1.概述
圖像分類是根據圖像的語義信息對不同類別圖像進行區分,是計算機視覺的核心,是物體檢測、圖像分割、物體跟蹤、行為分析、人臉識別等其他高層次視覺任務的基礎。圖像分類在許多領域都有著廣泛的應用,如:安防領域的人臉識別和智能視頻分析等,交通領域的交通場景識別,互聯網領域基于內容的圖像檢索和相冊自動歸類,醫學領域的圖像識別等。
這里對圖像分類領域的經典卷積神經網絡進行剖析,介紹如何應用這些基礎模塊構建卷積神經網絡,解決圖像分類問題。按照被提出的時間順序,涵蓋如下卷積神經網絡:
-
LeNet:Yan LeCun等人于1998年第一次將卷積神經網絡應用到圖像分類任務上[1],在手寫數字識別任務上取得了巨大成功。
-
AlexNet:Alex Krizhevsky等人在2012年提出了AlexNet[2], 并應用在大尺寸圖片數據集ImageNet上,獲得了2012年ImageNet比賽冠軍(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)。
-
VGG:Simonyan和Zisserman于2014年提出了VGG網絡結構[3],是當前最流行的卷積神經網絡之一,由于其結構簡單、應用性極強而深受廣大研究者歡迎。
-
GoogLeNet:Christian Szegedy等人在2014提出了GoogLeNet[4],并取得了2014年ImageNet比賽冠軍。
-
ResNet:Kaiming He等人在2015年提出了ResNet[5],通過引入殘差模塊加深網絡層數,在ImagNet數據集上的錯誤率降低到3.6%,超越了人眼識別水平。ResNet的設計思想深刻地影響了后來的深度神經網絡的設計。
圖像分類處理基本流程,先使用卷積神經網絡提取圖像特征,然后再用這些特征預測分類概率,根據訓練樣本標簽建立起分類損失函數,開啟端到端的訓練,如下圖所示。
 ???????
???????
2.LeNet卷積神經網絡
LeNet是最早的卷積神經網絡之一。1998年,Yann LeCun第一次將LeNet卷積神經網絡應用到圖像分類上,在手寫數字識別任務中取得了巨大成功。LeNet通過連續使用卷積和池化層的組合提取圖像特征,其架構如圖1所示,這里展示的是用于MNIST手寫體數字識別任務中的LeNet-5模型:

- 第一模塊:包含5×5的6通道卷積和2×2的池化。卷積提取圖像中包含的特征模式(激活函數使用Sigmoid),圖像尺寸從28減小到24。經過池化層可以降低輸出特征圖對空間位置的敏感性,圖像尺寸減到12。
- 第二模塊:和第一模塊尺寸相同,通道數由6增加為16。卷積操作使圖像尺寸減小到8,經過池化后變成4。
- 第三模塊:包含4×4的120通道卷積。卷積之后的圖像尺寸減小到1,但是通道數增加為120。將經過第3次卷積提取到的特征圖輸入到全連接層。第一個全連接層的輸出神經元的個數是64,第二個全連接層的輸出神經元個數是分類標簽的類別數,對于手寫數字識別的類別數是10。然后使用Softmax激活函數即可計算出每個類別的預測概率。
卷積層的輸出特征圖如何當作全連接層的輸入使用呢?
