首發博客地址
https://blog.zysicyj.top/
Redis高可靠靠什么保證?
為什么要提這個呢,因為Redis主從庫目的呢其實就是為了實現高可靠。上篇文章中我們說過Redis的AOF、RDB日志其實就是為了減少數據丟失,這是高可靠的一部分。
這篇文章呢,我們聊聊Redis實現高可靠的另一方面:盡量減少服務中斷。這里Redis是怎么做的呢?Redis的做法是增加副本冗余,將一份數據同時保存在多個實例上。這樣某個實例掛掉并不影響其它實例提供對外服務,保證我們的業務正常運行。
Redis有哪些手段提高高可用呢?
-
數據持久化:Redis 支持多種數據持久化方式,包括快照(snapshotting)和日志(append-only file)。快照會定期將內存中的數據保存到磁盤文件,而日志會記錄每次寫操作,以便在重啟時進行恢復。這些持久化方式可以確保即使服務器意外關閉,數據也不會丟失。
-
主從復制:Redis 支持主從復制機制,其中一個 Redis 實例作為主節點,負責寫操作,而其他實例作為從節點,負責復制主節點的數據。這種方式可以實現數據的備份和負載均衡,從而提高可靠性和性能。
-
Sentinel 哨兵:Redis Sentinel 是一個監控和自動故障恢復系統,可以監控 Redis 實例的健康狀態并在主節點故障時自動進行故障切換。它可以確保系統在主節點發生故障時能夠自動切換到備用的從節點,保證服務的連續性。
-
Cluster 集群:Redis Cluster 是一種分布式系統,將數據分布在多個節點上,以提高可用性和擴展性。每個節點都持有部分數據,并且可以容忍部分節點的故障。當節點發生故障時,集群可以自動重新分配數據,確保服務的可靠性和高可用性。
