TiDB數據庫從入門到精通系列之六:使用 TiCDC 將 TiDB 的數據同步到 Apache Kafka
- 一、技術流程
- 二、搭建環境
- 三、創建Kafka changefeed
- 四、寫入數據以產生變更日志
- 五、配置 Flink 消費 Kafka 數據
一、技術流程
- 快速搭建 TiCDC 集群、Kafka 集群和 Flink 集群
- 創建 changefeed,將 TiDB 增量數據輸出至 Kafka
- 使用 go-tpc 寫入數據到上游 TiDB
- 使用 Kafka console consumer 觀察數據被寫入到指定的 Topic
- (可選)配置 Flink 集群消費 Kafka 內數據
二、搭建環境
部署包含 TiCDC 的 TiDB 集群
在實驗或測試環境中,可以使用 TiUP Playground 功能,快速部署 TiCDC,命令如下:
tiup playground --host 0.0.0.0 --db 1 --pd 1 --kv 1 --tiflash 0 --ticdc 1
# 查看集群狀態
tiup status
三、創建Kafka changefeed
1.創建 changefeed 配置文件
根據 Flink 的要求和規范,每張表的增量數據需要發送到獨立的 Topic 中,并且每個事件需要按照主鍵值分發 Partition。因此,需要創建一個名為 changefeed.conf 的配置文件,填寫如下內容:
[sink]
dispatchers = [
{matcher = ['*.*'], topic = "tidb_{schema}_{table}", partition="index-value"},
]
2.創建一個 changefeed,將增量數據輸出到 Kafka
tiup ctl:v<CLUSTER_VERSION> cdc changefeed
create --server="http://127.0.0.1:8300"
--sink-uri="kafka://127.0.0.1:9092/kafka-topic-name?protocol=canal-json"
--changefeed-id="kafka-changefeed"
--config="changefeed.conf"
如果命令執行成功,將會返回被創建的 changefeed 的相關信息,包含被創建的 changefeed 的 ID 以及相關信息,內容如下:
Create changefeed successfully!
ID: kafka-changefeed
Info: {... changfeed info json struct ...}
如果命令長時間沒有返回,你需要檢查當前執行命令所在服務器到 sink-uri 中指定的 Kafka 機器的網絡可達性,保證二者之間的網絡連接正常。
生產環境下 Kafka 集群通常有多個 broker 節點,你可以在 sink-uri 中配置多個 broker 的訪問地址,這有助于提升 changefeed 到 Kafka 集群訪問的穩定性,當部分被配置的 Kafka 節點故障的時候,changefeed 依舊可以正常工作。假設 Kafka 集群中有 3 個 broker 節點,地址分別為 127.0.0.1:9092 / 127.0.0.2:9092 / 127.0.0.3:9092,可以參考如下 sink-uri 創建 changefeed:
tiup ctl:v<CLUSTER_VERSION> cdc changefeed create
--server="http://127.0.0.1:8300"
--sink-uri="kafka://127.0.0.1:9092,127.0.0.2:9092,127.0.0.3:9092/kafka-topic-name?protocol=canal-json&partition-num=3&replication-factor=1&max-message-bytes=1048576"
--config="changefeed.conf"
3.Changefeed 創建成功后,執行如下命令,查看 changefeed 的狀態
tiup ctl:v<CLUSTER_VERSION> cdc changefeed list --server="http://127.0.0.1:8300"
