推薦:使用 NSDT場景編輯器 助你快速搭建可二次編輯器的3D應用場景
?

?
企業需要自定義模型來根據其特定用例和領域知識定制語言處理功能。自定義LLM使企業能夠在特定的行業或組織環境中更高效,更準確地生成和理解文本。
自定義模型使企業能夠創建符合其品牌聲音的個性化解決方案,優化工作流程,提供更精確的見解,并提供增強的用戶體驗,最終推動市場競爭優勢。
這篇文章涵蓋了各種模型定制技術以及何時使用它們。NVIDIA NeMo 支持許多方法。
NVIDIA NeMo 是一個端到端的云原生框架,可在任何地方構建、定制和部署生成式 AI 模型。它包括訓練和推理框架、護欄工具包、數據管理工具和預訓練模型,提供了一種簡單、經濟高效且快速的采用生成 AI 的方法。
選擇 LLM 自定義技術
您可以根據數據集大小要求與自定義期間的訓練工作量級別(與下游任務準確性要求相比)之間的權衡來對技術進行分類。

圖1.LLM 定制技術可用于 NVIDIA NeMo
圖 1 顯示了以行的自定義技術:
- 提示工程:操作發送到LLM的提示,但不以任何方式更改LLM的參數。它在數據和計算要求方面很輕。
- 快速學習:使用提示和完成對,通過虛擬令牌向LLM傳授特定于任務的知識。此過程需要更多的數據和計算,但比提示工程具有更好的準確性。
- 參數高效微調(PEFT):將少量參數或層引入現有LLM架構,并使用特定于用例的數據進行訓練,提供比提示工程和快速學習更高的準確性,同時需要更多的訓練數據和計算。
- 微調:涉及更新預訓練的LLM權重,這與前面概述的三種類型的自定義技術不同,這些技術使這些權重保持凍結。這意味著與其他技術相比,微調還需要最多的訓練數據和計算。但是,它為特定用例提供了最準確的準確性,從而證明了成本和復雜性的合理性。
有關更多信息,請參見大型語言模型簡介:提示工程和 P 調優。
快速工程
提示工程涉及在推理時通過展示和講述示例進行定制。LLM提供了示例提示和完成,這些詳細說明附加到新提示之前以生成所需的完成。模型的參數不會更改。
少數鏡頭提示:此方法需要在提示前面附加一些示例提示和完成對,以便LLM學習如何為新的不可見提示生成響應。雖然與其他自定義技術相比,少數鏡頭提示需要相對較少的數據量,并且不需要微調,但它確實增加了推理延遲。
思維鏈推理:就像人類將大問題分解成小問題并應用思維鏈來有效地解決問題一樣,思維鏈推理是一種快速的工程技術,可以幫助LLM提高他們在多步驟任務上的表現。它涉及將問題分解為更簡單的步驟,每個步驟都需要緩慢而深思熟慮的推理。這種方法適用于邏輯、算術和演繹推理任務。
系統提示:此方法涉及在用戶提示之外添加系統級提示,以向LLM提供特定和詳細的說明,使其按預期運行。可以將系統提示視為LLM的輸入以生成其響應。系統提示的質量和特異性會對LLM響應的相關性和準確性產生重大影響。
及時學習
快速學習是一種高效的自定義方法,可以在許多下游任務上使用預訓練的LLM,而無需調整預訓練模型的完整參數集。它包括兩種具有細微差異的變體,稱為 p 調諧和提示調諧;這兩種方法統稱為快速學習。
