1. 索引的各種存儲結構及其優缺點
1.1 二叉樹
-
優點:
二叉樹是一種比順序結構更加高效地查找目標元素的結構,它可以從第一個父節點開始跟目標元素值比較,如果相等則返回當前節點,如果目標元素值小于當前節點,則移動到左側子節點進行比較,大于的情況則移動到右側子節點進行比較,反復進行操作最終移動到目標元素節點位置。 -
缺點:
在大部分情況下,我們設計索引時都會在表中提供一個自增整形字段作為建立索引的列,在這種場景下使用二叉樹的結構會導致我們的索引總是添加到右側,在查找記錄時跟沒加索引的情況是一樣的
1.2 紅黑樹
- 優點:
紅黑樹也叫平衡二叉樹,它不僅繼承了二叉樹的優點,而且解決了上面二叉樹遇到的自增整形索引的問題,從下面的動態圖中可以看出紅黑樹會左旋、右旋對結構進行調整,始終保證左子節點數 < 父節點數 < 右子節點數的規則。
- 缺點:
在數據量大的時候,深度也很大。從圖中可以看出每個父節點只能存在兩個子節點,如果我們有很多數據,那么樹的深度依然會很大,可能就會超過十幾二十層以上,對我們的磁盤尋址不利,依然會花費很多時間查找。
1.3 Hash
- 優點:
對數據進行Hash(散列)運算,主流的Hash算法有MD5、SHA256等等,然后將哈希結果作為文件指針可以從索引文件中獲得數據的文件指針,再到數據文件中獲取到數據,按照這樣的設計,我們在查找where Col2 = 22的記錄時只需要對22做哈希運算得到該索引所對應那行數據的文件指針,從而在MySQL的數據文件中定位到目標記錄,查詢效率非常高。
- 缺點:
無法解決范圍查詢(Range)的場景,比如 select count(id) from sus_user where id >10;因此Hash這種索引結構只能針對字段名=目標值的場景使用。不適合模糊查詢(like)的場景。
1.4 B-Tree
既然紅黑樹存在缺點,那么我們可以在紅黑樹的基礎上構思一種新的儲存結構。解決的思路也很簡單,既然覺得樹的深度太長,就只需要適當地增加每個樹節點能存儲的數據個數即可,但是數據個數也必須要設定一個合理的閾值,不然一個節點數據個數過多會產生多余的消耗。
1.4.1 B-Tree的一些特點
- 度(Degree)-節點的數據存儲個數,每個樹節點中數據個數大于 15/16*Degree(未驗證) 時會自動分裂,調整結構
- 葉節點具有相同的深度,左子樹跟右子樹的深度一致
- 葉節點的指針為空
- 節點中的數據key從左到右遞增排列
- 優點:
BTree的結構可以彌補紅黑樹的缺點,解決數據量過大時整棵樹的深度過長的問題。相同數量的數據只需要更少的層,相同深度的樹可以存儲更多的數據,查找的效率自然會更高。
- 缺點:
從上面得知,在查詢單條數據是非常快的。但如果范圍查的話,BTree結構每次都要從根節點查詢一遍,效率會有所降低,因此在實際應用中采用的是另一種BTree的變種B+Tree(B+樹)。
2. B+Tree—InnoDB中的索引方案
2.1 相對于BTree,B+Tree做了哪些優化?
B+Tree存儲結構,只有葉子節點存儲數據
。新的B+樹結構沒有在所有的節點里存儲記錄數據,而是只在最下層的葉子節點存儲,上層的所有非葉子節點只存放索引信息,這樣的結構可以讓單個節點存放下更多索引值,增大度Degree的值,提高命中目標記錄的幾率。
這種結構會在上層非葉子節點存儲一部分冗余數據,但是這樣的缺點都是可以容忍的,因為冗余的都是索引數據,不會對內存造成大的負擔。這種結構會在上層非葉子節點存儲一部分冗余數據,但是這樣的缺點都是可以容忍的,因為冗余的都是索引數據,不會對內存造成大的負擔。
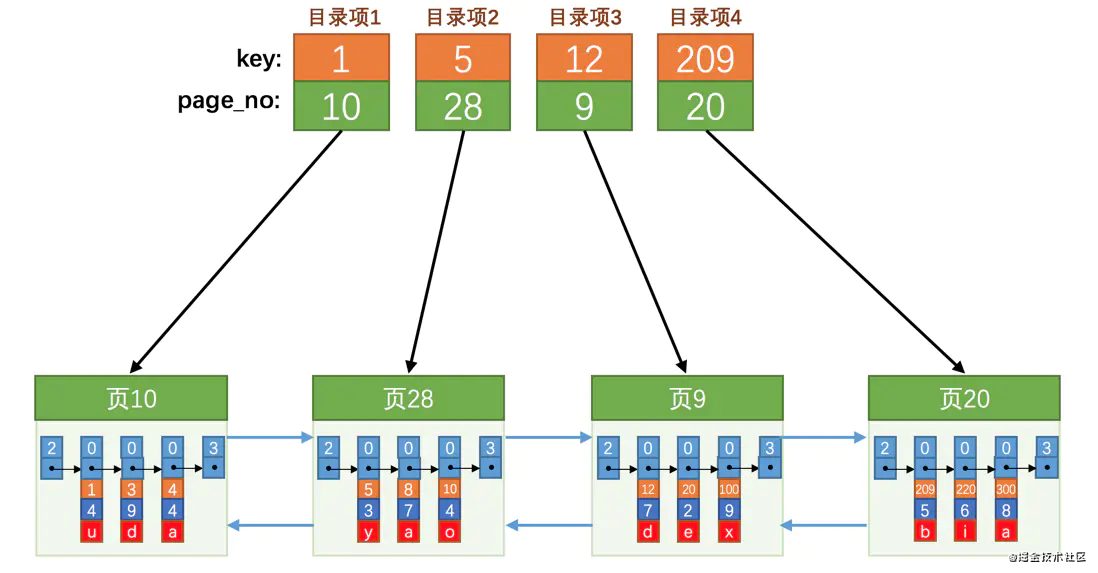
InnoDB中的索引是通過目錄項所指向的下一層頁號來一層一層去縮小搜索范圍,從而達到高效的查詢的。通過二分法對頁內的目錄項和目標值進行比對,查出下一層所在頁號,再在該頁下進行再次搜索,直到到達葉子節點
2.2 索引的存儲結構
索引中的目錄項其實長得跟我們的用戶記錄差不多,只不過目錄項中的兩個列是主鍵和頁號而已,所以InnoDB復用了之前存儲用戶記錄的數據頁來存儲目錄項,為了和用戶記錄做一下區分,我們把這些用來表示目錄項的記錄稱為目錄項記錄。
頁的組成結構也是一樣的(就是我們前邊介紹過的7個部分),都會為主鍵值生成Page Directory(頁目錄),從而在按照主鍵值進行查找時可以使用二分法來加快查詢速度。

