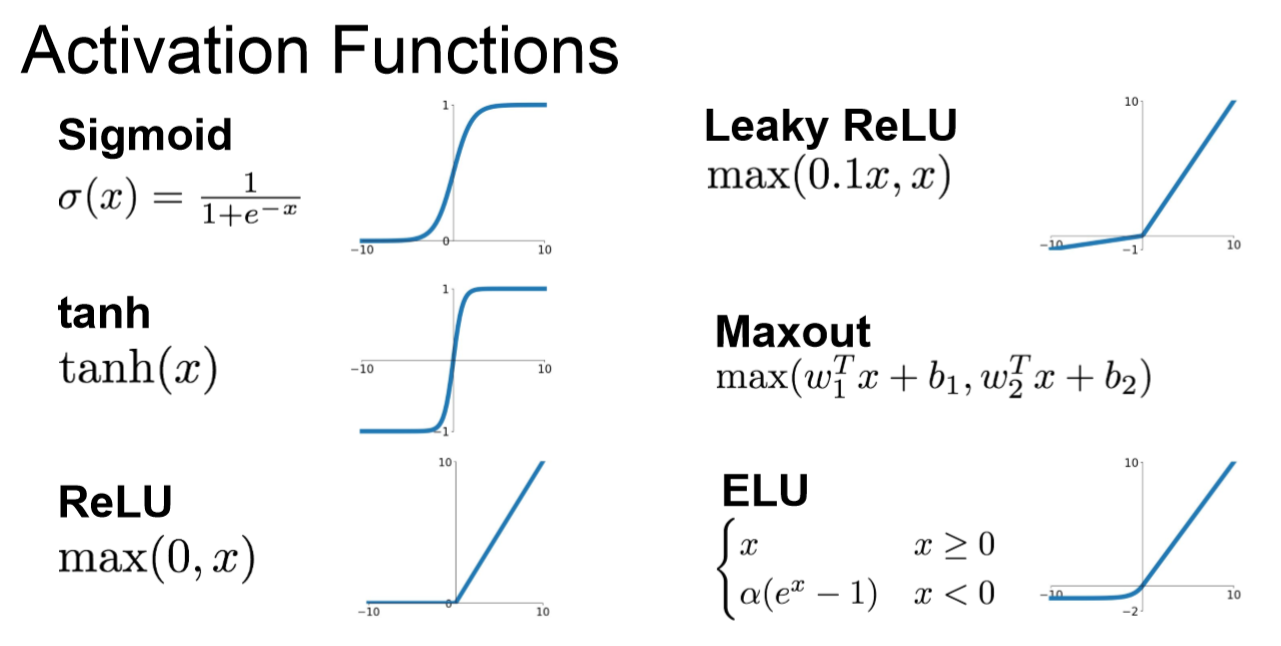
激活函數在神經網絡中起到了至關重要的作用。它們增加了模型的非線性,從而使其能夠學習和逼近復雜的函數。
ReLU激活函數
ReLU(Rectified Linear Unit)是現代深度學習中最流行的激活函數之一。它是非線性的,但計算非常高效。
優勢與劣勢
ReLU的主要優點是計算效率高和促進稀疏激活。然而,它可能會導致"死亡ReLU"現象,其中某些神經元永遠不會被激活。
# 使用PyTorch定義ReLU激活函數
relu = nn.ReLU()
Leaky ReLU
Leaky ReLU是ReLU的一種變體,允許負輸入值的小正斜率。這有助于緩解"死亡ReLU"問題。
# 使用PyTorch定義Leaky ReLU激活函數
leaky_relu = nn.LeakyReLU(0.01)
Sigmoid激活函數
Sigmoid激活函數可以將任何值壓縮到0和1之間。
優勢與劣勢
Sigmoid用于輸出層可以表示概率,但在隱藏層中可能會導致梯度消失問題。
# 使用PyTorch定義Sigmoid激活函數
sigmoid = nn.Sigmoid()
Tanh激活函數
Tanh是另一個類似于Sigmoid的激活函數,但它將輸出壓縮到-1和1之間。
優勢與劣勢
Tanh通常優于Sigmoid,因為它的輸出范圍更大,但仍可能導致梯度消失。
# 使用PyTorch定義Tanh激活函數
tanh = nn.Tanh()
Swish激活函數
Swish是一種自適應激活函數,可能會自動調整其形狀以適應特定問題。
# 使用PyTorch定義Swish激活函數
class Swish(nn.Module):def forward(self, x):return x * torch.sigmoid(x)
其他激活函數
還有許多其他激活函數,例如Softmax、Mish、ELU等,各有各的優點和適用場景。
激活函數的選擇
激活函數的選擇取決于許多因素,例如模型架構、數據類型和特定任務的需求。通過實驗和調整,可以找到適合特定問題的最佳激活函數。
2.3 池化層
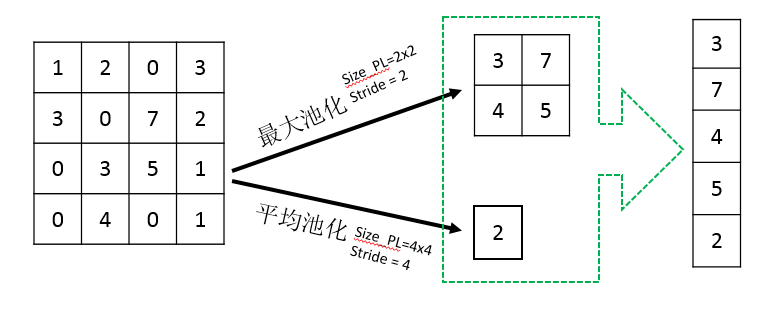
池化層(Pooling Layer)在卷積神經網絡中扮演了重要角色,通常用于降低特征映射的維度,從而減少計算需求,并增加特征檢測器的感受野。
最大池化(Max Pooling)
最大池化是最常用的池化技術之一。它通過選擇窗口中的最大值來降低特征映射的尺寸。
# 使用PyTorch定義2x2的最大池化層
max_pooling = nn.MaxPool2d(2)
優勢與劣勢
最大池化的主要優點是它能保留窗口中的最顯著特征。然而,它會丟失一些細節信息。
平均池化(Average Pooling)
與最大池化不同,平均池化使用窗口中所有值的平均值。
# 使用PyTorch定義2x2的平均池化層
average_pooling = nn.AvgPool2d(2)
優勢與劣勢
