1 前言
🔥 優質競賽項目系列,今天要分享的是
🚩 python 爬蟲與協同過濾的新聞推薦系統
🥇學長這里給一個題目綜合評分(每項滿分5分)
- 難度系數:3分
- 工作量:3分
- 創新點:4分
該項目較為新穎,適合作為競賽課題方向,學長非常推薦!
🧿 更多資料, 項目分享:
https://gitee.com/dancheng-senior/postgraduate
1 課題背景
由于網絡信息科技的不斷進步和數據量的快速增長每天會產生巨大的信息量,使得互聯網上的數據信息越來越龐大、系統變得越來越臃腫,這些龐大的海量信息給用戶尋找自己感興趣的內容帶來了極大的困難,往往會導致用戶迷失在信息迷宮中,從而無法找到自己真正感興趣的內容。因此,高效快速的進行新聞推薦變得極其重要。
本項目使用前后端分離,前端是基于Vue設計的界面,后端基于python Django框架建立。
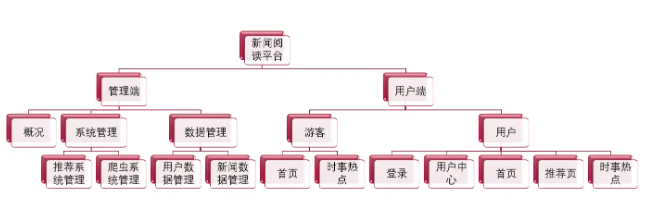
2 實現效果
整體軟件結構
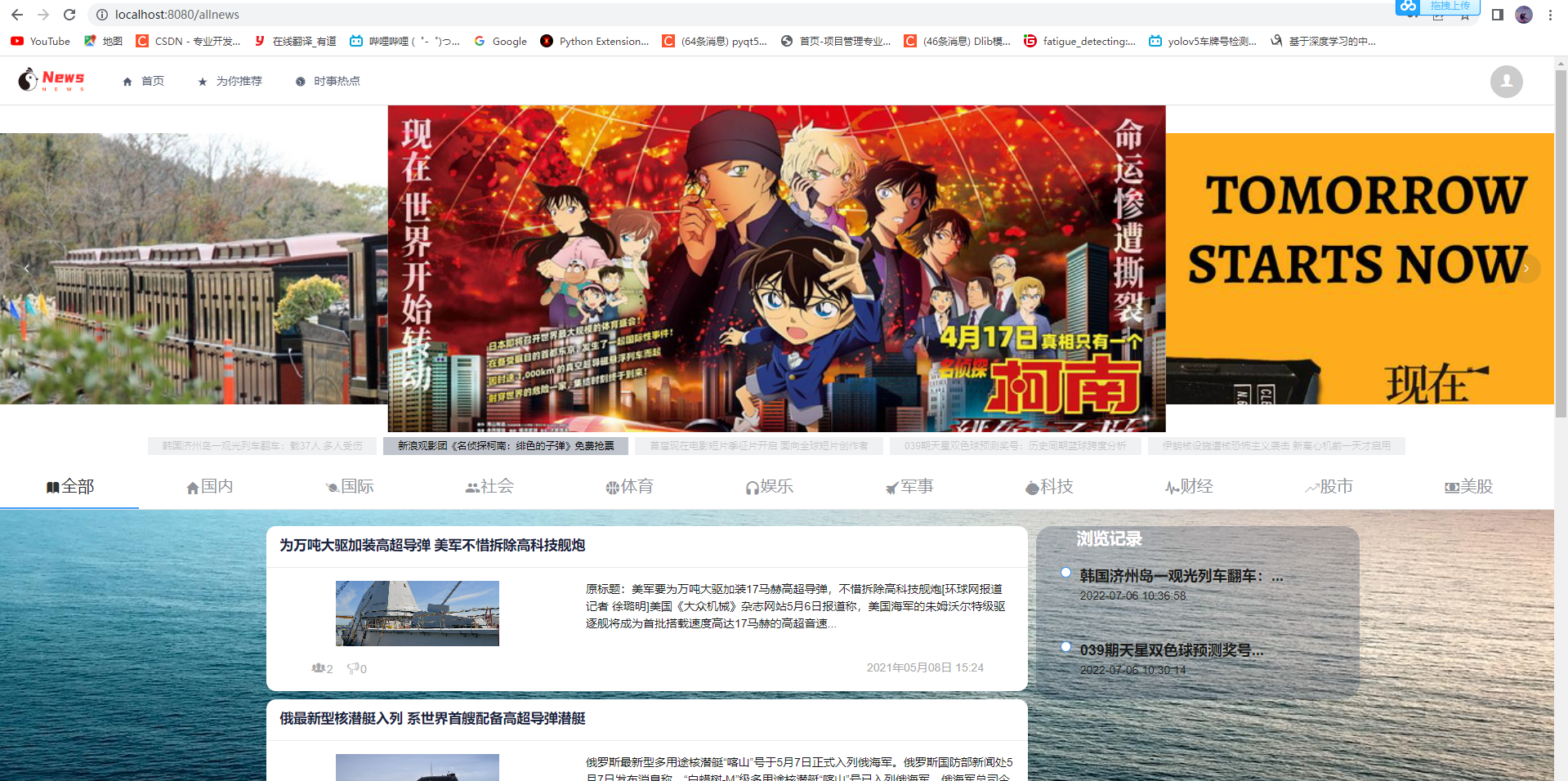
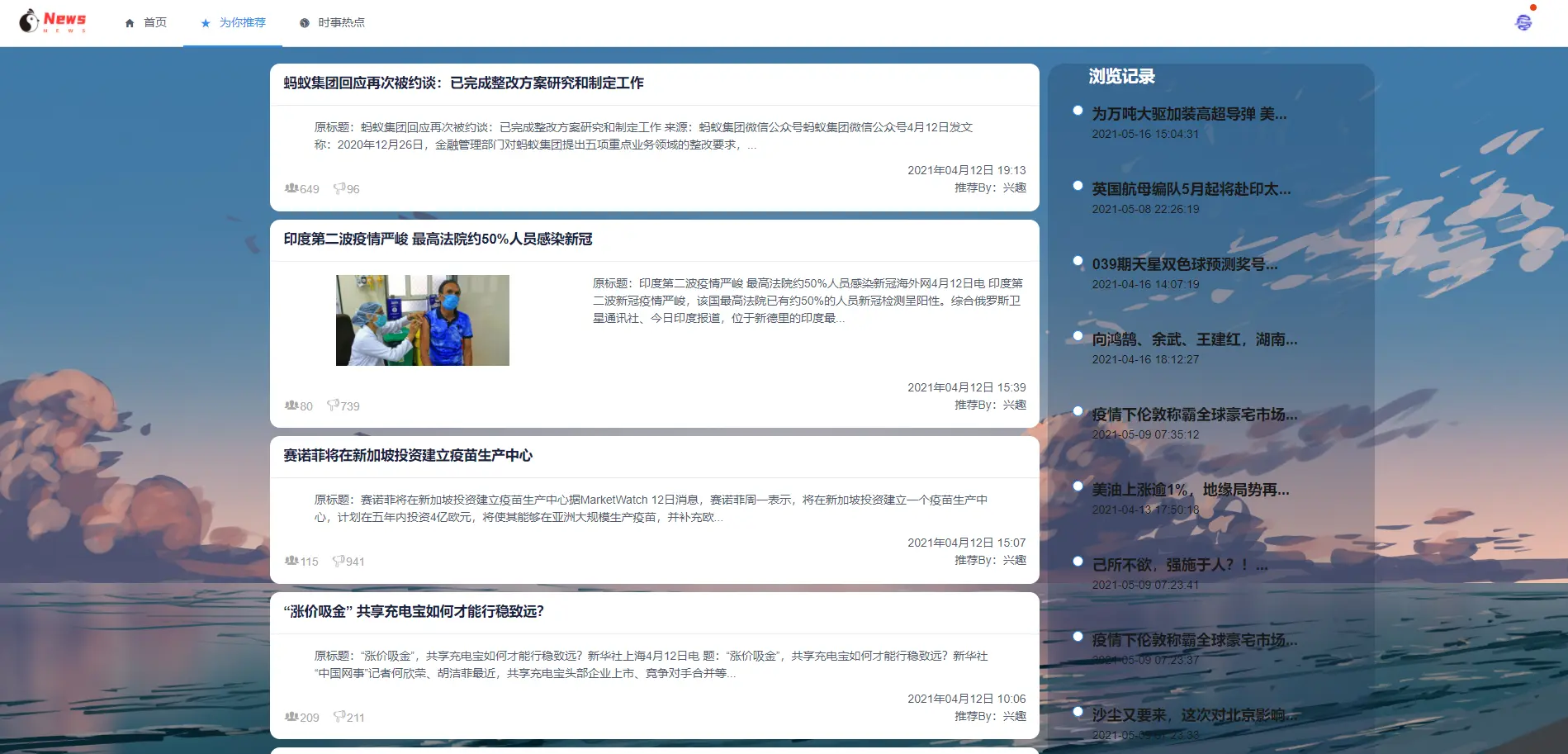
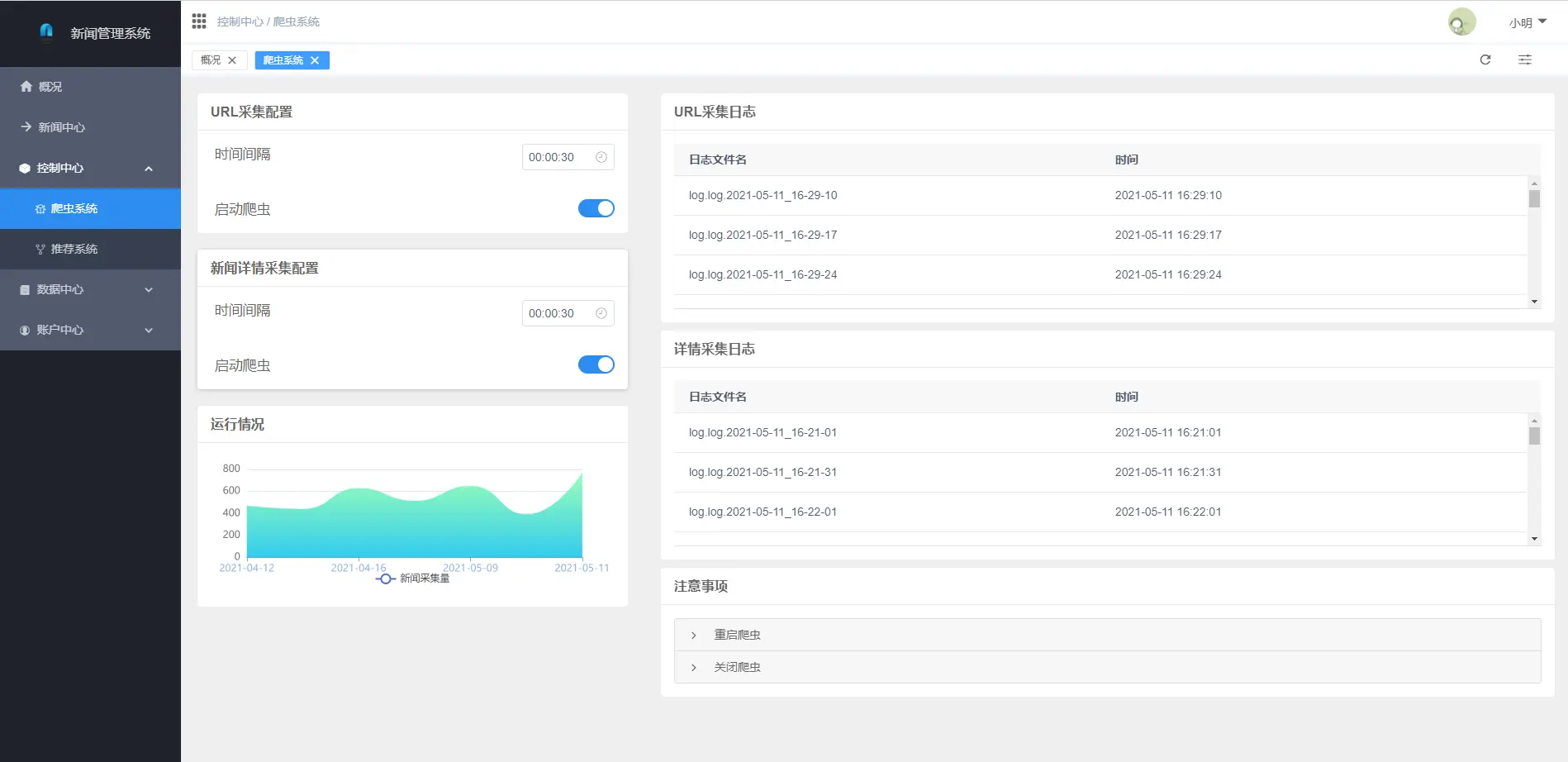
