熊貓數據集
If you are already familiar with NumPy, Pandas is just a package build on top of it. Pandas provide more flexibility than NumPy to work with data. While in NumPy we can only store values of single data type(dtype) Pandas has the flexibility to store values of multiple data type. Hence, we say Pandas is heterogeneous. We will unpack several more advantages of Pandas today.
如果您已經熟悉NumPy,Pandas只是基于它的一個軟件包。 與NumPy相比,熊貓提供了更大的靈活性來處理數據。 在NumPy中,我們只能存儲單個數據類型(dtype)的值。Pandas可以靈活地存儲多個數據類型的值。 因此,我們說熊貓是異質的 。 今天我們將介紹熊貓的更多優點。
Since we will be referring to NumPy in every section, I’m assuming you have knowledge of NumPy if not I will be dropping links to resources at the end of the article.
由于我們將在每個部分中都引用NumPy,因此假設您已經了解NumPy,否則我將在本文結尾處刪除指向資源的鏈接。
I’m considering the very popular Titanic datset to unpack the abilities of Pandas. You don’t have to worry because I will still be introducing the concepts of Pandas step-by-step keeping in mind you are a newbie to Pandas package.
我正在考慮非常受歡迎的泰坦尼克號daset,以解開熊貓的能力。 您不必擔心,因為我仍然會逐步介紹Pandas的概念,請記住您是Pandas軟件包的新手。
Let’s just quickly import Pandas, Numpy, and load the Titanic dataset.
讓我們快速導入Pandas,Numpy并加載Titanic數據集。
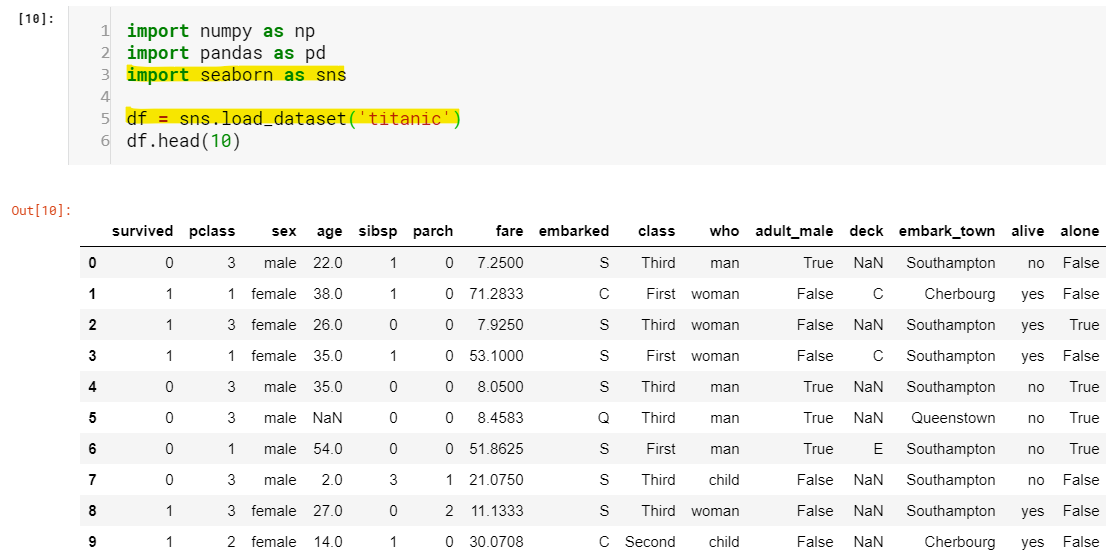
I know, a lot to digest at once but we will break it down at the course of time. For now, don’t worry about line 3 and line 5(highlighted). Just understand that the seaborn package has the dataset in it and we loaded it, that’s all. You might have already figured out that ‘df’ holds our entire dataset but wait, what is the data type of 'df’? and what on Earth is ‘df.head(10)’. This brings us to our first topic Pandas objects: Series and DataFrame.
我知道,有很多東西需要立即消化,但隨著時間的流逝我們會分解。 現在,不必擔心第3行和第5行(突出顯示)。 只需了解seaborn軟件包中就有數據集,然后我們就將其加載即可。 您可能已經發現'df'擁有我們的整個數據集,但是等等,'df'的數據類型是什么? 到底是什么'df.head(10)' 。 這將我們帶入第一個主題Pandas對象:Series和DataFrame。
熊貓系列對象 (Pandas Series object)
Series is a fundamental data structure of Pandas. We can think of it as a one-dimensional array of indexed data.
系列是熊貓的基本數據結構。 我們可以將其視為索引數據的一維數組。
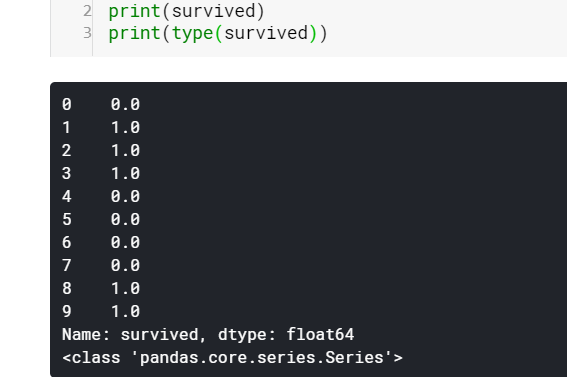
I have grabbed the ‘survived’ column from our dataset which is of type Series. I have converted the values of survived to float-point to differentiate between index and value. We can see it has a sequence of both index and value. Also, Series belongs to the class ‘pandas.core.series.Series’. We can access index and values separately with attribute index and values. Values are simply of type NumPy array and index is an array-like object of type pd.Index.
我從我們的數據集中獲取了“生存”列,其類型為Series。 我已經將生存的值轉換為浮點數,以區分索引和值。 我們可以看到它同時具有index和value的序列。 而且,Series屬于類'pandas.core.series.Series'。 我們可以使用屬性索引和值分別訪問索引和值。 值只是NumPy數組類型,而index是pd.Index類型的類似數組的對象。

