責備的近義詞
I’ve been considering writing on the topic of algorithms for a little while, but with the Exam Results Fiasco dominating the headline news in the UK during the past week, I felt that now is the time to look more closely into the subject.
我一直在考慮有關算法主題的寫作,但是在過去一周內, 考試成績慘敗在英國的頭條新聞中占據著主導地位,我認為現在是時候更加仔細地研究這個主題了。
With high school-leavers’ exams being canceled due to Covid-19 this summer, students’ final exam grades were adjusted from teacher assessments by means of an ‘algorithm’, produced by Ofqual. This caused controversy due to the impact it had on the results of those from the most disadvantaged backgrounds. Some schools and colleges had more than half of grades marked down, and consequently many felt the outcome was unfair. So controversial were these results, that in the face of enormous political pressure, the government eventually scrapped the grades generated by the algorithm in favor of the original grades recommended by teachers.
今年夏天,由于Covid-19取消了高中生考試,學生的期末考試成績根據教師的評估通過Ofqual制定的“算法”進行了調整。 由于它對來自最不利背景的人的結果產生了影響,因此引起了爭議 。 一些學校和學院有超過檔次的一半下調 ,因此許多人認為結果是不公平的。 這些結果極具爭議性,以至于面對巨大的政治壓力,政府最終放棄了算法生成的成績,轉而使用老師推薦的原始成績。
As we saw this week, the presumed complexity of the algorithm generating A-Level grade results allowed for the blame to be placed on the algorithm itself, rather than a number of factors which went in to its implementation. This essentially created a digital scapegoat for a flawed system.
正如我們在本周看到的那樣,生成A級成績結果的算法的復雜性允許將責任歸咎于算法本身,而不是影響其實施的許多因素。 這本質上為存在缺陷的系統創造了數字替罪羊。
Algorithms will play an increasingly important role in our lives, determining prospects, status, relationships and many other factors which determine both our societal and self worth. According to the CEO of Ofqual:
算法將在我們的生活中發揮越來越重要的作用,確定前景,地位,關系和許多其他因素,這些因素決定了我們的社會和自我價值。 根據Ofqual的首席執行官 :
Algorithms can be supportive of good decision-making, reduce human error and combat existing systemic biases.
算法可以支持良好的決策,減少人為錯誤并消除現有的系統偏差。
‘But issues can arise if, instead, algorithms begin to reinforce problematic biases, for example because of errors in design or because of biases in the underlying data sets.
但是,如果算法開始加強有問題的偏差,例如由于設計錯誤或底層數據集中的偏差,就會出現問題。
‘When these algorithms are then used to support important decisions about people’s lives, for example determining whether they are invited to a job interview, they have the potential to cause serious harm.’
“當這些算法被用來支持有關人們生活的重要決定時,例如確定是否邀請他們參加工作面試,它們就有可能造成嚴重傷害。”
I’m going to examine what exactly we mean by an algorithm and look at what went wrong in this particular case, with the hope that lessons can be learned for the future.
我將研究算法到底是什么意思,并查看在這種特殊情況下出了什么問題,希望以后能吸取教訓。
