文章目錄
- 問題
- 解決方案
- 1. 對ES的限制
- 2. 對Canal-Adapter的限制
問題
使用canal-adapter全量同步(參考Canal Adapter1.1.5版本API操作服務,手動同步數據(4))的時候
- 小批量數據可以正常運行(幾千條)
- 只要數據量一大(上萬條),就會內存、CPU雙線爆炸,ES自動被docker關閉。
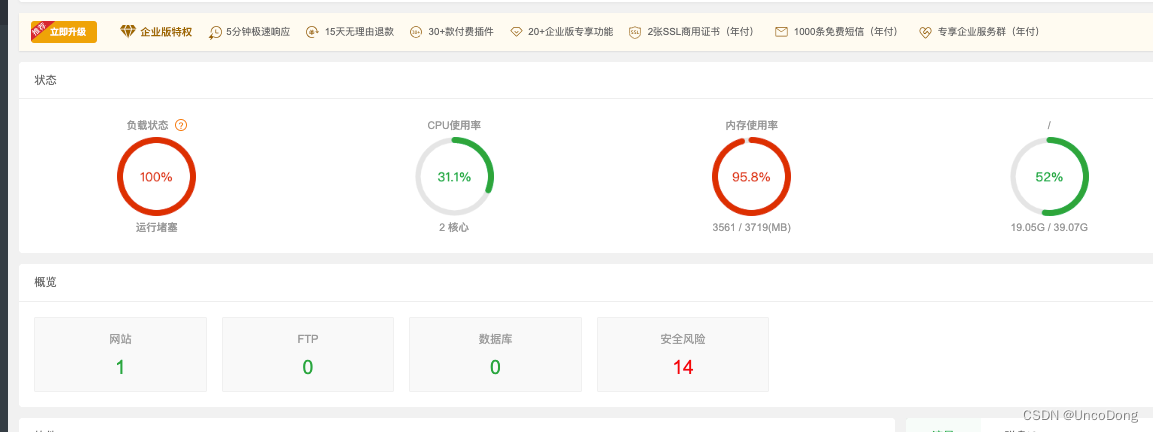
數據量大的時候系統負荷如下所示(用寶塔監控)
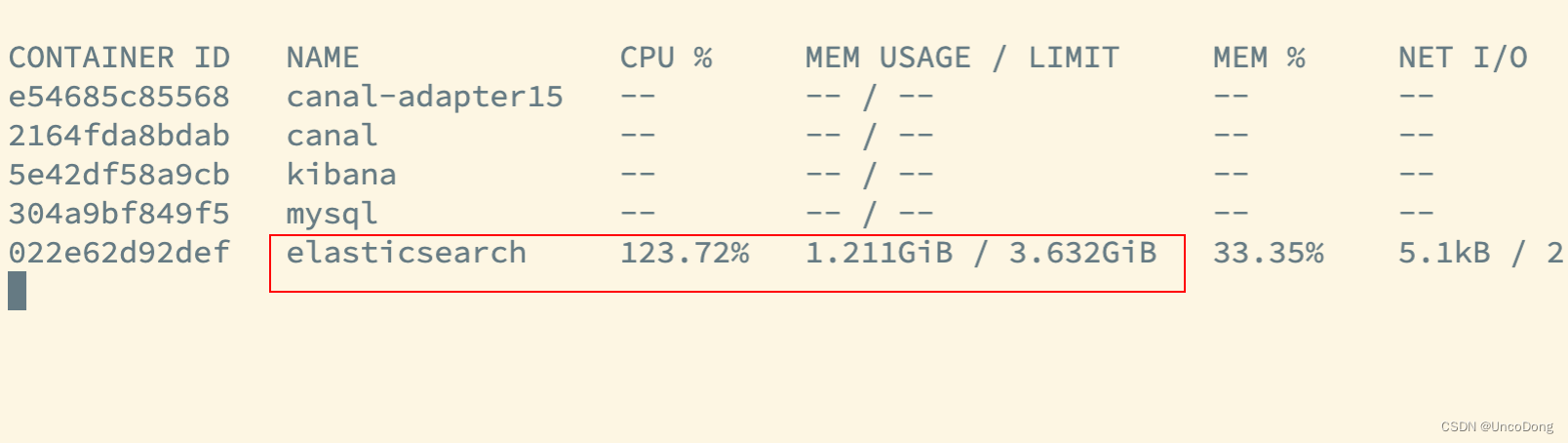
docker stats監控如下所示,很快其他容器全都變成--,完全無法提供服務
解決方案
1. 對ES的限制
參考Docker部署ES(增加內存限制啟動)
最關鍵的一句話:啟動的時候按照如下參數啟動。必須得先設置single-node單節點模式,然后設置ES_JAVA_OPTS="-Xms64m -Xmx512m" 才會成功。
docker run -d --name limit_es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" elasticsearch:7.6.2
ES_JAVA_OPTS的意思是設置ES中Java虛擬機環境的上下限
discovery.type=single-node是單節點模式的意思。和集群有關的配置可以參考ElasticSearch 設置-配置(一)發現和集群形成設置
-
discovery.seed_hosts:提供集群中符合主節點條件的節點列表。也可以是以逗號分隔的單個字符串。每個節點都是host:port或者host格式。host是由DNS解析出來的任意主機名稱。IPV6必須用方括號括起來。如果一個主機名通過DNS解析出來多個地址,ElasticSearch會使用所有被解析出來的地址。
-
discovery.seed_providers:指定種子主機提供程序的類型來獲取用于啟動發現進程的種子節點的地址。默認情況下,它是基于設置的種子主機提供程序,它從 discovery.seed_hosts 設置中獲取種子節點地址。此設置以前稱為 discovery.zen.hosts_provider。