Just as NumPy we can access values of Series with it’s associated index by using square bracket notation.
就像NumPy一樣,我們可以使用方括號表示法來訪問Series的值及其關聯的索引。
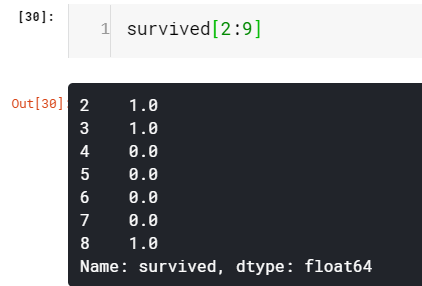
The essential difference between array and Series is that array have only an implicit index to access value while the series has an explicit index as well. The explicit indexing capability of Series gives an advantage, we can have an index of any type, the default is integer values as we have seen. Let’s see how we can change the integer index of our survived Series to string. Additionally, we will also learn how to create a Series object from scratch using an array(values of ‘survived’ which is of type array).
數組和序列之間的本質區別在于,數組僅具有用于訪問值的隱式索引,而序列也具有顯式索引。 Series的顯式索引功能提供了一個優勢,我們可以擁有任何類型的索引,如我們所見,默認值為整數值。 讓我們看看如何將生存系列的整數索引更改為字符串。 此外,我們還將學習如何使用數組(值為array的'survived'值)從頭創建Series對象。
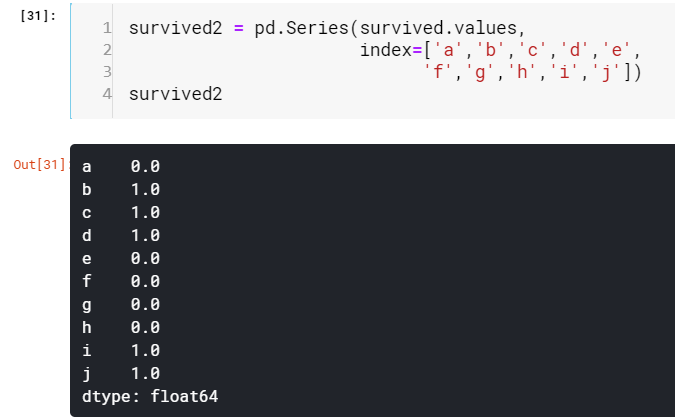
This also gives us scope to think series as an upgraded version on the Python dictionary.
這也使我們可以將系列視為Python詞典的升級版本。
熊貓DataFrame對象 (Pandas DataFrame object)
Remember we raised a question in Figure-0 “what is the data type of 'df’?” You got it, ‘df’ is of type DataFrame. DataFrame is another fundamental data structure of Pandas. As we analogically said Series is a one-dimensional array with flexible indices, here, Pandas is a two-dimensional array with both flexible row and column indices. As multiple one-dimensional arrays gave birth to a two-dimensional array, multiple Series gave birth to DataFrame. Now scrolling back to Figure-0, we can see our entire dataset is of type DataFrame which has multiple Series commonly referred as columns of DataFrame.
記得我們在圖0中提出了一個問題 :“ df”的數據類型是什么? 知道了,“ df”的類型為DataFrame。 DataFrame是Pandas的另一個基本數據結構。 正如我們以類推的方式說,Series是具有靈活索引的一維數組,在這里,Pandas是具有靈活行和列索引的二維數組。 隨著多個一維數組產生一個二維數組, 多個Series產生了DataFrame 。 現在返回到圖0,我們可以看到我們的整個數據集都是DataFrame類型,它具有多個Series,通常稱為DataFrame的列。
Like Series, DataFrame has an index attribute and column attribute.
與Series一樣,DataFrame具有索引屬性和列屬性。
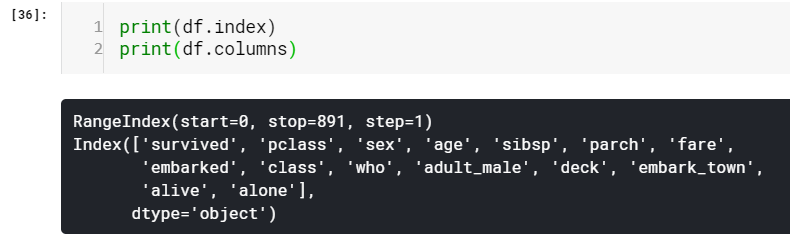
You can notice that columns are also of type pd.Index. Which means, we can access values using the column name just like any other Series or array. Exciting isn’t it! This is the power of DataFrame. Indeed, this is how I grabbed the values of column ‘survived’ in the Pandas Series object section.
您會注意到,列的類型也為pd.Index。 這意味著,我們可以像使用任何其他Series或數組一樣使用列名訪問值 。 令人興奮的不是! 這就是DataFrame的強大功能。 確實,這就是我在Pandas Series對象部分中獲取“幸存”列的值的方式。