快速學習可以向LLM添加新任務,而不會覆蓋或中斷模型已經預先訓練的先前任務。由于原始模型參數被凍結且永遠不會更改,因此快速學習還可以避免微調模型時經常遇到的災難性遺忘問題。當LLM在微調過程中以LLM預培訓期間獲得的基礎知識為代價學習新行為時,就會發生災難性的遺忘。
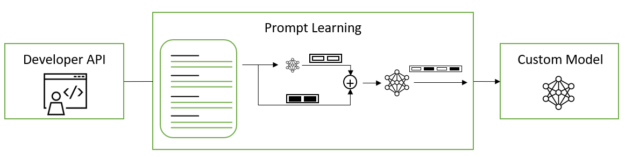
圖2.應用于法學碩士的快速學習
提示調優和 p 調諧不是以手動或自動方式選擇離散文本提示,而是使用可通過梯度下降進行優化的虛擬提示嵌入。這些虛擬令牌嵌入與構成模型詞匯表的離散、硬令牌或真實令牌相反。虛擬代幣是純粹的一維向量,其維數等于每個真實代幣嵌入的維數。在訓練和推理中,根據模型配置中提供的模板,在離散令牌嵌入中插入連續令牌嵌入。
提示調整:對于預訓練的 LLM,軟提示嵌入初始化為大小total_virtual_tokens?Xhidden_size的 2D 矩陣。提示優化模型以執行的每個任務都有其自己的關聯 2D 嵌入矩陣。任務在訓練或推理期間不共享任何參數。NeMo 框架提示調優實現基于參數高效提示調優的規模力量。
P-調諧:?稱為 LSTM 或 MLP 模型用于預測虛擬令牌嵌入。 參數在 p 調優開始時隨機初始化。所有基本LLM參數都被凍結,并且在每個訓練步驟中僅更新權重。p 調優完成后,提示調優的虛擬令牌將自動移動到存儲所有提示調優和 p 調優軟提示的位置。 然后從模型中移除。這使您能夠保留以前 p 調優的軟提示,同時仍保持將來添加新的 p 調優或提示調優軟提示的能力。prompt_encoderprompt_encoderprompt_encoderprompt_encoderprompt_tableprompt_encoder
prompt_table使用任務名稱作為鍵來查找指定任務的正確虛擬令牌。NeMo框架p調諧實現基于GPT Understands,Too。
參數高效微調
參數高效微調(PEFT)技術使用巧妙的優化來有選擇地向原始LLM架構添加和更新一些參數或層。使用 PEFT,針對特定用例訓練模型參數。預訓練的LLM權重保持凍結,并且在PEFT期間使用域和任務特定的數據集更新的參數明顯較少。這使LLM能夠在訓練的任務上達到高精度。
有幾種流行的參數高效替代方法來微調預訓練語言模型。與提示學習不同,這些方法不會在輸入中插入虛擬提示。相反,他們將可訓練層引入變壓器架構中,用于特定任務的學習。這有助于在下游任務上獲得強大的性能,同時與微調相比,可訓練參數的數量減少了幾個數量級(參數減少了近 10,000 倍)。
- 適配器學習
- 通過抑制和放大內部激活(IA3)注入適配器
- 低秩適應 (LoRA)
適配器學習:在核心變壓器架構各層之間引入小的前饋層。只有這些層(適配器)在微調時針對特定的下游任務進行訓練。適配器層通常使用下投影將輸入

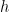
投影到低維空間,然后使用非線性激活函數,并使用

?
?
.殘差連接將此輸出添加到輸入中,從而形成最終形式:
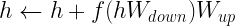
?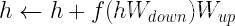
?
