1.處理缺失值數據
使用dropna()時,注意里面參數axis、how、thresh的用法
使用fillna()時,注意里面參數value、method、inplace、limit的用法

2.數據轉換
去重
data.drop_duplicates(keep='last')#注意keep的用法映射
map()針對的是一維數組series,后面跟函數表示對整個一維數組執行的操作
apply()在針對一維數組時作用與map相同,在針對DataFrame數組時是對某一行或某一列進行操作,輸出的是一列或一行的結果
applymap()是針對DataFrame的整個數據的操作
替換值
replace()
重命名軸索引
rename()注意rename對列名的修改,后面跟上字典實現
astype()轉換數據類型
離散化和面元劃分
cats=pd.cut(data,bins,right=False,labels=name)#按照bins里面的區間,把data數據集里面的數據劃分到不同的區間,實現離散化,right修改閉端位置
pd.cut(data,4,precision=2)#傳入數字則根據數據分位數進行幾等分,precision保留小數個數
pd.value_counts(cats)#劃分結果計數
pd.qcut()檢測和過濾異常值
data.describe()#數據現行,無處可逃
data[2][np.abs(data[2])>3]#選出2這一列中絕對值大于3的數
data[(np.abs(data)>3).any(1)]#選出絕對值大于3的數所在的行
np.sign(data)#根據數值的正負生成1或-1排列和隨機采樣
sampler=np.random.permutation(5)
df.take(sampler)
#實現對df的重新排列,相當于按軸索引隨機排列計算指標、啞變量
get_dummies()#沒看太懂,研究中3.字符串的操作
val.split(',')#把字符串val按‘,’分成數段
pieces=[x.strip() for x in val.split(',')]#可去除空格和換行
'::'.join(pieces)#拼接
val.index('a') val.find('a')#查找字符串
val.count('a')#統計出現次數
val.replace()#替換
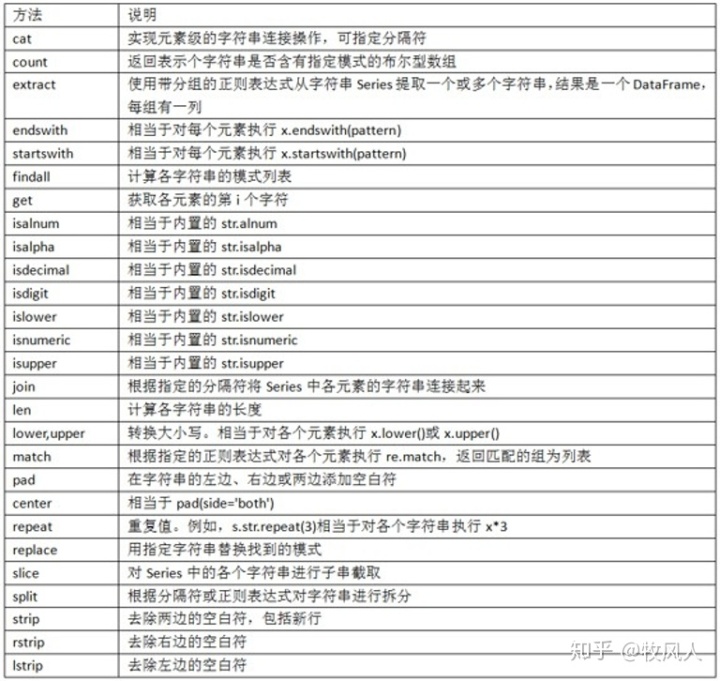
還有一些關于正則表達式的方法

矢量化字符串的方法
4.連接數據
橫向連接
pd.mager(data1,data2,on='key',how='left')#jion也可以實現

軸向連接
pd.concat()
5.重塑
stack:將數據的列旋轉成行
unstack:將數據的行旋轉成列
pivot與melt也互為相反操作,作用類似
6.時間序列

datetime.strptime可以?這些格式化編碼將字符串轉換為?期:


)


)






)

)





)