如何保證副本數據一致?
首先我們要知道,Redis提供了主從庫模式,以保證副本一致,主從庫之間采用的是讀寫分離的方式。
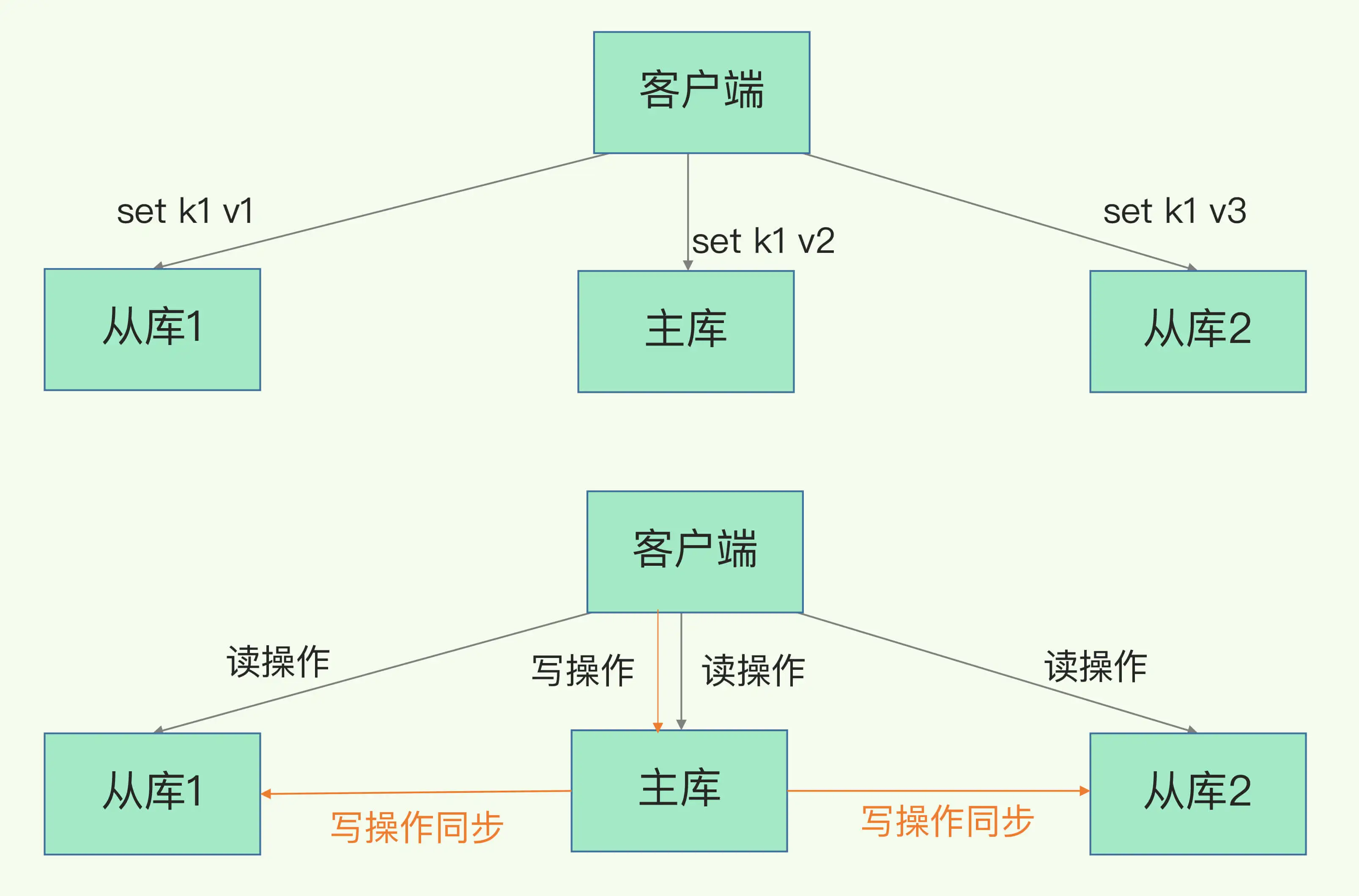
Redis中的讀寫分離基本原理和步驟
Redis 讀寫分離是一種架構設計,將讀操作和寫操作分別路由到不同的 Redis 節點上,以提高性能和擴展性。在 Redis 讀寫分離中,通常會有一個主節點負責寫操作,多個從節點負責讀操作。
-
主節點(寫節點):
-
主節點負責處理所有的寫操作,包括寫入、更新和刪除等。 -
寫操作在主節點上執行,然后主節點將寫操作的結果同步到所有從節點。
-
-
從節點(讀節點):
-
從節點負責處理讀操作,例如獲取數據、查詢等。 -
從節點從主節點復制數據,并在本地保存一份與主節點相同的數據副本。
-
-
讀寫分離的實現:
-
客戶端根據需要的操作類型將請求分發到主節點或從節點。 -
讀操作可以通過負載均衡策略,將請求分發到不同的從節點,實現負載分擔。 -
寫操作仍然發送給主節點,確保數據的一致性和完整性。
-
需要注意的是,Redis 讀寫分離并不是完全的數據實時同步,因為從節點的數據可能會有一定的延遲。另外,讀寫分離適用于大多數場景下的負載均衡和性能優化,但在一些特定情況下,例如有序集合等復雜數據結構的查詢,仍然需要訪問主節點。
實現 Redis 讀寫分離需要正確配置主從節點的關系,以及在客戶端中使用合適的策略進行讀寫操作的路由。同時,需要注意主節點和從節點之間的數據同步和故障處理,以確保系統的穩定性和可靠性。
Redis主從庫第一次同步是如何實現的?