Let me reveal another secret, neither the Series ‘survived’ nor the DataFrame 'df' have 10 rows. Actually, they have 891 rows. This brings us back to our question from Figure-0 “and what on Earth is ‘df.head(10)’ ”. With the magic of the Pandas method head() we can display only the number of rows we pass as a parameter starting from the 1st row and the default value is 5. This is why all the way down we saw only 10 rows. The opposite is the method tail(). Our entire dataset looks like this:
讓我透露另一個秘密,無論是“生存”系列還是DataFrame“ df”都沒有10行。 實際上,它們有891行。 這使我們回到圖-0中的問題 “以及'df.head(10)'在地球上是什么”。 借助Pandas方法head()的魔力,我們可以僅顯示從第1行開始作為參數傳遞的行數,默認值為5。這就是為什么一路向下只能看到10行的原因。 相反的是方法tail()。 我們的整個數據集如下所示:
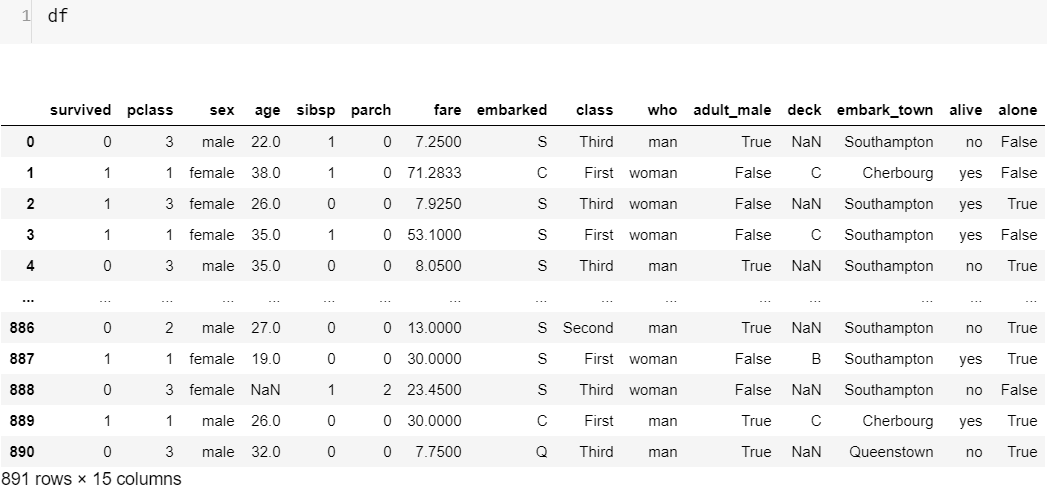
Although we can create a DataFrame from scratch we are not going to discuss because?as?a?data?scientist?we?rarely?have?to?create?any?dataset.
盡管我們可以從頭開始創建DataFrame,但我們不會討論,因為作為數據科學家,我們幾乎不必創建任何數據集。
數據選擇 (Data selection)
While we can use the Python style square-brackets notation to index and select values from our DataFrame, Pandas provides a more powerful attribute called Indexers: loc and iloc. Pandas indexers have an advantage over the regular square-bracket style. They provide us the flexibility to index a DataFrame like any other NumPy array.
雖然我們可以使用Python樣式的方括號符號來索引并從DataFrame中選擇值,但Pandas提供了一個更強大的屬性,稱為Indexers:loc和iloc。 熊貓索引器比常規方括號樣式具有優勢。 它們使我們可以像其他任何NumPy數組一樣靈活地為DataFrame編制索引。
