雙城記s001
Keywords: Data science, Machine learning, Python, Web scraping, Foursquare
關鍵字:數據科學,機器學習,Python,Web抓取,Foursquare

The post covers the methodology and analysis used for the final capstone project in the IBM Data Science Professional course. Detailed report, code and results can be found on Github and are linked towards the end of the post.
這篇文章涵蓋了 IBM Data Science Professional 課程中 用于最終頂點項目的方法和分析 。 可以在Github上找到詳細的報告,代碼和結果,并在文章末尾鏈接。
1.簡介 (1. Introduction)
Picking a city, when it comes to London and Paris is always a hard decision as both these cities are truly global, multicultural, and cosmopolitan cities found at the heart of two European nations. Along with being two of Europe’s most important diplomatic centres, they are major centres for finance, commerce, sciences, fashion, arts, culture and gastronomy. Both London (capital of the United Kingdom) and Paris (capital of France) have a rich history and are two of the most visited and sought-after cities in Europe. London is the largest city within the UK and stands on River Thames in South East England. Paris, on the other hand, is located in the north-central part of the nation. Similar to London, the city also stands along a river, commonly known as the Seine River.
在倫敦和巴黎時,選擇一個城市始終是一個艱難的決定,因為這兩個城市都是真正的全球化,多元文化和國際化城市,位于兩個歐洲國家的心臟地帶。 它們是歐洲最重要的兩個外交中心,也是金融,商業,科學,時尚,藝術,文化和美食的主要中心。 倫敦(英國首都)和巴黎(法國首都)都有著悠久的歷史,并且是歐洲訪問量最大,最受歡迎的兩個城市。 倫敦是英國最大的城市,位于英格蘭東南部的泰晤士河上。 另一方面,巴黎位于該國中北部。 與倫敦類似,這座城市也沿著一條河流而行,通常被稱為塞納河。
Our goal is to perform a comparison of the two cities to see how similar or dissimilar they are. Such techniques allow users to identify similar neighbourhoods among cities based on amenities or services being offered locally, and thus can help in understanding the local area activities, what are the hubs of different activities, how citizens are experiencing the city, and how they are utilising its resources.
我們的目標是對兩個城市進行比較,以了解它們之間的相似程度或相異程度。 此類技術使用戶可以根據本地提供的便利設施或服務在城市中識別相似的社區,從而有助于理解本地活動,不同活動的樞紐是什么,市民如何體驗城市以及他們如何利用它的資源。
What kind of clientele would benefit from such an analysis?
什么樣的客戶將從這種分析中受益?
- A potential job seeker with transferable skills may wish to search for jobs in selective cities which provide the most suitable match for their qualifications and experience in terms of salaries, social benefits, or even in terms of a culture fit for expats. 潛在的具有可轉讓技能的求職者可能希望在選擇的城市中尋找工作,這些城市在薪資,社會福利乃至適合外籍人士的文化方面提供與其資格和經驗最匹配的職位。
- Further, a person buying or renting a home in a new city may want to look for recommendations for locations in the city similar to other cities known to them. 此外,在新城市中購買或租賃房屋的人可能希望尋找與他們所熟悉的其他城市相似的城市中的位置的推薦。
- Similarly, a large corporation looking to expand its locations to other cities might benefit from such an analysis. 同樣,希望將其地點擴展到其他城市的大型公司可能會從這種分析中受益。
- Many within-city urban planning computations might also benefit from modelling a city’s relationship to other cities. 城市內部許多城市規劃計算也可能會受益于對城市與其他城市的關系進行建模。
2.數據準備 (2. Data Preparation)
To solve the problem at hand, data extraction was done as follows:
為了解決當前的問題,數據提取按以下方式進行:
Web scraping: City data was extracted from the respective Wikipedia pages [1][2] using the Requests and BeautifulSoup libraries.
