模型預測
- 一、導入關鍵包
- 二、如何載入、分析和保存文件
- 三、修改缺失值
- 3.1 眾數
- 3.2 平均值
- 3.3 中位數
- 3.4 0填充
- 四、修改異常值
- 4.1 刪除
- 4.2 替換
- 五、數據繪圖分析
- 5.1 餅狀圖
- 5.1.1 繪制某一特征的數值情況(二分類)
- 5.2 柱狀圖
- 5.2.1 單特征與目標特征之間的圖像
- 5.2.2 多特征與目標特征之間的圖像
- 5.3 折線圖
- 5.3.1 多個特征之間的關系圖
- 5.4 散點圖
- 六、相關性分析
- 6.1 皮爾遜相關系數
- 6.2 斯皮爾曼相關系數
- 6.3 肯德爾相關系數
- 6.4 計算熱力圖
- 七、數據歸一化
- 八、模型搭建
- 九、模型訓練
- 十、評估模型
- 十一、預測模型
一、導入關鍵包
# 導入數據分析需要的包
import pandas as pd
import numpy as np
# 可視化包
import seaborn as sns
sns.set(style="whitegrid")
import matplotlib.pyplot as plt
%matplotlib inline
# 忽略警告信息
import warnings
warnings.filterwarnings('ignore')
# 導入數據分析需要的包
import pandas as pd
import numpy as np
from datetime import datetime# 構建多個分類器
from sklearn.ensemble import RandomForestClassifier # 隨機森林
from sklearn.svm import SVC, LinearSVC # 支持向量機
from sklearn.linear_model import LogisticRegression # 邏輯回歸
from sklearn.neighbors import KNeighborsClassifier # KNN算法
from sklearn.naive_bayes import GaussianNB # 樸素貝葉斯
from sklearn.tree import DecisionTreeClassifier # 決策樹分類器
from xgboost import XGBClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import precision_score, recall_score, f1_score
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import GridSearchCV # 網格搜索
np.set_printoptions(suppress=True)# 顯示中文
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
二、如何載入、分析和保存文件
df=pd.read_csv('data/dataset.csv')df.head(5)# 查看前幾列數據
df.tail() # 返回CSV文件的最后幾行數據。
df.info() # 顯示CSV文件的基本信息,包括數據類型、列數、行數、缺失值等。
df.describe()# 對CSV文件的數值型數據進行統計描述,包括計數、均值、標準差、最小值、最大值等。
df.shape()# 返回CSV文件的行數和列數。
df.unique() # 返回CSV文件中某一列的唯一值。