iloc[ <row>, <column> ]
iloc [ < 行 >,<列>]
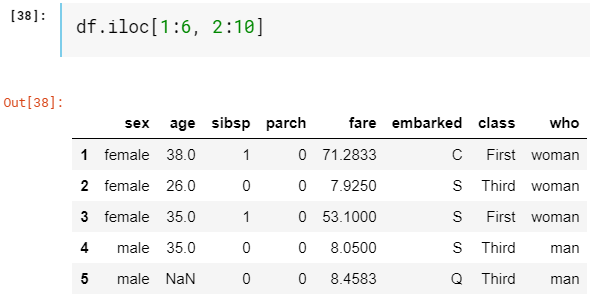
All DataFrames are indexed in two styles: explicit and implicit. We already know that we have column names survived, pclass, sex,… which act as explicit index but they are also indexed internally with integers starting from 0 just like any other Python list acting as an implicit index. Indexer iloc always refers to implicit indices. Although we have columns names we can slice them using integer indices. Let’s extract rows from 1–6 and columns from ‘sex’ to ‘who’.
所有DataFrame都有兩種樣式索引:顯式和隱式。 我們已經知道我們有幸存的列名,pclass,sex等,它們充當顯式索引,但它們也從內部以0開頭的整數建立索引,就像其他Python列表充當隱式索引一樣。 索引器iloc始終引用隱式索引。 盡管我們有列名,但我們可以使用整數索引對其進行切片。 讓我們從1–6提取行,從'sex'到'who'提取列。
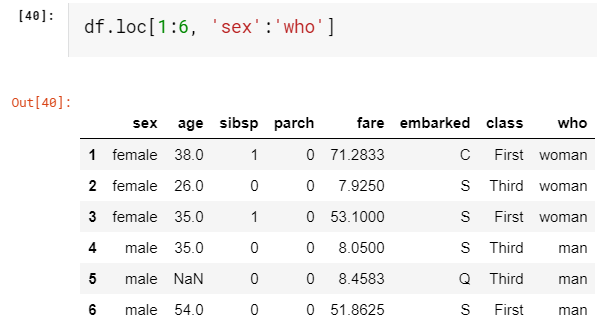
loc[ <row>, <column> ]
loc [<行>,<列>]
Same way, loc always refers to explicit indices. Let’s do the same thing as above with loc.
同樣,loc始終引用顯式索引。 讓我們使用loc進行與上述相同的操作。
If you provide a column name for iloc or integer indices for loc it will throw an error.
如果提供iloc的列名或loc的整數索引,則會拋出錯誤。
We can perform many useful and complex operations using iloc and loc. Suppose we need to know the total number of kids and teenagers aged less than 20 who survived the disaster and were alone on the Titanic.
我們可以使用iloc和loc執行許多有用和復雜的操作。 假設我們需要知道在災難中幸存下來且獨自一人在泰坦尼克號上的未滿20歲的兒童和青少年的總數。

