7 分布式鎖
分布式鎖是控制分布式系統之間同步訪問共享資源的一種方式。如果不同的系統或是同一個系統的不同主機之間共享了一個或一組資源,那么訪問這些資源的時候,往往需要通過一些互斥手段來防止彼此之間的干擾,以保證一致性,在這種情況下,就需要使用分布式鎖了。
在平時的實際項目開發中,我們往往很少會去在意分布式鎖,而是依賴于關系型數據庫固有的排他性來實現不同進程之間的互斥。這確實是一種非常簡便且被廣泛使用的分布式鎖實現方式。然而有一個不爭的事實是,目前絕大多數大型分布式系統的性能瓶頸都集中在數據庫操作上。因此,如果上層業務再給數據庫添加一些額外的鎖,例如行鎖、表鎖甚至是繁重的事務處理,那么是不是會讓數據庫更加不堪重負呢?下面我們來看看使用ZooKeeper如何實現分布式鎖,這里主要講解排他鎖和共享鎖兩類分布式鎖。
排他鎖
排他鎖(Exclusive Locks,簡稱X鎖),又稱為寫鎖或獨占鎖,是一種基本的鎖類型。
如果事務T1對數據對象O1加上了排他鎖,那么在整個加鎖期間,只允許事務T1對O1進行讀取和更新操作,其他任何事務都不能再對這個數據對象進行任何類型的操作——直到T1釋放了排他鎖。
從上面講解的排他鎖的基本概念中,我們可以看到,排他鎖的核心是如何保證當前有且僅有一個事務獲得鎖,并且鎖被釋放后,所有正在等待獲取鎖的事務都能夠被通知到。
下面我們就來看看如何借助ZooKeeper實現排他鎖。
定義鎖
在通常的Java開發編程中,有兩種常見的方式可以用來定義鎖,分別是synchronized機制和JDK5提供的ReentrantLock。然而,在ZooKeeper中,沒有類似于這樣的API可以直接使用,而是通過ZooKeeper上的數據節點來表示一個鎖,例如/exclusive_lock/lock節點就可以被定義為一個鎖,如下圖所示。

獲取鎖
在需要獲取排他鎖時,所有的客戶端都會試圖通過調用create()接口,在/exclusive_lock 節點下創建臨時子節點/exclusive_lock/lock。在前面幾節中我們也介紹了,ZooKeeper會保證在所有的客戶端中,最終只有一個客戶端能夠創建成功,那么就可以認為該客戶端獲取了鎖。同時,所有沒有獲取到鎖的客戶端就需要到/exclusive_lock節點上注冊一個子節點變更的Watcher監聽,以便實時監聽到lock節點的變更情況。
釋放鎖
在“定義鎖”部分,我們已經提到,/exclusive_lock/lock是一個臨時節點,因此在以下兩種情況下,都有可能釋放鎖。
(1)當前獲取鎖的客戶端機器發生宕機,那么ZooKeeper上的這個臨時節點就會被移除。
(2)正常執行完業務邏輯后,客戶端就會主動將自己創建的臨時節點刪除。
無論在什么情況下移除了lock 節點,ZooKeeper都會通知所有在/exclusive_lock節點上注冊了子節點變更Watcher監聽的客戶端。這些客戶端在接收到通知后,再次重新發起分布式鎖獲取,即重復“獲取鎖”過程。整個排他鎖的獲取和釋放流程,可以用下圖來表示。