df.value_counts()# 計算CSV文件中某一列中每個值的出現次數。
df.groupby() # 按照某一列的值進行分組,并對其他列進行聚合操作,如求和、計數、平均值等。
df.sort_values()# 按照某一列的值進行排序。
df.pivot_table()# 創建透視表,根據指定的行和列對數據進行匯總和分析。# 保存處理后的數據集
3df.to_csv('data/Telecom_data_flag.csv')
三、修改缺失值
3.1 眾數
# 對每一列屬性采用相應的缺失值處理方式,通過分析發現這類數據都可以采用眾數的方式解決
df.isnull().sum()
modes = df.mode().iloc[0]
print(modes)
df = df.fillna(modes)
print(df.isnull().sum())
3.2 平均值
mean_values = df.mean()
print(mean_values)
df = df.fillna(mean_values)
print(df.isnull().sum())
3.3 中位數
median_values = df.median()
print(median_values)
df = df.fillna(median_values)
print(df.isnull().sum())
3.4 0填充
df = df.fillna(0)
print(df.isnull().sum())
四、修改異常值
4.1 刪除
1.刪除DataFrame表中全部為NaN的行
your_dataframe.dropna(axis=0,how='all')
2.刪除DataFrame表中全部為NaN的列
your_dataframe.dropna(axis=1,how='all')
3.刪除表中含有任何NaN的行
your_dataframe.dropna(axis=0,how='any')
4.刪除表中含有任何NaN的列
your_dataframe.dropna(axis=1,how='any')
4.2 替換
這里的替換可以參考前文的中位數,平均值,眾數,0替換等。
replace_value = 0.0# 這里設置 inplace 為 True,能夠直接把表中的 NaN 值替換掉your_dataframe.fillna(replace_value, inplace=True)# 如果不設置 inplace,則這樣寫就行# new_dataframe = your_dataframe.fillna(replace_value)五、數據繪圖分析
5.1 餅狀圖
5.1.1 繪制某一特征的數值情況(二分類)
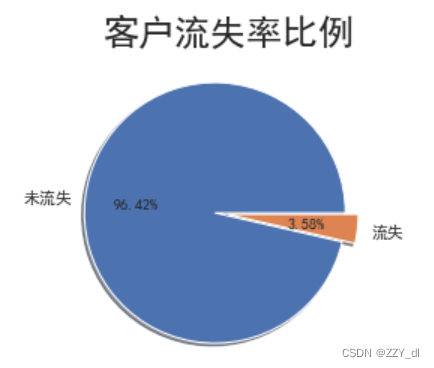
# 查看總體客戶流失情況
churnvalue = df["LEAVE_FLAG"].value_counts()
labels = df["LEAVE_FLAG"].value_counts().index
plt.pie(churnvalue,labels=["未流失","流失"],explode=(0.1,0),autopct='%.2f%%', shadow=True,)
plt.title("客戶流失率比例",size=24)
plt.show()
# 從餅形圖中看出,流失客戶占總客戶數的很小的比例,流失率達3.58%
5.2 柱狀圖
5.2.1 單特征與目標特征之間的圖像
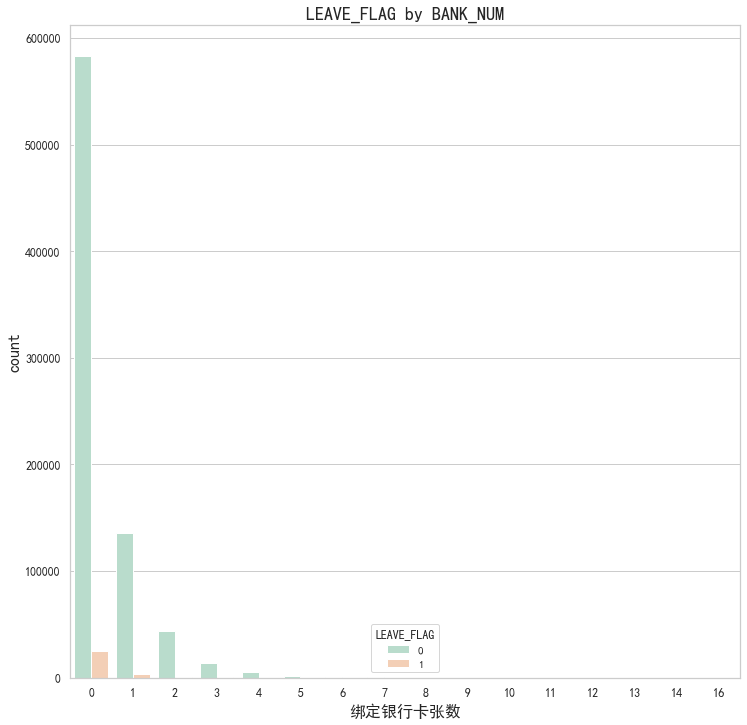
# 粘性/忠誠度分析 包括綁定銀行卡張數
fig, axes = plt.subplots(1, 1, figsize=(12,12))