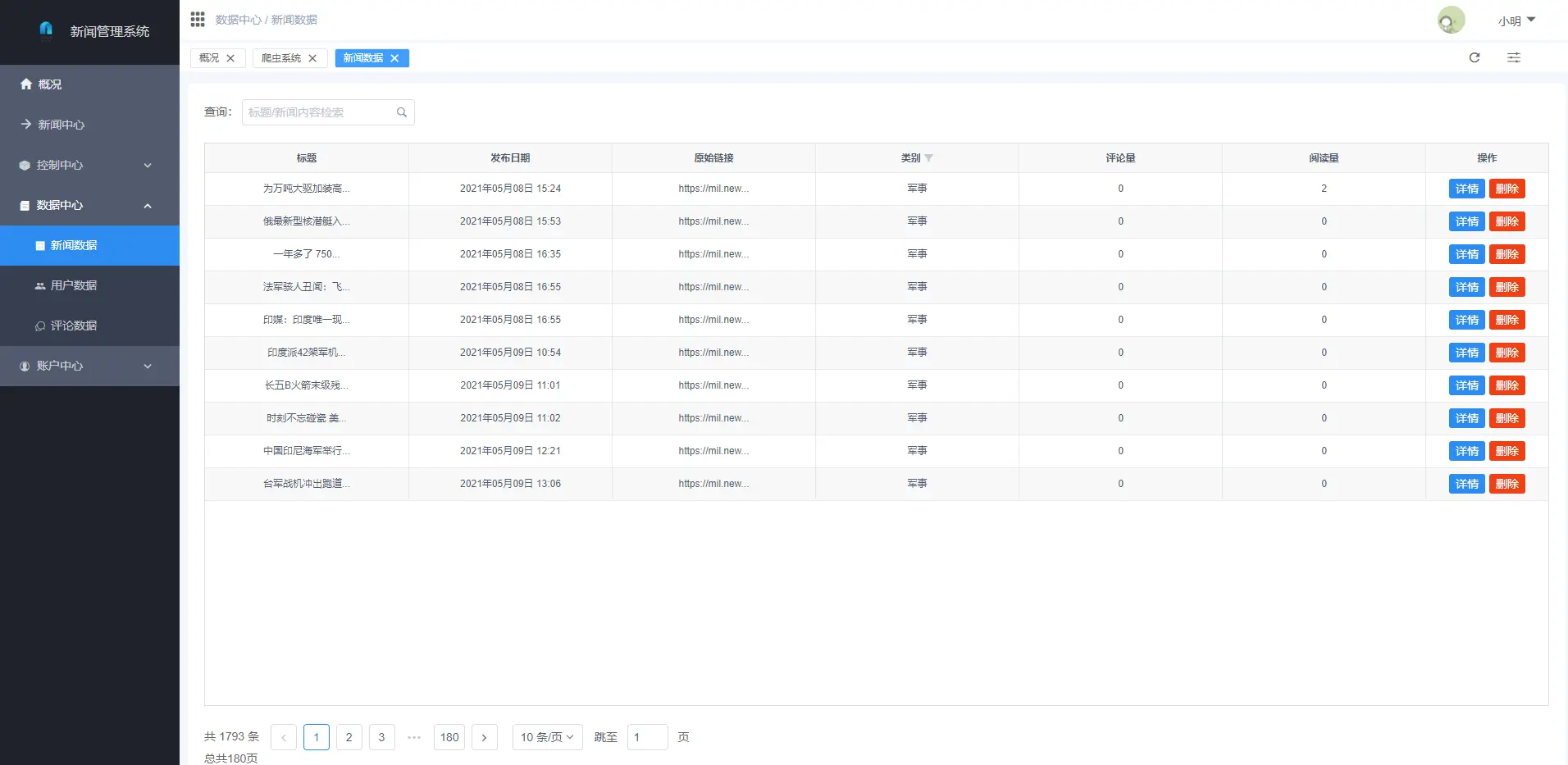
2.1 用戶端
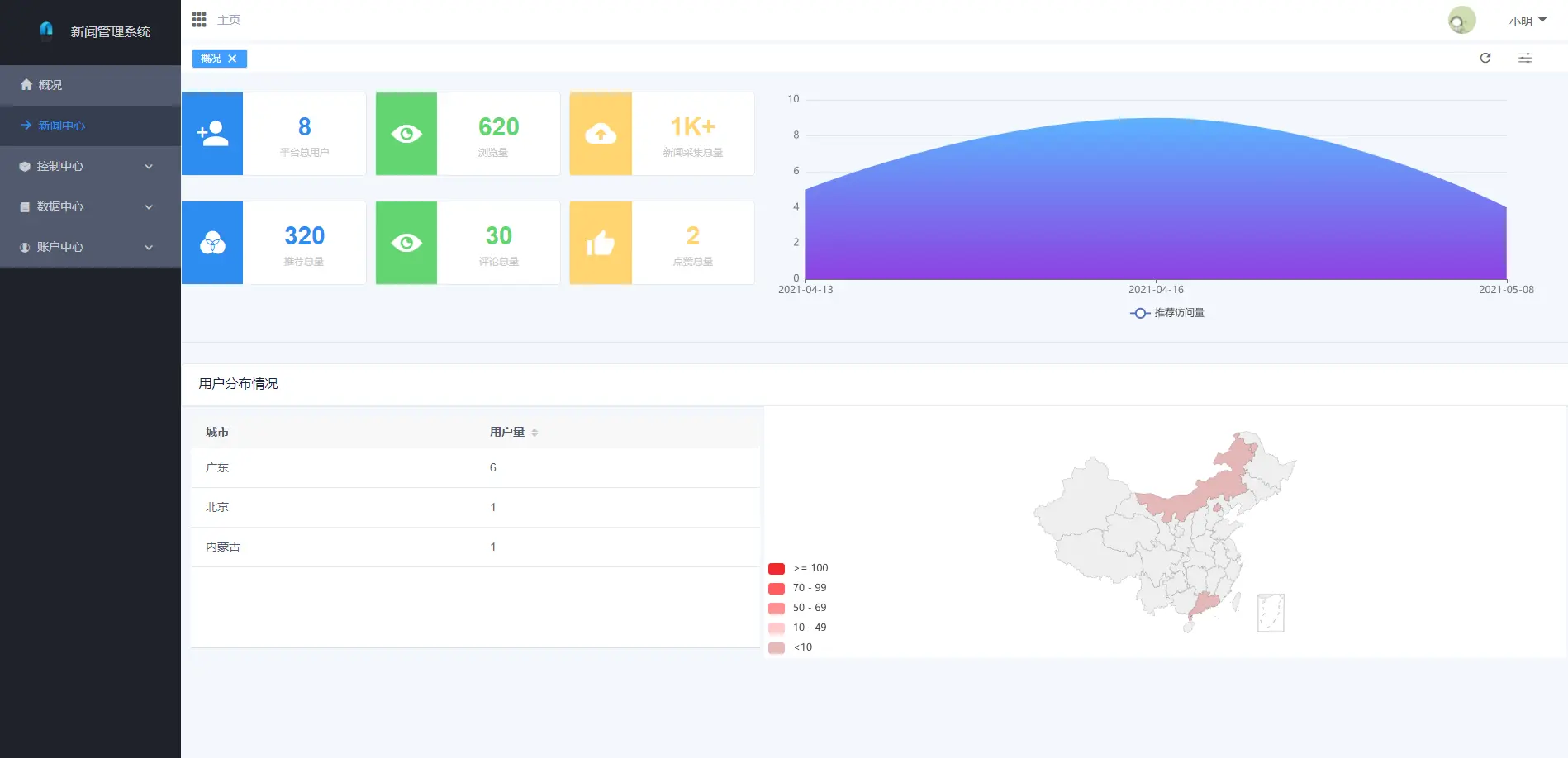
2.2 管理端
3 Django
簡介
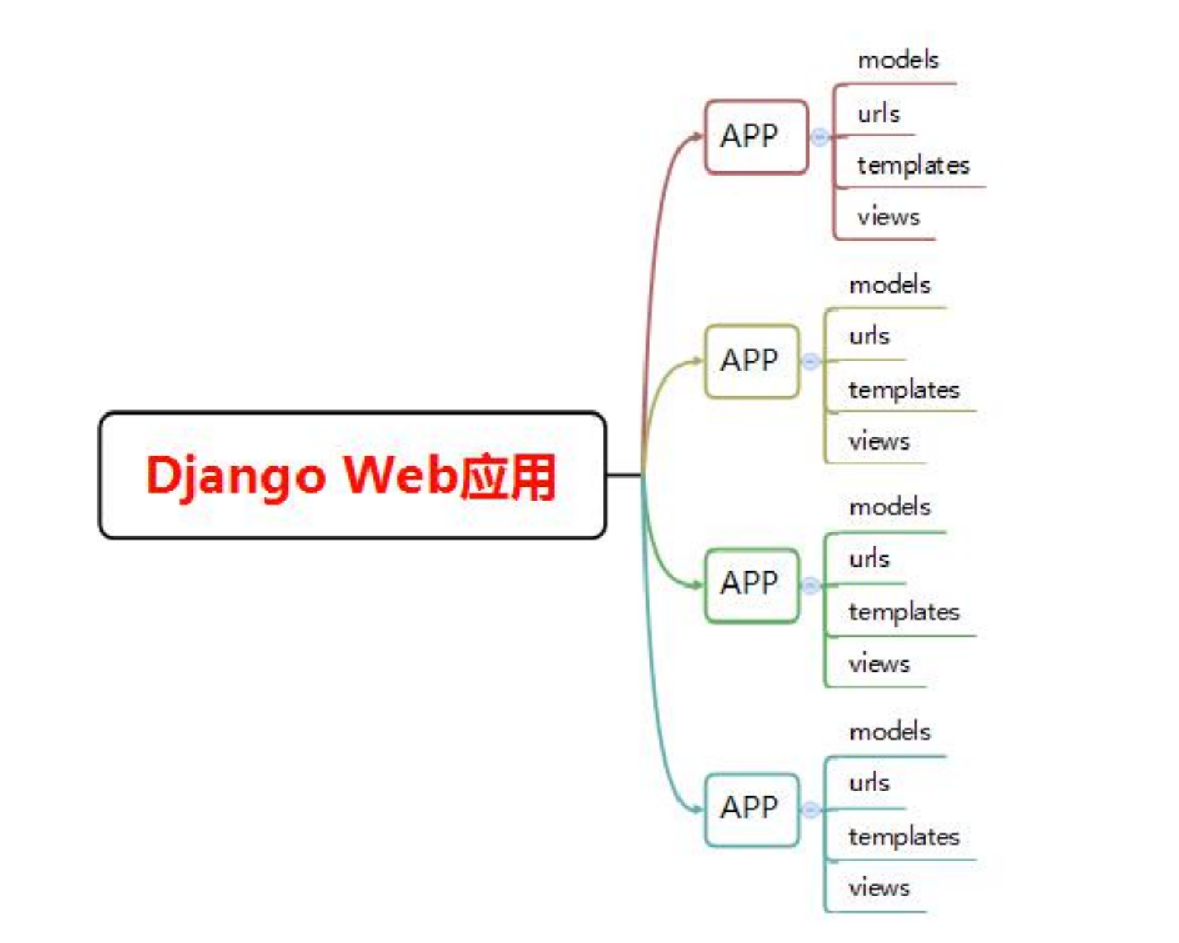
Django是一個基于Web的應用框架,由python編寫。Web開發的基礎是B/S架構,它通過前后端配合,將后臺服務器的數據在瀏覽器上展現給前臺用戶的應用。Django本身是基于MVC模型,即Model(模型)+View(視圖)+
Controller(控制器)設計模式,View模塊和Template模塊組成了它的視圖部分,這種結構使動態的邏輯是剝離于靜態頁面處理的。
Django框架的Model層本質上是一套ORM系統,封裝了大量的數據庫操作API,開發人員不需要知道底層的數據庫實現就可以對數據庫進行增刪改查等操作。Django強大的QuerySet設計能夠實現非常復雜的數據庫查詢操作,且性能接
安裝
?
? pip install django
使用
? #!/usr/bin/env python
? '''Django's command-line utility for administrative tasks.'''
