你相信我們對大模型也存在「迷信權威」嗎?
ChatGPT 的 GPT-4 名聲在外,我們就不自覺地更相信它,優先使用它。但我用 ChatALL 比較 AI 大模型們這么久,得到的結論是:
ChatGPT GPT-4 在大多數情況下確實是最強,但綜合費用、訪問難度、封號風險等條件,它就不是了。而大多數人在用的 ChatGPT 3.5,就更不是了。
那么最強的是誰呢?Bing Chat!先列舉幾個客觀事實,再做主觀分析。
| ChatGPT 3.5 | ChatGPT 4 | Bing Chat | |
|---|---|---|---|
| 費用 | 免費 | 每月 20 美元 | 免費 |
| 注冊 | 國外手機號 | 國外手機號 | 任意郵箱 |
| 封 IP | 多 | 多 | 少 |
| 封帳號 | 有 | 有 | 無 |
| 瀏覽器兼容 | 好 | 好 | 只 Edge |
從上表可以看出,除了瀏覽器兼容這一項以外,都是 Bing Chat 更好。
下面再主觀分析下模型的效果,畢竟這個是王道。
先透露一個小道消息。據說,Bing Chat 比 ChatGPT 更早使用了 GPT-4 模型。甚至可能從第一天就是 GPT-4。但為什么沒有人說 Bing Chat 比當時的 ChatGPT 3.5 更強?大概就是明星光環導致的吧。
Bing Chat 的三個風格:創造力、平衡和精確,從一開始時就不是同一個模型設了不同的 temperature 那么簡單。
起初,創造力的模型是 h3imaginative,平衡是 harmonyv3,精確是 h3precise。從命名看,平衡就很獨特。后來不知道某一天「平衡」變成了 galileo(伽利略),更獨特了。
用 chatall.ai 同時發 prompt 給它們,能明顯感覺到「平衡」的生成速度更快。這也說明基礎模型和另兩個大有不同。可能是 GPT-3.5,也可能是 GPT-4 最新的蒸餾調優版(就像現在的 3.5 比最早的 3.5 快很多一樣)。后者的可能性更大。
也就是說,Bing Chat 就是免費的 GPT-4 了,何必還費勁去鼓搗 ChatGPT 呢?
如果以上分析還不夠說服力,那么我們來看客觀數據。
下面是 chatall.ai 五月份的數據統計:
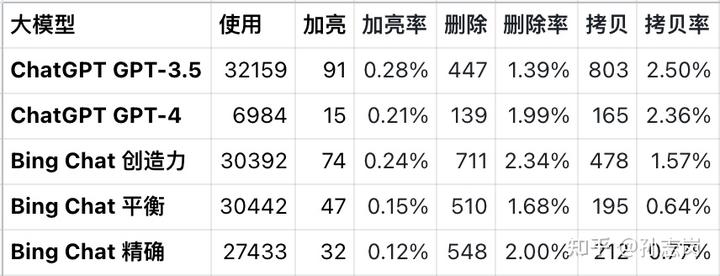
解釋下數據:
- 發送、加亮、刪除和拷貝四列是用戶對大模型做對應操作的次數,「率」就顧名思義了
- 「加亮」是突出顯示,表示這個結果好。但因為 ChatALL 現在長期保存數據的能力還不夠,這個操作的意義不大,不是很能說明問題
- 「刪除」表示這條結果太差了,不想再看到了。但因為 ChatALL 這段時間在 Bing Chat 上出了不少 bug,很可能有大量出錯信息被刪除
- 「拷貝」表示這條結果我打包帶走拿去用了,是另一種認可,且可能是最強的認可
坦率說,因為基數不夠大,以及各種缺陷,這個數據只能參考。但考慮到 ChatGPT 的光環加持,Bing Chat 受 ChatALL bug 的負面影響,還是可以說明 Bing Chat 和 ChatGPT 4 效果上是伯仲之間的。
?轉載:https://zhuanlan.zhihu.com/p/633148476
)









)
)



)



