一、說明
隨著HBase在重要的商業系統中應用的大量增加,許多企業需要通過對它們的HBase集群建立健壯的備份和故障恢復機制來保證它們的企業(數據)資產。備份Hbase時的難點是其待備份的數據集可能非常巨大,因此備份方案必須有很高的效率。Hbase備份方案必須既能夠伸縮至對數百TB的存儲容量進行備份,又能夠在一個合理的時間內完成數據恢復的工作。HBase和Apache Hadoop系統提供了許多內置的機制,可以快速而輕松的完成PB級數據的備份和恢復工作。
二、方法
HBase是一個基于LSM樹(log-structured merge-tree)的分布式數據存儲系統,它使用復雜的內部機制確保數據準確性、一致性、多版本等。因此,你如何獲取數十個region server在HDFS和內存中的存儲的眾多HFile文件、WALs(Write-Ahead-Logs)的一致的數據備份?
讓我們從最小的破壞性,最小的數據占用空間,最小的性能要求機制和工作方式到最具破壞性的逐一講述:
- Snapshots
- Replication
- Export
- CopyTable
- HTable API
- Offline backup of HDFS data
下面的表格提供了一個關于這些方法的快速比較,具體的細節在下面再詳細描述。

Snapshots(快照)
HBase快照功能豐富,有很多特征,并且創建時不需要關閉集群。關于snapshot在文章《apache hbase snapshot介紹》中有更詳細的介紹。
快照能通過在HDFS中創建一個和unix硬鏈接相同的存儲文件,簡單捕捉你的hbase表的某一時刻的信息(如下圖)。這些快照在幾秒內就可以完成,幾乎對整個集群沒有任何性能影響。并且,它只占用一個微不足道的空間。除了在metadata文件中存儲的極少目錄數據,你的數據不會冗余,快照允許你的系統回滾到(創建快照)那個時刻,當然,你需要恢復快照。