那么什么是“算法”? (So what is an ‘algorithm’?)
Wikipedia has a predictably dry definition of an algorithm, which doesn’t contribute much to our understanding and is too broad to be correct in its actual usage in everyday situations. You will find this kind of definition all over the web.
Wikipedia具有可預測的算法干燥定義,對我們的理解沒有多大幫助,而且范圍太廣,無法在日常情況下正確使用。 您會在網上找到這種定義。
An algorithm, in more everyday terms, is a definition of a sequence of operations and rules on an input, to provide an output. So, under this argument,
用更日常的術語來說,算法是對輸入的一系列操作和規則的定義,以提供輸出。 所以,根據這個論點,
input -> “Add 4” -> output
輸入->“加4”->輸出
Is an algorithm, as is:
是一種算法,如下所示:
input -> if (input >10, output 10) else (output 0) -> output
輸入->如果(輸入> 10,輸出10)否則(輸出0)->輸出
However, both of these examples contradict the way in which the word “Algorithm” is used commonly. The above would probably be referred to as ‘code’, ‘processes’, ‘logic’, ‘computation’ or similar. Algorithm as a term seems to be reserved for those sequences which are complicated to describe or explain to humans.
但是,這兩個示例都與通常使用“算法”一詞的方式相矛盾。 以上內容可能稱為“代碼”,“過程”,“邏輯”,“計算”或類似內容。 算法作為一個術語似乎被保留用于被復雜描述或解釋人類的那些序列。
Conversely, we still use the word algorithm to describe some simple tasks, for example sorting. This is, admittedly, a simple algorithm that can be explained in a sentence (see Bubble sort for one example), but no-one is arguing that it isn’t an algorithm. Perhaps the complexity, in this case, comes from the fact that the stop condition is not pre-determined, i.e. we need to know the input before we know exactly how many steps will be taken.
相反,我們仍然使用單詞算法來描述一些簡單的任務,例如排序。 誠然,這是一種可以用句子解釋的簡單算法(例如,請參閱“ 冒泡排序 ”),但是沒有人爭辯說它不是一種算法。 在這種情況下,可能的復雜性來自未預先確定停止條件的事實,即我們需要在確切知道將要執行多少步驟之前先知道輸入。
As a further counter-example:
再舉一個反例:
input -> (output = all positive integers below input) -> output
輸入->(輸出=輸入以下所有正整數)->輸出
Is this an algorithm? It appears simple, yet we don’t know in advance how many steps we will take. If the input is 0, no steps will be taken. Is this complex enough to be branded an algorithm?
這是算法嗎? 看起來很簡單,但我們事先不知道將要執行多少步驟。 如果輸入為0,將不執行任何步驟。 這種復雜程度足以打上算法烙印嗎?
I think it is safe to say that the true definition of an Algorithm is difficult, however, the following comes close:
我認為可以肯定地說,算法的真正定義很困難,但是,以下內容很接近:
A definition of a finite set of sequences or rules which must be implemented through computing to generate the desired output.
有限的一組序列或規則的定義,必須通過計算來實現以生成所需的輸出。
Think of it as a blueprint or a set of instructions to a computer to perform a task.
將其視為藍圖或計算機執行任務的一組指令。
怎么會這么危險? (How can that be so dangerous?)