卷積層的輸出數據格式是[N,C,H,W],在輸入全連接層的時候,會自動將數據拉平,也就是對每個樣本,自動將其轉化為長度為K的向量,其中K=C×H×W,一個mini-batch的數據維度變成了N×K的二維向量。
3.AlexNet卷積神經網絡
自從1998年LeNet問世以來,接下來十幾年的時間里,神經網絡并沒有在計算機視覺領域取得很好的結果,反而一度被其它算法所超越。原因主要有兩方面,一是神經網絡的計算比較復雜,對當時計算機的算力來說,訓練神經網絡是件非常耗時的事情;另一方面,當時還沒有專門針對神經網絡做算法和訓練技巧的優化,神經網絡的收斂是件非常困難的事情。
隨著技術的進步和發展,計算機的算力越來越強大,尤其是在GPU并行計算能力的推動下,復雜神經網絡的計算也變得更加容易實施。另一方面,互聯網上涌現出越來越多的數據,極大的豐富了數據庫。同時也有越來越多的研究人員開始專門針對神經網絡做算法和模型的優化,Alex Krizhevsky等人提出的AlexNet以很大優勢獲得了2012年ImageNet比賽的冠軍。
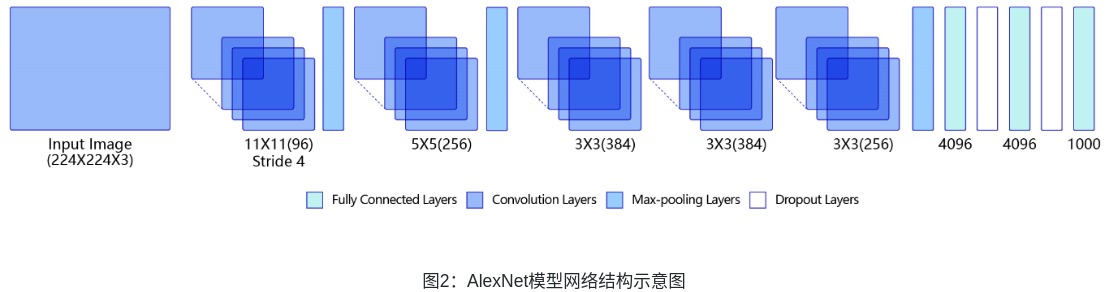
AlexNet與LeNet相比,具有更深的網絡結構,包含5層卷積和3層全連接,同時使用了如下三種方法改進模型的訓練過程:
-
數據增廣:深度學習中常用的一種處理方式,通過對訓練隨機加一些變化,比如平移、縮放、裁剪、旋轉、翻轉或者增減亮度等,產生一系列跟原始圖片相似但又不完全相同的樣本,從而擴大訓練數據集。通過這種方式,可以隨機改變訓練樣本,避免模型過度依賴于某些屬性,能從一定程度上抑制過擬合。
-
使用Dropout抑制過擬合。
-
使用ReLU激活函數減少梯度消失現象。
?4.VGG卷積神經網絡
VGG是當前最流行的CNN模型之一,2014年由Simonyan和Zisserman提出,其命名來源于論文作者所在的實驗室Visual Geometry Group。AlexNet模型通過構造多層網絡,取得了較好的效果,但是并沒有給出深度神經網絡設計的方向。VGG通過使用一系列大小為3x3的小尺寸卷積核和池化層構造深度卷積神經網絡,并取得了較好的效果。VGG模型因為結構簡單、應用性極強而廣受研究者歡迎,尤其是它的網絡結構設計方法,為構建深度神經網絡提供了方向。
圖3是VGG-16的網絡結構示意圖,有13層卷積和3層全連接層。VGG網絡的設計嚴格使用3×3的卷積層和池化層來提取特征,并在網絡的最后面使用三層全連接層,將最后一層全連接層的輸出作為分類的預測。 在VGG中每層卷積將使用ReLU作為激活函數,在全連接層之后添加dropout來抑制過擬合。使用小的卷積核能夠有效地減少參數的個數,使得訓練和測試變得更加有效。比如使用兩層3×3卷積層,可以得到感受野為5的特征圖,而比使用5×5的卷積層需要更少的參數。由于卷積核比較小,可以堆疊更多的卷積層,加深網絡的深度,這對于圖像分類任務來說是有利的。VGG模型的成功證明了增加網絡的深度,可以更好的學習圖像中的特征模式。

