http://www.scholarpedia.org/article/Kohonen_network
另一個很好的演示在這里
http://www.math.le.ac.uk/people/ag153/homepage/PCA_SOM/PCA_SOM.html
SOM
t是訓練步
一個輸入數據是n維向量

待訓練的是一堆節點,這堆節點之間有邊連著,通常是排成grid那樣的網狀結構
一個要訓練的節點包含一個n維向量

訓練從t=0開始,t=輸入數據個數時結束
每步的更新規則是
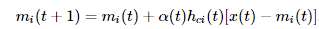
其中a(t)是一個隨訓練步數衰減的函數,c,i都是訓練節點的索引,c是離x(t)最近的節點的索引,hci是節點mc和mi的邊距離。也就是說每個訓練步選一個輸入數據x(t),將離它最近的節點mc向這個輸入數據拉扯,這個節點又透過連著的邊,帶動鄰近的節點向這個輸入數據移動。
Batch SOM
這樣輸入數據太多的時候會很慢,改進的方法稱為batch som。
方法是在每一步,對每個節點 mj,統計所有選中它為最近鄰的輸入數據的平均值,記為?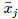 。
。
。再按下式更新每個節點的值。

nj是選了mj做最鄰近的輸入數據個數,hji是節點mi與節點mj的邊距離。可見對于節點mi,它會更新到鄰近所有節點mj對應的 的加權平均值。
的加權平均值。
的加權平均值。來自為知筆記(Wiz)
)


你可以這樣學)











工具(附帶視頻教程源碼)...)


)