? import os
? import sys?
? def main():
? '''Run administrative tasks.'''
? os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'newsServer.settings')
? try:
? from django.core.management import execute_from_command_line
? except ImportError as exc:
? raise ImportError(
? "Couldn't import Django. Are you sure it's installed and "
? "available on your PYTHONPATH environment variable? Did you "
? "forget to activate a virtual environment?"
? ) from exc
? execute_from_command_line(sys.argv)?
? if __name__ == '__main__':
? main()
4 爬蟲
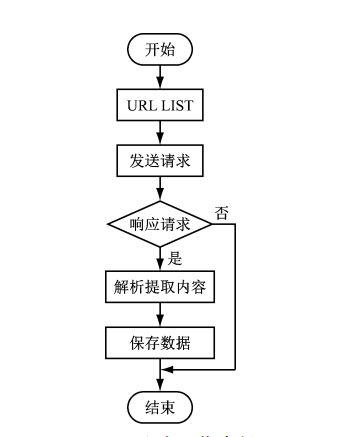
網絡爬蟲是一種按照一定的規則,自動地抓取萬維網信息的程序或者腳本。爬蟲對某一站點訪問,如果可以訪問就下載其中的網頁內容,并且通過爬蟲解析模塊解析得到的網頁鏈接,把這些鏈接作為之后的抓取目標,并且在整個過程中完全不依賴用戶,自動運行。若不能訪問則根據爬蟲預先設定的策略進行下一個
URL的訪問。在整個過程中爬蟲會自動進行異步處理數據請求,返回網頁的抓取數據。在整個的爬蟲運行之前,用戶都可以自定義的添加代理,偽 裝
請求頭以便更好地獲取網頁數據。爬蟲流程圖如下:
相關代碼
?
def getnewsdetail(url):
? # 獲取頁面上的詳情內容并將詳細的內容匯集在news集合中
? result = requests.get(url)
? result.encoding = 'utf-8'
? soup = BeautifulSoup(result.content, features="html.parser")
? title = getnewstitle(soup)
? if title == None:
? return None
? date = getnewsdate(soup)
? mainpage, orimainpage = getmainpage(soup)