Web抓取:使用Requests和BeautifulSoup庫從相應的Wikipedia頁面[1] [2]中提取城市數據。
## URL to extract City neighbourhood information
urlL = "https://en.wikipedia.org/wiki/List_of_London_boroughs"
urlP = "https://en.wikipedia.org/wiki/Arrondissements_of_Paris"
pageLondon = urllib.request.urlopen(urlL)
pageParis = urllib.request.urlopen(urlP)wikitablesL = read_html(urlL, attrs={"class":"wikitable"})
print ("Extracted {num} wikitables from London Wikipedia".format(num=len(wikitablesL)))
wikitablesP = read_html(urlP, attrs={"class":"wikitable"})
print ("Extracted {num} wikitables from Paris Wikipedia".format(num=len(wikitablesP)))dfP = wikitablesP[0]
dfL0 = wikitablesL[0]
dfL1 = wikitablesL[1]## Request & response
s = requests.Session()
responseL = s.get(urlL,timeout=10)Further data cleaning was performed on the extracted data in order to store relevant information about its neighbourhoods, their corresponding coordinates, area and population, and the corresponding borough numbers.
為了對提取的數據進行進一步的數據清理,以便存儲有關其鄰域,其相應坐標,面積和人口以及相應區號的相關信息。
def scrapeLondonTable(table):
c1=[]
c2=[]
c3=[]
c4=[]
c5=[]
c6=[]
c7=[]
c8=[]
c9=[]
c10=[]
c11=[]
for row in table.findAll("tr"):
cellsL = row.findAll('td')
if len(cellsL)==10: #Only extract table body not heading
c1.append(cellsL[0].find('a').text)
c2.append(cellsL[1].find(text=True))
c3.append(cellsL[2].find(text=True))
c4.append(cellsL[3].find(text=True))
c5.append(cellsL[4].find(text=True))
c6.append(cellsL[5].find(text=True))
c7.append(cellsL[6].find(text=True))
c8.append(cellsL[7].find(text=True))
c9.append(cellsL[8].find('span',{'class': 'geo'}))
c10.append(cellsL[9].find(text=True))
# create a dictionary
d = dict([(x,0) for x in headerL])
# append dictionary with corresponding data list
d['Borough'] = c1
d['Inner']= c2
d['Status']=c3
d['Local authority']=c4
d['Political control']=c5
d['Headquarters']=c6
d['Area (sq mi)']=c7
d['Population (2013 est)[1]']=c8
d['Co-ordinates']=c9
d[' Nr. in map']=c10
# convert dict to DataFrame
dfL_table = pd.DataFrame(d)
## convert Area units to kms^2
#dfL["Area"] = 2.59 * (pd.to_numeric(dfL["Area"]))
Latitude = []
Longitude = []
for i in range(len(dfL_table)):
locationSplit = dfL_table['Co-ordinates'].iloc[i].getText().split("; ")
Latitude.append(locationSplit[0])
Longitude.append(locationSplit[1])
dfL_table['Latitude'] = Latitude
dfL_table['Longitude'] = Longitude
dfL_table.drop(['Inner','Status','Local authority','Political control','Headquarters','Co-ordinates'],axis=1,inplace=True)
dfL = dfL_table.rename(columns={'Area (sq mi)': 'Area', 'Population (2013 est)[1]': 'Population',' Nr. in map':'District Number'})
dfL['District Number'] = dfL['District Number'].astype(int)
for i in range(len(dfL)):
dfL['Area'].iloc[i] = float(re.findall(r'[\d\.\d]+', dfL['Area'].iloc[i])[0])
dfL['Population'].iloc[i] = int(dfL['Population'].iloc[i].replace(',',''))
return dfLAfter the necessary data cleaning, we get the following data frames for our study:
經過必要的數據清潔后,我們將獲得以下數據框用于研究:


Foursquare location data: Foursquare is a social location service that allows users to explore the world around them. Foursquare API provides location based experiences with diverse information about venues, users, photos, and check-ins. We took advantage of Foursquare data to extract venue based information for all of the neighbourhoods under study. The call to the API returns a JSON file and we need to turn that into a data-frame. The location data was then used to find the top and unique venues in each of the neighbourhoods. I decided to pick 100 most popular spots in each neighbourhood within a radius of 1 km.