平均池化可以減輕最大池化可能導致的過于突出某些特征的問題,但可能會淡化一些重要特征。
全局平均池化(Global Average Pooling)
全局平均池化是一種更復雜的池化策略,它計算整個特征映射的平均值。這常用于網絡的最后一層,直接用于分類。
# 使用PyTorch定義全局平均池化層
global_average_pooling = nn.AdaptiveAvgPool2d(1)
池化窗口大小和步長
池化窗口的大小和步長會直接影響輸出的尺寸。較大的窗口和步長會更顯著地降低尺寸。
池化的替代方案
池化層已經有了一些現代替代方案,例如使用卷積層的步長大于1,或使用空洞卷積。這些方法可能提供更好的特征保存。
池化層的選擇
選擇特定類型的池化層取決于任務需求和特定數據特性。深入理解各種池化技術如何工作,可以幫助深入理解它們是如何影響模型性能的。
2.4 歸一化層
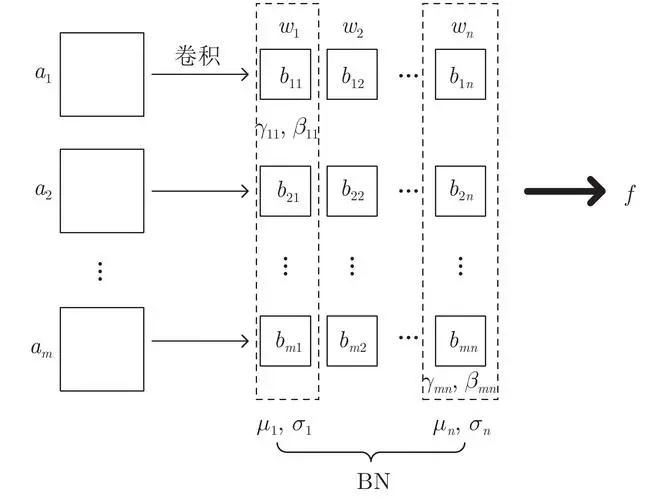
歸一化層在訓練深度神經網絡時扮演了關鍵角色,主要用于改善訓練的穩定性和速度。通過將輸入數據縮放到合適的范圍,歸一化層有助于緩解訓練過程中的梯度消失和梯度爆炸問題。
批量歸一化(Batch Normalization)
批量歸一化通過對每個特征通道的輸入進行歸一化,將輸入縮放到零均值和單位方差。
# 使用PyTorch定義批量歸一化層
batch_norm = nn.BatchNorm2d(num_features=64)
優勢與劣勢
- 優勢:它允許更高的學習率,提供了一些正則化效果,通常導致更快的訓練。
- 劣勢:在小批量上的統計估計可能會導致訓練和推理間的不一致。
層歸一化(Layer Normalization)
層歸一化是在單個樣本上對所有特征進行歸一化的變體。它在句子處理和循環神經網絡中特別流行。
# 使用PyTorch定義層歸一化
layer_norm = nn.LayerNorm(normalized_shape=64)
實例歸一化(Instance Normalization)
實例歸一化主要用于樣式轉換任務,歸一化是在每個樣本的每個通道上獨立進行的。
# 使用PyTorch定義實例歸一化
instance_norm = nn.InstanceNorm2d(num_features=64)
組歸一化(Group Normalization)
組歸一化是批量歸一化和層歸一化之間的一種折衷方案,將通道分為不同的組,并在每個組內進行歸一化。
# 使用PyTorch定義組歸一化
group_norm = nn.GroupNorm(num_groups=32, num_channels=64)
歸一化層的選擇
歸一化層的選擇應基于特定的任務和模型架構。例如,在視覺任務中,批量歸一化可能是首選,而在NLP任務中,層歸一化可能更有用。
三、訓練與優化
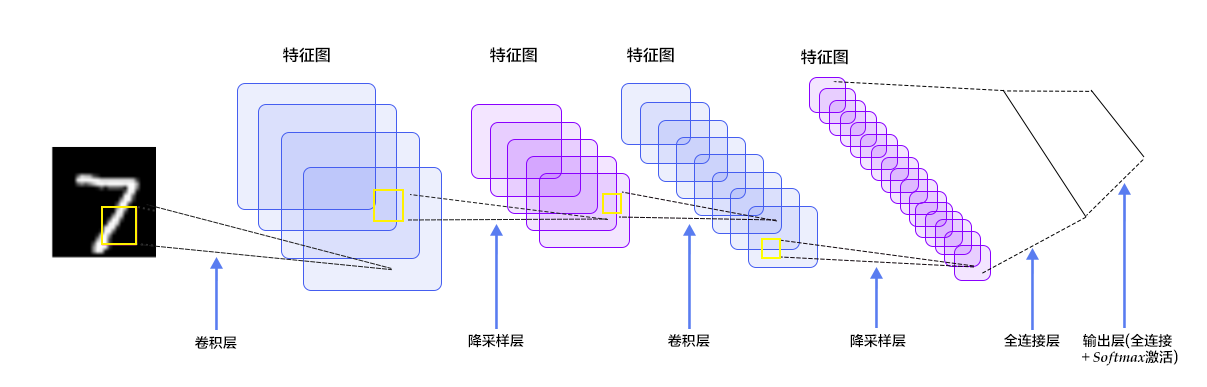
卷積神經網絡的訓練和優化涉及許多關鍵組件和技術,它們共同決定了模型的性能和可用性。下面詳細介紹這些方面。
3.1 訓練集準備與增強
