機器學習介紹

Hnad-crafted rules
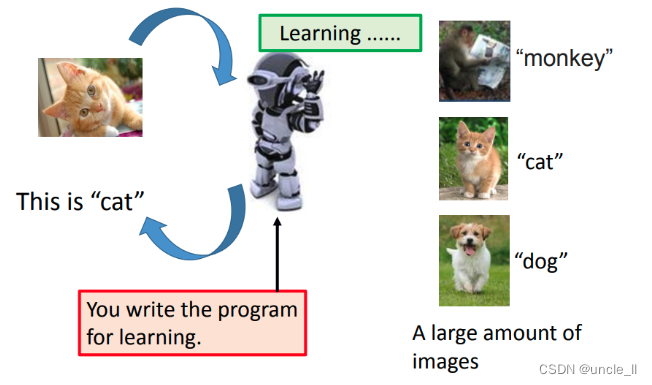
Hand-crafted rules,叫做人設定的規則。那假設今天要設計一個機器人,可以幫忙打開或關掉音樂,那做法可能是這樣:
- 設立一條規則,就是寫一段程序。如果輸入的句子里面看到**“turn off”**這個詞匯,那chat-bot要做的事情就是把音樂關掉。這個時候,之后對chat-bot說,
Please turn off the music或can you turn off the music, Smart? 它就會幫你把音樂關掉。看起來好像很聰明。別人就會覺得果然這就是人工智能。但是如果今天想要欺負chat-bot一下,就可以說please don‘t turn off the music,但是還是會把音樂關掉。這是個真實的例子。相同的例子在車上面也體現,打開車窗,不要打開車窗,最終都會打開車窗。身邊有很多這種類似的chat-bot,然后去真的對它說這種故意欺負它的話,它其實是會答錯的。
使用hand-crafted rules有什么樣的壞處呢,它的壞處就是:hand-crafted rules沒辦法考慮到所有的可能性,它非常的僵化,而用hand-crafted rules創造出來的machine,它永遠沒有辦法超過它的創造者人類。 人類想不到東西,就沒辦法寫規則,沒有寫規則,機器就不知道要怎么辦。所以如果一個機器,它只能夠按照人類所設定好的hand-crafted rules,它整個行為都是被規定好的,沒有辦法freestyle。如果是這樣的話,它就沒有辦法超越創造它的人類。
你好像看到很多chat-bot看起來非常的聰明。如果你是有一個是一個非常大的企業,他給以派給成千上萬的工程師,用血汗的方式來建出數以萬計的規則,然后讓他的機器看起來好像很聰明。但是對于中小企業來說,這樣建規則的方式反而是不利的。
要做的其實是讓機器它有自己學習的能力,也就我們要做的應該machine learning的方向。講的比較擬人化一點,所謂machine learning的方向,就是你就寫段程序,然后讓機器人變得了很聰明,他就能夠有學習的能力。接下來,你就像教一個嬰兒、教一個小孩一樣的教他,你并不是寫程序讓他做到這件事,你是寫程序讓它具有學習的能力。然后接下來,你就可以用像教小孩的方式告訴它。
machine learning所做的事情,可以想成就是在尋找一個function,要讓機器具有一個能力,這種能力是根據你提供給它的資料去尋找要尋找的function。


要先準備一個function set(集合),這個function里面有成千上萬的function。舉例來說,這個function在里面,有一個f1,你給它看一只貓,它就告訴你輸出貓,看一只狗就輸出狗。有一個function f2它很怪,你給它看貓,它說是猴子;你給他看狗,它說是蛇。所以要準備一個function set,這個function set里面有成千上萬的function。先假設手上有一個function set,這個function set就叫做model(模型)。