Foursquare位置數據: Foursquare是一種社交位置服務,允許用戶探索周圍的世界。 Foursquare API提供基于位置的體驗,其中包含有關場所,用戶,照片和簽到的各種信息。 我們利用Foursquare數據為正在研究的所有街區提取基于場所的信息。 對該API的調用會返回一個JSON文件,我們需要將其轉換為數據幀。 然后使用位置數據查找每個街區中最重要的地點。 我決定在方圓1公里以內的每個社區中挑選100個最受歡迎的景點。
3.探索性數據分析 (3. Exploratory Data Analysis)
城市資料 (City data)
Wikipedia data provided us with information about the coordinates, area, and population of each borough in the respective cities. One can use this information to visualise a map of the city marking each Borough according to its population density. ‘Geocoder’ and the ‘folium map’ libraries were used for data visualisation on leaflet maps, where boroughs were marked according to its population density. The higher the density, the bigger the radius of the marker.
維基百科的數據為我們提供了有關各個城市中每個自治市鎮的坐標,面積和人口的信息。 可以使用此信息來可視化根據自治市鎮的人口密度標記每個自治市鎮的城市地圖。 “ 地理 編碼器 ”和“ 葉片地圖 ”庫用于在傳單地圖上進行數據可視化,在傳單地圖上根據人口密度對行政區進行標記。 密度越高,標記的半徑越大。


場地數據 (Venue data)
Foursquare location data gave information about the list of venues within a 1 km radius of each borough. This is a reasonable distance to understand the characteristics of the neighbourhood.
Foursquare位置數據提供了有關每個市鎮1公里半徑內的場所列表的信息。 這是理解社區特征的合理距離。
## Extracting Foursquare venue data
LIMIT = 100 # limit of number of venues returned by Foursquare API
radius = 1000 # define radiusdef getNearbyVenues(names, latitudes, longitudes, radius=500):
venues_list=[]
for name, lat, lng in zip(names, latitudes, longitudes):
print(name)
# create the API request URL
url = 'https://api.foursquare.com/v2/venues/explore?&client_id={}&client_secret={}&v={}&ll={},{}&radius={}&limit={}'.format(
CLIENT_ID,
CLIENT_SECRET,
VERSION,
lat,
lng,
radius,
LIMIT)
# make the GET request
results = requests.get(url).json()["response"]['groups'][0]['items']
# return only relevant information for each nearby venue
venues_list.append([(
name,
lat,
lng,
v['venue']['name'],
v['venue']['location']['lat'],
v['venue']['location']['lng'],
v['venue']['categories'][0]['name']) for v in results])
nearby_venues = pd.DataFrame([item for venue_list in venues_list for item in venue_list])
nearby_venues.columns = ['Borough',
'Borough Latitude',
'Borough Longitude',
'Venue',
'Venue Latitude',
'Venue Longitude',
'Venue Category']
return(nearby_venues)print("Getting venues inside the following Boroughs of London:")
London_venues = getNearbyVenues(names=tableL['Borough'],
latitudes=tableL['Latitude'],
longitudes=tableL['Longitude']
)In total, there were around 219 unique venue categories in London and 180 in Paris. I used this information to visualise the most common venues in some of the central London and central Paris boroughs on a bar chart.