處理缺失值/數據 (Handling missing values/data)
In real-world datasets, we can always find many missing values. This happens because not everyone provides all the information we need for our analysis or prediction, like a personal phone number. We also cannot discard the entire dataset or the column phone number from the dataset. In such cases, Pandas represents it as a NaN( not a number) and provides several methods for deleting, removing, and replacing them.
在實際數據集中,我們總是可以找到許多缺失值。 發生這種情況是因為并非每個人都提供我們進行分析或預測所需的所有信息,例如個人電話號碼。 我們也不能丟棄整個數據集或該數據集中的列電話號碼。 在這種情況下,Pandas將其表示為NaN(而不是數字),并提供了幾種刪除,刪除和替換它們的方法。
- isnull() 一片空白()
- notnull() notnull()
- dropna() dropna()
- fillna() fillna()
isnull()
一片空白()
Method isnull() returns us a boolean mask of the entire dataset in just one line of code. True if the value is missing and False otherwise.
方法nonull()僅用一行代碼就向我們返回了整個數據集的布爾掩碼。 如果該值丟失,則為True,否則為False 。

More insightful is to perform aggregation on it such as to see the total number of missing values in each column.
更有見地的是對它執行聚合,例如查看每列中缺失值的總數。

notnull()
notnull()
Method notnull() works the exact opposite of isnull(). False if the value is missing and True otherwise.
方法notnull()與isull()完全相反。 如果缺少該值,則為False;否則為True 。
dropna()
dropna()
Method dropna() is used to drop the missing values. The catch here is we cannot drop only the missing value, either we have to drop the column or row having the missing values. Axis parameters is used to mention if we wish to drop row(axis=0) or column(axis=1).
方法dropna()用于刪除缺少的值。 這里的要點是我們不能只刪除丟失的值,要么我們必須刪除具有丟失值的列或行 。 如果要刪除行(軸= 0)或列(軸= 1),則使用軸參數來提及。
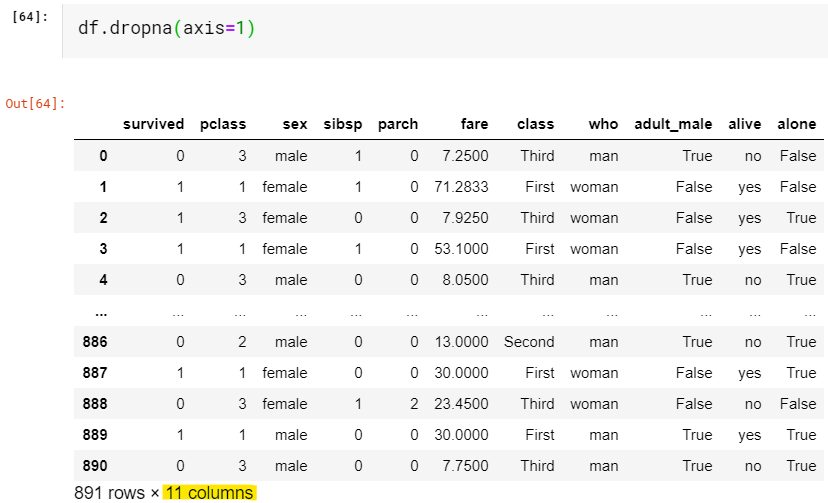
We just dropped all the columns having NaN values that are, ‘age’, ‘embarked’, ‘deck’, and ‘embark_town’. We can note the number of columns reduced from 15 to 11.
我們只刪除了所有NaN值為“年齡”,“進站”,“甲板”和“ embark_town”的列。 我們可以注意到列數從15減少到11。
fillna()