-
discovery.type:指定 Elasticsearch 是否應形成多節點集群。默認情況下,Elasticsearch 在形成集群時會發現其他節點,并允許其他節點稍后加入集群。如果discovery.type 設置為single-node,Elasticsearch 會形成一個單節點集群并不支持cluster.publish.timeout 設置的超時。
-
cluster.initial_master_nodes:設置全新群集中符合條件的主節點的初始集。默認情況下,此列表為空,表示此節點希望加入已引導的集群。請參閱cluster.initial_master_nodes。
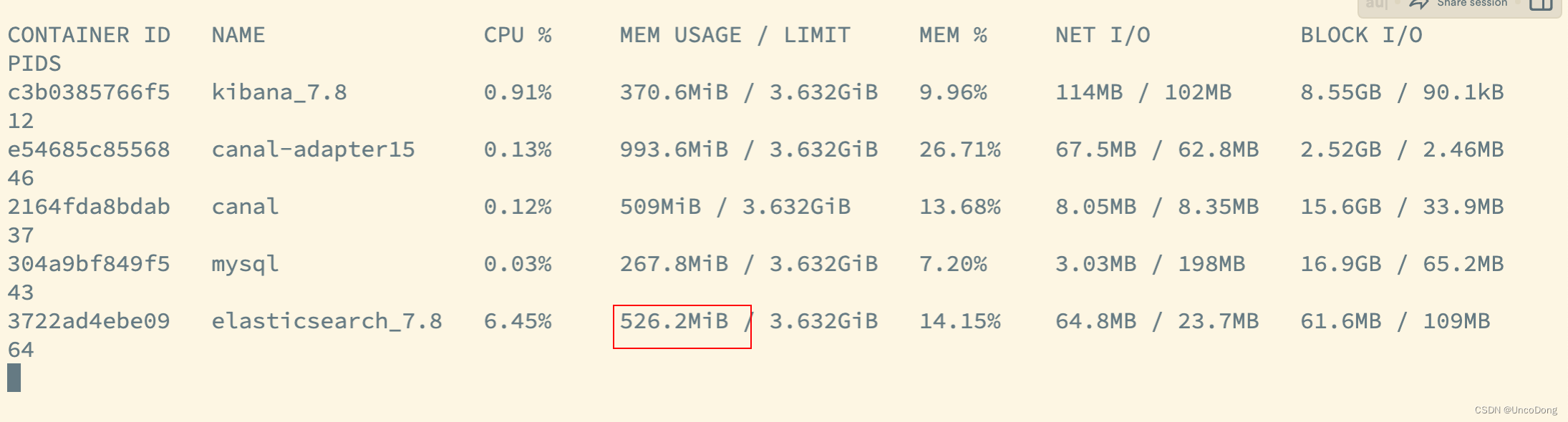
ES的內存占用顯著小了很多,并且可以直接同步大批量數據
2. 對Canal-Adapter的限制
我在canal-adapter中也提了一個issue,并嘗試自己解決
我對docker canal-adapter內部的start.sh進行了修改,似乎好像解決了這個問題?但是只是本地部署沒有看出問題,不知道線上如何。先記錄一下修改方案
以下修改方案基于slpcat/canal-adapter:v1.1.5-jdk8修改
首先docker exec進入到容器內部,修改啟動腳本vi bin/startup.sh
我修改了兩個地方
- if else判斷的地方,我直接指定JAVA_OPTS為非x64系統的配置
- 修改了原先的
-Xms和-Xmx,變成了新的104m和512m (隨便設置的,就想著要小一點),以及增加了新的參數-XX:MaxDirectMemorySize=128m
#!/bin/bashcurrent_path=`pwd`
case "`uname`" inLinux)bin_abs_path=$(readlink -f $(dirname $0));;*)bin_abs_path=`cd $(dirname $0); pwd`;;
esac
base=${bin_abs_path}/..
export LANG=en_US.UTF-8
