釘釘設置jira機器人
For software developers, one of the most-debated and maybe even most-hated questions is “…and how long will it take?”. I’ve experienced those discussions myself, which oftentimes lacked precise information on the requirements. What I’ve learned is: If only sparse information is available, a reliable estimate is almost impossible. To make matters worse, developers found themselves under pressure after having issued a wild guess and then requiring more time.
對于軟件開發人員而言,最受爭議甚至最討厭的問題之一是“……需要多長時間?”。 我自己經歷了這些討論,而這些討論通常缺少有關要求的準確信息。 我了解到的是:如果只有稀疏信息可用,那么幾乎不可能進行可靠的估計。 更糟糕的是,開發人員在做出了瘋狂的猜測之后發現自己處于壓力之下,然后需要更多的時間。
體驗另一面 (Experiencing the other side)
As I started working in direct contact with customers, I’ve (reluctantly) realized that the collaboration oftentimes benefits from providing a schedule. In my experience, time becomes an important factor when customers have plans and projects on their own which can’t continue without knowing when a missing piece arrives.
當我開始與客戶直接聯系時,我(很不情愿地)意識到,協作通常可以從提供計劃中受益。 根據我的經驗,當客戶自己制定計劃和項目時,時間變得很重要,而計劃和項目無法不知道丟失的零件何時到達。
相互理解(業務理解) (Understanding each other (Business Understanding))
In the end, this comes down to a simple problem: “How can managers and developers work together on a project and get what they, respectively, need?”. For those who interact with a customer, this means that they need the information (estimates) to make the collaboration go smoothly. In turn, developers need accurate requirements and some flexibility has to be respected as well.
最后,這歸結為一個簡單的問題:“管理人員和開發人員如何才能共同完成一個項目,并分別獲得他們需要的東西?”。 對于那些與客戶互動的人來說,這意味著他們需要信息(估算)來使協作順利進行。 反過來,開發人員需要準確的要求,并且還必須尊重一些靈活性。
學習! (Learn!)
With that in mind, I’ve decided to use a data-science-driven approach to gain insights into the estimation problem. You can find the code that I used and more detailed technical explanations in my github repository. What I wanted to know, was:
考慮到這一點,我決定使用數據科學驅動的方法來深入了解估計問題。 您可以在github存儲庫中找到我使用的代碼以及更詳細的技術說明。 我想知道的是:
- As a baseline reference, what are the average times that a “New Feature”, “Bug” (etc) spends in implementation (i.e. status “in progress”)? 作為基準參考,“新功能”,“錯誤”(等)在實施(即狀態“進行中”)上花費的平均時間是多少?
- Is it possible to estimate the time spent “in progress” from analyzing the text in the summary and description of a ticket? 是否可以通過分析票證摘要和說明中的文本來估計“進行中”所花費的時間?
- Which words in the description make up for large / small durations? 說明中的哪些詞組成了較長/較短的持續時間?
數據理解 (Data Understanding)
As data, I gathered around 20.000 tickets from the RTFACT-repository of the JFrog open source project. For all tickets, the following is available: Issuetype (i.e. “Bug”, “New Feature”), summary, description, time spent “in progress”. Some initial data exploration showed, that out of all the tickets, only 10% (2258) have a nonzero “in progress”-time. All the others have not been worked at or they were never put in that status.
作為數據,我從JFrog開源項目的RTFACT存儲庫中收集了大約20.000張票證。 對于所有票證,以下內容可用:發行類型(即“錯誤”,“新功能”),摘要,描述,“進行中”所花費的時間。 一些初步的數據研究表明,在所有故障單中,只有10%(2258)的“進行中”時間為非零。 所有其他人都沒有工作過,或者從未處于這種狀態。
To get a feeling for the data, I checked the counts of tickets by their issuetype. And as you can see in the next image, there is a large variation in the types with the highest count being Bugs.
為了了解數據,我按票證發行類型檢查了票數。 正如您在下一張圖片中看到的那樣,類型之間的差異很大,其中錯誤最多。

