?
ZooKeeper特性
- 1. 全局數據一致:集群中每個服務器保存一份相同的數據副本,client 無論連接到哪個服務器,展示的數據都是一致的,這是最重要的特征。
- 2. 可靠性:如果消息被其中一臺服務器接受,那么將被所有的服務器接受。
- 3. 順序性:包括全局有序和偏序兩種:全局有序是指如果在一臺服務器上消息 a 在消息 b 前發布,則在所有 Server 上消息 a 都將在消息 b 前被發布;偏序是指如果一個消息 b 在消息 a后被同一個發送者發布,a 必將排在 b 前面。
- 4. 數據更新原子性:一次數據更新要么成功(半數以上節點成功),要么失敗,不存在中間狀態。
- 5. 實時性:Zookeeper 保證客戶端將在一個時間間隔范圍內獲得服務器的更新信息,或者服務器失效的信息。
?
ZooKeeper集群的角色
Leader:
Zookeeper 集群工作的核心,事務請求(寫操作)的唯一調度和處理者,保證集群事務處理的順序性;集群內部各個服務器的調度者。對于 create,setData,delete 等有寫操作的請求,則需要統一轉發給leader 處理,leader 需要決定編號、執行操作,這個過程稱為一個事務。
Follower:
處理客戶端非事務(讀操作)請求,轉發事務請求給 Leader;參與集群 Leader 選舉投票。
?
此外,針對訪問量比較大的 zookeeper 集群,還可新增觀察者角色。
Observer:
觀察者角色,觀察 Zookeeper 集群的最新狀態變化并將這些狀態同步過來,其對于非事務請求可以進行獨立處理,對于事務請求,則會轉發給 Leader服務器進行處理。不會參與任何形式的投票只提供非事務服務,通常用于在不影響集群事務處理能力的前提下提升集群的非事務處理能力。
?
主要用來管理solr集群中的相關配置信息和集群的運行狀態, 協助solr進行主節點的選舉。
?
準備:zookeeper的安裝包? 三臺linux虛擬機? 虛擬機的安裝
修改三臺虛擬機的hosts文件:vi /etc/hosts
添加如下內容:
192.168.44.28 node-01
192.168.44.29 node-02
192.168.44.30 node-03
注意: 添加時, 前面ip地址一定是自己的三臺linux的ip地址 切記不要搞錯了 cd /export/software/
rz #此時選擇zookeeper的壓縮包進行上傳 tar -zxf zookeeper-3.4.9.tar.gz -C /export/servers/
cd /export/servers/ cd /export/servers/zookeeper-3.4.9/conf
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg 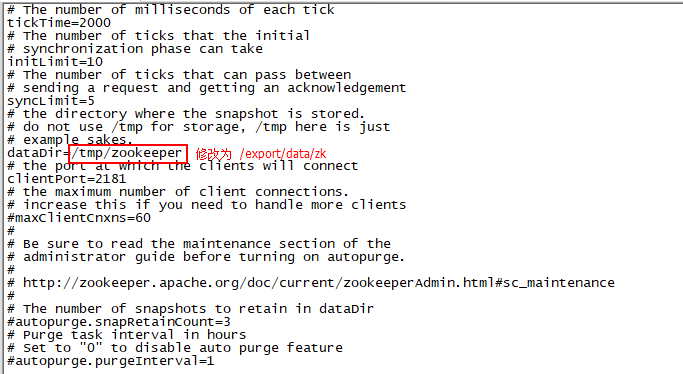
修改后, 在配置文件的底部, 添加如下內容
server.1=node-01:2888:3888
server.2=node-02:2888:3888
server.3=node-03:2888:3888 更改后配置文件整體內容如下:(如果擔心修改錯誤, 可以直接將zoo.cfg中的內容全部刪除, 復制以下內容即可)
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/export/data/zk
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1#zookeeper集群配置
server.1=node-01:2888:3888
server.2=node-02:2888:3888
server.3=node-03:2888:3888 cd /export/servers/
scp -r zookeeper-3.4.9/ root@node-02:$PWD //將zookeeper復制到node-02的同級目錄下
scp -r zookeeper-3.4.9/ root@node-03:$PWD //將zookeeper復制到node-03的同級目錄下 
發送完成后,在其他兩臺主機查看, 是否已經成功接收到
cd /export/servers
ll node-01:執行的命令
mkdir -p /export/data/zk //這個路徑和上面修改配置文件dataDir一致
echo "1" > /export/data/zk/myid
cat /export/data/zk/myid //此命令用于查看此文件有沒有正確寫入 1node-02:執行的命令
mkdir -p /export/data/zk
echo "2" > /export/data/zk/myid
cat /export/data/zk/myid //此命令用于查看此文件有沒有正確寫入 2node-03:執行的命令
mkdir -p /export/data/zk
echo "3" > /export/data/zk/myid
cat /export/data/zk/myid //此命令用于查看此文件有沒有正確寫入 3 cd /export/servers/zookeeper-3.4.9/bin/
./zkServer.sh start 一個leader 其余的為follower



?
1. 當第一臺(id=1),啟動后, 由于目前自有自己,故會把票投給自己
2. 當第二臺(id=2),啟動后, 由于目前已經又二臺啟動, 這時候會將票投給id最大的機器, 此時三臺中已經有二臺啟動, 數量過半, 第二臺理所應當的成為了leader
3. 當第三臺(id=3),啟動后, 雖然id=3為最大, 但是由于leader已經產生, 故只能擔任follower 當下一次在重新啟動時, 又會恢復選舉,此時誰的數據多, 誰為leader, 如果數據都一樣, 那么看id誰最大,同時一般選舉過半,就會產生leader
?
還有一種選舉方式是非全新集群選舉:
對于運行正常的 zookeeper 集群,中途有機器 down 掉,需要重新選舉時,選舉過程就需要加入數據 ID、服務器 ID 和邏輯時鐘。 數據 ID:數據新的 version 就大,數據每次更新都會更新 version。 服務器 ID:就是我們配置的 myid 中的值,每個機器一個。 邏輯時鐘:這個值從 0 開始遞增,每次選舉對應一個值。 如果在同一次選舉中,這個值是一致的。 這樣選舉的標準就變成: 1、邏輯時鐘小的選舉結果被忽略,重新投票; 2、統一邏輯時鐘后,數據 id 大的勝出; 3、數據 id 相同的情況下,服務器 id 大的勝出; 根據這個規則選出 leader。
?
?


)













![漢諾塔問題遞歸算法python代碼_[python]漢諾塔問題遞歸實現](http://pic.xiahunao.cn/漢諾塔問題遞歸算法python代碼_[python]漢諾塔問題遞歸實現)