-
建立連接: 從服務器會向主服務器發送
PSYNC命令,表示要進行同步。主服務器收到PSYNC命令后,會創建一個專門用于復制的后臺線程(replication thread),并等待從服務器的連接。 -
全量復制(第一次同步): 當從服務器連接到主服務器后,主服務器會將自己的數據發送給從服務器。這個過程叫做全量復制,主服務器會遍歷自己的數據集,將所有數據發送給從服務器。
-
主服務器會在一個 RDB 文件中保存當前數據集的快照,然后將這個 RDB 文件發送給從服務器。從服務器接收到 RDB 文件后,會加載這個文件,將自己的數據集替換成主服務器的數據集。
-
在 RDB 文件傳輸的過程中,主服務器會將在傳輸期間的寫操作記錄下來,稱為命令傳播(command propagation)。這樣一來,主服務器就能夠在發送完 RDB 文件后,將期間的寫操作重新發送給從服務器,以保證從服務器的數據集與主服務器保持一致。
-
-
增量復制: 在完成全量復制后,主從服務器之間會保持一個 TCP 連接,主服務器會將自己的寫操作發送給從服務器,從服務器執行這些寫操作,從而保持數據一致性。增量復制的數據同步是異步的,但通過記錄寫操作,主從服務器之間的數據最終會達到一致狀態。
需要注意的是,在第一次全量復制的過程中,可能會有一些網絡故障、主從服務器負載等情況影響同步。為了提高穩定性和安全性,Redis 提供了一些配置選項和機制,如持久化、復制偏移量、主服務器驗證等,來確保主從復制的正常進行。 
PSYNC命令
當 Redis 主從復制中的從服務器(Slave)需要與主服務器(Master)進行數據同步時,可以使用 PSYNC(Partial SYNC)命令。PSYNC 命令在 Redis 2.8 版本引入,用于提高數據同步的效率和可靠性。
PSYNC 命令包括兩種模式:完全同步(Full Sync)和部分同步(Partial Sync)。
-
完全同步(Full Sync): 完全同步在以下情況下發生:
-
從服務器初次連接主服務器時。 -
從服務器需要進行初次同步,或者復制偏移量與主服務器的偏移量差距較大時。 -
主服務器沒有保存 RDB 快照文件,所以無法進行部分同步。
完全同步的過程如下:
-
從服務器向主服務器發送一條 PSYNC 命令,并附帶上自己的復制積壓緩沖區的偏移量(offset)和 replid(復制 ID)。 -
主服務器使用 bgsave命令,生成RDB文件,接著將文件發給從庫。 -
從庫接收到RDB文件后,會先清空當前數據庫,然后加載RDB文件。
-
-
部分同步(Partial Sync): 部分同步在以下情況下發生:
-
從服務器已經復制了一部分數據,并且復制偏移量與主服務器的偏移量差距較小時。
部分同步的過程如下:
-
主庫將后續所有 寫操作記錄到內存中的replication buffer中 -
從服務器向主服務器發送一條 PSYNC 命令,并附帶上自己的復制積壓緩沖區的偏移量和 replid。 -
主庫將所有保存的寫操作發送給從庫,具體來說,就是當RDB發送完成后,就會把此時replication buffer中的修改發給從庫,從庫再重新執行這些操作。這樣一來,主從庫就實現同步了
-
PSYNC 命令的目標是在保證數據一致性的前提下,盡可能地減少數據同步所需的數據傳輸量,從而提高復制效率。完全同步和部分同步的選擇取決于從服務器與主服務器之間的復制狀態和數據差距。
主庫的煩惱
這里我們能分析得到主庫做全量同步時的兩個耗時操作:
-
生成RDB文件 -
傳輸RDB文件
這里設想一個場景,如果是一主多從的架構,那么主節點就要生成多份RDB并傳輸給從節點,很顯然,這種操作是非常耗時的。這里主要占用兩塊資源
-
通過fork子進程生成RDB快照會 阻塞主線程處理請求 -
傳輸RDB文件會占用 網絡帶寬
那么有什么方法可以解決這些問題呢? 這里呀,我們就引入了“主-從-從”架構,很容易理解,就是主庫只需要同步一份給某從庫A,其他從庫從從庫A同步數據。
如何理解 主-從-從 架構?