plt.subplot(1,1,1)
# palette參數表示設置顏色
gender=sns.countplot(x='BANK_NUM',hue="LEAVE_FLAG",data=df,palette="Pastel2")
plt.xlabel("綁定銀行卡張數",fontsize=16)
plt.title("LEAVE_FLAG by BANK_NUM",fontsize=18)
plt.ylabel('count',fontsize=16)
plt.tick_params(labelsize=12) # 設置坐標軸字體大小
# 從此表可知,對于沒有綁定銀行卡的用戶流失情況會更大,應該加強督促用戶綁定銀行卡
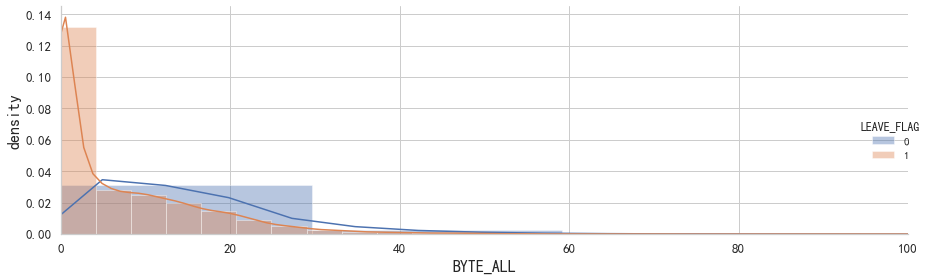
# 查看正常用戶與流失用戶在上網流量上的差別
plt.figure(figsize=(10,6))
g = sns.FacetGrid(data = df,hue = 'LEAVE_FLAG', height=4, aspect=3)
g.map(sns.distplot,'BYTE_ALL',norm_hist=True)
g.add_legend()
plt.ylabel('density',fontsize=16)
plt.xlabel('BYTE_ALL',fontsize=16)
plt.xlim(0, 100)
plt.tick_params(labelsize=13) # 設置坐標軸字體大小
plt.tight_layout()
plt.show()
# 從上圖看出,上網流量少的用戶流失率相對較高。
5.2.2 多特征與目標特征之間的圖像
這里繪制的多個二分類特征的情況是與目標特征之間的關系
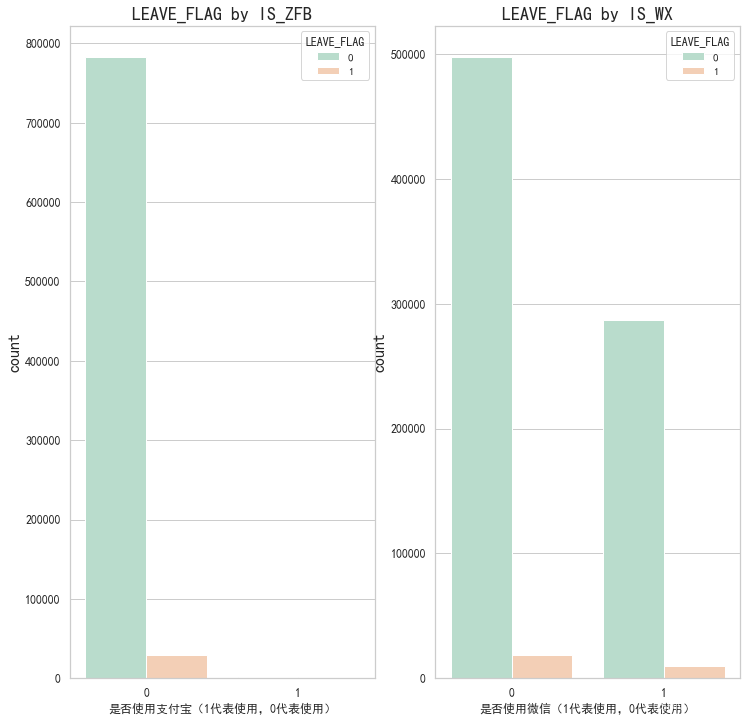
# 粘性/忠誠度分析 包括是否捆綁微信、是否捆綁支付寶
# sns.countplot()函數繪制了"是否使用支付寶"(IS_ZFB)這一列的柱狀圖,并根據"LEAVE_FLAG"(是否離網)進行了顏色分類。
fig, axes = plt.subplots(1, 2, figsize=(12,12))
plt.subplot(1,2,1)
# palette參數表示設置顏色
partner=sns.countplot(x="IS_ZFB",hue="LEAVE_FLAG",data=df,palette="Pastel2")
plt.xlabel("是否使用支付寶(1代表使用,0代表使用)")
plt.title("LEAVE_FLAG by IS_ZFB",fontsize=18)
plt.ylabel('count',fontsize=16)
plt.tick_params(labelsize=12) # 設置坐標軸字體大小plt.subplot(1,2,2)
seniorcitizen=sns.countplot(x="IS_WX",hue="LEAVE_FLAG",data=df,palette="Pastel2")
plt.xlabel("是否使用微信(1代表使用,0代表使用)")
plt.title("LEAVE_FLAG by IS_WX",fontsize=18)
plt.ylabel('count',fontsize=16)
plt.tick_params(labelsize=12) # 設置坐標軸字體大小
# 從此表可知 支付寶綁定目前對于用戶流失沒有影響,微信的綁定影響會稍微大點,可能是微信用戶用的較多
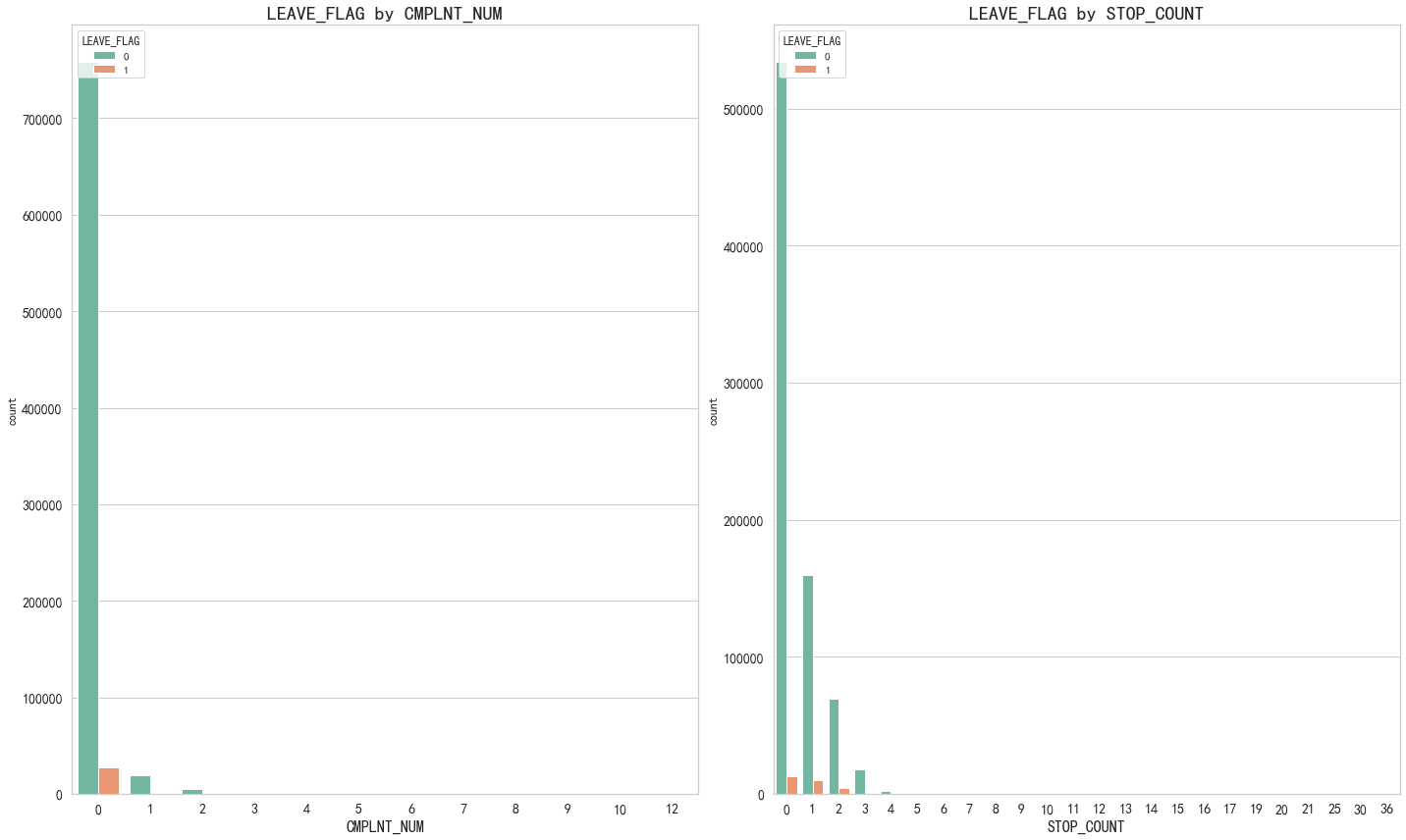
