聯合索引提高查詢效率的原理
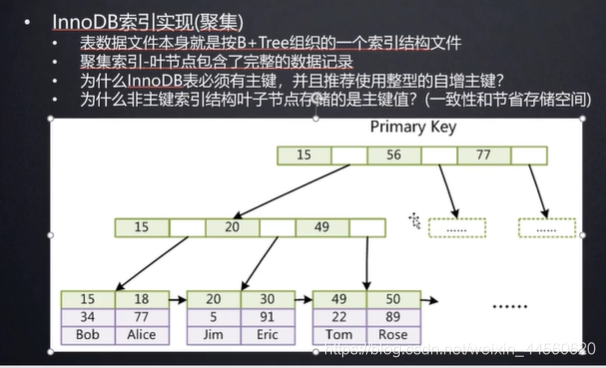
MySQL會為InnoDB的每個表建立聚簇索引,如果表有索引會建立二級索引。聚簇索引以主鍵建立索引,如果沒有主鍵以表中的唯一鍵建立,唯一鍵也沒會以隱式的創建一個自增的列來建立。聚簇索引和二級索引都是一個b+樹,b+樹的特點是數據按一定順序存在葉子節點且每頁數據相連。一般情況下使用索引查詢時,先查詢二級索引的b+樹,查到數據并拿數據中保存的主鍵回查聚簇索引查到所有數據。下面我們舉個例子來重現這個過程。
以下面表舉例,假設表中已經存了部分數據:
create table `user_info`(`id` bigint(20) NOT NULL PRIMARY KEY,`name` varchar(11),`age` int(11),`phone` varchar(20),KEY `key_name_age` (`name`,`age`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
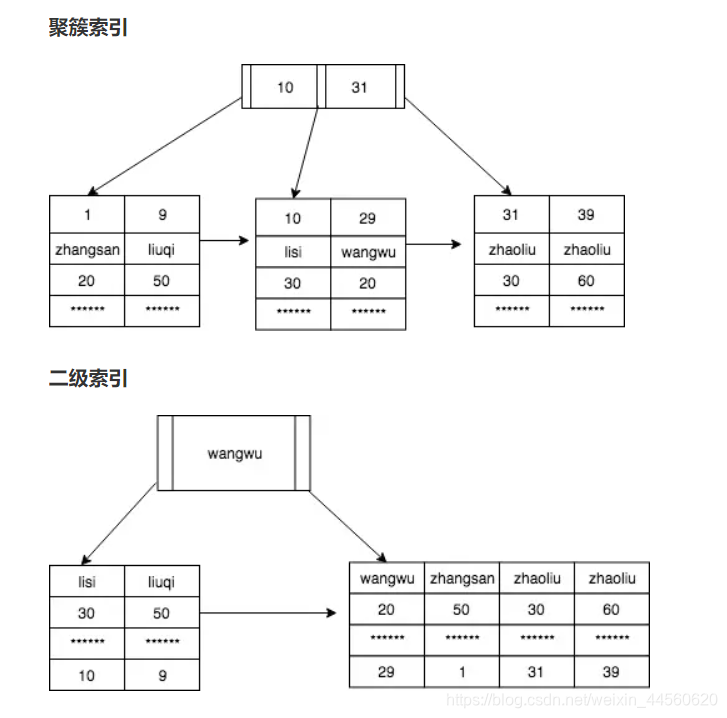
假如我們想要查找名字為zhaoliu,年齡為30的人的信息。即name=‘zhaoliu’,age=30
(1)先查二級索引,先用二分法查找發現在wangwu名字的右邊
(2)讀取右邊的這頁的數據到內存,二分法查到數據2個name為zhaoliu人。
(3)繼續二分法比較age查到數據id=31
(4)id=31回查聚簇索引先用二分法查找發現在31右邊
(5)讀取31左邊這頁數據到內存,二分法查到數據并返回數據
如果你僅僅查找id,name和age數據那么這樣就用到了覆蓋索引,這樣就不用回查聚簇索引,在第(3)步直接返回數據即可。


)




算法)

)







)
)
