目錄
- 一、引言
- 1.1 計算機視覺的定義
- 1.1.1 核心技術
- 1.1.2 應用場景
- 1.2 歷史背景及發展
- 1.2.1 1960s-1980s: 初期階段
- 1.2.2 1990s-2000s: 機器學習時代
- 1.2.3 2010s-現在: 深度學習的革命
- 1.3 應用領域概覽
- 1.3.1 工業自動化
- 1.3.2 醫療圖像分析
- 1.3.3 自動駕駛
- 1.3.4 虛擬現實與增強現實
- 二、計算機視覺五大核心任務
- 2.1 圖像分類與識別
- 2.1.1 圖像分類與識別的基本概念
- 2.1.2 早期方法與技術演進
- 2.1.3 深度學習的引入與革新
- 卷積神經網絡在圖像分類中的應用
- 總結
- 2.2 物體檢測與分割
- 2.2.1 物體檢測
- 早期方法
- 深度學習方法
- 2.2.2 物體分割
- 語義分割
- 實例分割
- 總結
- 2.3 人體分析
- 2.3.1 人臉識別
- 2.3.2 人體姿態估計
- 2.3.3 動作識別
- 2.3.4 人體分割
- 2.4 三維計算機視覺
- 2.4.1 三維重建
- 立體視覺
- 多視圖幾何
- 點云生成和融合
- 2.4.2 3D物體檢測和識別
- 基于2D圖像的方法
- 基于點云的方法
- 2.4.3 三維語義分割
- 基于體素的方法
- 基于點云的方法
- 2.4.4 三維姿態估計
- 單視圖方法
- 多視圖方法
- 總結
- 2.5 視頻理解與分析
- 2.5.1 視頻分類
- 2.5.2 動作識別
- 2.5.3 視頻物體檢測與分割
- 2.5.4 視頻摘要與高亮檢測
- 2.5.5 視頻生成和編輯
- 總結
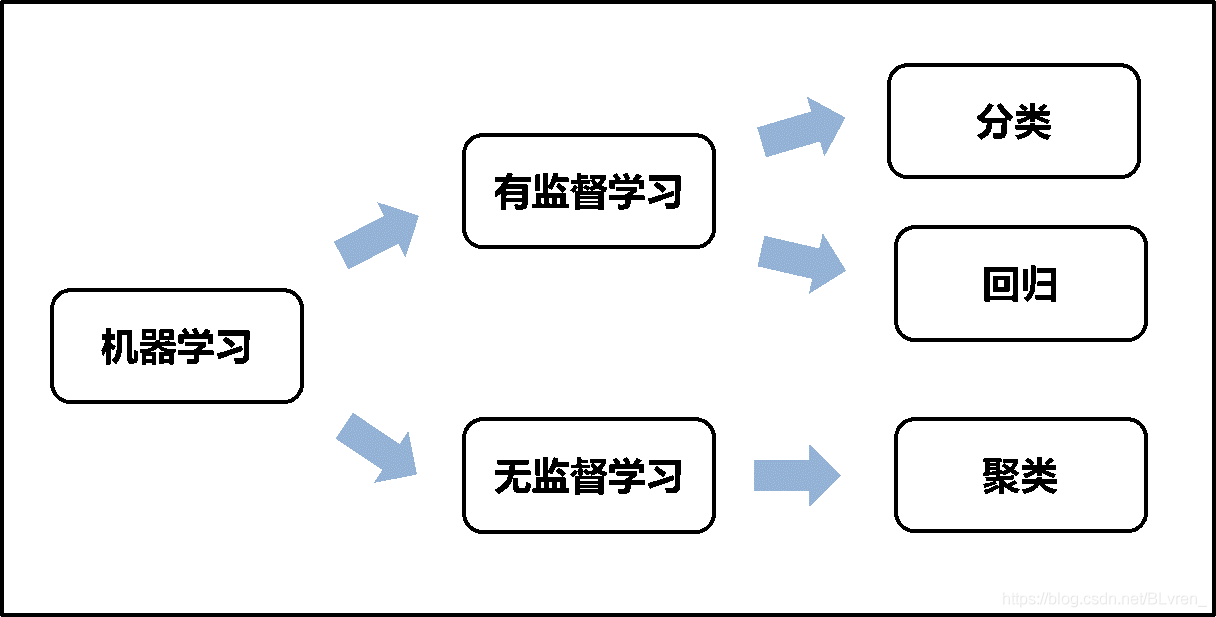
- 三、無監督學習與自監督學習在計算機視覺中的應用
- 3.1 無監督學習
- 聚類
- 降維與表示學習
- 3.2 自監督學習
- 對比學習
- 預訓練任務設計
- 3.3 跨模態學習
- 4. 總結
本篇文章深入探討了計算視覺的定義和主要任務。內容涵蓋了圖像分類與識別、物體檢測與分割、人體分析、三維計算機視覺、視頻理解與分析等技術,最后展示了無監督學習與自監督學習在計算機視覺中的應用。
作者 TechLead,擁有10+年互聯網服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智能實驗室成員,阿里云認證的資深架構師,項目管理專業人士,上億營收AI產品研發負責人