As teachers, students and parents across the UK sought answers to why so many A level results were downgraded, the stock answer was that an algorithm had decided the outcome. But the blame cannot sit with a computational process.
當英國各地的老師,學生和家長都在尋找答案,為什么要對這么多的A級成績進行降級時,常見的答案是算法決定了結果。 但是,責任不能與計算過程放在一起。
Let’s take a simple example. Assume that the algorithm looks to the public, or even students like:
讓我們舉一個簡單的例子。 假設該算法面向公眾,甚至學生也喜歡:
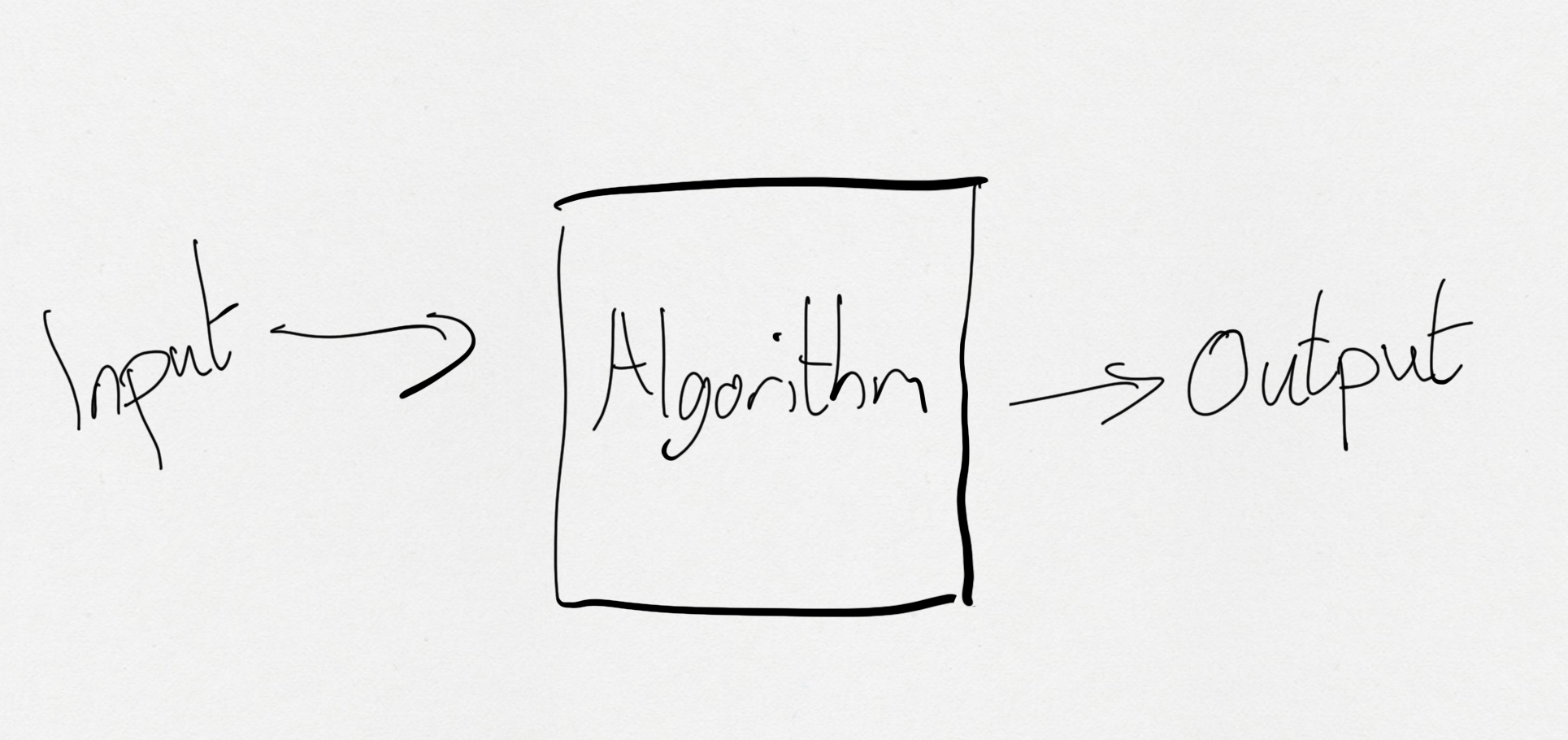
Inside the box, this is what is happening:
在盒子里,這是正在發生的事情:
Mock Grade -> “50% of time same, 40% Subtract 1, 10% add one” -> A-Level Result.
模擬成績->“ 50%的時間相同,40%減去1,10%加一”-> A級成績。
The result? 40% of students have now ended up with a worse grade than their mock exam results, while 10% did better. There would be a similar outcry, and questions would be asked about what made the algorithm choose to lower certain students grades, and why did it decide that all 3 students in the small village of Ombersley should get increased grades?
結果? 現在,有40%的學生成績比模擬考試成績差,而10%的學生成績更好。 會有類似的強烈抗議,并且會問有關該算法為何選擇降低某些學生的成績,以及為什么它決定在Ombersley小村莊中的所有3名學生都應提高成績?
Although my algorithm is very simple, it would allow me to hide behind the assumed complexity of the algorithm, leading people to blame the unknown black-box instead of the real culprit, me.
盡管我的算法非常簡單,但它可以讓我躲在算法的假定復雜度后面,從而導致人們責怪未知的黑匣子而不是真正的罪魁禍首。
Ofqual:隱藏在算法背后 (Ofqual: Hiding behind an algorithm)
Ofqual, in their defense, have in the interests of transparency released an approximation of their methodology. It’s a 319 page document, describing and evaluating the factors contributing to the final grades, but never outlining the decision making process in detail. It also contains a particularly interesting sentence. After analyzing distributions across many different factors and cross referencing against variables such as year and subject, they state:
為了維護自己的利益,Oqual為透明起見, 發布了一種近似于他們的方法論的方法。 這是一份319頁的文件,描述和評估了影響最終成績的因素,但從未詳細概述決策過程。 它還包含一個特別有趣的句子。 在分析了許多不同因素的分布并交叉引用諸如年份和主題之類的變量之后,他們指出:
The analyses conducted show no evidence that this year’s process of awarding grades has introduced bias. Changes in outcomes for students with different protected characteristics and from different socio-economic backgrounds are similar to those seen between 2018 and 2019.
進行的分析表明,沒有證據表明今年的成績授予過程引入了偏見。 具有不同受保護特征,來自不同社會經濟背景的學生的成績變化與2018年至2019年之間的變化相似。
In effect, this says that the distributions across each of the factors analysed are not significantly different to those seen in previous years. The above quote is also the entirety of the conclusion section, in a 319 page document.
實際上,這表示分析的每個因素之間的分布與前幾年沒有明顯差異。 上面的引用還是319頁文檔中結論部分的全部 。