? if mainpage == None:
? return None
? pic_url = getnewspic_url(soup)
? videourl = getvideourl(url)
? news = {'mainpage': mainpage,
? 'pic_url': pic_url,
? 'title': title,
? 'date': date,
? 'videourl': videourl,
? 'origin': orimainpage,
? }
? return news?
? def getmainpage(soup):
? '''
? @Description:獲取正文部分的p標簽內容,網易對正文部分的內容通過文本前部的空白進行標識\u3000
? @:param None
? '''
? if soup.find('div', id='article') != None:
? soup = soup.find('div', id='article')
? p = soup.find_all('p')
? for numbers in range(len(p)):
? p[numbers] = p[numbers].get_text().replace("\u3000", "").replace("\xa0", "").replace("新浪", "新聞")
? text_all = ""
? for each in p:
? text_all += each
? logger.info("mainpage:{}".format(text_all))
? return text_all, p
? elif soup.find('div', id='artibody') != None:
? soup = soup.find('div', id='artibody')
? p = soup.find_all('p')
? for numbers in range(len(p)):
? p[numbers] = p[numbers].get_text().replace("\u3000", "").replace("\xa0", "").replace("新浪", "新聞")
? text_all = ""
? for each in p:
? text_all += each
? logger.info("mainpage:{}" + text_all)
? return text_all, p
? else:
? return None, None?