適配器模塊通常被初始化為適配器的初始輸出始終為零,以防止由于添加此類模塊而導致原始模型的性能下降。NeMo 框架適配器實現基于 NLP 的參數高效遷移學習。
IA3:與適配器相比,添加的參數更少,適配器只是使用學習向量縮放轉換器層中的隱藏表示。可以為特定的下游任務訓練這些擴展參數。學習的向量 、 和 分別重新縮放注意力機制中的鍵和值以及位置前饋網絡中的內部激活。這種技術還使混合任務批處理成為可能,因為批處理中的每個激活序列都可以單獨且廉價地乘以其關聯的學習任務向量。NeMo框架IA3 實現基于少鏡頭參數高效微調比上下文學習更好、更便宜。lklvlff

圖3.用于參數高效微調的 LoRA
洛拉:將可訓練的低秩矩陣注入變壓器層以近似權重更新。LoRA 沒有更新完整的預訓練權重矩陣 W,而是更新其低秩分解,與微調相比,可訓練參數的數量減少了 10,000 倍,GPU 內存需求減少了 3 倍。此更新將應用于多頭注意力子圖層中的查詢和值投影權重矩陣。事實證明,將更新應用于低秩分解而不是整個矩陣在模型質量上與微調相當或更好,從而實現更高的訓練吞吐量,并且沒有額外的推理延遲。
NeMo框架LoRA實現基于大型語言模型的低秩適配。有關如何將 LoRa 模型應用于抽取式 QA 任務的詳細信息,請參閱 LoRA 教程筆記本。
微調
當數據和計算資源沒有硬約束時,監督微調 (SFT) 和人工反饋強化學習 (RLHF) 等定制技術是 PEFT 和提示工程的絕佳替代方法。與其他自定義方法相比,微調有助于在一系列用例上實現最佳準確性。
有監督的微調:?SFT是在輸入和輸出的標記數據上微調模型所有參數的過程,它教授模型域特定的術語以及如何遵循用戶指定的指令。它通常在模型預訓練后完成。與預訓練階段相比,使用預訓練模型可以實現許多好處,包括使用最先進的模型而無需從頭開始訓練、降低計算成本并減少數據收集需求。SFT的一種形式被稱為指令調優,因為它涉及在通過指令描述的數據集集合上微調語言模型。
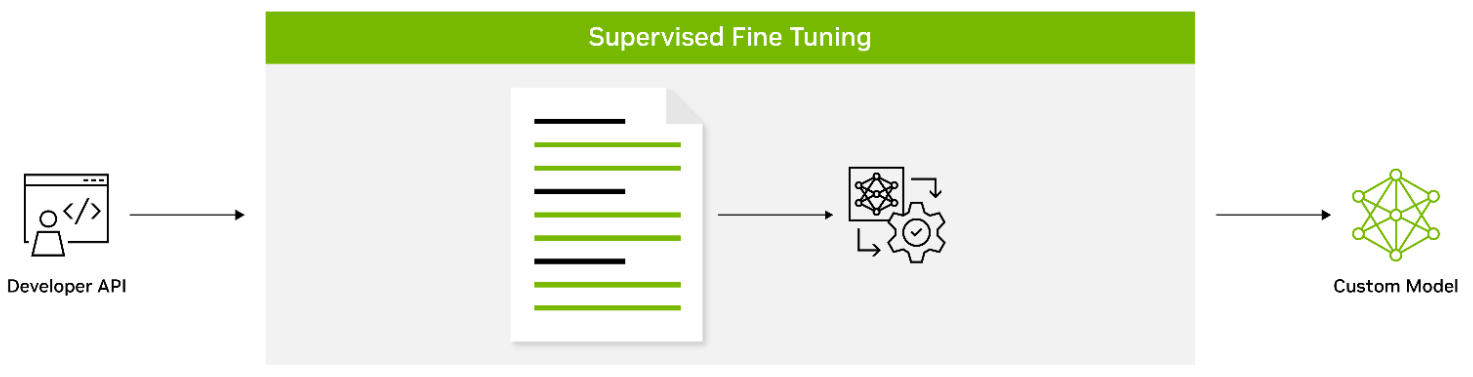