主從(Master-Slave)架構是一種常見的數據庫復制和數據備份方案。在這種架構中,存在一個主數據庫(主服務器)和一個或多個從數據庫(從服務器),主數據庫負責處理寫操作和讀操作,從數據庫負責復制主數據庫的數據,以提供讀取操作和備份。
主從架構的工作方式如下:
-
主數據庫(主服務器):
-
主數據庫是系統的主要數據庫,負責處理所有的寫操作(數據的插入、更新、刪除)和部分讀操作。 -
當主數據庫接收到寫操作時,會將這些寫操作記錄到自己的日志文件(例如 MySQL 的二進制日志)中,并發送給從數據庫。 -
主數據庫也會保存一個復制積壓緩沖區(replication backlog buffer),其中存儲了一部分的寫操作數據,用于滿足部分同步和斷線重連的需求。
-
-
從數據庫(從服務器):
-
從數據庫是主數據庫的復制副本,負責從主數據庫復制數據以供讀取操作和備份。 -
從數據庫會連接到主數據庫,并發送復制請求(如 PSYNC 命令)以獲取主數據庫的數據更新。 -
從數據庫會持續地復制主數據庫的寫操作,將寫操作應用到自己的數據副本中,以保持與主數據庫的數據一致性。 -
從數據庫可以處理讀取請求,從而減輕主數據庫的讀取壓力。
-
主從架構的優勢:
-
負載均衡: 通過將讀操作分發給從數據庫,可以分擔主數據庫的讀取壓力,提高整體系統的吞吐量。 -
高可用性: 當主數據庫出現故障時,可以將其中一個從數據庫提升為新的主數據庫,從而實現快速故障切換。 -
數據備份: 從數據庫可以作為主數據庫的數據備份,用于恢復數據和災難恢復。 -
數據分析: 從數據庫可以用于讀取操作,以進行數據分析、報表生成等工作,而不影響主數據庫的性能。
需要注意的是,主從架構并不是完全實時的,因為從數據庫需要時間來同步主數據庫的數據更新。因此,在考慮使用主從架構時,需要權衡數據一致性和性能之間的需求。 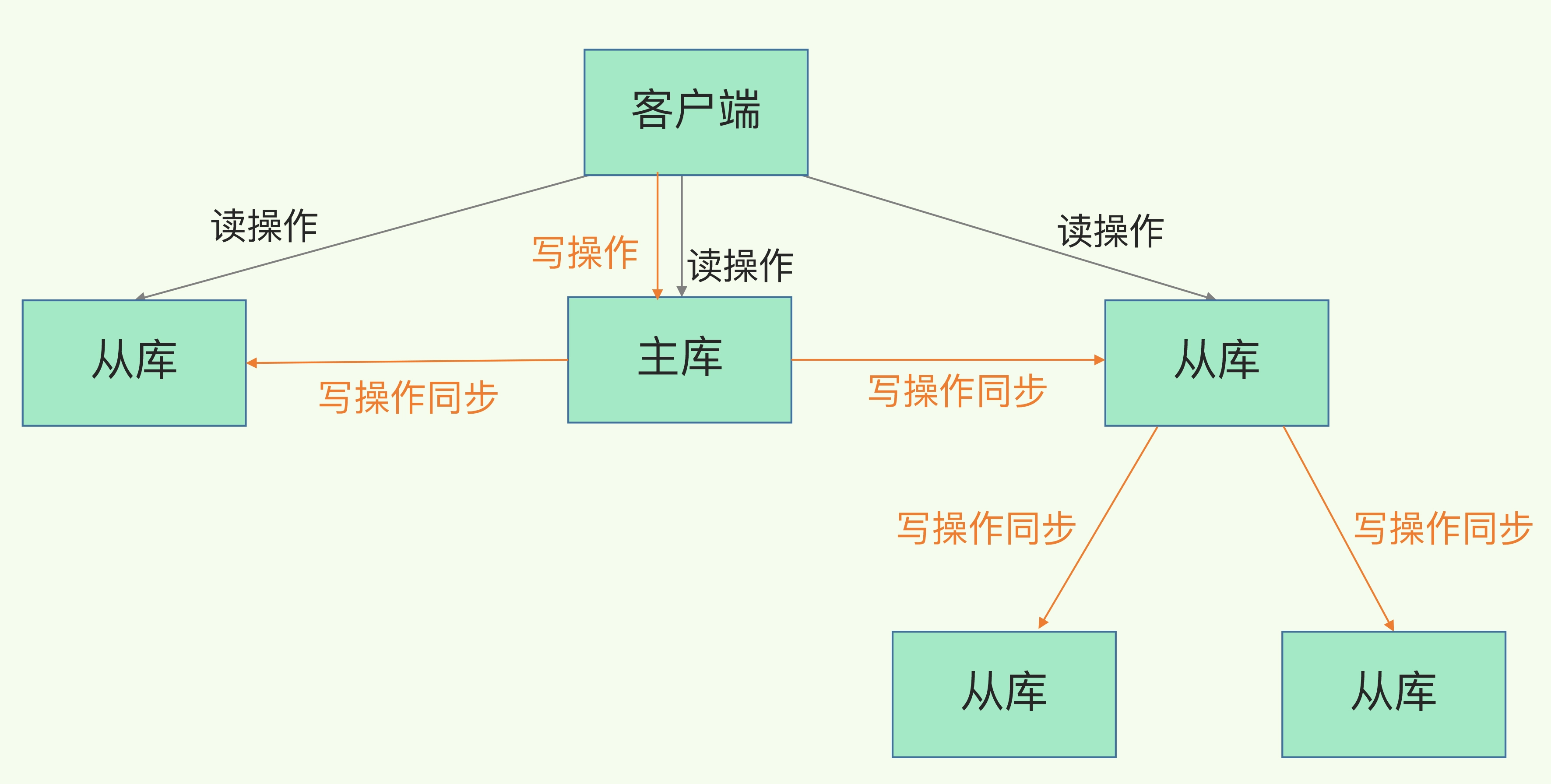
如何配置主從從架構呢
-
安裝和配置主服務器(Master):
-
安裝Redis主服務器并確保主服務器正常運行。 -
在主服務器的配置文件(redis.conf)中開啟持久化(通常使用RDB快照或AOF日志)和監聽端口,確保配置項如下: port?6379
save?900?1