? def getnewspic_url(soup):
? '''
? @Description:獲取正文部分的pic內容,網易對正文部分的圖片內容通過div中class屬性為“img_wrapper”
? @:param None
? '''
? pic = soup.find_all('div', class_='img_wrapper')
? pic_url = re.findall('src="(.*?)"', str(pic))
? for numbers in range(len(pic_url)):
? pic_url[numbers] = pic_url[numbers].replace("//", 'https://')
? logging.info("pic_url:{}".format(pic_url))
? return pic_url
5 Vue
簡介
Vue是一套用于構建用戶界面的漸進式框架。其核心庫只關注視圖層,不僅易于上手,還便于與第三方庫或既有項目整合。Vue框架主要有以下三個特點:
-
遵循MVVM模式
MVVM是Model-View-ViewModel的簡寫,它本質上是MVC的改進版。MVVM的主要目的是分離視圖(View)和模型(Model)。如圖所示。
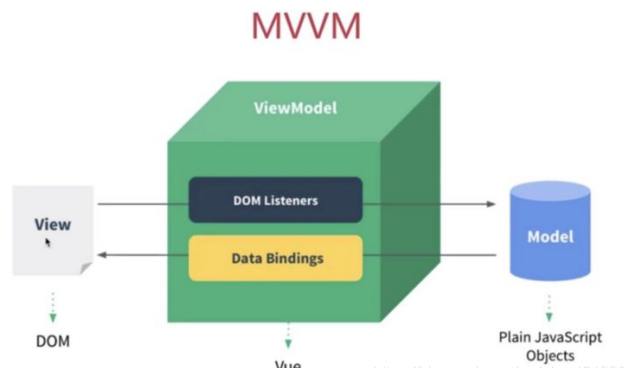
-
組件化
組件系統允許我們使用小型、獨立和通常可復用的組件構建大型應用。幾乎任意類型的應用界面都可以抽象為一個組件樹,如圖所示。
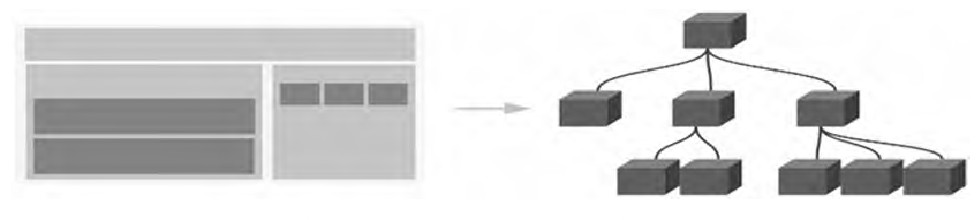
-
虛擬DOM
頻繁操作操作真實DOM會出現頁面卡頓,影響用戶體驗。Vue的虛擬DOM不會立即操作DOM,而是將多次操作保存起來,進行合并計算,減少真實DOM的渲染計算次數,提升用戶體驗。
6 推薦算法(Recommendation)
基于協同過濾的推薦算法(Collaborative Filtering Recommendations)
協同過濾(Collaborative Filtering)推薦算法是最經典、最常用的推薦算法。
所謂協同過濾, 基本思想是根據用戶之前的喜好以及其他興趣相近的用戶的選擇來給用戶推薦物品(基于對用戶歷史行為數據的挖掘發現用戶的喜好偏向,
并預測用戶可能喜好的產品進行推薦),一般是僅僅基于用戶的行為數據(評價、購買、下載等),
而不依賴于項的任何附加信息(物品自身特征)或者用戶的任何附加信息(年齡, 性別等)。目前應用比較廣泛的協同過濾算法是基于鄰域的方法,
而這種方法主要有下面兩種算法:
- 基于用戶的協同過濾算法(UserCF): 給用戶推薦和他興趣相似的其他用戶喜歡的產品
- 基于物品的協同過濾算法(ItemCF): 給用戶推薦和他之前喜歡的物品相似的物品
代碼實現
?
def itemcf_sim(df):"""文章與文章之間的相似性矩陣計算:param df: 數據表:item_created_time_dict: 文章創建時間的字典return : 文章與文章的相似性矩陣思路: 基于物品的協同過濾(詳細請參考上一期推薦系統基礎的組隊學習), 在多路召回部分會加上關聯規則的召回策略"""
?