Let’s explain very quickly what’s wrong with this, with a simplified example.
讓我們用一個簡化的例子快速解釋一下這是怎么回事。
The analysis was performed on the results of the algorithm-based marks compared to previous years, against a large set of factors including gender, past performances, socio-economic grouping and many more. This is impressive to see and shows that some real effort has been put in to considering potential pitfalls of the resulting grading. However, very few factors are actually compared, focusing instead on mean and variation (standard deviation) and the % of students achieving greater than C or A grades.
分析是根據與前幾年相比基于算法的標記的結果進行的,其中涉及大量因素,包括性別,過往表現,社會經濟群體等等。 令人印象深刻,這表明在考慮最終評分的潛在陷阱方面已經付出了一些實際的努力。 但是,實際上很少進行比較,而是著重于均值和方差(標準差)以及達到C或A以上成績的學生所占的百分比。
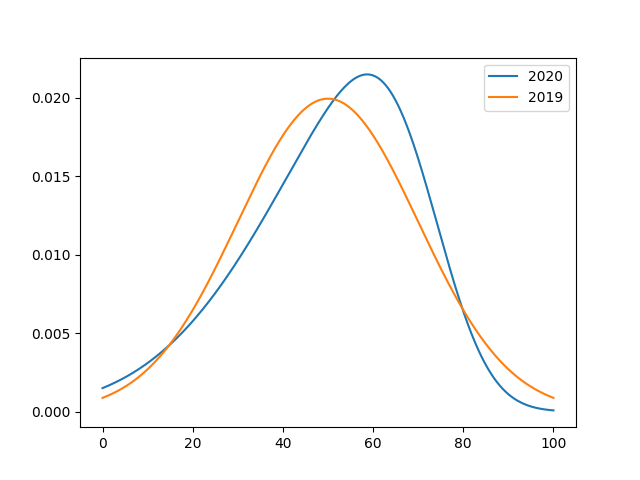
Above, there are two curves. Let’s say one is 2019 and one is 2020 results. Both have exactly the same mean and standard deviation, and so could be stated in these results as “showing no evidence of bias”. However, these plots would provide an additional 3% Grades of U (lowest attainable) and 2% more A* grades (highest attainable) in 2020. Let’s now assume that I’m doing this analysis to show that boys and girls results are unbiased:
上方有兩條曲線。 假設一個是2019年的結果,另一個是2020年的結果。 兩者均具有完全相同的均值和標準差,因此可以在這些結果中表述為“無偏見跡象”。 但是,這些圖將在2020年提供另外3%的U(可達到的最低成績)和2%的A *(可達到的最高成績)成績。現在讓我們假設我正在做此分析,以表明男孩和女孩的成績是公正的:
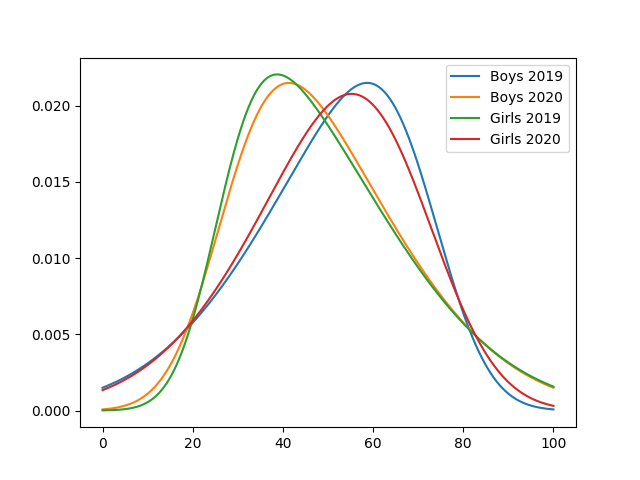
Just looking at U Grades.
只看U成績。
Boys: 14% to 21%. Increase of 7%
男孩:14%至21%。 增長7%
Girls: 23% to 15%. Decrease of 8%
女孩:23%至15%。 減少8%
Clearly a bias is shown in these results towards Girls getting fewer U Grades.
顯然,這些結果表明,女生獲得的U成績降低了。
This is a very simple explanation, playing with one of a number of factors in one particular type of distribution. My point is that 3 sentences saying “showing no evidence of bias” in an over 300 page report, with no mention of potential pitfalls may be because insufficient work was done or presented to provide the evidence.
這是一個非常簡單的解釋,涉及一種特定類型的分布中的眾多因素之一。 我的觀點是,在300多頁的報告中,有3句話說“沒有偏見”,而沒有提及潛在的陷阱,這可能是因為未完成或沒有提供足夠的證據來提供證據。
如果我們不能責怪算法,那又是誰呢? (If we can’t blame algorithms, then who?)
I believe that the bottom line comes down to human processes. After all, the computational process is a product of human design. Firstly, the requirements are gathered by analysts and turned into code by data scientists and developers. If I developed the “algorithm” I discussed earlier, and ran any kind of testing I would have been able to see how the resulting distribution compared to the previous year(s), as well as other variables. I would know at the time of developing this, that the percentages chosen were essentially arbitrary and I should immediately question their correctness and impact.