fillna()
We just lost four critical features of our data ‘age’, ‘embarked’, ‘deck’, and ‘embark_town’. We cannot afford to lose such features just like that. So here comes the lifesaver method fillna(). With fillna() we can replace the NaN value with our desired value.
我們只是丟失了數據“年齡”,“進站”,“甲板”和“ embark_town”的四個關鍵特征。 我們不能像那樣失去這些功能。 因此,出現了救生方法fillna()。 使用fillna()可以將NaN值替換為所需的值。
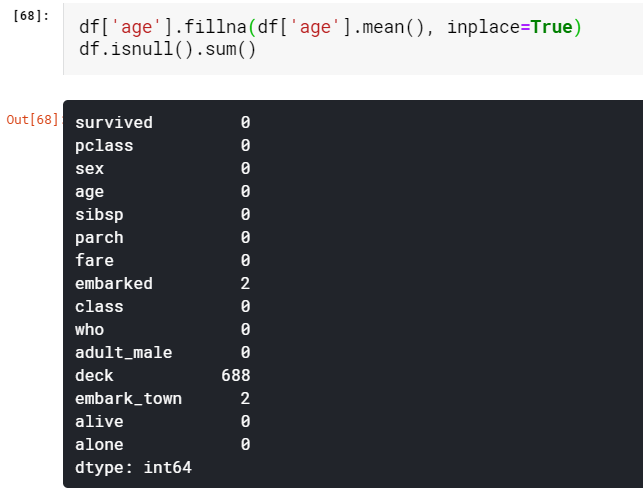
Here the critical decision will be to decide with what values we have to fill the missing values. In our case, the most sensible approach will be to fill the NaN values of age with a mean value of all the ages. Now we don’t have any missing values in our age column. The ability to decide what value to replace with will come with practice.
在這里,關鍵的決定將是決定用什么值來填補缺失的值。 在我們的案例中,最明智的方法是用所有年齡段的平均值填充年齡的NaN值。 現在,我們的“年齡”列中沒有任何缺失的值。 決定替換為什么值的能力將隨實踐而定。
排序 (Sorting)
Sorting is another powerful tool by Pandas. Unlike list and array, DataFrames are sometimes not sorted by index as well. Hence, there are two types of sorting.
排序是熊貓提供的另一個強大工具。 與列表和數組不同,DataFrame有時也不會按索引排序。 因此,有兩種類型的排序。
- Sort by index - sort_index() 按索引排序-sort_index()
- Sort by value - sort_values() 按值排序-sort_values()
Let us take a small section of data from our Titanic dataset with the help of indexing we learned to demonstrate sorting. I’m going to introduce another way of indexing called vector indexing where we can specify row and column name we want in any order as a list.
讓我們借助我們學習來演示排序的索引,從Titanic數據集中獲取一小部分數據。 我將介紹另一種索引方式,稱為向量索引 ,其中我們可以以任意順序將所需的行和列名稱指定為列表。
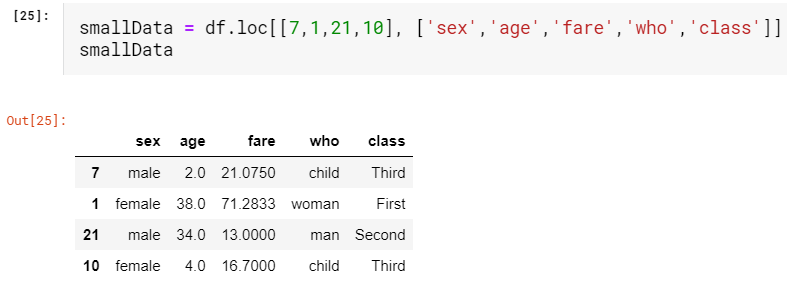
We notice that both our row index and column index are unsorted. Let’s try to sort them both. As we already know we use axis=0 for the row which is the default value and axis=1 for the column.
我們注意到我們的行索引和列索引都是未排序的。 讓我們嘗試對它們進行排序。 眾所周知,我們對默認值的行使用axis = 0,對列使用axis = 1。