appendonly?yes??#?如果使用AOF日志 -
如果需要對外提供訪問,確保防火墻或網絡設置允許訪問主服務器的6379端口。
-
-
安裝和配置第一個從服務器(Slave1):
-
在從服務器1上安裝Redis數據庫。 -
在從服務器1的配置文件中配置主從關系。在配置文件中添加類似如下的內容,其中 masterauth是主服務器的密碼,master是主服務器的IP和端口:slaveof?master_ip?master_port
masterauth?your_master_password -
重啟從服務器1使配置生效。
-
-
安裝和配置第二個從服務器(Slave2):
-
在從服務器2上安裝Redis數據庫。 -
在從服務器2的配置文件中配置主從關系,與從服務器1相似。確保配置項不沖突。 -
重啟從服務器2使配置生效。
-
-
重啟主服務器:
-
在主服務器上查看主服務器的信息,如IP和端口。通常使用以下命令: INFO?server
-
-
測試主從從架構:
-
在主服務器上進行寫操作,如插入、更新或刪除數據。 -
查看從服務器1和從服務器2是否同步了主服務器的數據。
-
需要注意的是,Redis的主從從架構在部署和配置上與主從架構類似,只是需要在從服務器上再次配置主從關系。另外,Redis還可以配置更多高可用性的功能,如哨兵(Sentinel)和集群(Cluster),以實現更強大的架構。具體配置細節可能會因版本和需求而有所不同,建議參考官方文檔或相關資源進行詳細了解和配置。
主從庫間網絡斷了怎么辦?
在 Redis 2.8 之前,如果主從庫在命令傳播時出現了網絡閃斷,那么,從庫就會和主庫重新進行一次全量復制,開銷非常大。
2.8之后呢是支持增量同步的,那么Redis是怎么實現增量同步的呢? 當Redis主從庫之間的網絡斷開后,網絡恢復時從庫需要進行增量同步,以獲取在網絡斷開期間主庫中的更新數據。Redis實現增量同步的方式是通過Redis復制機制,具體流程如下:
-
保存主服務器的數據: 主服務器會將更新的數據寫入內存,并在內存中保存一份副本。同時,主服務器會將更新的數據寫入AOF(Append-Only File)日志文件,以便在斷電或宕機情況下能夠進行數據恢復。
-