一、引言
計算機視覺(Computer Vision)是一門將人類的視覺能力賦予機器的學科。它涵蓋了圖像識別、圖像處理、模式識別等多個方向,并已成為人工智能研究的重要組成部分。本文將詳細介紹計算機視覺的定義、歷史背景及發展、和當前的應用領域概覽。

1.1 計算機視覺的定義
計算機視覺不僅是一門研究如何使機器理解和解釋視覺世界的科學,更是一種追求讓機器擁有與人類相近視覺處理能力的技術。它通過分析數字圖像和視頻,使得機器能夠識別、追蹤和理解現實世界中的對象和場景。此外,計算機視覺還包括圖像恢復、三維重構等深入的研究方向。
1.1.1 核心技術
核心技術包括但不限于特征提取、目標檢測、圖像分割、3D重建等,通過多個技術的結合實現更為復雜的視覺任務。
1.1.2 應用場景
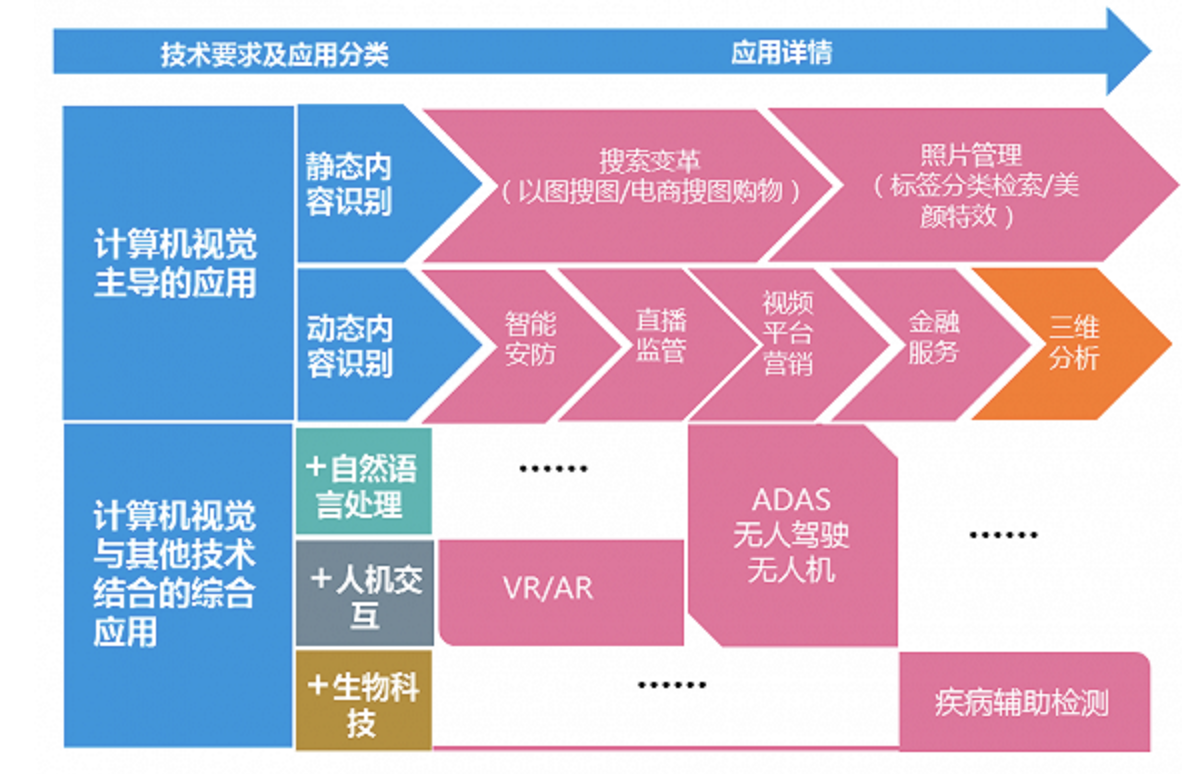
計算機視覺被廣泛應用于自動駕駛、醫療診斷、智能監控等眾多領域,推動了相關產業的快速發展。
1.2 歷史背景及發展
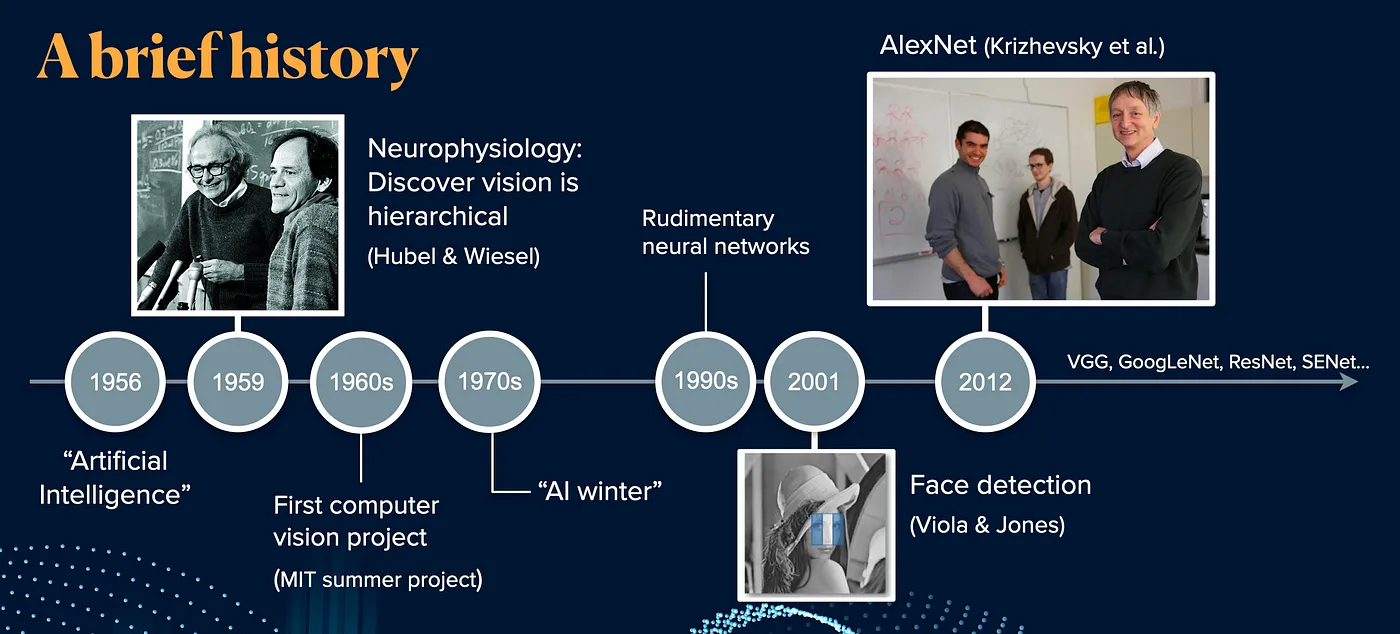
計算機視覺的發展歷程豐富多彩,從上世紀60年代初步探索到如今的深度學習技術革命,可以分為以下幾個主要階段:
1.2.1 1960s-1980s: 初期階段
- 圖像處理: 主要關注簡單的圖像處理和特征工程,例如邊緣檢測、紋理識別等。
- 模式識別: 諸如手寫數字識別等初級任務的實現。
1.2.2 1990s-2000s: 機器學習時代
- 特征學習: 通過機器學習方法使得特征學習和對象識別變得更加復雜和強大。
- 支持向量機和隨機森林的應用: 提供了新的解決方案。
1.2.3 2010s-現在: 深度學習的革命
- 卷積神經網絡: CNN的廣泛應用為計算機視覺帶來了突破性進展。
- 遷移學習和強化學習的結合: 在計算機視覺任務上獲得了重大進展。
1.3 應用領域概覽
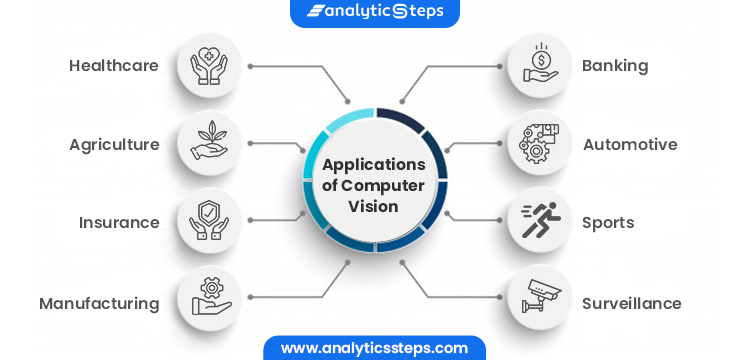
計算機視覺已經滲透到了許多行業,其應用不僅僅局限于科技領域,更廣泛地影響了我們的日常生活。
1.3.1 工業自動化
利用圖像識別技術,自動化地進行產品質量檢測、分類,提高了生產效率和精確度。
1.3.2 醫療圖像分析
計算機視覺結合深度學習進行疾病診斷和預測,改變了傳統醫療方式。
1.3.3 自動駕駛
計算機視覺在自動駕駛中起到關鍵作用,實時分析周圍環境,為車輛路徑規劃和決策提供準確信息。