有效的訓練數據是深度學習成功的基礎。為了使卷積神經網絡有效學習,訓練集的選擇和增強至關重要。
數據預處理
預處理是訓練集準備的關鍵步驟,包括:
- 標準化:將輸入縮放到0-1范圍。
- 中心化:減去均值,使數據以0為中心。
- 數據清洗:消除不一致和錯誤的數據。
數據增強
數據增強是一種通過應用隨機變換增加數據量的技術,從而增加模型的泛化能力。
常見增強技巧
- 圖像旋轉、縮放和剪裁
- 顏色抖動
- 隨機噪聲添加
# 使用PyTorch進行多種圖像增強
from torchvision import transforms
transform = transforms.Compose([transforms.RandomRotation(10),transforms.RandomResizedCrop(224),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1)
])
訓練集分割
通常將數據分為訓練集、驗證集和測試集,以確保模型不會過擬合。
3.2 損失函數
損失函數衡量模型預測與真實目標之間的差距。選擇適當的損失函數是優化模型性能的關鍵步驟。
回歸任務
對于連續值預測,通常使用:
- 均方誤差(MSE):衡量預測值與真實值之間的平方差。
# 使用PyTorch定義MSE損失
mse_loss = nn.MSELoss()
- 平滑L1損失:減少異常值的影響。
分類任務
對于類別預測,常見的損失函數包括:
- 交叉熵損失:衡量預測概率分布與真實分布之間的差異。
# 使用PyTorch定義交叉熵損失
cross_entropy_loss = nn.CrossEntropyLoss()
- 二元交叉熵損失:特別用于二分類任務。
- 多標簽損失:適用于多標簽分類。
優化損失函數
選擇適當的損失函數不僅取決于任務類型,還與模型架構、數據分布和特定的業務指標有關。有時,自定義損失函數可能是必要的,以便捕捉特定問題的核心挑戰。
3.3 優化器
優化器用于更新神經網絡的權重,以便最小化損失函數。每種優化器都有其特定的數學原理和應用場景。
隨機梯度下降(SGD)
SGD是最基本的優化算法。
- 基本SGD: 按照負梯度方向更新權重。
- 帶動量的SGD: 引入動量項,積累之前的梯度,以便更平穩地收斂。
# 使用PyTorch定義帶動量的SGD優化器
optimizer_sgd_momentum = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
自適應優化器
自適應優化器能自動調整學習率。
- Adam: 結合了Momentum和RMSProp的優點。
# 使用PyTorch定義Adam優化器
optimizer_adam = torch.optim.Adam(model.parameters(), lr=0.001)
- Adagrad、RMSprop等: 針對不同參數有不同的學習率。
優化器選擇注意事項
- 任務相關性: 不同優化器在不同任務和數據上可能有不同的效果。
- 超參數調優: 如學習率、動量等可能需要調整。