四、寫入數據以產生變更日志
完成以上步驟后,TiCDC 會將上游 TiDB 的增量數據變更日志發送到 Kafka,下面對 TiDB 寫入數據,以產生增量數據變更日志。
1.模擬業務負載
在測試實驗環境下,可以使用 go-tpc 向上游 TiDB 集群寫入數據,以讓 TiDB 產生事件變更數據。如下命令,首先在上游 TiDB 創建名為 tpcc 的數據庫,然后使用 TiUP bench 寫入數據到這個數據庫中。
tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 4 prepare
tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 4 run --time 300s
2.消費 Kafka Topic 中的數據
changefeed 正常運行時,會向 Kafka Topic 寫入數據,你可以通過由 Kafka 提供的 kafka-console-consumer.sh,觀測到數據成功被寫入到 Kafka Topic 中:
./bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --from-beginning --topic `${topic-name}`
至此,TiDB 的增量數據變更日志就實時地復制到了 Kafka。下一步,你可以使用 Flink 消費 Kafka 數據。當然,你也可以自行開發適用于業務場景的 Kafka 消費端。
五、配置 Flink 消費 Kafka 數據
1.安裝 Flink Kafka Connector
在 Flink 生態中,Flink Kafka Connector 用于消費 Kafka 中的數據并輸出到 Flink 中。Flink Kafka Connector 并不是內建的,因此在 Flink 安裝完畢后,還需要將 Flink Kafka Connector 及其依賴項添加到 Flink 安裝目錄中。下載下列 jar 文件至 Flink 安裝目錄下的 lib 目錄中,如果你已經運行了 Flink 集群,請重啟集群以加載新的插件。
- flink-connector-kafka-1.17.1.jar
- flink-sql-connector-kafka-1.17.1.jar
- kafka-clients-3.5.1.jar
2.創建一個表
可以在 Flink 的安裝目錄執行如下命令,啟動 Flink SQL 交互式客戶端:
[root@flink flink-1.15.0]# ./bin/sql-client.sh
隨后,執行如下語句創建一個名為 tpcc_orders 的表:
CREATE TABLE tpcc_orders (o_id INTEGER,o_d_id INTEGER,o_w_id INTEGER,o_c_id INTEGER,o_entry_d STRING,o_carrier_id INTEGER,o_ol_cnt INTEGER,o_all_local INTEGER
) WITH (
'connector' = 'kafka',
'topic' = 'tidb_tpcc_orders',
'properties.bootstrap.servers' = '127.0.0.1:9092',
'properties.group.id' = 'testGroup',
'format' = 'canal-json',
'scan.startup.mode' = 'earliest-offset',
'properties.auto.offset.reset' = 'earliest'
)
請將 topic 和 properties.bootstrap.servers 參數替換為環境中的實際值。
3.查詢表內容
執行如下命令,查詢 tpcc_orders 表中的數據:
SELECT * FROM tpcc_orders;
執行成功后,可以觀察到有數據輸出,如下圖
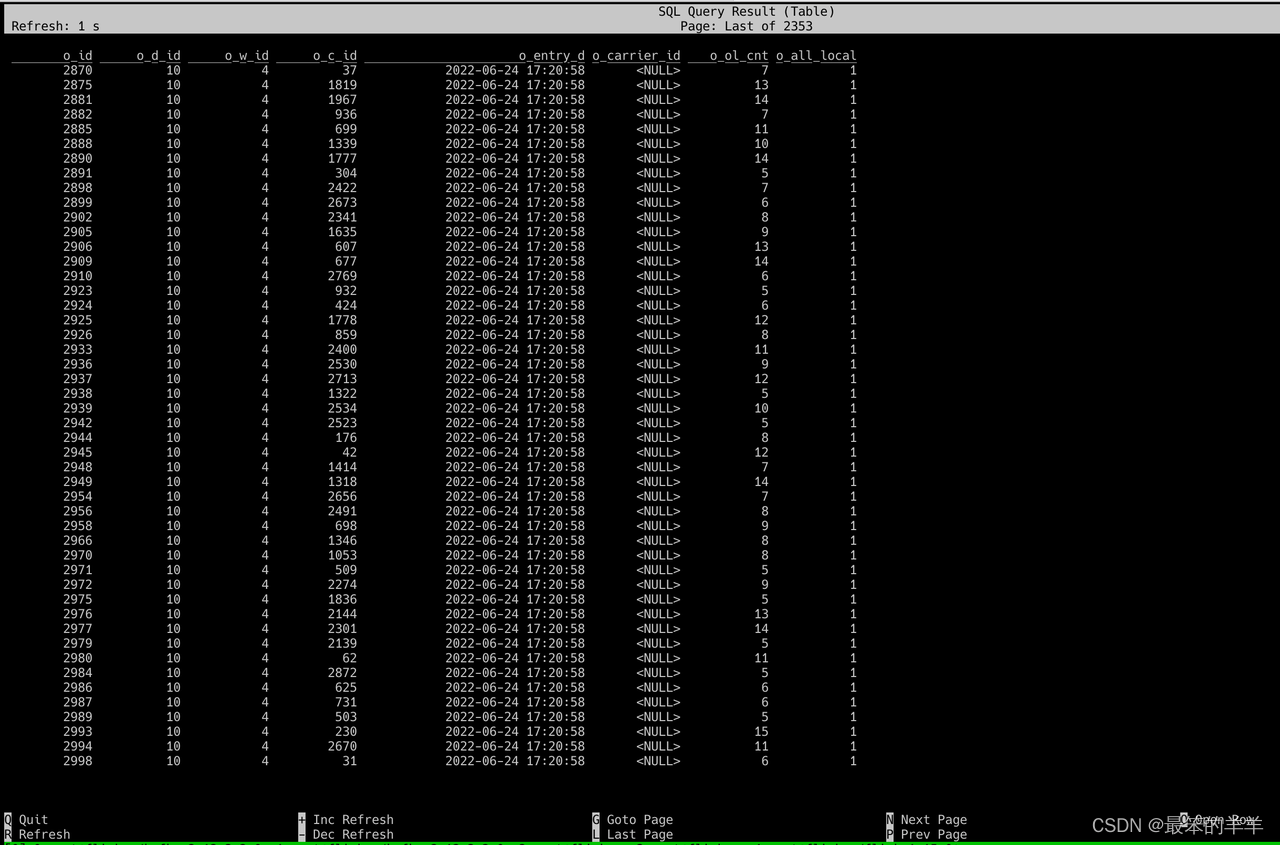
至此,就完成了 TiDB 與 Flink 的數據集成。


)

_面向對象編程)







小白版)