1.3.4 虛擬現實與增強現實
通過計算機視覺技術創建沉浸式的虛擬環境,為娛樂和教育等領域提供了全新的體驗方式。
二、計算機視覺五大核心任務
當然,技術深度和內容的豐富性是非常重要的。以下是針對所提供內容的改進版本:
2.1 圖像分類與識別
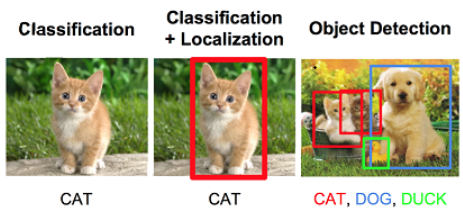
圖像分類與識別是計算機視覺的核心任務之一,涉及將輸入的圖像或視頻幀分配到一個或多個預定義的類別中。本章節將深入探討這一任務的關鍵概念、技術演進、最新的研究成果,以及未來可能的發展方向。
2.1.1 圖像分類與識別的基本概念
圖像分類是將圖像分配到某個特定類別的任務,而圖像識別則進一步將類別關聯到具體的實體或對象。例如,分類任務可能會識別圖像中是否存在貓,而識別任務會區分不同種類的貓,從寵物貓到野生豹子的區分。
2.1.2 早期方法與技術演進
早期的圖像分類與識別方法重依賴于手工設計的特征和統計機器學習算法。這些方法的發展歷程包括:
- 特征提取: 采用如 SIFT、HOG等特征來捕捉圖像的局部信息。
- 分類器的應用: 利用SVM、決策樹等分類器進行圖像的分級。
然而,這些方法在許多實際應用中的性能受限,因為特征工程的復雜性和泛化能力的限制。
2.1.3 深度學習的引入與革新
隨著深度學習的出現,圖像分類與識別取得了顯著的進展。尤其是卷積神經網絡(CNN)的引入,為領域內的研究和實際應用帶來了革命性的改變。
卷積神經網絡在圖像分類中的應用
卷積神經網絡通過層疊的卷積層、池化層和全連接層來自動學習圖像特征,消除了手工設計特征的需要。下面是一個簡單的CNN結構示例:
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense# 定義模型
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(1, activation='sigmoid'))# 輸出模型結構
model.summary()
總結
圖像分類與識別作為計算機視覺的基石,其技術演進完美地反映了整個領域的快速進展。從手工設計的特征到復雜的深度學習模型,該領域不僅展示了計算機視覺的強大能力,還為未來的創新和發展奠定了堅實的基礎。隨著更先進的算法和硬件的發展,我們期待未來圖像分類與識別能夠在更多場景中發揮作用,滿足人們日益增長的需求。
2.2 物體檢測與分割