總體而言,倫敦大約有219種獨特的場館類別,而巴黎則有180種。 我使用此信息以條形圖可視化了倫敦市中心和巴黎市中心的一些最常見場所。
## Picking major districts inside inner London and inner Paris respectively
districtsL = ['City of London','Westminster','Kensington and Chelsea','Hammersmith and Fulham', 'Wandsworth']
districtsP = ['Louvre, Bourse, Temple, H?tel-de-Ville', 'Panthéon', 'Luxembourg', 'Palais-Bourbon', 'élysée']def nearbyvenues_count(venues_df, district):
venues_count = venues_df
venues_count = venues_count.rename(columns={'Venue Category': 'Category'})
venues_count = venues_count.groupby(['Borough']).Category.value_counts().to_frame("Counts")
fig, ax = plt.subplots(1,1,figsize=(20, 7))
fig.subplots_adjust(left=0.115, right=0.88)
venues_plot = venues_count['Counts'].loc[district][:10].head(10)
pos = np.arange(len(venues_plot))
ax.set_title(district,size=20)
freqchart = ax.barh(pos, venues_plot,align='center',height=0.5,tick_label=venues_plot.index)
return freqchart



While the most common venues in central London varied between cafes/coffee shops, pubs, juice bars or hotels, the most common venues in Boroughs in the central or major areas of Paris were mostly French or Italian restaurants along with hotels.
倫敦市中心最常見的場所因咖啡館/咖啡店,酒吧,果汁吧或酒店而異,而巴黎市中心或主要地區的自治市鎮最常見的場所主要是法國或意大利餐廳以及酒店。
In order to explore the venue data in a more comprehensive way and further use it for analysis, foursquare venue data was arranged into pandas data frame as follows:
為了更全面地探索場館數據并進一步用于分析,將Foursquare場館數據整理到熊貓數據框中,如下所示:
First, create a data-frame with pandas one hot encoding for each of the venue categories
首先,為每個場所類別的熊貓創建一個數據編碼的熱編碼
Obtain the mean of each one-hot encoded venue categories using pandas groupby method on the borough column
使用自治市鎮列上的pandas groupby方法獲得每個熱門編碼場所類別的平均值
- Use the venue category mean to obtain a venue based data frame for each city giving the ten most common venues for each borough 使用場所類別的意思是獲取每個城市的場所數據框架,并給出每個行政區的十個最常見場所