# 異常性 根據用戶流失情況來結合判定
covariables=["CMPLNT_NUM", "STOP_COUNT"]
fig,axes=plt.subplots(1,2,figsize=(20,12))
for i, item in enumerate(covariables):'''0,'CMPLNT_NUM'1,'STOP_COUNT''''plt.subplot(1,2,(i+1))ax=sns.countplot(x=item,hue="LEAVE_FLAG",data=df,palette="Set2")plt.xlabel(str(item),fontsize=16)plt.tick_params(labelsize=14) # 設置坐標軸字體大小plt.title("LEAVE_FLAG by "+ str(item),fontsize=20)i=i+1
plt.tight_layout()
plt.show()
# 從此表可知 最近6個月累計投訴次數間接性的決定了用戶的流失,停機天數也和用戶流失成正相關。
5.3 折線圖
5.3.1 多個特征之間的關系圖
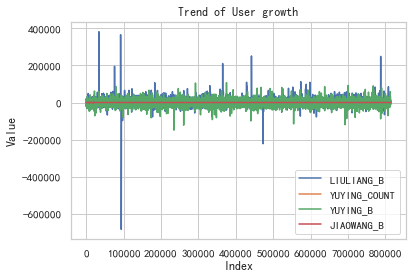
# 用戶的成長性分析,結合用戶流失情況。
# 包括流量趨勢、語音通話次數趨勢、語音通話時長趨勢、交往圈趨勢
# 提取特征數據列
feature1 = df["LIULIANG_B"]
feature2 = df["YUYING_COUNT"]
feature3 = df["YUYING_B"]
feature4 = df["JIAOWANG_B"]# 繪制折線圖
plt.plot(feature1, label="LIULIANG_B")
plt.plot(feature2, label="YUYING_COUNT")
plt.plot(feature3, label="YUYING_B")
plt.plot(feature4, label="JIAOWANG_B")# 添加標題和標簽
plt.title("Trend of User growth")
plt.xlabel("Index")
plt.ylabel("Value")# 添加圖例
plt.legend()# 顯示圖表
plt.show()
# 從此圖可以發現針對流量趨勢來說,用戶的波動是最大的。
5.4 散點圖
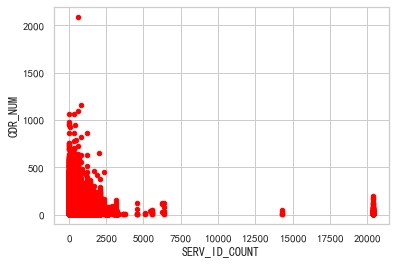
df.plot(x="SERV_ID_COUNT", y="CDR_NUM", kind="scatter", c="red")
plt.show()
這段代碼的作用是繪制一個以"SERV_ID_COUNT"為橫軸,"CDR_NUM"為縱軸的散點圖,并將散點的顏色設置為紅色。通過這個散點圖,可以直觀地觀察到"SERV_ID_COUNT"和"CDR_NUM"之間的關系。
六、相關性分析
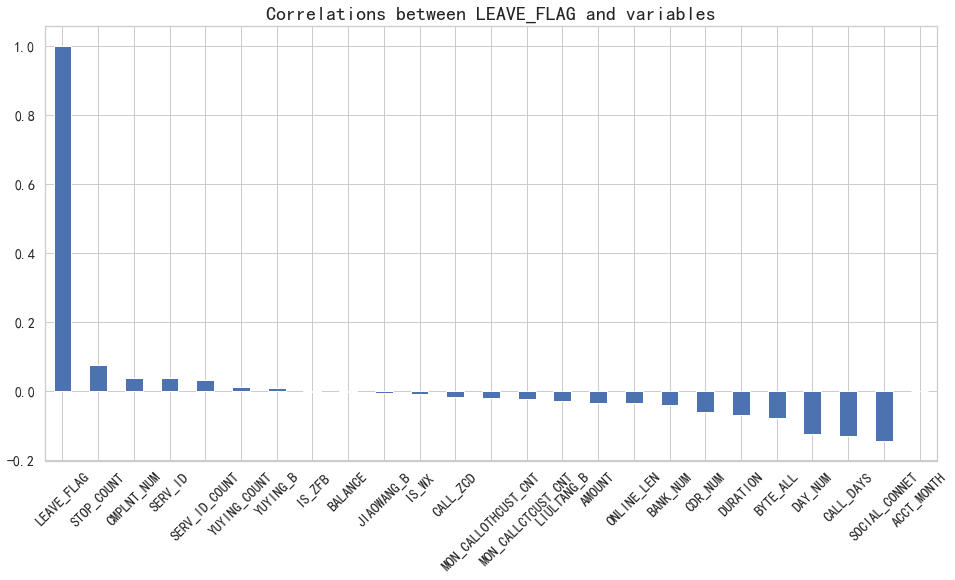
6.1 皮爾遜相關系數
plt.figure(figsize=(16,8))
df.corr()['LEAVE_FLAG'].sort_values(ascending = False).plot(kind='bar')
plt.tick_params(labelsize=14) # 設置坐標軸字體大小
plt.xticks(rotation=45) # 設置x軸文字轉向
plt.title("Correlations between LEAVE_FLAG and variables",fontsize=20)
