荷蘭語是大約24萬人的第一語言,也是近5萬人的第二語言,是繼英語和德語之后第三大日耳曼語言。來自比利時魯汶大學和柏林工業大學的一組研究人員最近推出了基于荷蘭RoBERTa的語言模型RobBERT。
谷歌的BERT(來自Transformers的B idirectional Encoder R表示)于2019年首次推出,是一種強大而流行的語言表示模型,旨在預訓練來自未標記文本的深度雙向表示。研究表明,在單一語言上訓練的BERT模型明顯優于多語言版本。
與以前使用早期的BERT實現來訓練荷蘭語BERT的方法不同,新研究使用了RoBERTa,這是去年夏天由Facebook AI和華盛頓大學西雅圖分校的研究人員推出的BERT的改進版本。RobBERT 經過了來自 OSCAR 語料庫荷蘭部分的 6 億字總計 6 GB 文本的預訓練。
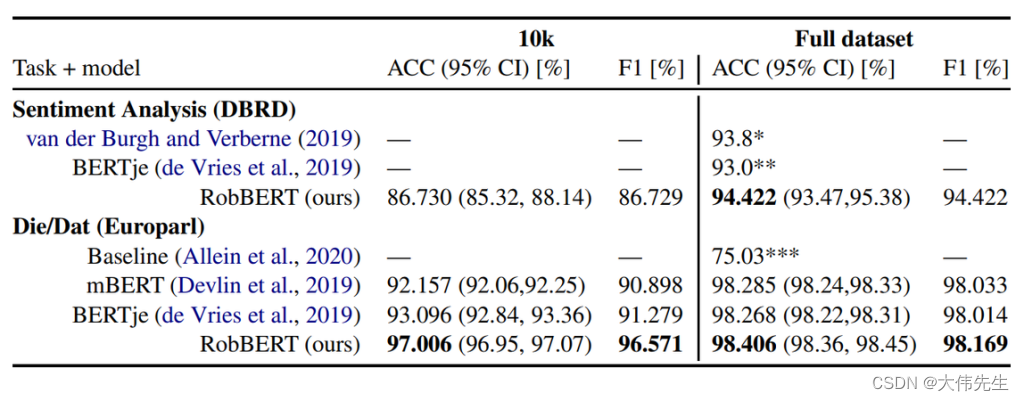
與SOTA相比,RobBERT在幾個下游任務上進行了微調的結果
研究人員在不同環境中評估了RobBERT在多個下游任務上的表現,比較了其在荷蘭書評數據集(DBRD)的情感分析中的表現,以及荷蘭語特有的任務,將Europarl話語語料庫中的“die”與“dat(that)”區分開來。結果表明,RobBERT在情感分析方面優于現有的基于荷蘭BERT的模型,如BERTje,并在“Die/Dat”消歧任務上取得了最先進的結果。
本文確定了這項研究的可能改進和未來方向,例如訓練類似的模型,改變訓練數據格式和預訓練任務,如句子順序預測,以及將RobBERT應用于其他荷蘭語任務。
預訓練的RobBERT模型可以與Hugging Face的變壓器和Facebook的Fairseq工具包一起使用。順便說一下,RobBERT標志源于這樣一個事實,即“rob”這個詞在荷蘭語中也是“印章”的意思。
論文RobBERT:基于荷蘭RoBERTa的語言模型在arXiv上發表。模型和代碼可在 GitHub 上找到。
)
4.2 基于Matlab/Simulink的軟件組件開發)

——Centos7更新)



)
)

)