通過在HBase shell中運行如下命令來創建一個表的快照:
hbase(main):013:0> snapshot 'yy', 'MySnapShot' 在執行這條命令之后,你將發現在hdfs中有一些小的數據文件。在/hbase/.hbase-snapshots里 ,這些文件中存儲著快照信息。想要恢復數據只需要執行在shell中執行如下命令:
hbase(main):022:0> disable 'yy'
hbase(main):023:0> restore_snapshot 'MySnapShot'
hbase(main):024:0> enable 'yy'正如你看到的,恢復快照需要對表進行離線操作。一旦恢復快照,那任何在快照時刻之后做的增加/更新數據都會丟失。如果你的業務需求是這樣的:你必須有數據的異地備份,你可以用exportSnapshot命令賦值一個表的數據到你的本地HDFS或者你選擇的遠程HDFS中。
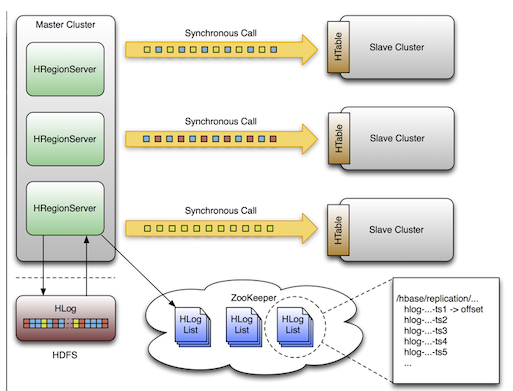
HBase復制(HBase Relication)
HBase復制是另外一個負載較輕的備份工具。文章《HBase復制概述》有對它的詳細描述。總的來說,復制被定義為列簇級別,可以工作在后臺并且保證所有的編輯操作在集群復制鏈之間的同步。
復制有三種模式:主->從(master->slave),主<->主(master<->master)和循環(cyclic)。這種方法給你靈活的從任意數據中心獲取數據并且確保它能獲得在其他數據中心的所有副本。在一個數據中心發生災難性故障的情況下,客戶端應用程序可以利用DNS工具,重定向到另外一個備用位置。
復制是一個強大的,容錯的過程。它提供了“最終一致性”,意味著在任何時刻,最近對一個表的編輯可能無法應用到該表的所有副本,但是最終能夠確保一致。
注:對于一個存在的表,你需要通過本文描述的其他方法,手工的拷貝源表到目的表。復制僅僅在你啟動它之后才對新的寫/編輯操作有效。
導出導入(Export/Import)
HBase的導出工具是一個內置的實用功能,它使數據很容易從hbase表導入HDFS目錄下的SequenceFiles文件。它創造了一個map reduce任務,通過一系列HBase API來調用集群,獲取指定表格的每一行數據,并且將數據寫入指定的HDFS目錄中。這個工具對集群來講是性能密集的,因為它使用了mapreduce和HBase 客戶端API。但是它的功能豐富,支持制定版本或日期范圍,支持數據的篩選,從而使增量備份可用。
下面是一個導出命令的簡單例子:
hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir> 一旦你的表導出了,你就可以復制生成的數據文件到你想存儲的任何地方(比如異地/離線集群存儲)。你可以執行一個遠程的HDFS集群/目錄作為命令的輸出目錄參數,這樣數據將會直接被導出到遠程集群。使用這個方法需要網絡,所以你應該確保到遠程集群的網絡連接是否可靠以及快速。
導入命令:
hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir> 拷貝表(CopyTable)
拷貝表功能在文章《使用CopyTable在線備份HBase》中有詳細描述,但是這里做了基本的總結。和導出功能類似,拷貝表也使用HBase API創建了一個mapreduce任務,以便從源表讀取數據。不同的地方是拷貝表的輸出是hbase中的另一張表,這張表可以在本地集群,也可以在遠程集群。
一個簡單的例子如下:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test 這個命令將會拷貝名為test的表到集群中的另外一個表testCopy。
請注意,這里有一個明顯的性能開銷,它使用獨立的“puts”操作來逐行的寫入數據到目的表。如果你的表非常大,拷貝表將會導致目標region server上的memstore被填滿,會引起flush操作并最終導致合并操作的產生,會有垃圾收集操作等等。
此外,你必須考慮到在HBase上運行mapreduce任務所帶來的性能影響。對于大型的數據集,這種方法的效果可能不太理想。
HBase API
由于總是這樣使用hadoop,你可以使用公用的api寫自己定制的客戶端應用程序來直接查詢表格。你也可以通過mapreduce任務的批量處理優勢,或者自己設計的其他手段。然而,這個方法需要對hadoop開發以及因此對生產集群帶來的影響有深入的理解。
離線備份原生的HDFS數據(Offline Backup of Raw HDFS Data)
最強力的備份機制,也是破壞性最大的一個。涉及到最大的數據占用空間。你可以干凈的關閉你的HBase集群并且手工的在HDFS上拷貝數據(distcp)。因為HBase已經關閉,所以能確保所有的數據已經被持久化到HDFS上的HFile文件中,你也將能獲得一個最準確的數據副本。但是,增量的數據幾乎不能再獲得,你將無法確定哪些數據發生了變化。
同時也需要注意,恢復你的數據將需要一個離線的元數據因為.META.表將包含在修復時可能無效的信息。這種方法需要一個快速的,可信賴的網絡來傳輸異地的數據,如果需要在稍后恢復它的話。
由于這些原因,Cloudera非常不鼓勵在HBase中這種備份方法。
故障恢復(Disaster Recory)
HBase被設計為一個非常能容忍錯誤的分布式系統,假設硬件失敗很頻繁。在HBase中的故障恢復通常有以下幾種形式:
- 在數據中心級別的災難性故障,需要切換到備份位置;
- 需要恢復由于用戶錯誤或者意外刪除的數據的之前一個拷貝;
- 出于審計目的,恢復實時點數據拷貝的能力
正如其他的故障恢復計劃,業務需要驅動這你如何架構并且投入多少金錢。一旦你確定了你將要選擇的備份方案,恢復將有以下幾種類型:
- 故障轉移到備份集群
- 導入表/恢復快照
- 指向HBase在備份位置的根目錄
如果你的備份策略是這樣的,你復制你的HBase數據在不同數據中心的備份集群,故障轉移將變得簡單,僅需要使用DNS技術,轉移你的應用程序。
請記住,如果你打算允許數據在停運時寫入你的備份集群,那你需要確保在停運結束后,數據可以回到主機群。主<->主或循環的復制架構能自動處理這個過程,但對于一個主從結構來講,你就需要手動進行干預了。
你也可以在故障時通過簡單的修改hbase-site.xml的 hbase.root.dir屬性來更改hbase根目錄,但是這是最不理想的還原選項,因為你復制完數據返回生產集群時,正如之前提到的,可能會發現.META是不同步的。
總結
綜上所述,從某種損失或中斷中恢復數據需要一個精心設計的BDR計劃。強烈建議你徹底明白你的業務需求,然后明白數據精確度/可用性以及故障恢復的最大時間。有了這些知識,你才能更好的選擇滿足這些需求的工具。
選擇工具僅僅是個開始,你應該對你的BDR策略進行大規模測試,以確保它的在你的基礎設施下的功能。并且,你應該是非常熟悉所有的故障恢復步驟。
參考
http://blog.cloudera.com/blog/2013/11/approaches-to-backup-and-disaster-recovery-in-hbase/
http://blog.csdn.net/iam333/article/details/38232215



——App啟動歡迎頁面制作)



)
BeautifulSoup的使用示范)



)





)