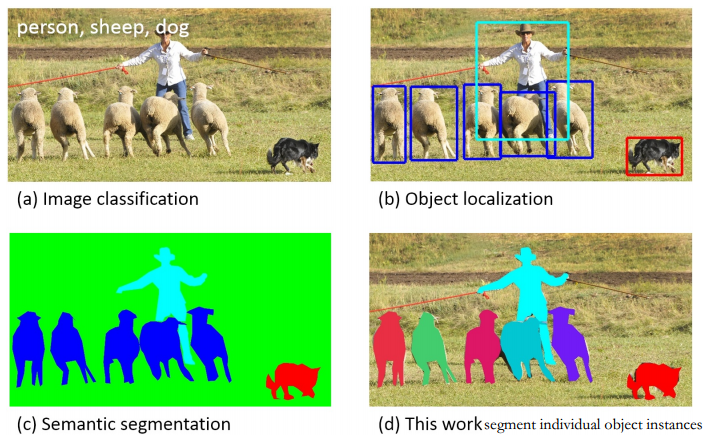
物體檢測與分割在計算機視覺中具有核心地位,它不僅是關于識別圖像中的物體,更關乎精確定位和分割這些物體。該領域涉及的挑戰從基礎的圖像處理到復雜的深度學習方法都有。本章節將深入探討物體檢測與分割的關鍵概念、主流方法和最新進展。
2.2.1 物體檢測
物體檢測不僅要求識別圖像中的對象,還要精確確定其位置和類別。它的應用包括人臉識別、交通分析、產品質檢等。
早期方法
早期的物體檢測方法主要依賴于手工特征和傳統機器學習方法。
- 滑動窗口: 結合手工特征如HOG,通過滑動窗口的方式在多個尺度和位置尋找對象。
- SVM分類器: 通常與滑動窗口相結合,使用SVM分類器進行物體分類。
深度學習方法
深度學習技術的出現極大地推動了物體檢測領域的進展。
- R-CNN系列: 從R-CNN到Faster R-CNN,逐漸演進,實現了對物體的精確檢測,特別是在使用區域提議網絡(RPN)和ROI池化方面的創新。
- YOLO: YOLO(You Only Look Once)以其一次前向傳播的實時檢測能力而受到關注。
- SSD: SSD(Single Shot Multibox Detector)通過多尺度特征圖來檢測不同大小的對象,也具備實時檢測的優勢。
# 使用YOLO進行物體檢測的代碼示例
from yolov3.utils import detect_imageimage_path = "path/to/image.jpg"
output_path = "path/to/output.jpg"
detect_image(image_path, output_path)
# 輸出圖片包括檢測到的物體的邊界框
2.2.2 物體分割
物體分割任務則更為細致,涉及到像素級別的對象分析。
語義分割
語義分割旨在將圖像中每個像素分配給一個特定的類別,不區分同一類別的不同實例。
- FCN: FCN(全卷積網絡)是語義分割的開創性工作之一。
- U-Net: U-Net通過對稱的編碼器和解碼器結構,實現了精確的醫學圖像分割。
實例分割
實例分割則進一步區分同一類別的不同對象實例。
- Mask R-CNN: Mask R-CNN在Faster R-CNN基礎上增加了對象掩碼生成分支,實現了實例分割。
總結
物體檢測與分割結合了圖像處理、機器學習和深度學習的多個方面,是計算機視覺中的復雜和多面任務。其在自動駕駛、醫療診斷、智能監控等領域有著廣泛的應用。未來的研究將更多聚焦于多模態信息融合、少樣本學習、實時高精度檢測等前沿挑戰,持續推動該領域的創新和發展。
