《強化學習:原理與Python實戰》揭秘大模型核心技術RLHF!
- 一·圖書簡介
- 二·RLHF是什么?
- 三·RLHF適用于哪些任務?
- 四·RLHF和其他構造獎勵模型的方法相比有何優劣?
- 五·什么樣的人類反饋才是好反饋?
- 六·如何減小人類反饋帶來的負面影響?
- 七·購買鏈接
- 八·參與方式
- 九·往期贈書回顧
一·圖書簡介

RLHF(Reinforcement Learning with Human Feedback,人類反饋強化學習)雖是熱門概念,并非包治百病的萬用仙丹。本問答探討RLHF的適用范圍、優缺點和可能遇到的問題,供RLHF系統設計者參考。
二·RLHF是什么?
強化學習利用獎勵信號訓練智能體。有些任務并沒有自帶能給出獎勵信號的環境,也沒有現成的生成獎勵信號的方法。為此,可以搭建獎勵模型來提供獎勵信號。在搭建獎勵模型時,可以用數據驅動的機器學習方法來訓練獎勵模型,并且由人類提供數據。我們把這樣的利用人類提供的反饋數據來訓練獎勵模型以用于強化學習的系統稱為人類反饋強化學習,示意圖如下。
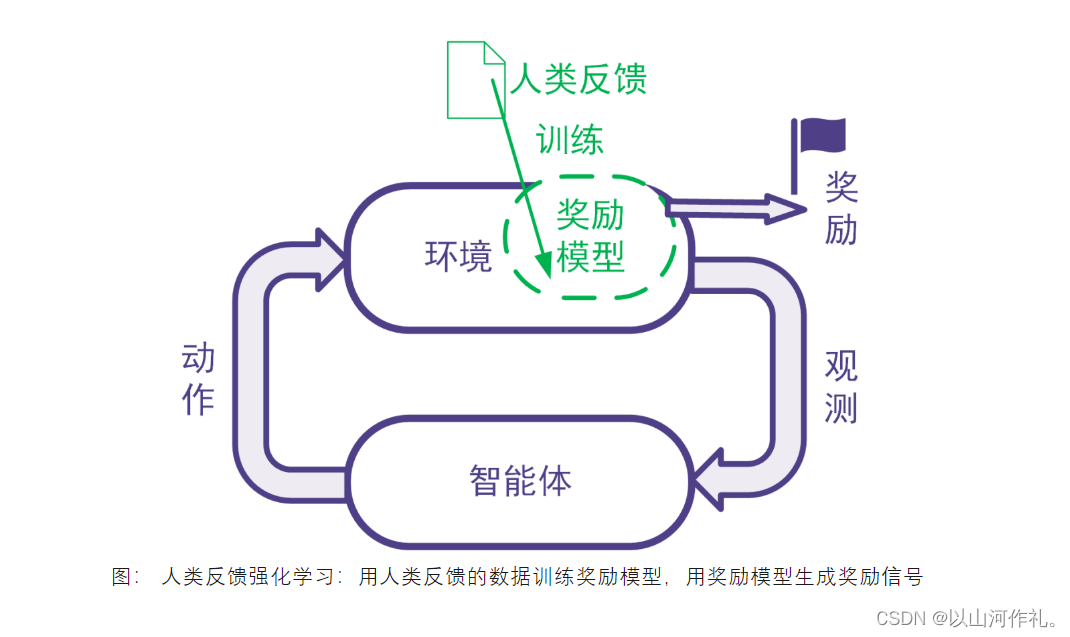
三·RLHF適用于哪些任務?
RLHF適合于同時滿足下面所有條件的任務:
- 要解決的任務是一個強化學習任務,但是沒有現成的獎勵信號并且獎勵信號的確定方式事先不知道。為了訓練強化學習智能體,考慮構建獎勵模型來得到獎勵信號。
- 反例:比如電動游戲有游戲得分,那樣的游戲程序能夠給獎勵信號,那我們直接用游戲程序反饋即可,不需要人類反饋。
- 反例:某些系統獎勵信號的確定方式是已知的,比如交易系統的獎勵信號可以由賺到的錢完全確定。這時直接可以用已知的數學表達式確定獎勵信號,不需要人工反饋。
- 不采用人類反饋的數據難以構建合適的獎勵模型,而且人類的反饋可以幫助得到合適的獎勵模型,并且人類來提供反饋可以在合理的代價(包括成本代價、時間代價等)內得到。如果用人類反饋得到數據與其他方法采集得到數據相比不具有優勢,那么就沒有必要讓人類來反饋。