?5.GoogLeNet卷積神經網絡
GoogLeNet是2014年ImageNet比賽的冠軍,它的主要特點是網絡不僅有深度,還在橫向上具有“寬度”。由于圖像信息在空間尺寸上的巨大差異,如何選擇合適的卷積核來提取特征就顯得比較困難了。空間分布范圍更廣的圖像信息適合用較大的卷積核來提取其特征;而空間分布范圍較小的圖像信息則適合用較小的卷積核來提取其特征。為了解決這個問題,GoogLeNet提出了一種被稱為Inception模塊的方案,如圖4所示。
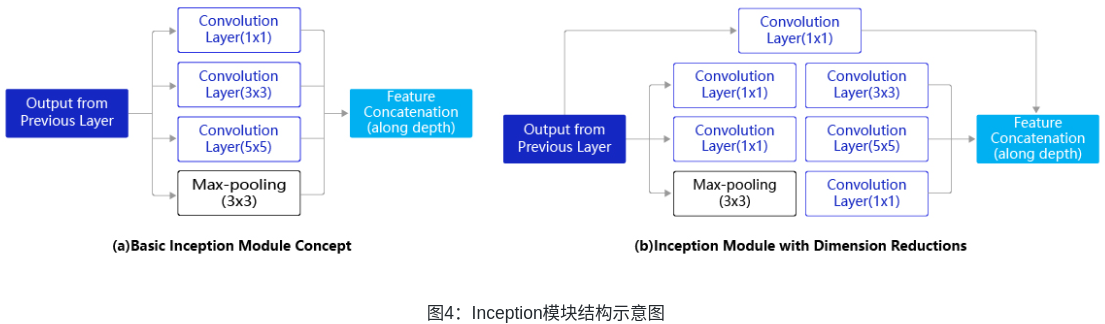
?圖4(a)是Inception模塊的設計思想,使用3個不同大小的卷積核對輸入圖片進行卷積操作,并附加最大池化,將這4個操作的輸出沿著通道這一維度進行拼接,構成的輸出特征圖將會包含經過不同大小的卷積核提取出來的特征,從而達到捕捉不同尺度信息的效果。Inception模塊采用多通路(multi-path)的設計形式,每個支路使用不同大小的卷積核,最終輸出特征圖的通道數是每個支路輸出通道數的總和,這將會導致輸出通道數變得很大,尤其是使用多個Inception模塊串聯操作的時候,模型參數量會變得非常大。為了減小參數量,Inception模塊使用了圖(b)中的設計方式,在每個3x3和5x5的卷積層之前,增加1x1的卷積層來控制輸出通道數;在最大池化層后面增加1x1卷積層減小輸出通道數。基于這一設計思想,形成了上圖(b)中所示的結構。
GoogLeNet的架構如圖5所示,在主體卷積部分中使用5個模塊(block),每個模塊之間使用步幅為2的3 ×3最大池化層來減小輸出高寬。
- 第一模塊使用一個64通道的7 × 7卷積層。
- 第二模塊使用2個卷積層:首先是64通道的1 × 1卷積層,然后是將通道增大3倍的3 × 3卷積層。
- 第三模塊串聯2個完整的Inception塊。
- 第四模塊串聯了5個Inception塊。
- 第五模塊串聯了2 個Inception塊。
- 第五模塊的后面緊跟輸出層,使用全局平均池化層來將每個通道的高和寬變成1,最后接上一個輸出個數為標簽類別數的全連接層。
說明: 在原作者的論文中添加了圖中所示的softmax1和softmax2兩個輔助分類器,如下圖所示,訓練時將三個分類器的損失函數進行加權求和,以緩解梯度消失現象。這里的程序作了簡化,沒有加入輔助分類器。