user_item_time_dict = get_user_item_time(df)
# 計算物品相似度i2i_sim = {}item_cnt = defaultdict(int)for user, item_time_list in tqdm(user_item_time_dict.items()):# 在基于商品的協同過濾優化的時候可以考慮時間因素for i, i_click_time in item_time_list:item_cnt[i] += 1i2i_sim.setdefault(i, {})for j, j_click_time in item_time_list:if(i == j):continuei2i_sim[i].setdefault(j, 0)i2i_sim[i][j] += 1 / math.log(len(item_time_list) + 1)i2i_sim_ = i2i_sim.copy()for i, related_items in i2i_sim.items():for j, wij in related_items.items():i2i_sim_[i][j] = wij / math.sqrt(item_cnt[i] * item_cnt[j])# 將得到的相似性矩陣保存到本地pickle.dump(i2i_sim_, open(save_path + 'itemcf_i2i_sim.pkl', 'wb'))return i2i_sim_
?
7 APScheduler框架
簡介
Advanced Python Scheduler (APScheduler) 是一個 Python 庫,可讓您安排 Python
代碼稍后執行,可以只執行一次,也可以定期執行。您可以隨意添加新工作或刪除舊工作。如果您將任務存儲在數據庫中,它們也將在調度器重新啟動后幸存下來并保持其狀態。當調度器重新啟動時,它將運行它在離線時應該運行的所有任務。
除此之外,APScheduler 可以用作跨平臺、特定于應用程序的平臺特定調度器的替代品,例如 cron 守護程序或 Windows
任務調度器。但是請注意,APScheduler
本身不是守護程序或服務,也不附帶任何命令行工具。它主要用于在現有應用程序中運行。也就是說,APScheduler
確實為您提供了一些構建塊來構建調度器服務或運行專用調度器進程。
安裝
pip安裝:
?
? pip install apscheduler
本項目相關使用:
? from apscheduler.schedulers.blocking import BlockingScheduler
? from Recommend.NewsRecommendByCity import beginrecommendbycity
? from Recommend.NewsRecommendByHotValue import beginrecommendbyhotvalue
? from Recommend.NewsRecommendByTags import beginNewsRecommendByTags
? from Recommend.NewsKeyWordsSelect import beginSelectKeyWord
? from Recommend.NewsHotValueCal import beginCalHotValue
? from Recommend.NewsCorrelationCalculation import beginCorrelation
? from Recommend.HotWordLibrary import beginHotWordLibrary
? sched = BlockingScheduler()sched2 = BlockingScheduler()?
? def beginRecommendSystem(time):
? '''
? @Description:推薦系統啟動管理器(基于城市推薦、基于熱度推薦、基于新聞標簽推薦)
? @:param time --> 時間間隔
? '''
? sched.add_job(func=beginrecommendbycity, trigger='interval', max_instances=1, seconds=int(time),
? id='NewsRecommendByCity',
? kwargs={})
? sched.add_job(beginrecommendbyhotvalue, 'interval', max_instances=1, seconds=int(time),
? id='NewsRecommendByHotValue',
? kwargs={})
? sched.add_job(beginNewsRecommendByTags, 'interval', max_instances=1, seconds=int(time), id='NewsRecommendByTags',
? kwargs={})
? sched.start()?
? def stopRecommendSystem():
? '''
? @Description:推薦系統關閉管理器
? @:param None
? '''
? sched.remove_job('NewsRecommendByCity')
? sched.remove_job('NewsRecommendByHotValue')
? sched.remove_job('NewsRecommendByTags')?
? def beginAnalysisSystem(time):
? '''
? @Description:數據分析系統啟動管理器(關鍵詞分析、熱詞分析、新聞相似度分析、熱詞統計)
? @:param time --> 時間間隔
? '''
? sched2.add_job(beginSelectKeyWord, trigger='interval', max_instances=1, seconds=int(time),
? id='beginSelectKeyWord',
? kwargs={"_type": 2})
? sched2.add_job(beginCalHotValue, 'interval', max_instances=1, seconds=int(time),
? id='beginCalHotValue',
? kwargs={})
? sched2.add_job(beginCorrelation, 'interval', max_instances=1, seconds=int(time), id='beginCorrelation',
? kwargs={})
? sched2.add_job(beginHotWordLibrary, 'interval', max_instances=1, seconds=int(time), id='beginHotWordLibrary',
? kwargs={})
? sched2.start()
? def stopAnalysisSystem():'''@Description:數據分析系統關閉管理器@:param None'''sched2.remove_job('beginSelectKeyWord')sched2.remove_job('beginCalHotValue')sched2.remove_job('beginCorrelation')sched2.remove_job('beginHotWordLibrary')sched2.shutdown()?
7 最后
🧿 更多資料, 項目分享:
https://gitee.com/dancheng-senior/postgraduate



)
)
)
)

)