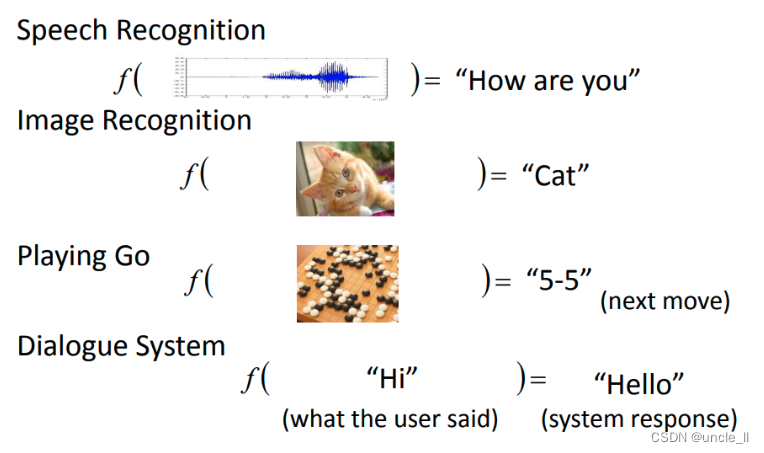
有了這個function set,接下來機器要做的事情是:它有一些訓練的資料,這些訓練資料告訴機器說一個好的function,它的輸入輸出應該長什么樣子,有什么樣關系。你告訴機器說呢,現在在這個影像辨識的問題里面,如果看到這個猴子,看到這個猴子圖也要輸出猴子,看到這個貓的圖也要輸出猴子貓,看到這個狗的圖,就要輸出猴子貓狗,這樣才是對的。只有這些訓練資料,拿出一個function,機器就可以判斷說,這個function是好的還是不好的。

機器可以根據訓練資料判斷一個function是好的,還是不好的。舉例來說:在這個例子里面顯然 f 1 f_1 f1?,他比較符合training data的敘述,比較符合我們的知識。所以f1看起來是比較好的。 f 2 f_2 f2?看起來是一個荒謬的function。這種task叫做supervised learning