Sort by values is pretty self-explanatory, we just have to decide on which column values we need the sort which can be done with the help of ‘by’ parameter.
按值排序很容易解釋,我們只需要確定哪些列值需要排序,就可以借助'by'參數來完成。
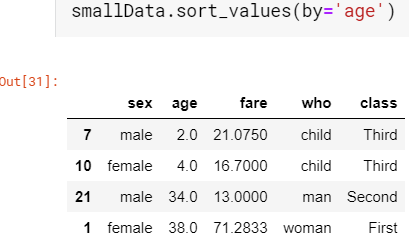
In case of conflicting values for example if two persons have the same age then who has to be on top can be decided by adding another level of sorting which can be accomplished by passing a list of column names in the ‘by’ parameter (Ex. smallData.sort_values(by=[‘age’, ‘fare’]). We can also specify the order of sorting using parameter ‘ascending=True’ and ‘ascending=Flase’.
在值沖突的情況下,例如,如果兩個人的年齡相同,則可以通過添加另一級別的排序來確定必須位于最上面的人,這可以通過在'by'參數中傳遞列名列表來實現(例如smallData.sort_values(by = ['age','fare'])。我們還可以使用參數' ascending = True'和'ascending = Flase'指定排序順序 。
排行 (Ranking)
We are seeing ranking since our 1st grade. We are always being ranked be it by our marks or our quarterly performance. Since ranking is widely used Pandas provide rank() method to ease our work. There exist few standard methods to rank like minimum, maximum, dense, and average. Let’s explore them.
自一年級以來,我們正在看到排名。 無論是我們的成績還是季度業績,我們始終被評為排名第一。 由于排名被廣泛使用,熊貓提供了rank()方法來簡化我們的工作。 很少有標準方法可以對最小值,最大值,密集和平均值進行排名。 讓我們探索它們。
Suppose I wish to rank people who board the Titanic based on the fare they paid. For the ease of understanding, we will only look at the ‘survived’ and ‘fare’ column of our data and all methods of ranking next to it.
假設我希望根據他們所支付的票價對登上《泰坦尼克號》的人進行排名。 為了便于理解,我們將僅查看數據的“幸存”和“票價”列以及其旁邊的所有排名方法。
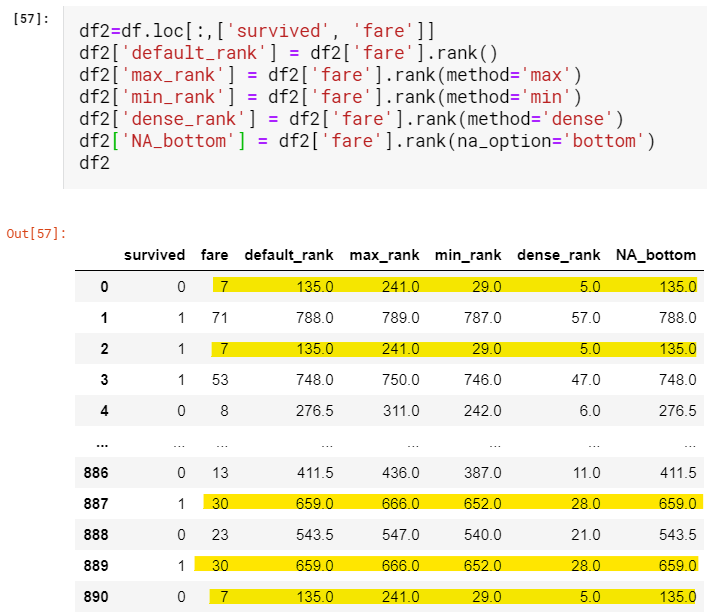
By default, ranking is done in ascending order. Method plays its part only when repeated values occur.
默認情況下,排名是按升序進行的。 僅當出現重復值時,方法才發揮作用。
- The default method is average. When values repeat the average of the positions is taken. In our case value 7 is repeated thrice and is ranked 135: (134+135+136)/3 默認方法是平均值。 當值重復時,將獲得位置的平均值。 在我們的情況下,值7重復三次,并且排名135:(134 + 135 + 136)/ 3