記錄復制偏移量: 在主服務器的復制過程中,主服務器會記錄一個復制偏移量(replication offset),表示從服務器在主服務器中的數據位置。這個偏移量會隨著數據的更新而遞增。
-
網絡恢復: 當網絡恢復時,從服務器會嘗試連接主服務器并請求進行復制。
-
發送SYNC命令: 從服務器會發送SYNC命令給主服務器。如果是初次連接復制,從服務器發送的SYNC命令中不包含任何參數。如果是增量同步,從服務器會發送帶有偏移量參數的SYNC命令。
-
全量復制或部分復制: 根據情況,主服務器會執行全量復制或部分復制:
-
全量復制(初次連接): 如果是初次連接復制,主服務器會執行全量復制。它會創建一個RDB快照(數據庫快照),將數據庫中的數據快照發送給從服務器。這樣從服務器就能夠擁有主服務器的完整數據集。 -
部分復制(增量同步): 如果是增量同步,主服務器會從記錄的偏移量處開始,將從偏移量后的所有更新數據發送給從服務器。這樣從服務器就能夠獲取在斷開網絡期間主服務器的更新數據。
-
-
復制數據傳輸: 主服務器會將全量數據或增量數據通過網絡傳輸給從服務器。從服務器會接收并處理這些數據,更新自己的數據集。
-
復制過程繼續: 一旦復制數據傳輸完成,從服務器會持續地與主服務器保持連接,接收來自主服務器的增量更新。這樣,主從庫之間的數據保持同步。
需要注意的是,當網絡斷開時間較長或斷開期間數據更新較大時,增量同步可能會導致從服務器落后于主服務器。在網絡恢復后,從服務器需要足夠的時間來接收和處理更新數據,以保持與主服務器的數據同步。 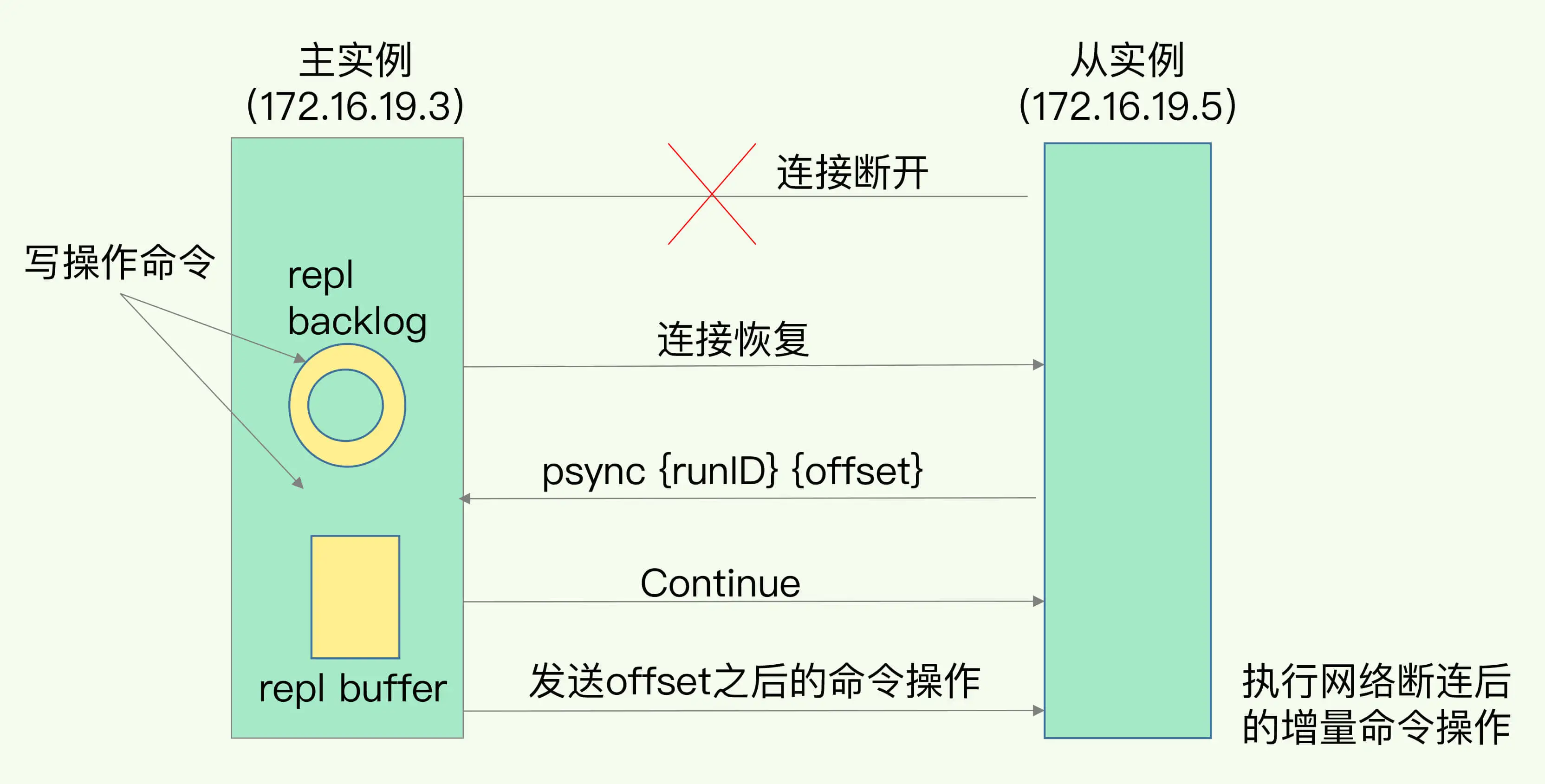
一般的排查流程
-
檢查網絡連接問題: 首先,確保網絡連接問題的確是造成主從庫通信中斷的原因。檢查網絡配置、防火墻規則、路由等設置,確保主從庫之間可以互相訪問。
-
重新連接網絡: 如果網絡問題是暫時的,你可以嘗試恢復網絡連接,讓主從庫之間恢復通信。
-
檢查主從狀態: 在主從庫網絡連接恢復后,使用
INFO replication命令檢查主從庫的同步狀態。確保主庫已將數據同步到從庫。 -
手動重新同步: 如果主從庫之間的網絡斷開時間較長,可以考慮進行手動重新同步:
-
在從庫上,使用 SLAVEOF NO ONE命令解除從庫狀態。 -