2.3 人體分析

人體分析是計算機視覺中一個重要且活躍的研究領域,涵蓋了對人體的識別、檢測、分割、姿態估計和動作識別等多方面任務。人體分析的研究和應用在許多領域都有深遠的影響,包括安全監控、醫療健康、娛樂、虛擬現實等。
2.3.1 人臉識別
人臉識別不僅是定位圖像中人臉的技術,還涉及了人臉的驗證和識別。
- 人臉檢測: 通過使用如Haar級聯等算法,精確地定位圖像中的人臉位置。
- 人臉驗證和識別: 應用深度學習方法,例如FaceNet,以判斷兩張人臉是否屬于同一個人,或從大型數據庫中找到匹配的人臉。
2.3.2 人體姿態估計
人體姿態估計涉及了識別人體的關鍵關節位置和整體姿態,它在運動分析、健康監測等領域有著重要應用。
- 單人姿態估計: 通過識別單個人體的關鍵關節,例如使用OpenPose等方法。
- 多人姿態估計: 針對復雜場景,可同時識別多個人體的關鍵關節。
# 使用OpenPose估計人體姿態的代碼示例
import cv2
body_model = cv2.dnn.readNetFromTensorflow("path/to/model")
image = cv2.imread("path/to/image.jpg")
body_model.setInput(cv2.dnn.blobFromImage(image))
points = body_model.forward()
# points中包括了人體的關鍵關節信息
2.3.3 動作識別
動作識別從圖像或視頻中識別特定的人體動作或行為。
- 基于序列的方法: 使用RNN或LSTM分析一系列圖像,以捕捉動作的時序特點。
- 基于三維卷積的方法: 利用3D CNN分析視頻中的時空特征,獲取更豐富的動作信息。
2.3.4 人體分割
人體分割是從背景和其他對象中分離人體的技術。
- 語義分割: 將整個人體與背景分開,無需區分個體。
- 實例分割: 進一步區分不同的人體實例,適用于
2.4 三維計算機視覺
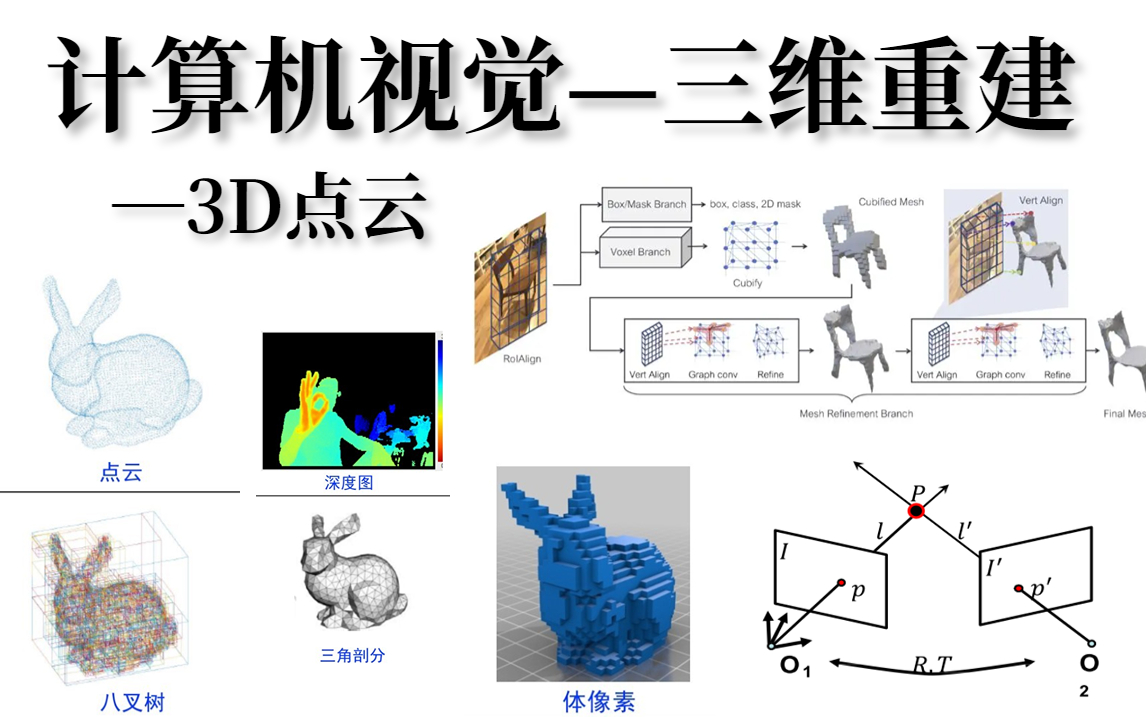
三維計算機視覺不僅是一個令人興奮的研究領域,也為許多實際應用提供了基礎,包括虛擬現實(VR)、增強現實(AR)、3D建模、機器人導航等。本章節將深入探討三維計算機視覺的主要概念和方法。
2.4.1 三維重建
三維重建是從一組二維圖像中重建出三維場景的過程。這個過程涉及多個復雜的技術和算法。