plt.show()
# 從圖可以直觀看出,YUYING_COUNT 、YUYING_B、IS_ZFB、BALANCE、JIAOWANG_B、IS_WX這六個變量與LEAVE_FLAG目標變量相關性最弱。
6.2 斯皮爾曼相關系數
plt.figure(figsize=(16,8))
df.corr(method='spearman')['LEAVE_FLAG'].sort_values(ascending = False).plot(kind='bar')
plt.tick_params(labelsize=14) # 設置坐標軸字體大小
plt.xticks(rotation=45) # 設置x軸文字轉向
plt.title("Correlations between LEAVE_FLAG and variables",fontsize=20)
plt.show()
6.3 肯德爾相關系數
plt.figure(figsize=(16,8))
df.corr(method='kendall')['LEAVE_FLAG'].sort_values(ascending = False).plot(kind='bar')
plt.tick_params(labelsize=14) # 設置坐標軸字體大小
plt.xticks(rotation=45) # 設置x軸文字轉向
plt.title("Correlations between LEAVE_FLAG and variables",fontsize=20)
plt.show()
6.4 計算熱力圖
# 計算相關性矩陣
corr_matrix = df.corr()# 繪制熱力圖
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap="coolwarm")
plt.title("Correlation Heatmap", fontsize=16)
plt.show()
七、數據歸一化
特征主要分為連續特征和離散特征,其中離散特征根據特征之間是否有大小關系又細分為兩類。
- 連續特征:一般采用歸一標準化方式處理。
- 離散特征:特征之間沒有大小關系。
- 離散特征:特征之間有大小關聯,則采用數值映射。
# 通過歸一化處理使特征數據標準為1,均值為0,符合標準的正態分布,
# 降低數值特征過大對預測結果的影響
# 除了目標特征全部做歸一化,目標特征不用做,歸一化會導致預測結果的解釋變得困難
from sklearn.preprocessing import StandardScaler
# 實例化一個轉換器類
scaler = StandardScaler(copy=False)
target = df["LEAVE_FLAG"]
# 提取除目標特征外的其他特征
other_features = df.drop("LEAVE_FLAG", axis=1)
# 對其他特征進行歸一化
normalized_features = scaler.fit_transform(other_features)
# 將歸一化后的特征和目標特征重新組合成DataFrame
normalized_data = pd.DataFrame(normalized_features, columns=other_features.columns)
normalized_data["LEAVE_FLAG"] = target
normalized_data.head()
八、模型搭建
# 深拷貝
X=normalized_data.copy()
X.drop(['LEAVE_FLAG'],axis=1, inplace=True)