圖4.通過跟蹤數據的標記指令進行監督微調
帶有指令的SFT利用了NLP任務可以通過自然語言指令描述的直覺,例如“將以下文章總結為三句話”或“用西班牙語寫一封關于即將到來的學校節日的電子郵件”。該方法成功地結合了微調和提示范式的優勢,以提高推理時的LLM零鏡頭性能。
指令調優過程涉及對預訓練模型執行微調,這些數據集由以不同比例混合的自然語言指令表達的多個 NLP 數據集的混合物。在推理時,對看不見的任務進行評估,并且已知此過程可以顯著提高看不見任務的零鏡頭性能。SFT也是使用強化學習提高LLM能力過程中的重要中間步驟,我們將在下面描述。
帶有人類反饋的強化學習:?帶有人類反饋的強化學習(RLHF)是一種定制技術,使LLM能夠更好地與人類價值觀和偏好保持一致。它使用強化學習使模型能夠根據收到的反饋調整其行為。它涉及一個三階段微調過程,該過程使用人類偏好作為損失函數。使用前面部分中描述的說明進行微調的SFT模型被認為是RLHF技術的第一階段。
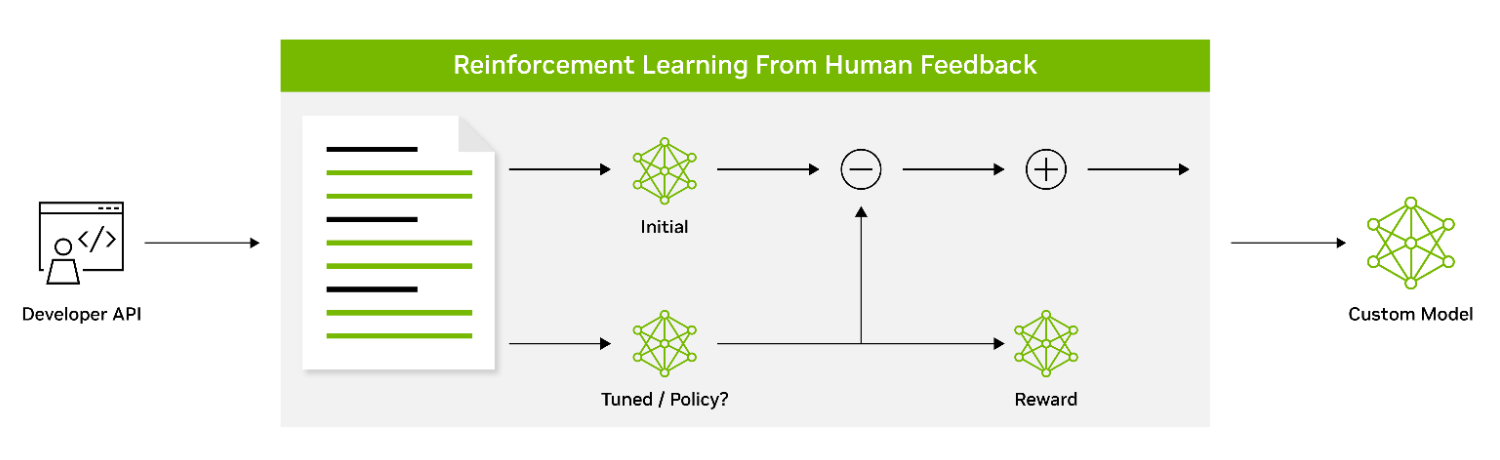
圖5.使用強化學習使LLM行為與人類偏好保持一致
SFT 模型在 RLHF 的第 2 階段被訓練為獎勵模型 (RM)。由具有多個響應的提示組成的數據集用于訓練 RM 以預測人類偏好。
訓練 RM 后,RLHF 的第 3 階段側重于使用近端策略優化 (PPO) 算法的強化學習針對 RM 微調初始策略模型。RLHF的這三個階段迭代執行,使LLM能夠生成更符合人類偏好的輸出,并且可以更有效地遵循指令。
雖然 RLHF 會產生強大的 LLM,但缺點是這種方法可能會被濫用和利用來生成不良或有害的內容。NeMo方法使用PPO價值網絡作為批評者模型,以指導LLM遠離生成有害內容。研究界正在積極探索其他方法,以引導LLMs采取適當的行為,并減少LLM構成事實的有毒物質產生或幻覺。
原文鏈接:選擇大型語言模型自定義技術 (mvrlink.com)



用法)