export BASE=$baseif [ -f $base/bin/adapter.pid ] ; thenecho "found adapter.pid , Please run stop.sh first ,then startup.sh" 2>&2exit 1
fiif [ ! -d $base/logs ] ; thenmkdir -p $base/logs
fi## set java path
if [ -z "$JAVA" ] ; thenJAVA=$(which java)
fiALIBABA_JAVA="/usr/alibaba/java/bin/java"
TAOBAO_JAVA="/opt/taobao/java/bin/java"
if [ -z "$JAVA" ]; thenif [ -f $ALIBABA_JAVA ] ; thenJAVA=$ALIBABA_JAVAelif [ -f $TAOBAO_JAVA ] ; thenJAVA=$TAOBAO_JAVAelseecho "Cannot find a Java JDK. Please set either set JAVA or put java (>=1.5) in your PATH." 2>&2exit 1fi
ficase "$#"
in
0 );;
2 )if [ "$1" = "debug" ]; thenDEBUG_PORT=$2DEBUG_SUSPEND="n"JAVA_DEBUG_OPT="-Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,address=$DEBUG_PORT,server=y,suspend=$DEBUG_SUSPEND"fi;;
* )echo "THE PARAMETERS MUST BE TWO OR LESS.PLEASE CHECK AGAIN."exit;;
esacstr=`file -L $JAVA | grep 64-bit`
if [ -n "$str" ]; thenJAVA_OPTS="-server -Xms2048m -Xmx3072m -Xmn1024m -XX:SurvivorRatio=2 -Xss256k -XX:+DisableExplicitGC -XX:+HeapDumpOnOutOfMemoryError"