- In the max method the highest possible position is ranked. Since 7 is repeated thrice there is a competition between ranks 239,240 and 241, finally, 241 is assigned. Rank 239 and 240 are given to nobody. 在最大方法中,對最高可能排名進行排名。 由于重復7次,所以在239,240和241之間存在競爭,最后分配了241。 等級239和240被給予任何人。
- The exact opposite is method min. For value 7 there is a competition between ranks 29,30 and 31 finally, 29 is assigned and the positions 30 and 31 are given to nobody. 完全相反的是方法min。 對于值7,最終在等級29,30和31之間存在競爭,分配29,并且將排名30和31給予任何人。
- In the dense method, there is no competition between positions. It is exactly as min method but succeeding positions are not skipped, unlike min method. 在密集方法中,職位之間沒有競爭。 與min方法完全相同,但不跳過后續位置。
If you are reading this sentence, congratulations! You have learned more than the basics of Pandas. There are many more concepts to be covered which will be done in Unpacking Pandas for Data Science: Part 2. I will try my best to make it available as soon as possible.
如果您正在閱讀這句話,那么恭喜! 您不僅學到了熊貓的基礎知識。 在數據科學的熊貓解壓縮:第2部分中 ,將涉及更多概念。我將盡我所能,盡快使它可用。
翻譯自: https://medium.com/swlh/unpacking-pandas-for-data-science-part-1-32e480ca1688
熊貓數據集
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391537.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391537.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391537.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

2018年,你想從InfoQ獲取什么內容?丨Q言Q語

特征阻抗輸入阻抗輸出阻抗_軟件阻抗說明

)
leetcode 190. 顛倒二進制位(位運算)

JAVA基礎——時間Date類型轉換

LeetCode第五天

matplotlib可視化_使用Matplotlib改善可視化設計的5個魔術技巧

adb 多點觸碰_無法觸及的神話

robot:循環遍歷數據庫查詢結果是否滿足要求
)
leetcode 74. 搜索二維矩陣(二分)


javascript消除字符串兩邊空格的兩種方式,面向對象和函數式編程。python oop在調用時候的優點...

如何使用Retrofit,OkHttp,Gson,Glide和Coroutines處理RESTful Web服務
)
leetcode 90. 子集 II(回溯算法)

robot:linux下安裝robot環境

感知器 機器學習_機器學習感知器實現

JS解析格式化Json插件,Json和XML互相轉換插件

Python之集合、解析式,生成器,函數
)
深度神經網絡課程總結_了解深度神經網絡如何工作(完整課程)
