「作者主頁」:士別三日wyx
「作者簡介」:CSDN top100、阿里云博客專家、華為云享專家、網絡安全領域優質創作者
「推薦專欄」:對網絡安全感興趣的小伙伴可以關注專欄《網絡安全入門到精通》
sklearn數據集
- 二、安裝sklearn
- 二、獲取數據集
- 三、數據集劃分
機器學習是人工智能的一個實現途徑,可以從「數據」中自動分析獲得「模型」,并利用模型對未知數據進行「預測」。
簡單來說就是從歷史數據中總結規律,用來解決新出現的問題。
從數據中總結規律,需要提供一個「數據集」,數據集由「特征值」和「目標值」兩部分組成。
機器學習有很多好用的工具,這里我們使用sekearn。
sklearn是基于Python的機器學習工具包,自帶大量數據集,可供我們練習各種機器學習算法。
二、安裝sklearn
環境要求:
- Python(>=2.7 or >=3.3)
- NumPy (>= 1.8.2)
- SciPy (>= 0.13.3)
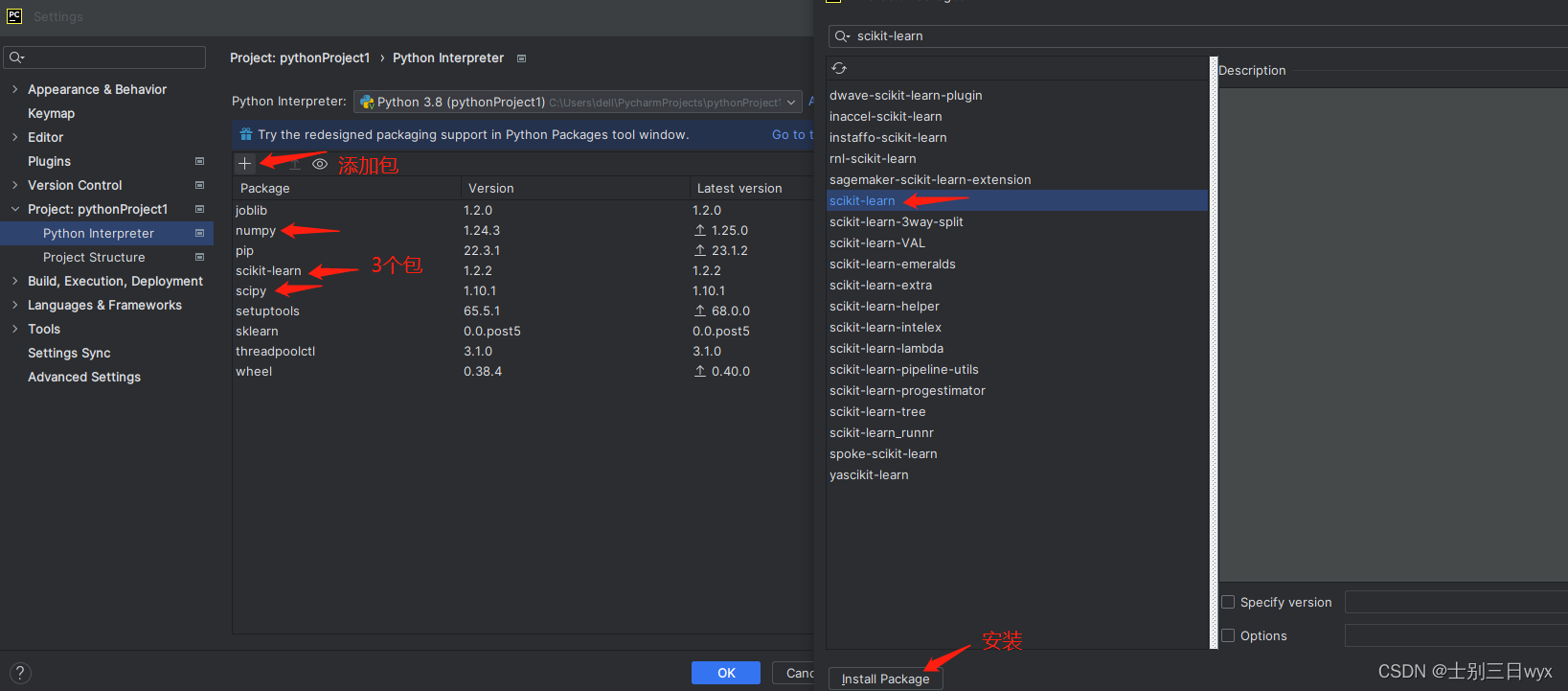
先安裝 numpy、scipy,再安裝 scikit-learn
PyCharm左上角【file】-【Settings】-【Project:pythonProject】-【Python Interpreter】
二、獲取數據集
sklearn數據集有有三種「獲取數據」的方式:
- sklearn.datasets.load_*():小規模數據集(本地加載)
- sklearn.datasets.fetch_*():大規模數據集(在線下載)
- sklearn.datasets.make_*():本地生成數據集(本地構造)
sklearn數據集的「返回值」是字典格式:
- data:特征值數據數組
- target:目標值數據數組(標簽)
- target_names:標簽名(目標值和標簽的對應關系)
- DESCR:數據描述
- feature_names:特征名
接下來,我們獲取一個自帶的本地數據集:
from sklearn import datasets# 獲取數據集
iris = datasets.load_iris()
# 打印數據集
print(iris)
輸出:
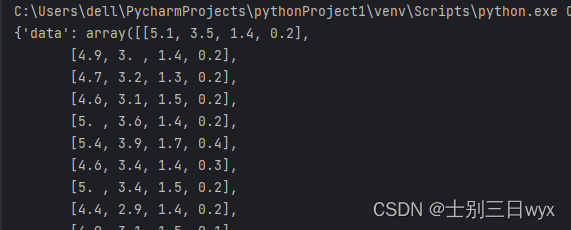
從輸出結果來看,它返回的數據集是一個字典,里面包含了特征值(data)、目標值(target)等信息。
我們可以調用返回值「屬性」,單獨查看數據集的某個信息:
from sklearn import datasets# 獲取數據集
iris = datasets.load_iris()# 查看數據值
print(iris.data)
# 查看目標值(標簽)
print(iris.target)
# 查看標簽名
print(iris.target_names)
# 查看數據描述
print(iris.DESCR)
# 查看特征名
print(iris.feature_names)
三、數據集劃分
數據集通常會劃分為兩個部分:
- 「訓練數據」:用于訓練,生成模型。
- 「測試數據」:用于檢驗,判斷模型是否有效。
sklearn.model_selection.train_test_split() 用來劃分數據集
參數:
- x:(必選)數組類型,數據集的特征值
- y:(必選)數組類型,數據集的目標值
- test_size:(可選,默認0.25)浮點型,測試集的大小
- random_state:(可選)整型,隨機數種子,不同的隨機數對應不同的采樣結果。
返回值:
- 訓練集特征值、測試集特征值、訓練集目標值、測試集目標值
接下來,我們對剛才獲取的本地數據集進行劃分,測試集大小不給值,就是默認的0.25,意思是25%當做測試數據、剩下的75%當做訓練數據。
from sklearn import datasets
from sklearn import model_selection# 獲取數據集
iris = datasets.load_iris()# 數據集的特征值
data_arr = iris.data
# 數據集的目標值(標簽)
target_arr = iris.targetx_data, y_data, x_target, y_target = model_selection.train_test_split(data_arr, target_arr)
print('訓練集特征值', x_data)
print('測試集特征值', y_data)
print('訓練集目標值', x_target)
print('測試集目標值', y_target)





)

_面向對象編程)







小白版)