y=df["LEAVE_FLAG"]
#查看預處理后的數據
X.head()# 建立訓練數據集和測試數據集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state = 0)
print("原始訓練集包含樣本數量: ", len(X_train))
print("原始測試集包含樣本數量: ", len(X_test))
print("原始樣本總數: ", len(X_train)+len(X_test))# 使用分類算法
Classifiers=[["RandomForest",RandomForestClassifier()],["LogisticRegression",LogisticRegression(C=1000.0, random_state=30, solver="lbfgs",max_iter=100000)],["NaiveBayes",GaussianNB()],["DecisionTree",DecisionTreeClassifier()],["AdaBoostClassifier", AdaBoostClassifier()],["GradientBoostingClassifier", GradientBoostingClassifier()],["XGB", XGBClassifier()]
]
九、模型訓練
from datetime import datetime
import pickle
import joblibdef get_current_time():current_time = datetime.now()formatted_time = current_time.strftime("%Y-%m-%d %H:%M:%S")return current_time, formatted_timeClassify_result=[]
names=[]
prediction=[]
i = 0for name, classifier in Classifiers:start_time, formatted_time = get_current_time()print("**********************************************************************")print("第{}個模型訓練開始時間:{} 模型名稱為:{}".format(i+1, formatted_time, name))classifier = classifierclassifier.fit(X_train, y_train)y_pred = classifier.predict(X_test)recall = recall_score(y_test, y_pred)precision = precision_score(y_test, y_pred)f1score = f1_score(y_test, y_pred)model_path = 'models/{}_{}_model.pkl'.format(name, round(precision, 5))print("開始保存模型文件路徑為:{}".format(model_path))# 保存模型方式1# with open('models/{}_{}_model.pkl'.format(name, precision), 'wb') as file:# pickle.dump(classifier, file)# file.close()# 保存模型方式2joblib.dump(classifier, model_path)end_time = datetime.now() # 獲取訓練結束時間print("第{}個模型訓練結束時間:{}".format(i+1, end_time.strftime("%Y-%m-%d %H:%M:%S")))print("訓練耗時:", end_time - start_time)# 打印訓練過程中的指標print("Classifier:", name)print("Recall:", recall)print("Precision:", precision)print("F1 Score:", f1score)print("**********************************************************************")# 保存指標結果class_eva = pd.DataFrame([recall, precision, f1score])Classify_result.append(class_eva)name = pd.Series(name)names.append(name)y_pred = pd.Series(y_pred)prediction.append(y_pred)i += 1
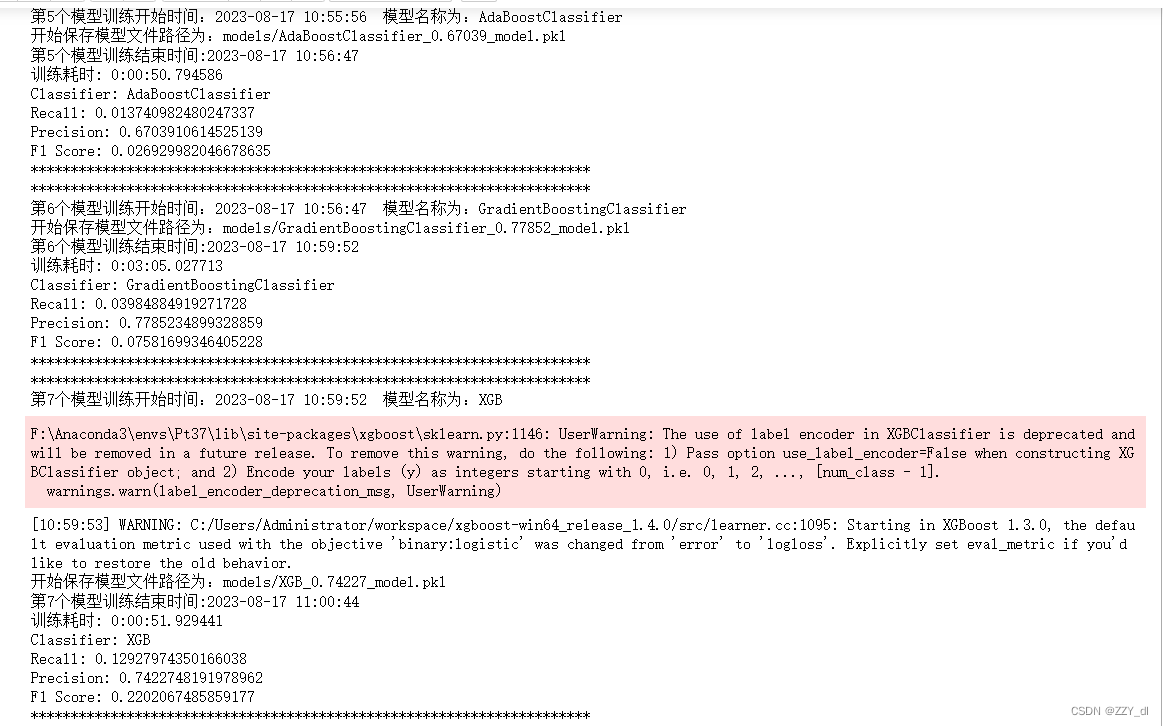
十、評估模型
召回率(recall)的含義是:原本為對的當中,預測為對的比例(值越大越好,1為理想狀態)
精確率、精度(precision)的含義是:預測為對的當中,原本為對的比例(值越大越好,1為理想狀態)
F1分數(F1-Score)指標綜合了Precision與Recall的產出的結果
F1-Score的取值范圍從0到1的,1代表模型的輸出最好,0代表模型的輸出結果最差。
classifier_names=pd.DataFrame(names)
# 轉成列表
classifier_names=classifier_names[0].tolist()
result=pd.concat(Classify_result,axis=1)
result.columns=classifier_names
result.index=["recall","precision","f1score"]
result

十一、預測模型
對于h5模型
from keras.models import load_model
model = load_model('lstm_model.h5')
pred = model.predict(X, verbose=0)
print(pred)
對于pkl模型
loaded_model = joblib.load('models/{}_model.pkl'.format(name))
由于沒有預測數據集,選擇最后n條數為例進行預測。
# 由于沒有預測數據集,選擇最后n條數為例進行預測。
n = 500
pred_id = SERV_ID.tail(n)
# 提取預測數據集特征(如果有預測數據集,可以一并進行數據清洗和特征提取)
pred_x = X.tail(n)# 使用上述得到的最優模型
model = GradientBoostingClassifier()model.fit(X_train,y_train)
pred_y = model.predict(pred_x) # 預測值# 預測結果
predDf = pd.DataFrame({'SERV_ID':pred_id, 'LEAVE_FLAG':pred_y})
print("*********************原始的標簽情況*********************")