立體視覺
立體視覺是通過比較來自兩個或多個相機的圖像,以估計場景的深度信息。這為進一步的3D重建提供了基礎。
多視圖幾何
多視圖幾何是一種利用多個視圖的幾何關系來重建三維結構的方法。通過對極幾何和三角測量的應用,可以實現精確的三維重建。
點云生成和融合
點云生成和融合方法如SLAM(同時定位和映射)技術,可以從多視角圖像生成精確的三維結構。
2.4.2 3D物體檢測和識別
3D物體檢測和識別不僅涉及識別物體的類別,還確定其在三維空間中的方位和姿態。
基于2D圖像的方法
這些方法利用2D圖像和深度信息進行3D推理,例如使用3D CNN來識別和定位3D對象。
基于點云的方法
一些先進的方法,如PointNet,直接處理三維點云數據,可以在更復雜的場景中實現精確檢測和識別。
2.4.3 三維語義分割
三維語義分割涉及將3D場景分割成有意義的部分,并為每個部分分配語義標簽。
基于體素的方法
如3D U-Net,這些方法將3D空間劃分為體素并進行分割,提供了強大的三維分割能力。
基于點云的方法
基于點云的方法,如PointNet,能夠直接處理點云數據,實現精確的三維語義分割。
2.4.4 三維姿態估計
三維姿態估計涉及估計物體在三維空間中的位置和方向。
單視圖方法
從單個圖像估計3D姿態,雖然挑戰較大,但在一些特定應用中足夠有效。
多視圖方法
結合多個視角的信息進行精確估計,為許多先進的三維視覺任務提供了關鍵技術。
總結
三維計算機視覺是一門充滿挑戰和機遇的領域。從基礎的三維重建到復雜的3D物體識別和語義分割,這個領域的研究對許多先進技術和應用產生了深遠影響。隨著硬件和算法的不斷進步,三維計算機視覺將繼續推動許多前沿技術的發展,如自動駕駛、智能城市建設、虛擬與增強現實等。未來,我們可以期待這一領域將產生更多創新和突破。
2.5 視頻理解與分析

視頻理解與分析是計算機視覺的一個重要分支,不僅涉及對視頻內容的識別和解釋,還包括時空結構的推理。相比單一的圖像分析,視頻分析更能深入挖掘視覺信息的連續性和內在聯系,從而開拓了計算機視覺的新領域。
2.5.1 視頻分類
視頻分類的目的是識別和標記視頻的整體內容,它可以進一步細分為不同的任務。
- 短片分類: 主要關注視頻中的特定活動或場景,如識別動作、表情等。該任務廣泛應用于社交媒體內容分析、廣告推薦等。
- 長片分類: 針對整部電影或電視劇進行分析,可能涉及情感、風格、主題等多方面的識別。此項技術可用于推薦系統、內容審查等。