準備數據 (Prepare Data)
As a first cleaning step, I only kept entries with a non-zero “in progress”-time and removed outliers (outside of the 96%-quantile). Now, keep in mind that statistical models can only understand numbers, not text. To translate between strings of characters, I computed TFIDF text analysis features. These are a way of numerically representing the occurrence and importance of certain words in a text document.
作為第一步清理,我只保留“進行中”時間為非零的條目,并刪除了異常值(在96%的位數之外)。 現在,請記住,統計模型只能理解數字,而不能理解文本。 為了在字符串之間進行翻譯,我計算了TFIDF文本分析功能。 這是一種數字表示文本文檔中某些單詞的出現和重要性的方法。
資料建模 (Data Modeling)
A powerful and insightful model for analyzing data are decision trees / random forests. One branch of that type of model are gradient boosted trees. These are my model of choice due to their performance (won several Kaggle competitions) and their interpretability. This mainly means, that we can draw further insight from the decisions made in the trees.
決策樹/隨機森林是分析數據的強大而有見地的模型。 這種模型的一個分支是梯度增強樹 。 由于它們的表現(贏得了幾次Kaggle比賽)和可解釋性,這些是我選擇的模型。 這主要意味著,我們可以從樹中做出的決策中獲得更多的見解。
評估結果 (Evaluate the Results)
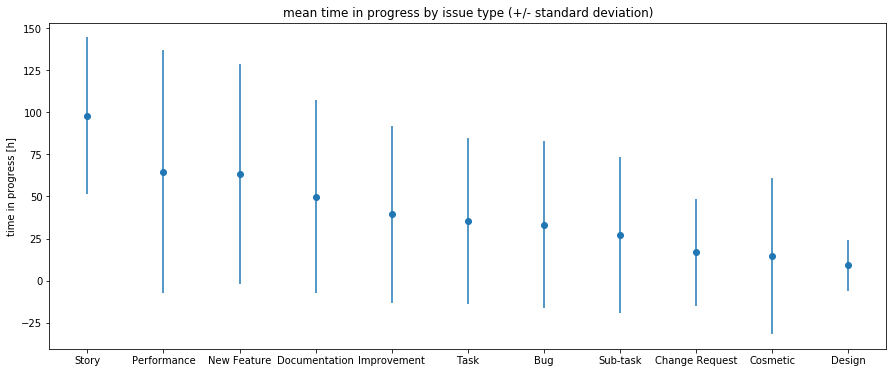
So, the first question asked regarded a baseline for the duration of a ticket. As you can see in the next image, the mean duration spans between ~10h and ~100h. Note, that the standard deviation is very large (~50 or higher), which calls for additional estimation information through e.g. the boosted trees.
因此,首先要問的問題是機票期限的基準。 如下圖所示,平均持續時間介于?10h和?100h之間。 請注意,標準偏差非常大(?50或更高),這需要通過增強樹等其他估算信息。
For the trees, the performance is good (and can be tuned to “great”) — on the training set. However, on the test set, the model generalized badly. This is, why I captioned this article by “early results”. As you can see in the next image, the ground truth (blue) deviates significantly from the estimated values (orange).
對于樹木而言, 訓練集上的表現很好(并且可以調整為“出色”)。 但是,在測試集上,該模型的推廣效果很差。 這就是為什么我用“早期結果”為本文加上標題。 如您在下一張圖片中所看到的,地面實況(藍色)與估計值(橙色)明顯不同。

I think it’s still interesting to take a look at the keywords contribute in a positive way (larger time “in progress”) or a negative way (smaller time “in progress”):
我認為,以積極的方式(較長的時間在“進行中”)或否定的方式(較短的時間在“進行中”)查看關鍵字貢獻是很有趣的:

As you can see from the results, the issue types “Bug” and “New Feature” have the largest positive impact on the estimation. On the other end of the spectrum are the “error” and “com”, which have the largest negative impact on the estimation. For the top 15 words that cause the highest positive / negative impact, see the figure below.
從結果中可以看出,問題類型“錯誤”和“新功能”對估計的影響最大。 另一方面,“誤差”和“ com”對估計的負面影響最大。 有關正面/負面影響最大的前15個字,請參見下圖。
未來的工作 (Future Work)
What else needs to be done?
還有什么需要做的?
- The dataset is not very large (the model had to be trained based on only ~2200 valid samples). The next step would be to find a ticket repository with a larger number of valid tickets. 數據集不是很大(必須僅基于約2200個有效樣本來訓練模型)。 下一步將是查找具有大量有效票證的票證存儲庫。
instead of only estimating the implementation time (time “in progress”), the cycle time is possibly as well interesting to know
不僅可以估計實施時間(“進行中”的時間 ),還可以了解周期時間
- Is it possible to estimate (classify) the ‘resolution’ (Fixed, Duplicate, Won’t Fix, …) of a ticket? 是否可以估計(分類)票證的“解決方案”(固定,重復,無法解決……)?
謝謝 (Thanks)
This was my first article on medium! Thanks a lot for taking the time. If you have any feedback or insights that you’d like to share: I’d be glad to get some feedback.
這是我關于媒體的第一篇文章! 非常感謝您抽出寶貴的時間。 如果您想分享任何反饋或見解:很高興獲得一些反饋。
翻譯自: https://medium.com/@steffen.herbort/early-results-this-is-what-happens-when-you-machine-learn-jira-tickets-1ea0d82f39fa
釘釘設置jira機器人
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391588.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391588.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391588.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
)
python的賦值與參數傳遞(python和linux切換)

vscode 標準庫位置_如何在VSCode中使用標準

leetcode 1603. 設計停車系統

IBM量子計算新突破:成功構建50個量子比特原型機

ChromeDriver與chrome對應關系
算法)
快速排序和快速選擇(quickSort and quickSelect)算法

小程序點擊地圖氣泡獲取氣泡_氣泡上的氣泡
)
leetcode 150. 逆波蘭表達式求值(棧)

WebLogic常見問題

PopTheBubble —測量媒體偏差的產品創意

linux-Centos7安裝nginx

javascript原型_JavaScript原型初學者指南

leetcode 73. 矩陣置零

elasticsearch,elasticsearch-service安裝

圖表可視化seaborn風格和調色盤
)
面向Tableau開發人員的Python簡要介紹(第3部分)
)
leetcode 191. 位1的個數(位運算)


seaborn分布數據可視化:直方圖|密度圖|散點圖