在從庫上,刪除持久化文件(RDB文件或AOF文件)。 -
在從庫上,執行 SLAVEOF master_ip master_port命令,將其重新設置為主庫的從庫。 -
在主庫上,執行 SLAVEOF NO ONE命令解除主庫狀態。 -
在主庫上,執行 SLAVEOF slave_ip slave_port命令,將其重新設置為從庫的主庫。
-
-
手動復制數據: 如果網絡斷開時間較長且重新同步不可行,你可能需要手動復制數據。在主庫上導出數據,并在從庫上導入數據。
-
備份和恢復: 如果網絡問題無法解決,你可能需要在網絡恢復后考慮從主庫重新備份數據,然后在從庫上進行數據恢復。
總結
文章中介紹了Redis主從庫架構以及如何配置、維護和解決主從庫網絡斷開的問題。以下是文章中涉及到的主要內容:
-
Redis主從庫架構及其保證的高可靠性:
-
Redis主從庫的目的是實現高可靠性,通過數據持久化、主從復制、Sentinel哨兵和Cluster集群等方式來保障數據的安全性和可用性。
-
-
如何保證副本數據一致:
-
Redis通過全量復制和部分復制(增量同步)來保證主從庫之間的數據一致性。復制偏移量和復制積壓緩沖區等機制用于記錄和傳輸數據。
-
-
主從庫第一次同步的過程:
-
主從庫之間的第一次同步涉及主服務器創建RDB快照,發送給從服務器,以及記錄期間的寫操作進行命令傳播。
-
-
PSYNC命令和增量同步:
-
PSYNC命令用于主從庫網絡斷開后的增量同步。完全同步用于初次連接,部分同步用于增量同步,從而減少數據傳輸量。
-
-
主從從架構及其優勢:
-
主從從架構是在主從架構基礎上的擴展,通過級聯的方式減輕主服務器的復制壓力,實現更高的可用性和負載均衡。
-
-
配置主從從架構的步驟:
-
安裝和配置主服務器,從服務器1和從服務器2。 -
重啟主服務器,查看主服務器信息。 -
進行測試,驗證主從庫之間是否同步。
-
-
解決主從庫間網絡斷開問題:
-
檢查網絡連接問題,確保主從庫之間可以互相訪問。 -
重新連接網絡,恢復通信。 -
檢查主從狀態,確保同步。 -
手動重新同步,嘗試恢復數據一致性。 -
手動復制數據或備份恢復數據。
-
本文由 mdnice 多平臺發布




)




)
)
)
)

)