共享鎖
共享鎖(Shared Locks,簡稱S鎖),又稱為讀鎖,同樣是一種基本的鎖類型。如果事務T1對數據對象O1,加上了共享鎖,那么當前事務只能對O1進行讀取操作,其他事務也只能對這個數據對象加共享鎖一直到該數據對象上的所有共享鎖都被釋放。
共享鎖和排他鎖最根本的區別在于,加上排他鎖后,數據對象只對一個事務可見,而加上共享鎖后,數據對所有事務都可見。下面我們就來看看如何借助ZooKeeper來實現共享鎖。
定義鎖
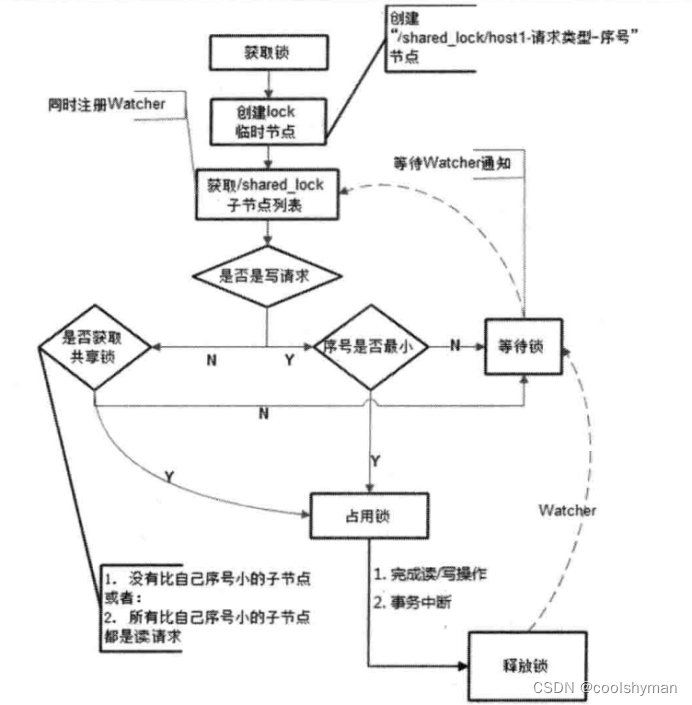
和排他鎖一樣,同樣是通過ZooKeeper上的數據節點來表示一個鎖,是一個類似于“/shared_lock/[Hostname]-請求類型-序號”的臨時順序節點,例如/shared_lock/192.168.0.1-0000000001,那么,這個節點就代表了一個共享鎖。
獲取鎖
在需要獲取共享鎖時,所有客戶端都會到/shared_lock這個節點下面創建一個臨時順序節點,如果當前是讀請求,那么就創建例如/shared_lock/192. 168.0.1-0000000001的節點;如果是寫請求,那么就創建例如/shared_lock/192.168.0. I-W-000000001的節點。
判斷讀寫順序
根據共享鎖的定義,不同的事務都可以同時對同一個數據對象進行讀取操作,而更新操作必須在當前沒有任何事務進行讀寫操作的情況下進行。基于這個原則,我們來看看如何通過ZooKeeper的節點來確定分布式讀寫順序,大致可以分為如下4個步驟。
(1)創建完節點后,獲取/shared_lock節點下的所有子節點,并對該節點注冊子節點變更的Watcher監聽。
(2)確定自己的節點序號在所有子節點中的順序。
(3)對于讀請求:
如果沒有比自己序號小的子節點,或是所有比自己序號小的子節點都是讀請求,那么表明自己已經成功獲取到了共享鎖,同時開始執行讀取邏輯。
如果比自己序號小的子節點中有寫請求,那么就需要進入等待。
對于寫請求:
如果自己不是序號最小的子節點,那么就需要進入等待。
(4)接收到Watcher通知后,重復步驟1。
釋放鎖
釋放鎖的邏輯和排他鎖是一致的,這里不再贅述。整個共享鎖的獲取和釋放流程,可以用下圖來表示。
羊群效應
上面講解的這個共享鎖實現,大體上能夠滿足一般的分布式集群競爭鎖的需求,并且性能都還可以一這里說的一般場景是指集群規模不是特別大,一般是在10臺機器以內。
但是如果機器規模擴大之后,會有什么問題呢?我們著重來看上面“判斷讀寫順序”程的步驟3,結合下圖給出的實例,看看實際運行中的情況。

針對上圖中的實際情況,我們看看會發生什么事情。
(1)192.168.0.1這臺機器首先進行讀操作,完成讀操作后將節點/192.168.0.1-R-0000000001刪除。
(2)余下的4臺機器均收到了這個節點被移除的通知,然后重新從/shared_lock節點上獲取一份新的子節點列表。
(3)每個機器判斷自己的讀寫順序。其中192.168.0.2這臺機器檢測到自己已經是序號最小的機器了,于是開始進行寫操作,而余下的其他機器發現沒有輪到自己進行讀取或更新操作,于是繼續等待。
(4)繼續....
上面這個過程就是共享鎖在實際運行中最主要的步驟了,我們著重看下上面步驟3中提
到的:“而余下的其他機器發現沒有輪到自己進行讀取或更新操作,于是繼續等待。”很
明顯,我們看到,192.168.0.1 這個客戶端在移除自己的共享鎖后,ZooKeeper 發送了子
節點變更Watcher通知給所有機器,然而這個通知除了給192.168.0.2這臺機器產生實際
影響外,對于余下的其他所有機器都沒有任何作用。
相信讀者也已經意識到了,在這整個分布式鎖的競爭過程中,大量的“Watcher通知”和“子節點列表獲取”兩個操作重復運行,并且絕大多數的運行結果都是判斷出自己并非是序號最小的節點,從而繼續等待下一次通知——這個看起來顯然不怎么科學。客戶端無端地接收到過多和自己并不相關的事件通知,如果在集群規模比較大的情況下,不僅會對ZooKeeper服務器造成巨大的性能影響和網絡沖擊,更為嚴重的是,如果同一時間有多個節點對應的客戶端完成事務或是事務中斷引起節點消失,ZooKeeper服務器就會在短時間內向其余客戶端發送大量的事件通知一這就是所謂的羊群效應。
上面這個ZooKeeper分布式共享鎖實現中出現羊群效應的根源在于,沒有找準客戶端真正的關注點。我們再來回顧一下上面的分布式鎖競爭過程,它的核心邏輯在于:判斷自己是否是所有子節點中序號最小的。于是,很容易可以聯想到,每個節點對應的客戶端只需要關注比自己序號小的那個相關節點的變更情況就可以了一而不需要關注全局的子列表變更情況。
改進后的分布式鎖實現
現在我們來看看如何改進上面的分布式鎖實現。首先,我們需要肯定的一點是,上面提到的共享鎖實現,從整體思路上來說完全正確。這里主要的改動在于:每個鎖競爭者,只需要關注/shared.lock節點下序號比自己小的那個節點是否存在即可,具體實現如下。
(1)客戶端調用create()方法創建一個類似于“/shared_ lock/[Hostname]請求類型-序號”的臨時順序節點。
(2)客戶端調用getChildren()接口來獲取所有已經創建的子節點列表,注意,這里不注冊任何Watcher。
(3)如果無法獲取共享鎖,那么就調用exist()來對比自己小的那個節點注冊Watcher。
注意,這里“比自己小的節點”只是一個籠統的說法,具體對于讀請求和寫請求不一樣。
讀請求:向比自己序號小的最后一個寫請求節點注冊Watcher監聽。
寫請求:向比自己序號小的最后一個節點注冊Watcher 監聽。
(4)等待Watcher通知,繼續進入步驟2。
改進后的分布式鎖流程如下圖所示。

