前言
本文的文字及圖片來源于網絡,僅供學習、交流使用,不具有任何商業用途,版權歸原作者所有,如有問題請及時聯系我們以作處理。
加入作者的python學習圈子:1156465813 即可免費獲取,資料全在群文件里。資料可以領取包括不限于Python實戰演練、PDF電子文檔、面試集錦、學習資料等
一、項目背景
在素材網想找到合適圖片需要一頁一頁往下翻,現在學會python就可以用程序把所有圖片保存下來,慢慢挑選合適的圖片。
二、項目目標
1、根據給定的網址獲取網頁源代碼。
2、利用正則表達式把源代碼中的圖片地址過濾出來。
3、過濾出來的圖片地址下載素材圖片。
三、涉及的庫和網站
1、網址如下:
https://www.51miz.com/2、涉及的庫:requests、lxml
四、項目分析
首先需要解決如何對下一頁的網址進行請求的問題。可以點擊下一頁的按鈕,觀察到網站的變化分別如下所示:
https://www.51miz.com/so-sucai/1789243.html
https://www.51miz.com/so-sucai/1789243/p_2/
https://www.51miz.com/so-sucai/1789243/p_3/我們可以發現圖片頁數是1789243/p{},p{}花括號數字表示圖片哪一頁。
五、項目實施
1、打開覓知網,在搜索中輸入你想要的圖片素材(以鼠年素材圖片為例)。
2、根據上一步對網址的分析,首先我們定義一個類叫做ImageSpider,類里面定義初始化函數、發送請求獲取響應數據函數、解析函數、主函數。首先初始化函數,準備url地址和headers,代碼如下圖所示。

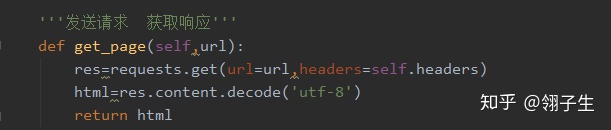
3、發送請求獲取相應數據函數。
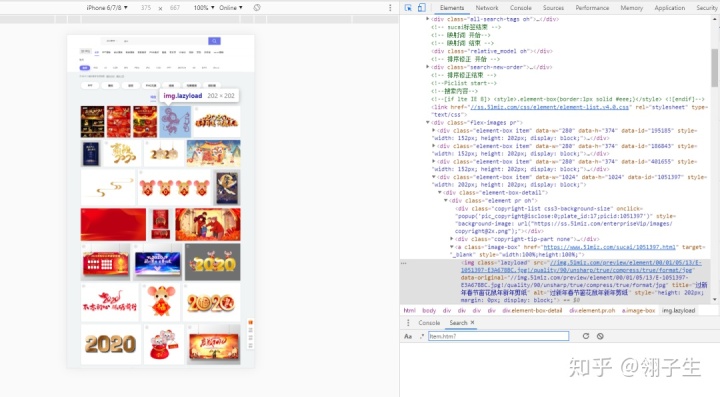
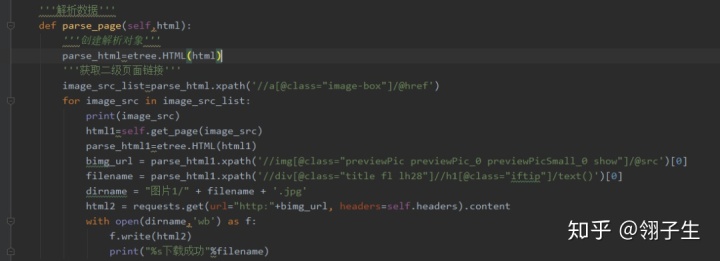
4、解析數據,使用xpath獲取二級頁面鏈接,最后把圖片存儲在文件夾中。使用谷歌瀏覽器選擇開發者工具或直接按F12,發現我們需要的圖片src是在img標簽下的,于是用Python的requests提取該組件。
5、主函數,代碼如下圖所示。
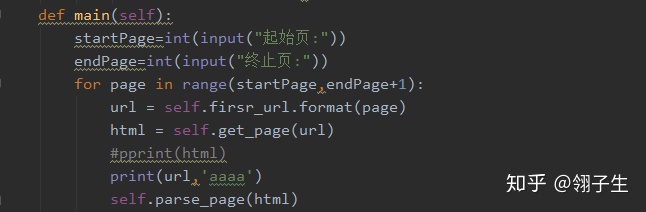
六、效果展示
1、運行程序,在控制臺輸入你要爬取的頁數,如下圖所示。
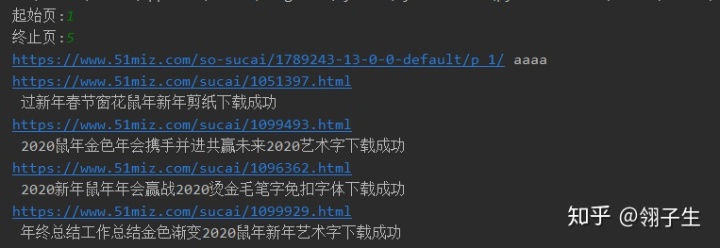
2、在本地可以看到效果圖,如下圖所示。

最后
如果你處于想學Python或者正在學習Python,Python的教程不少了吧,但是是最新的嗎?說不定你學了可能是兩年前人家就學過的內容,我來分享一波2020最新的Python教程。加入我的學習圈子:1156465813,就可以領取學習資料
單元測試)



)



)