?圖5:GoogLeNet模型網絡結構示意圖
6.ResNet卷積神經網絡
ResNet是2015年ImageNet比賽的冠軍,將識別錯誤率降低到了3.6%,這個結果甚至超出了正常人眼識別的精度。
通過前面幾個經典模型學習,我們可以發現隨著深度學習的不斷發展,模型的層數越來越多,網絡結構也越來越復雜。那么是否加深網絡結構,就一定會得到更好的效果呢?從理論上來說,假設新增加的層都是恒等映射,只要原有的層學出跟原模型一樣的參數,那么深模型結構就能達到原模型結構的效果。換句話說,原模型的解只是新模型的解的子空間,在新模型解的空間里應該能找到比原模型解對應的子空間更好的結果。但是實踐表明,增加網絡的層數之后,訓練誤差往往不降反升。
Kaiming He等人提出了殘差網絡ResNet來解決上述問題,其基本思想如圖6所示。
- 圖6(a):表示增加網絡的時候,將x映射成y = F(x)輸出。
- 圖6(b):對圖6(a)作了改進,輸出y = F(x)+x。這時不是直接學習輸出特征 y 的表示,而是學習y?x。
- 如果想學習出原模型的表示,只需將F(x)的參數全部設置為0,則y=x是恒等映射。
- F(x)=y?x也叫做殘差項,如果x→y的映射接近恒等映射,圖6(b)中通過學習殘差項也比圖6(a)學習完整映射形式更加容易。
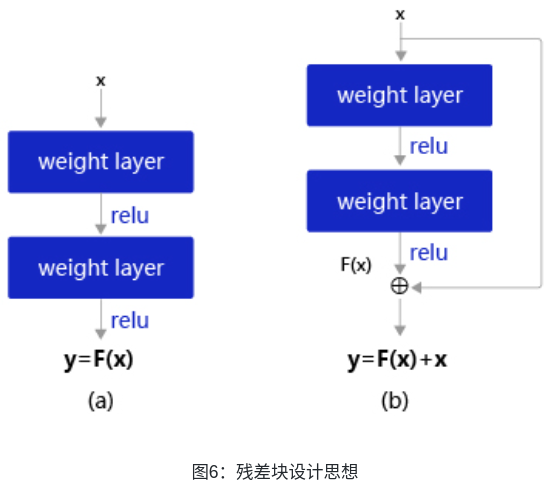
圖6(b)的結構是殘差網絡的基礎,這種結構也叫做殘差塊(Residual block)。輸入x通過跨層連接,能更快的向前傳播數據,或者向后傳播梯度。
通俗的比喻,如“傳聲筒”的游戲。我們常常會發現剛開始的嘉賓往往表演出最多的信息(類似于Loss),而隨著表演的傳遞,有效的表演信息越來越少(類似于梯度彌散)。類似的,由于ResNet每層都存在直連的旁路,相當于每一層都和最終的損失有“直接對話”的機會,自然可以更好的解決梯度彌散的問題。
殘差塊的具體設計方案如圖7所示,這種設計方案也常稱作瓶頸結構(BottleNeck)。1*1的卷積核可以非常方便的調整中間層的通道數,在進入3*3的卷積層之前減少通道數(256->64),經過該卷積層后再恢復通道數(64->256),可以顯著減少網絡的參數量。這個結構(256->64->256)像一個中間細,兩頭粗的瓶頸,所以被稱為“BottleNeck”。
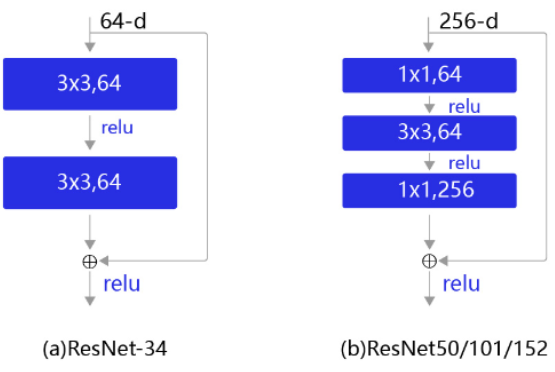
?圖7:殘差塊結構示意圖
下圖表示出了ResNet-50的結構,一共包含49層卷積和1層全連接,所以被稱為ResNet-50。
















)
--猿人學第十五題)


)