現在機器有辦法決定一個function的好壞。但光能夠決定一個function的好壞是不夠的,因為在function set里面有成千上萬的function,它有會無窮無盡的function,所以需要一個有效率的評估算法,可以從function的set里面挑出最好的function。一個一個衡量function的好壞太花時間,實際上做不到。所以需要有一個好的評價算法,從function set里面挑出一個最好的的function,這個最好的function將它記為 f ? f^* f??
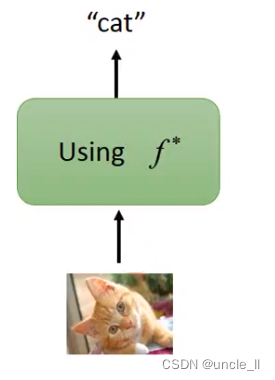
machine learning里面非常重要的問題:機器有舉一反三的能力
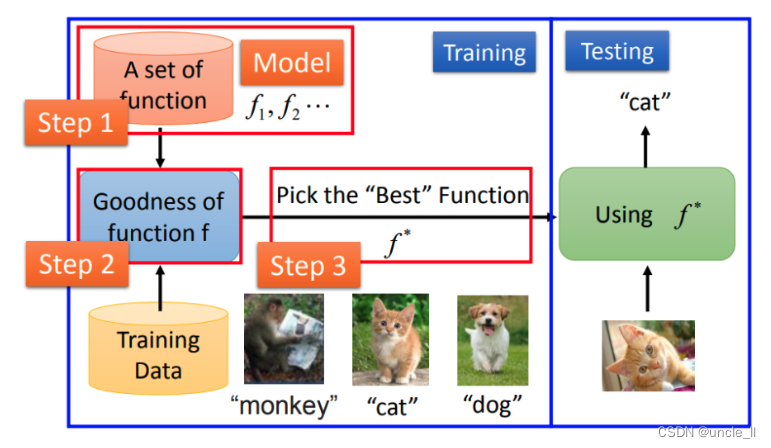
左邊這個部分叫training,就是學習的過程;右邊這個部分叫做testing,學好以后就可以拿它做應用。所以在整個machine learning framework整個過程分成了三個步驟:
- 第一個步驟就是找一個function
- 第二個步驟讓machine可以衡量一個function是好還是不好
- 第三個步驟是讓machine有一個自動的方法,有一個好評估算法可以挑出最好的function。
機器學習其實只有三個步驟,這三個步驟簡化了整個process。可以類比為:把大象放進冰箱。把大象塞進冰箱,其實也是三個步驟:把門打開;象塞進去;后把門關起來,然后就結束了。所以說,機器學習三個步驟,就好像是說把大象放進冰箱,也只需要三個步驟。
監督學習
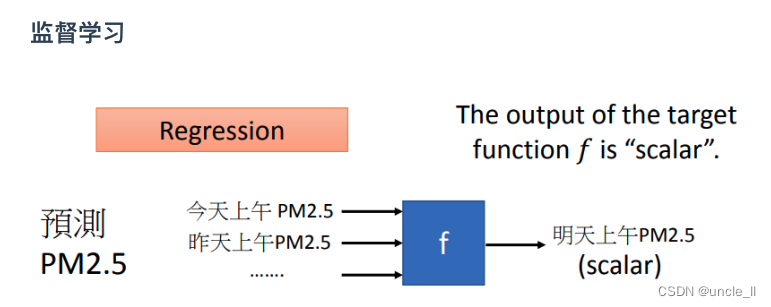
Regression是一種machine learning的task,當我們說:要做regression時的意思是,machine找到的function,它的輸出是一個scalar,這個叫做regression。舉例來說,在作業一里面會做PM2.5的預測(比如說預測明天上午的PM2.5) ,也就是說要找一個function,這個function的輸出是未來某一個時間PM2.5的一個數值,這個是一個regression的問題。
