
作為最基礎的引用數據類型,Java 設計者為 String 提供了字符串常量池以提高其性能,那么字符串常量池的具體原理是什么,我們帶著以下三個問題,去理解字符串常量池:
- 字符串常量池的設計意圖是什么?
- 字符串常量池在哪里?
- 如何操作字符串常量池?
字符串常量池的設計思想
- 字符串的分配,和其他的對象分配一樣,耗費高昂的時間與空間代價,作為最基礎的數據類型,大量頻繁的創建字符串,極大程度地影響程序的性能
- JVM為了提高性能和減少內存開銷,在實例化字符串常量的時候進行了一些優化
- 為字符串開辟一個字符串常量池,類似于緩存區
- 創建字符串常量時,首先堅持字符串常量池是否存在該字符串
- 存在該字符串,返回引用實例,不存在,實例化該字符串并放入池中
- 實現的基礎
- 實現該優化的基礎是因為字符串是不可變的,可以不用擔心數據沖突進行共享
- 運行時實例創建的全局字符串常量池中有一個表,總是為池中每個唯一的字符串對象維護一個引用,這就意味著它們一直引用著字符串常量池中的對象,所以,在常量池中的這些字符串不會被垃圾收集器回收
代碼:從字符串常量池中獲取相應的字符串
String str1 = “hello”;String str2 = “hello”;System.out.printl("str1 == str2" : str1 == str2 ) //true 字符串常量池在哪里
在分析字符串常量池的位置時,首先了解一下堆、棧、方法區:
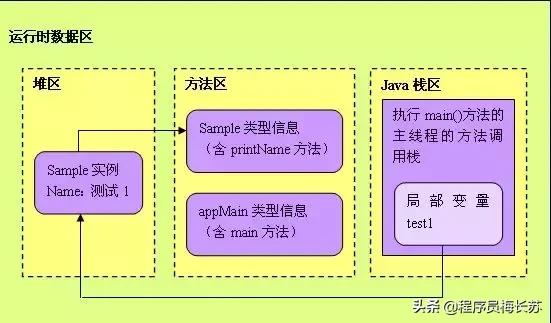
堆
存儲的是對象,每個對象都包含一個與之對應的class
JVM只有一個堆區(heap)被所有線程共享,堆中不存放基本類型和對象引用,只存放對象本身
對象的由垃圾回收器負責回收,因此大小和生命周期不需要確定
棧
每個線程包含一個棧區,棧中只保存基礎數據類型的對象和自定義對象的引用(不是對象)
每個棧中的數據(原始類型和對象引用)都是私有的
棧分為3個部分:基本類型變量區、執行環境上下文、操作指令區(存放操作指令)
數據大小和生命周期是可以確定的,當沒有引用指向數據時,這個數據就會自動消失
方法區
靜態區,跟堆一樣,被所有的線程共享
方法區中包含的都是在整個程序中永遠唯一的元素,如class,static變量
字符串常量池則存在于方法區
代碼:堆棧方法區存儲字符串
String str1 = “abc”;String str2 = “abc”;String str3 = “abc”;String str4 = new String(“abc”);String str5 = new String(“abc”);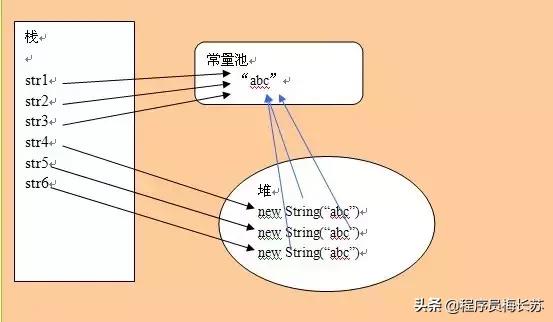
字符串對象的創建
面試題:String str4 = new String(“abc”) 創建多少個對象?
- 在常量池中查找是否有“abc”對象
- 有則返回對應的引用實例
- 沒有則創建對應的實例對象
- 在堆中 new 一個 String("abc") 對象
- 將對象地址賦值給str4,創建一個引用
所以,常量池中沒有“abc”字面量則創建兩個對象,否則創建一個對象,以及創建一個引用
根據字面量,往往會提出這樣的變式題:
String str1 = new String("A"+"B") ; 會創建多少個對象?
String str2 = new String("ABC") + "ABC" ; 會創建多少個對象?
str1:
字符串常量池:"A

)



)












)