print(df.tail(n)['LEAVE_FLAG'].value_counts())
print("*********************預測的標簽情況*********************")
print(predDf['LEAVE_FLAG'].value_counts())
print("*********************預測的準確率*********************")
min1 = min(df.tail(n)['LEAVE_FLAG'].value_counts()[0],predDf['LEAVE_FLAG'].value_counts()[0])
min2 = min(df.tail(n)['LEAVE_FLAG'].value_counts()[1],predDf['LEAVE_FLAG'].value_counts()[1])
print("{}%".format(round((min1+min2)/n,3)*100))
# 由于沒有預測數據集,選擇最后n條數為例進行預測。
n = 500 # 預測的數量
pred_id = SERV_ID.tail(n)
# 提取預測數據集特征(如果有預測數據集,可以一并進行數據清洗和特征提取)
pred_x = X.tail(n)
# 加載模型
loaded_model = joblib.load('models/GradientBoostingClassifier_0.77852_model.pkl')
# 使用加載的模型進行預測
pred_y = loaded_model.predict(pred_x)
# 預測結果
predDf = pd.DataFrame({'SERV_ID':pred_id, 'LEAVE_FLAG':pred_y})
print("*********************原始的標簽情況*********************")
print(df.tail(n)['LEAVE_FLAG'].value_counts())
print("*********************預測的標簽情況*********************")
print(predDf['LEAVE_FLAG'].value_counts())
print("*********************預測的準確率*********************")
min1 = min(df.tail(n)['LEAVE_FLAG'].value_counts()[0],predDf['LEAVE_FLAG'].value_counts()[0])
min2 = min(df.tail(n)['LEAVE_FLAG'].value_counts()[1],predDf['LEAVE_FLAG'].value_counts()[1])
print("{}%".format(round((min1+min2)/n,3)*100))


![[數據集][目標檢測]鋼材表面缺陷目標檢測數據集VOC格式2279張10類別](http://pic.xiahunao.cn/[數據集][目標檢測]鋼材表面缺陷目標檢測數據集VOC格式2279張10類別)





![[C++]筆記 - 知識點積累](http://pic.xiahunao.cn/[C++]筆記 - 知識點積累)


![[Go版]算法通關村第十一關白銀——位運算的高頻算法題](http://pic.xiahunao.cn/[Go版]算法通關村第十一關白銀——位運算的高頻算法題)

之 手動搭建 K8S 環境搭建)