四·RLHF和其他構造獎勵模型的方法相比有何優劣?
獎勵模型可以人工指定,也可以通過有監督模型、逆強化學習等機器學習方法來學習。RLHF使用機器學習方法學習獎勵模型,并且在學習過程中采用人類給出的反饋。
比較人工指定獎勵模型與采用機器學習方法學習獎勵模型的優劣:
這與對一般的機器學習優劣的討論相同。機器學習方法的優點包括不需要太多領域知識、能夠處理非常復雜的問題、能夠處理快速大量的高維數據、能夠隨著數據增大提升精度等等。機器學習算法的缺陷包括其訓練和使用需要數據時間空間電力等資源、模型和輸出的解釋型可能不好、模型可能有缺陷、覆蓋范圍不夠或是被攻擊(比如大模型里的提示詞注入)。
比較采用人工反饋數據和采用非人工反饋數據的優劣:
人工反饋往往更費時費力,并且不同人在不同時候的表現可能不一致,并且人還會有意無意地犯錯,或是人類反饋的結果還不如用其他方法生成數據來的有效,等等。我們在后文會詳細探討人工反饋的局限性。采用機器收集數據等非人工反饋數據則對收集的數據類型有局限性。有些數據只能靠人類收集,或是用機器難以收集。這樣的數據包括是主觀的、人文的數據(比如判斷藝術作品的藝術性),或是某些機器還做不了的事情(比如玩一個AI暫時還不如人類的游戲)。
五·什么樣的人類反饋才是好反饋?
好的反饋需要夠用:反饋數據可以用來學成獎勵模型,并且數據足夠正確、量足夠大、覆蓋足夠全面,使得獎勵模型足夠好,進而在后續的強化學習中得到令人滿意的智能體。
這個部分涉及的評價指標包括:對數據本身的評價指標(正確性、數據量、覆蓋率、一致性),對獎勵模型及其訓練過程的評價指標、對強化學習訓練過程和訓練得到的智能體的評價指標。
好的反饋需要是可得的反饋。反饋需要可以在合理的時間花費和金錢花費的情況下得到,并且在成本可控的同時不會引發其他風險(如法律上的風險)。
涉及的評價指標包括:數據準備時間、數據準備涉及的人員數量、數據準備成本、是否引發其他風險的判斷。
六·如何減小人類反饋帶來的負面影響?
針對人類反饋費時費力且可能導致獎勵模型不完整不正確的問題,可以在收集人類反饋數據的同時就訓練獎勵模型、訓練智能體,并全面評估獎勵模型和智能體,以便于盡早發現人類反饋的缺陷。發現缺陷后,及時進行調整。
針對人類反饋中出現的反饋質量問題以及錯誤反饋,可以對人類反饋進行校驗和審計,如引入已知獎勵的校驗樣本來校驗人類反饋的質量,或為同一樣本多次索取反饋并比較多次反饋的結果等。
針對反饋人的選擇不當的問題,可以在有效控制人力成本的基礎上,采用科學的方法選定提供反饋的人。可以參考數理統計里的抽樣方法,如分層抽樣、整群抽樣等,使得反饋人群更加合理。
對于反饋數據中未包括反饋人特征導致獎勵模型不夠好的問題,可以收集反饋人的特征,并將這些特征用于獎勵模型的訓練。比如,在大規模語言模型的訓練中可以記錄反饋人的職業背景(如律師、醫生等),并在訓練獎勵模型時加以考慮。當用戶要求智能體像律師一樣工作時,更應該利用由律師提供的數據學成的那部分獎勵模型來提供獎勵信號;當用戶要求智能體像醫生一樣工作時,更應該利用由醫生提供的數據學成的那部分獎勵模型來提供獎勵信號。
上述內容摘編自《強化學習:原理與Python實戰》,經出版方授權發布。(ISBN:978-7-111-72891-7)
七·購買鏈接
🎁🎁京東鏈接:https://item.jd.com/13815337.html
八·參與方式
🎁🎁
抽獎方式:評論區隨機抽取五位小伙伴免費送出!!
參與方式:關注博主、點贊、收藏、評論區評論“人生苦短,我愛Python!”
(切記要點贊+收藏,否則抽獎無效,每個人最多評論三次!)
活動截止時間:2023-08-21 20:00:00
九·往期贈書回顧
【山河贈書第一期】:《Python從入門到精通(微課精編版》三本
【山河贈書第二期】:《零基礎學會Python編程(ChatGPT版》一本
【山河贈書第三期】:《Python機器學習:基于PyTorch和Scikit-Learn 》四本
【山河送書第四期】:《Python之光:Python編程入門與實戰》五本
【山河送書第五期】:《碼上行動:利用Python與ChatGPT高效搞定Excel數據分析》三本
【山河送書第六期】:《碼上行動:零基礎學會Python編程( ChatGPT版)》兩本
🎁🎁加入粉絲群,不定期發放粉絲福利,各種專業書籍免費贈送!

)





——替換主干網絡之RepViT(清華 ICCV 2023|最新開源移動端ViT))

)