機器要判斷function明天上午的PM2.5輸出,你要提供給它一些資訊,它才能夠猜出明天上午的PM2.5。你給他數據可能是今天上的PM2.5、昨天上午的PM2.5等等。這是一個function,它吃我們給它過去PM2.5的資料,它輸出的是預測未來的PM2.5。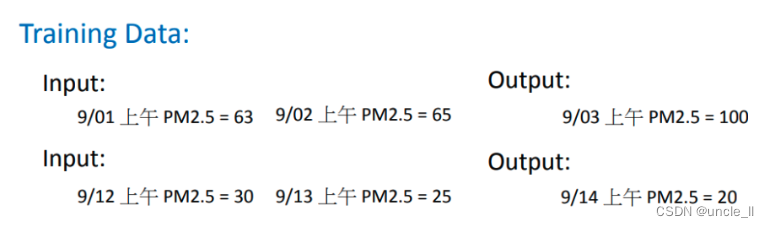
若要訓練這種machine,如同在Framework中講的,需要準備一些訓練資料,就告訴它是根據過去從政府的open data上搜集下來的資料。九月一號上午的PM2.5是63,九月二號上午的PM2.5是65,九月三號上午的PM2.5是100。所以一個好的function輸入九月一號、九月二號的PM2.5,它應該輸出九月三號的PM2.5;若給function九月十二號的PM2.5、九月十三號的PM2.5,它應該輸出九月十四號的PM2.5。若收集更多的data,那就可以做一個氣象預報的系統
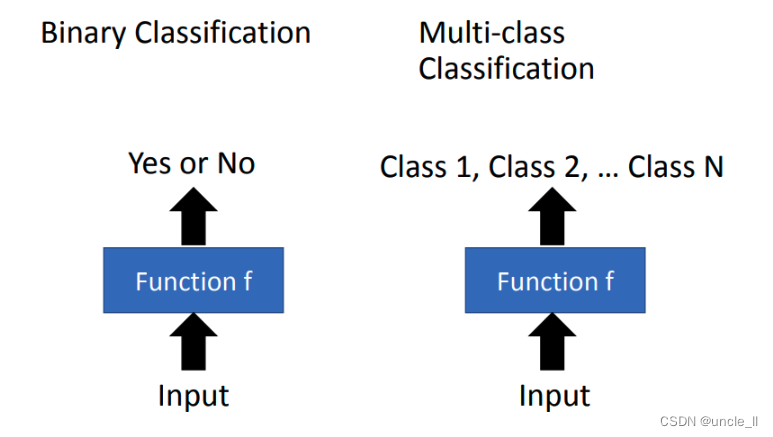
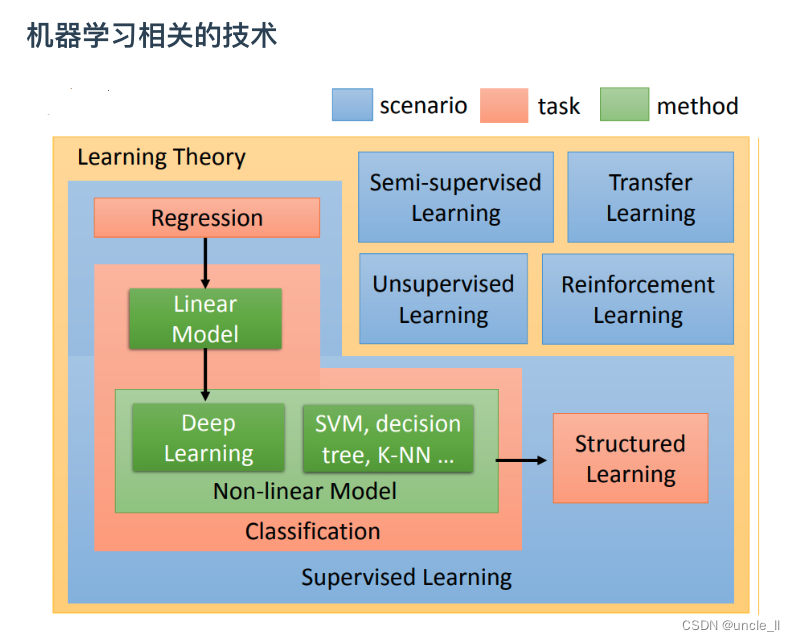
classification(分類)的問題。Regression和Classification的差別就是要機器輸出的東西的類型是不一樣。在Regression中機器輸出的是一個數值,在Classification里面機器輸出的是類別。假設Classification問題分成兩種,一種叫做二分類輸出的是是或否(Yes or No);另一類叫做多分類(Multi-class),在Multi-class中是讓機器做一個選擇題,等于是給他數個選項,每個選項都是一個類別,讓從數個類別里選擇正確的類別。