2.5.2 動作識別
動作識別是從視頻中捕捉特定動作或行為的過程。
- 基于2D卷積的方法: 通過捕捉時間維度上的連續性,例如使用C3D模型,適用于短時間的動作識別。
- 基于3D卷積的方法: 如I3D模型,更好地捕捉時空信息,用于更復雜的場景。
# 使用I3D模型進行動作識別的代碼示例
import tensorflow as tf
i3d_model = tf.keras.applications.Inception3D(include_top=True, weights='imagenet')
video_input = tf.random.normal([1, 64, 224, 224, 3]) # 隨機輸入
predictions = i3d_model(video_input)
# 輸出預測結果
print(predictions)
2.5.3 視頻物體檢測與分割
視頻物體檢測與分割集合了物體的檢測、跟蹤和分割技術。
- 物體檢測: 通過時序分析,結合方法如Faster R-CNN與光流,能夠在視頻序列中精確定位物體。
- 實例分割: 更細致地在視頻中對單個實例進行分割,應用場景包括醫學影像、智能監控等。
2.5.4 視頻摘要與高亮檢測
視頻摘要與高亮檢測的目的是從大量視頻數據中提取關鍵信息。
- 基于關鍵幀的方法: 選擇具有代表性的幀作為摘要,用于快速瀏覽或索引。
- 基于學習的方法: 如使用強化學習選擇精彩片段,應用于自動生成比賽精彩時刻回放等。
2.5.5 視頻生成和編輯
視頻生成和編輯涉及更高層次的創造和定制。
- 視頻風格轉換: 通過神經風格遷移技術,可實現不同風格的轉換。
- 內容生成: 例如使用GANs技術,能夠合成全新的視頻內容,為藝術創作、娛樂產業提供了新的可能性。
總結
視頻理解與分析作為一個多維度、多層次的領域,不僅推動了媒體和娛樂技術的進步,還在監控、醫療、教育等多個方向展現出廣泛的實用價值。它的研究涉及圖像分析、時空建模、機器學習等多個方面的交叉與融合。隨著技術的不斷發展和深入,未來的視頻理解預計將實現更精確、更智能、更自動化的水平,為人們的生活和工作提供更廣闊的便利和可能。
三、無監督學習與自監督學習在計算機視覺中的應用
無監督學習和自監督學習在計算機視覺中的應用是目前的熱門研究方向。與有監督學習相比,這些方法不需要昂貴且耗時的標注過程,具有巨大的潛力。下面將深入探討這兩種學習方法在視覺中的主要應用。
3.1 無監督學習
聚類