我認為最重要的是人的過程。 畢竟,計算過程是人類設計的產物。 首先,需求由分析師收集,并由數據科學家和開發人員轉換為代碼。 如果我開發了前面討論的“算法”,并且進行了任何形式的測試,我將能夠看到與前一年相比所得的分布以及其他變量。 在開發此程序時,我會知道所選的百分比基本上是任意的,我應該立即質疑它們的正確性和影響。
This is always good practice for any data scientist /developer to follow when writing code. If you set thresholds or constants in your code, then you should always question whether they are correct. Often, when sand-boxing, I will write #TODO comments forcing myself to come back and check or justify each of the set values, providing explainability for myself and future users of the code.
這是任何數據科學家/開發人員在編寫代碼時始終遵循的良好做法。 如果您在代碼中設置了閾值或常量,則應始終質疑它們是否正確。 通常,在進行沙箱測試時,我會編寫#TODO注釋,迫使自己返回并檢查或證明每個設置值,從而為我自己和將來的代碼用戶提供可解釋性。
Secondly, live systems need to be tested fully before release. In this case, the exam results will have been ready for at minimum several days before release, and therefore could have been checked to detect unforeseen bias. Given the importance of the outputs from this system and the impact felt by those affected, I think that data scientists should have anticipated this feedback and could have pulled the plug and improved the algorithm before releasing results.
其次,實時系統需要在發布之前進行全面測試。 在這種情況下,至少要在發布前幾天準備好考試結果,因此可以檢查以發現無法預料的偏差。 考慮到該系統輸出的重要性以及受影響者所受到的影響,我認為數據科學家應該預料到這種反饋,并且可以在發布結果之前拔掉插頭并改進算法。
Some may argue that it’s only a small number of cases which are affected. The small number of high impact cases should be more important to understanding inadequacies and bias in any complex system and so should have been noticed before release. Outliers are where you should be looking, especially in huge datasets, if you want to understand what is happening in a complicated system. It wouldn’t be difficult to look through what happened to the 100 biggest reductions and improvements and run through the algorithm to understand why someone would drop from a predicted grade of C (pass) to a resulting U (lowest attainable).
有人可能會說,受影響的只是少數案例。 少數高影響力案例對于理解任何復雜系統中的不足和偏見應更為重要,因此在發布之前應引起注意。 如果您想了解復雜系統中正在發生的事情,那么離群值是您應該尋找的地方,尤其是在龐大的數據集中。 仔細查看這100項最大的減少和改進所發生的事情,并遍歷算法,以理解為什么有人會從預測的C(通過)等級降至最終的U(可達到的最低等級)并不難。
Finally, a portion of blame lies with non-technical staff involved in the process. It might have been that Scientists and Developers raised all of the above issues loudly, but were not involved in the final decision on whether to release or delay, and what the acceptable level of “correctness” is. Usually, this group of people do not fully understand the algorithm enough to make an informed decision.