訓練這樣的function很簡單,給它一大堆的Data并告訴它,現在輸入這封郵件,應該說是垃圾郵件,輸入這封郵件,應該說它不是垃圾郵件。足夠多的這種資料去學就可以自動找出一個可以偵測垃圾郵件的function。

剛才講的都是讓machine去解的任務,接下來要講的是在解任務的過程中第一步就是要選擇function set,選不同的function set就是選不同的model。Model有很多種,最簡單的就是線性模型,但會花很多時間在非線性的模型上。在非線性的模型中最耳熟能詳的就是Deep learning。
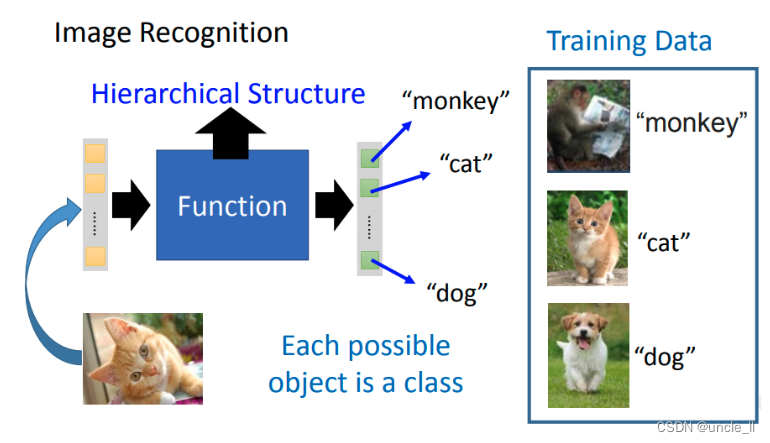
在做Deep learning時,它的function是特別復雜的,所以它可以做特別復雜的事情。比如它可以做圖像識別,這個復雜的function可以描述pixel和class之間的關系。
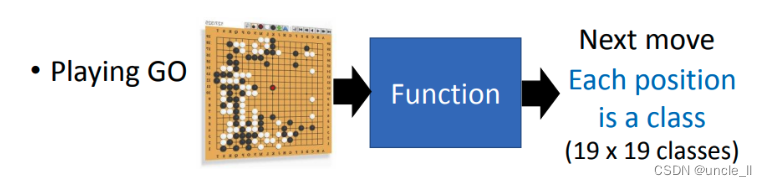
用Deep learning的技術也可以讓機器下圍棋, 下圍棋這個task 其實就是一個分類的問題。對分類問題需要一個很復雜的function,輸入是一個棋盤的格子,輸出就是下一步應該落子的位置。知道一個棋盤上有十九乘十九的位置可以落子,所以今天下圍棋這件事情就可以把它想成是一個十九乘十九個類別的分類問題,或者是可以把它想成是一個有十九乘十九個選項的選擇題。
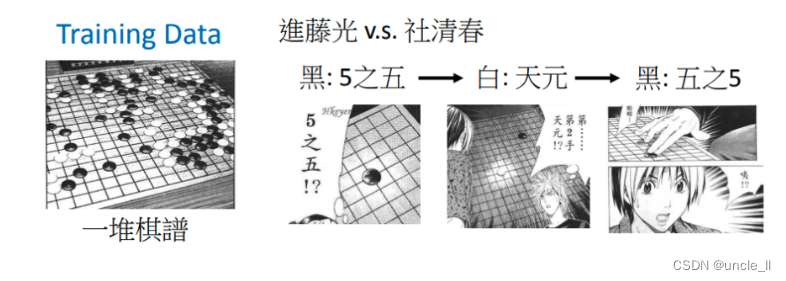
所以若你有了這樣的棋譜之后,可以告訴machine如果現在有人落子下5之五,下一步就落子在天元;若五之五和天元都有落子,那就要落子在另外一個五之5上。然后你給它足夠多的棋譜,它就能學會下圍棋了。

剛才講的都是supervised learning(監督學習),監督學習的問題是需要大量的training data。training data告訴要找的function的input和output之間的關系。如果在監督學習下進行學習,需要告訴機器function的input和output是什么。這個output往往沒有辦法用很自然的方式取得,需要人工的力量把它標注出來,這些function的output叫做label。
半監督學習

假設先想讓機器鑒別貓狗的不同,想做一個分類器讓它告訴你,圖片上是貓還是狗。有少量的貓和狗的labelled data,但是同時又有大量的Unlabeled data,但是又沒有力氣去告訴機器說哪些是貓哪些是狗。在半監督學習的技術中,這些沒有label的data,這些數據可能也是對學習有幫助,之后會講為什么這些沒有label的data對學習會有幫助。
另外一個減少data用量的方向是遷移學習。
遷移學習