不論是存放用戶記錄的數據頁,還是存放目錄項記錄的數據頁,我們都把它們存放到B+樹這個數據結構中了,所以我們也稱這些數據頁為節點。從圖中可以看出來,我們的實際用戶記錄其實都存放在B+樹的最底層的節點上,這些節點也被稱為葉子節點或葉節點,其余用來存放目錄項的節點稱為非葉子節點或者內節點,其中B+樹最上邊的那個節點也稱為根節點。
2.3 聚簇索引
我們上邊介紹的B+樹本身就是一個目錄,或者說本身就是一個索引。它有兩個特點:
使用記錄主鍵值的大小進行記錄和頁的排序,這包括三個方面的含義:
-
頁內的記錄是按照主鍵的大小順序排成一個單向鏈表。
-
各個存放用戶記錄的頁也是根據頁中用戶記錄的主鍵大小順序排成一個雙向鏈表。
-
存放目錄項記錄的頁分為不同的層次,在同一層次中的頁也是根據頁中目錄項記錄的主鍵大小順序排成一個雙向鏈表。
B+樹的葉子節點存儲的是完整的用戶記錄。
所謂完整的用戶記錄,就是指這個記錄中存儲了所有列的值(包括隱藏列)。
聚簇索引的優缺點
- 可以把相關數據保存在一起。
- 數據訪問更快。
- 使用覆蓋索引掃描的查詢可以直接使用頁節點中的主鍵值。
- 如果表在設計和查詢的時候能充分利用以上特點,將會極大提高性能。當然,聚簇索引也有它的缺點:
- 聚簇索引最大限度提高了I/O密集型應用的性能,但如果所有的數據都存放在內存中,聚簇索引就沒有優勢了。
- 插入速度嚴重依賴插入順序。這也是為什么InnoDB一般都會設置一個自增的int列作為主鍵。
- 更新聚簇索引的代價很高,因為會強制InnoDB將每個被更新的行移到新的位置。
- 如果不安順序插入新數據時,可能會導致"頁分裂"。
- 二級索引可能會比想象的更大。因為在二級索引的頁子節點中包含了引用行的主鍵列。
- 二級索引訪問可能會需要進行回表查詢。
2.4 二級索引
聚簇索引是根據主鍵比較大小的,而二級索引是通過用戶建立索引的字段來比較大小的。
并且B+樹的葉子節點存儲的并不是完整的用戶記錄,而只是c2列+主鍵這兩個列的值。目錄項記錄中不再是主鍵+頁號的搭配,而變成了c2列+頁號+主鍵的搭配。
并且如果需要查詢非索引字段的信息,需要拿著主鍵id回去聚簇索引中查找
2.5 聯合索引
在二級索引的基礎,采用多個字段進行比較,先根據最左邊的索引排一次序,如果存在相同的值,則根據次左邊的索引字段進行比較,如此類推。
3. InnoDB的B+樹索引的注意事項
B+樹的形成過程是這樣的
-
每當為某個表創建一個B+樹索引(聚簇索引不是人為創建的,默認就有)的時候,都會為這個索引創建一個根節點頁面。最開始表中沒有數據的時候,每個B+樹索引對應的根節點中既沒有用戶記錄,也沒有目錄項記錄。
-
隨后向表中插入用戶記錄時,先把用戶記錄存儲到這個根節點中。
-
當根節點中的可用空間用完時繼續插入記錄,此時會將根節點中的所有記錄復制到一個新分配的頁,比如頁a中,然后對這個新頁進行頁分裂的操作,得到另一個新頁,比如頁b。這時新插入的記錄根據鍵值(也就是聚簇索引中的主鍵值,二級索引中對應的索引列的值)的大小就會被分配到頁a或者頁b中,而根節點便升級為存儲目錄項記錄的頁。
這個過程需要大家特別注意的是:一個B+樹索引的根節點自誕生之日起,便不會再移動。這樣只要我們對某個表建立一個索引,那么它的根節點的頁號便會被記錄到某個地方,然后凡是InnoDB存儲引擎需要用到這個索引的時候,都會從那個固定的地方取出根節點的頁號,從而來訪問這個索引。



—索引使用)
![[BZOJ1626][Usaco2007 Dec]Building Roads 修建道路](http://pic.xiahunao.cn/[BZOJ1626][Usaco2007 Dec]Building Roads 修建道路)
)


)






-變量)
)


)