3.4 學習率調整
學習率是優化器中的關鍵超參數,其調整對模型訓練有深遠影響。
固定學習率
最簡單的方法是使用固定學習率。但可能不夠靈活。
學習率調度
更復雜的方法是在訓練過程中動態調整學習率。
預定調整
- 步驟下降: 在固定步驟處降低學習率。
- 余弦退火: 周期性調整學習率。
# 使用PyTorch定義余弦退火調度器
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_adam, T_max=50)
自適應調整
- ReduceLROnPlateau: 基于驗證損失降低學習率。
學習率預熱
訓練初期逐漸增加學習率。
- 線性預熱: 初始階段線性增加學習率。
3.5 正則化技巧
正則化是防止過擬合和提高模型泛化能力的關鍵技術。
L1和L2正則化
- L1正則化:傾向于產生稀疏權重,有助于特征選擇。
- L2正則化:減小權重,使模型更平滑。
# 使用PyTorch添加L1和L2正則化
l1_lambda = 0.0005
l2_lambda = 0.0001
loss = loss + l1_lambda * torch.norm(weights, 1) + l2_lambda * torch.norm(weights, 2)
Dropout
隨機關閉一部分神經元,使模型更魯棒。
- 普通Dropout:隨機丟棄神經元。
- Spatial Dropout:在卷積層中隨機丟棄整個特征圖。
Batch Normalization
通過標準化層輸入,加速訓練并減輕初始化的敏感性。
數據增強
如前所述,數據增強是一種重要的正則化手段。
3.6 模型評估與調優
模型評估是衡量模型性能的過程,調優則是改進性能。
交叉驗證
使用交叉驗證來估計模型的泛化能力。
- k-折交叉驗證:將數據分為k個部分,輪流使用其中一個作為驗證集。
調參技巧
- 網格搜索:嘗試不同超參數組合。
- 隨機搜索:隨機選擇超參數,更高效。
早停技巧
如果驗證損失不再下降,則停止訓練,以防止過擬合。
模型集成
通過結合多個模型來提高性能。
- Bagging:訓練多個模型并平均預測。
- Boosting:在先前模型的錯誤上訓練新模型。
- Stacking:使用新模型組合其他模型的預測。
4. 總結
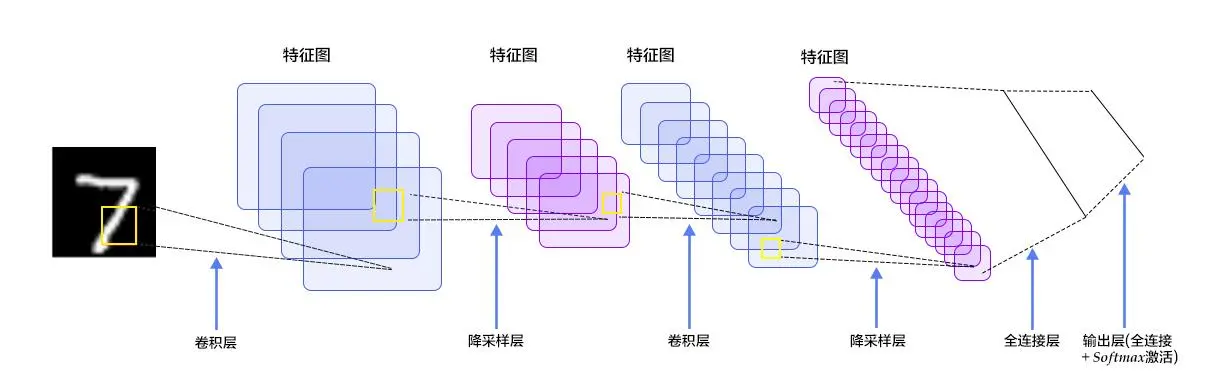
本文全面探討了卷積神經網絡CNN,深入分析了背景和重要性、定義與層次介紹、訓練與優化,詳細分析了其卷積層、激活函數、池化層、歸一化層,最后列出其訓練與優化的多項關鍵技術:訓練集準備與增強、損失函數、優化器、學習率調整、正則化技巧與模型評估調優。旨在為人工智能學者使用卷積神經網絡CNN提供全面的指導。
作者 TechLead,擁有10+年互聯網服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智能實驗室成員,阿里云認證的資深架構師,項目管理專業人士,上億營收AI產品研發負責人



