無監督學習中的聚類任務關注如何將相似的數據分組。
- 圖像聚類: 如使用K-means算法,可以通過顏色、紋理等特性對圖像進行分組,用于圖像檢索和分類。
- 深度聚類: 如DeepCluster,通過深度學習提取的特征進行聚類,能夠捕捉更復雜的模式。
降維與表示學習
降維和表示學習可以揭示數據的內在結構。
- 主成分分析(PCA): PCA是一種常用的圖像降維方法,有助于去除噪聲,更好地理解圖像的主要成分。
- 自編碼器(AE): 自編碼器能夠學習數據的壓縮表示,常用于圖像去噪、壓縮等任務。
3.2 自監督學習
自監督學習通過數據的一部分來預測其余部分,在無監督的環境中進行訓練,涵蓋了多種訓練任務。
對比學習
對比學習通過比較正例和負例來學習數據的表示。
- SimCLR: SimCLR通過比較正例和負例學習特征表示。
# SimCLR的代碼示例
from models import SimCLR
model = SimCLR(base_encoder)
loss = model.contrastive_loss(features) # 對比損失
- MoCo: MoCo使用隊列和動量編碼器進行更穩健的對比學習,有助于訓練更準確的模型。
預訓練任務設計
- 預測顏色: 通過灰度圖像預測原始顏色,有助于理解圖像的顏色構成。
- 自回歸預測: 如使用PixelCNN預測圖像下一個像素的值,增強對圖像生成的掌控力。
3.3 跨模態學習
- 圖像與文本匹配: 如使用CLIP同時學習視覺和文本表示,推動了多模態的研究進展。
- 音頻與圖像匹配: 無監督的方法在音頻和圖像之間建立關聯,開拓了多媒體分析的新領域。
4. 總結
無監督學習與自監督學習打開了一條不依賴昂貴標注的新路徑。通過豐富的方法,如聚類、對比學習、自回歸預測等,這一領域在計算機視覺中的應用日益廣泛。最新的研究展示了自監督學習在視覺表征學習方面與有監督方法越來越接近甚至超越的能力,暗示了未來可能的研究方向和廣泛的應用場景。
作者 TechLead,擁有10+年互聯網服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智能實驗室成員,阿里云認證的資深架構師,項目管理專業人士,上億營收AI產品研發負責人


)


函數)
大數據實戰——安裝使用mysql版的hive服務)

 —— React17+React Hook+TS4 最佳實踐,仿 Jira 企業級項目(二十三))
)

)