最后,部分責任歸咎于參與該過程的非技術人員。 可能是科學家和開發人員大聲提出了上述所有問題,但并未參與有關發布還是延遲以及“正確性”的可接受水平的最終決定。 通常,這群人不完全了解算法,無法做出明智的決定。
我們可以從中學到什么? (What can we learn from this?)
I have mentioned a couple of things throughout the piece about some things which we can do to mitigate against unintended outcomes.
在整篇文章中,我提到了一些事情,我們可以采取一些措施來減輕意外結果的影響。
As a Developer/Data Scientist (someone writing the algorithm):
作為開發人員/數據科學家(編寫算法的人):
- Think about the assumptions you are making. Try to justify these choices. 考慮一下您所做的假設。 嘗試證明這些選擇的合理性。
- Pay close(r) attention to the extremes of your data, think about the impact of these extremes. 密切注意數據的極端情況,考慮這些極端情況的影響。
- If you see potential problems speak up, loudly, as soon as possible. Be part of a culture where this is encouraged. 如果您發現潛在問題,請盡快大聲說出來。 成為鼓勵這種文化的一部分。
- Take responsibility. Don’t hide behind the complexity of your solution. 承擔責任。 不要隱藏解決方案的復雜性。
As a Manager/Director/Salesperson (i.e, someone not writing the algorithm):
作為經理/主任/銷售員(即不編寫算法的人):
- Listen to your staff. Develop a culture where they can speak out about problems without fear. 聽你的員工。 發展一種文化,使他們可以毫無畏懼地講出問題。
- Ask about the impact of any solution. What’s the worst case? 詢問任何解決方案的影響。 最壞的情況是什么?
- Try to understand any solution, even at a non-technical level. If no-one is capable of explaining sufficiently then this should raise red-flags. 嘗試理解任何解決方案,即使在非技術層面也是如此。 如果沒有人能夠充分解釋,那么這將引起危險信號。
- Take responsibility. Don’t hide publicly behind the complexity of your solution. 承擔責任。 不要公開地隱藏解決方案的復雜性。
As a consumer (someone affected by an algorithm)
作為消費者(受算法影響的人)
Don’t blame algorithms.
不要怪算法。
In most cases, issues caused by complex systems can and should be prevented by human intervention at various stages in the process. The algorithm does
在大多數情況下,可以而且應該通過在過程的各個階段進行人工干預來防止由復雜系統引起的問題。 該算法確實
exactly what it was told to do by people.
正是人們告訴人們要做的。
- Remember that people, and anything they create, are not necessarily perfect! 請記住,人及其創造的任何事物不一定都是完美的!
翻譯自: https://medium.com/swlh/the-exam-results-crisis-should-we-be-blaming-algorithms-ffe489461f47
責備的近義詞
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391707.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391707.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391707.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

電腦如何設置終端設置代理_如何設置一個嚴肅的Kubernetes終端
)
spring cloud(二)

c/c++編譯器的安裝


numpy 線性代數_數據科學家的線性代數—用NumPy解釋

spring 注解方式配置Bean

主成分分析 獨立成分分析_主成分分析概述

擴展方法略好于幫助方法

零元學Expression Blend 4 - Chapter 25 以Text相關功能就能簡單做出具有設計感的登入畫面...
)
leetcode 395. 至少有 K 個重復字符的最長子串(滑動窗口)

冠狀病毒時代的負責任數據可視化

集合_java集合框架


數據特征分析-統計分析

心學 禪宗_禪宗宣言,用于有效的代碼審查

leetcode 896. 單調數列

數據eda_銀行數據EDA:逐步


計算機網絡原理筆記-三次握手
)