8 分布式隊列
業界有不少分布式隊列產品,不過絕大多數都是類似于ActiveMQ、Metamorphosis、Kafka和HornetQ等的消息中間件(或稱為消息隊列)。在本文中,我們主要介紹基于ZooKeeper實現的分布式隊列。分布式隊列,簡單地講分為兩大類,一種是常規的先入先出隊列,另一種則是要等到隊列元素集聚之后才統一安排執行的Barrier模型。
FIFO:先入先出
FIFO (First Input First Output,先入先出)的算法思想,以其簡單明了的特點,廣泛應用于計算機科學的各個方面。而FIFO隊列也是一種非常典型且應用廣泛的按序執行的隊列模型:先進入隊列的請求操作先完成后,才會開始處理后面的請求。
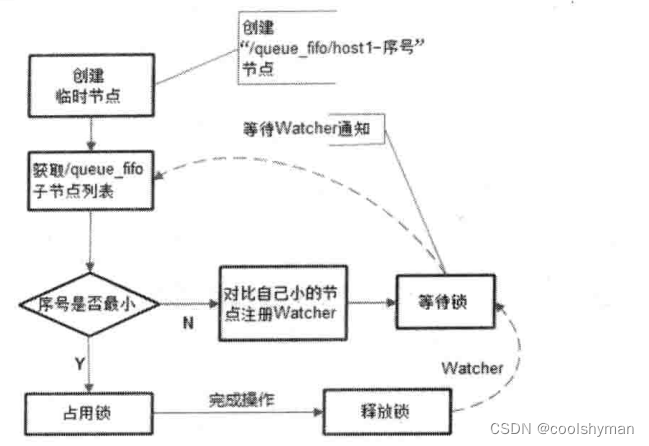
使用ZooKeeper實現FIFO隊列,和前面共享鎖的實現非常類似。FIFO 隊列就類似于一個全寫的共享鎖模型,大體的設計思路其實非常簡單:所有客戶端都會到/queue_fifo這個節點下面創建一個臨時順序節點,例如/queue. fifo/192. 168.0.1-0000000001。
創建完節點之后,根據如下4個步驟來確定執行順序。
(1)通過調用getChildren()接口來獲取/queue_fifo節點下的所有子節點,即獲取隊列中所有的元素。
(2)確定自己的節點序號在所有子節點中的順序。
(3)如果自己不是序號最小的子節點,那么就需要進入等待,同時向比自己序號小的最后一個節點注冊Watcher監聽。
(4)接收到Watcher通知后,重復步驟1。
整個FIFO隊列的工作流程,可以用下圖來表示。
Barrier:分布式屏障
Barrier原意是指障礙物、屏障,而在分布式系統中,特指系統之間的一個協調條件,規定了一個隊列的元素必須都集聚后才能統一進行安排, 否則一直等待。這往往出現在那些大規模分布式并行計算的應用場景上:最終的合并計算需要基于很多并行計算的子結果來進行。這些隊列其實是在FIFO 隊列的基礎上進行了增強,大致的設計思想如下:開始時,/queue_barrier節點是一個已經存在的默認節點,并且將其節點的數據內容賦值為一個數字n來代表Barrier 值,例如n=10表示只有當/queue_barrier節點下的子節點個數達到10后,才會打開Barrier。之后,所有的客戶端都會到/queue_barrier節點下創建一個臨時節點,例如/queue_barrier/192.168.0.1。
創建完節點之后,根據如下5個步驟來確定執行順序。
(1)通過調用getData()接口獲取/queue_barrier節點的數據內容:10。
(2)通過調用getChildren()接口獲取/queue_barrier節點下的所有子節點,即獲取隊列中的所有元素,同時注冊對子節點列表變更的Watcher監聽。
(3)統計子節點的個數。
(4)如果子節點個數還不足10個,那么就需要進入等待。
(5)接收到Watcher通知后,重復步驟2。
遞歸 JAVA)









)








)