遷移學習的意思是:假設要做貓和狗的分類問題,只有少量的有label的data。但是現在有大量的data,這些大量的data中可能有label也可能沒有label。但是跟我們現在要考慮的問題是沒有什么特別的關系的,分辨的是貓和狗的不同,但是這邊有一大堆其他動物的圖片還是動畫圖片。
更加進階的就是無監督學習,希望機器可以學到無師自通。
無監督學習
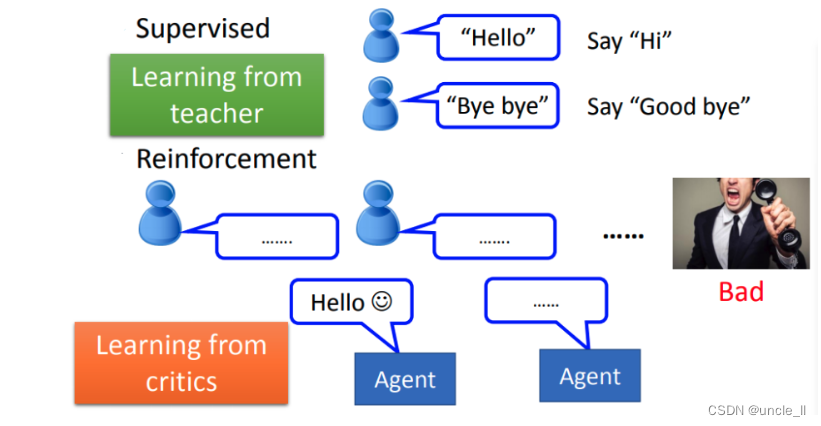
在reinforcement learning里面,沒有告訴機器正確的答案是什么,機器所擁有的只有一個分數,就是他做的好還是不好。若現在要用reinforcement learning方法來訓練一個聊天機器人的話,訓練的方法會是這樣:就把機器發到線下,讓它和進來的客人對話,然后對話半天以后呢,最后客人勃然大怒把電話掛掉了。那機器就學到一件事情就是剛才做錯了。但是它不知道哪邊錯了,它就要回去自己想道理,是一開始就不應該打招呼嗎?還是中間不應該在罵臟話了之類。它不知道,也沒有人告訴它哪里做的不好,它要回去反省檢討哪一步做的不好。機器要在reinforcement learning的情況下學習,機器是非常intelligence的。 reinforcement learning也是比較符合人類真正的學習的情景,這是在學校里面的學習老師會告訴你答案,但在真實社會中沒人回告訴你正確答案。只知道做得好還是做得不好,如果機器可以做到reinforcement learning,那確實是比較intelligence。
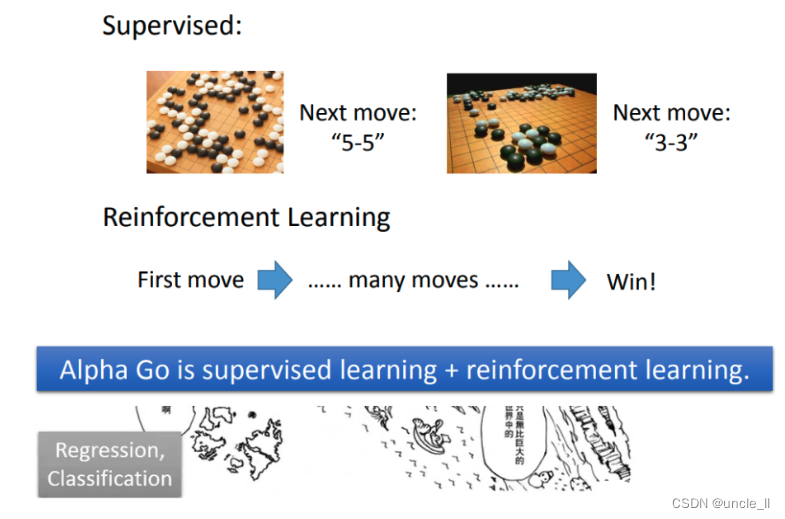
Alpha Go其實是用監督學習加上reinforcement learning去學習的。先用棋譜做監督學習,然后在做reinforcement learning,但是reinforcement learning需要一個對手,如果使用人當對手就會很讓費時間,所以機器的對手是另外一個機器。








用法)