elseJAVA_OPTS="-server -Xms1024m -Xmx1024m -XX:NewSize=256m -XX:MaxNewSize=256m -XX:MaxPermSize=128m "
fi
## 主要是修改了這個地方,修改了啟動參數
JAVA_OPTS="-server -Xms104m -Xmx512m -XX:NewSize=256m -XX:MaxNewSize=256m -XX:MaxDirectMemorySize=128m -XX:MaxPermSize=128m "
echo $JAVA_OPTS
JAVA_OPTS=" $JAVA_OPTS -Djava.awt.headless=true -Djava.net.preferIPv4Stack=true -Dfile.encoding=UTF-8"
ADAPTER_OPTS="-DappName=canal-adapter"for i in $base/lib/*;do CLASSPATH=$i:"$CLASSPATH";
doneCLASSPATH="$base/conf:$CLASSPATH";echo "cd to $bin_abs_path for workaround relative path"
cd $bin_abs_pathecho CLASSPATH :$CLASSPATH
exec $JAVA $JAVA_OPTS $JAVA_DEBUG_OPT $ADAPTER_OPTS -classpath .:$CLASSPATH com.alibaba.otter.canal.adapter.launcher.CanalAdapterApplication
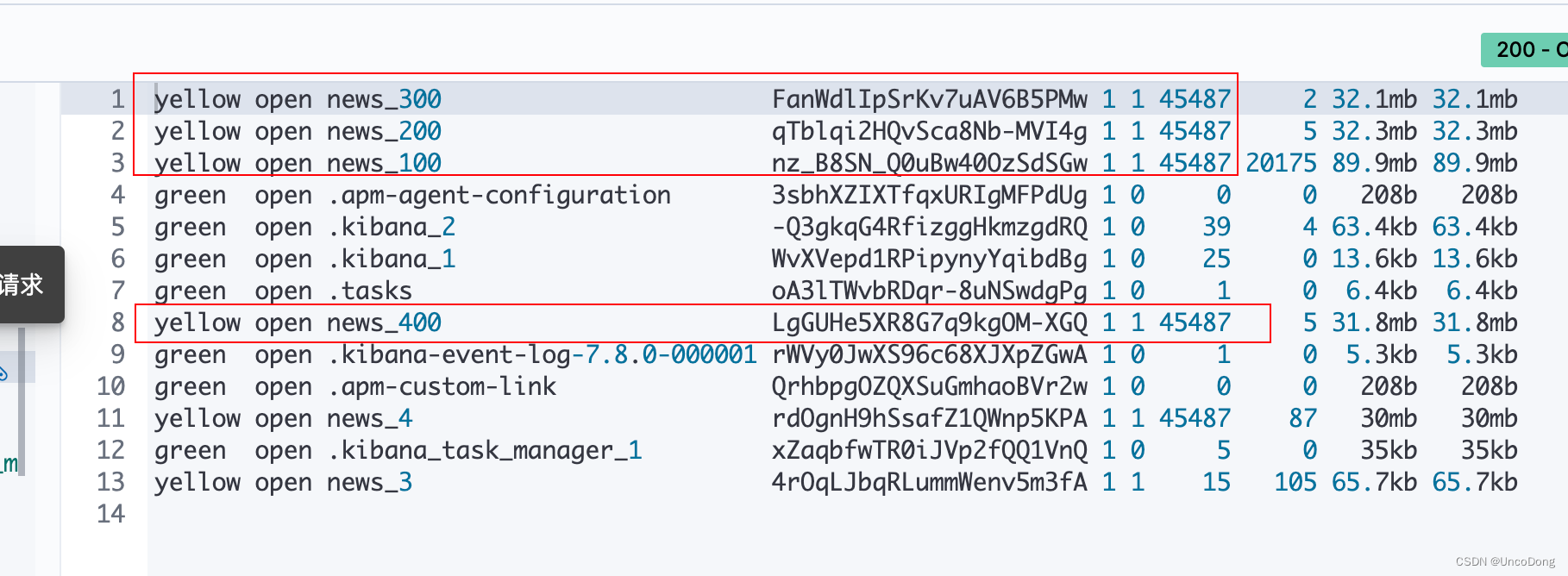
可以看到插入幾萬條數據后(確實也同步到ES中了),adapter的內存反而還下降了?不是很懂,只能說回想起了深度學習調參的日子

實現數據雙向綁定)








掌握最基本的Linux服務器用法——Linux下簡單的C/C++ 程序、項目編譯)



)