## Categorizing venues into pandas# one hot encoding
London_onehot = pd.get_dummies(London_venues[['Venue Category']], prefix="", prefix_sep="")# add neighborhood column back to dataframe
London_onehot['Borough'] = London_venues['Borough'] # move neighborhood column to the first column
fixed_columns = [London_onehot.columns[-1]] + list(London_onehot.columns[:-1])
London_onehot = London_onehot[fixed_columns]
London_onehot.head()
London_grouped = London_onehot.groupby('Borough').mean().reset_index()def return_most_common_venues(row, num_top_venues):
row_categories = row.iloc[1:]
row_categories_sorted = row_categories.sort_values(ascending=False)
return row_categories_sorted.index.values[0:num_top_venues]num_top_venues = 10
indicators = ['st', 'nd', 'rd']# create columns according to number of top venues
columns = ['Borough']for ind in np.arange(num_top_venues):
try:
columns.append('{}{} Most Common Venue'.format(ind+1, indicators[ind]))
except:
columns.append('{}th Most Common Venue'.format(ind+1))# create a new dataframe for London
Londonboroughs_venues_sorted = pd.DataFrame(columns=columns)
Londonboroughs_venues_sorted['Borough'] = London_grouped['Borough']for ind in np.arange(London_grouped.shape[0]):
Londonboroughs_venues_sorted.iloc[ind, 1:] = return_most_common_venues(London_grouped.iloc[ind, :], num_top_venues)
Londonboroughs_venues_sorted.head(10)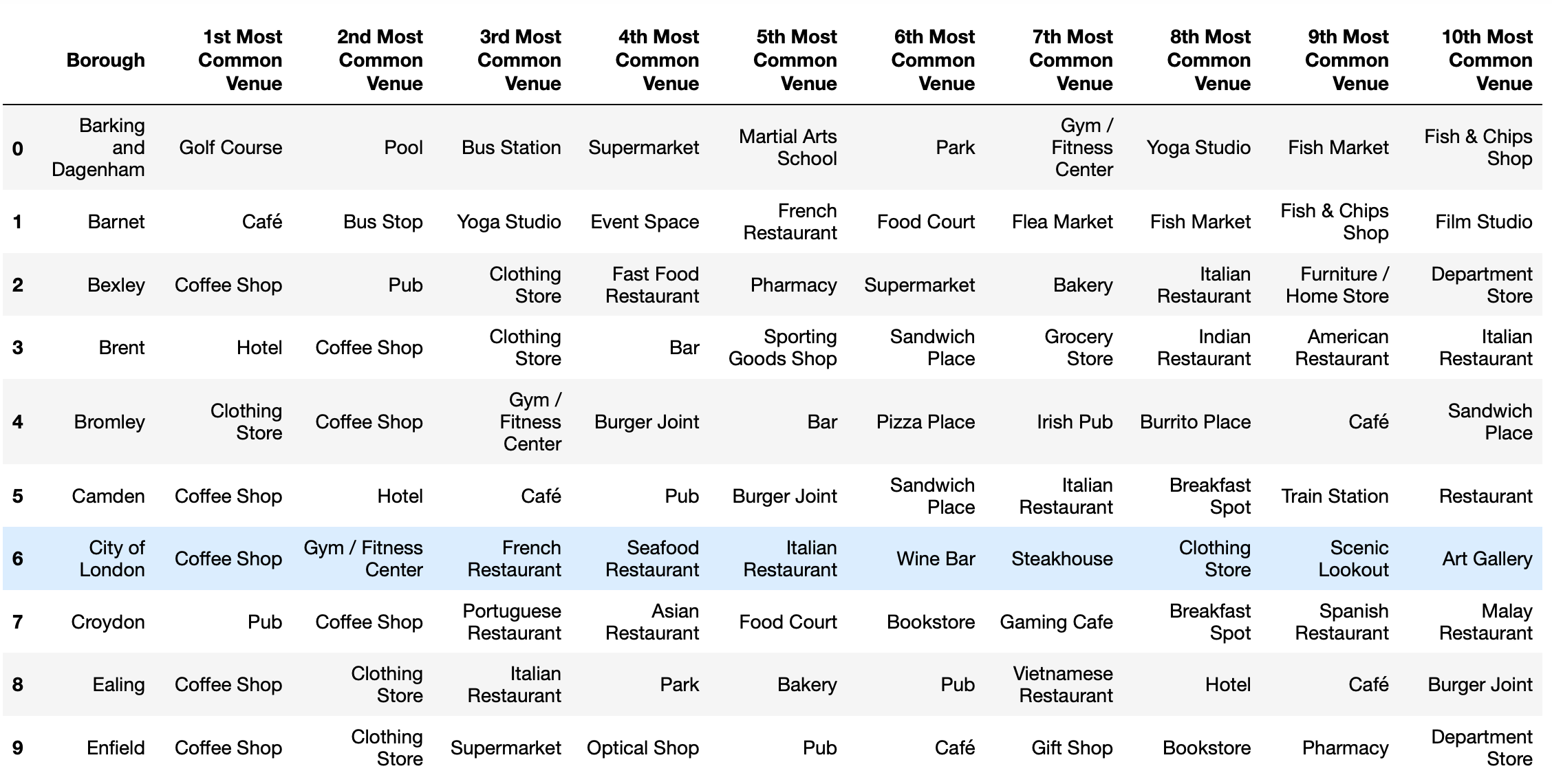

The information providing the most common venue data per borough was then used to categorise the neighbourhoods into clusters using ‘k-means’.
然后使用每個行政區提供最常見場地數據的信息,使用“ k均值 ”將鄰域分類為聚類。
4.聚集鄰里 (4. Clustering Neighbourhoods)
I performed a clustering analysis using the ‘k-means’ algorithm in order to categorise similar neighbourhoods into clusters based on the similarities provided by the venue categories. To gain some understanding, I decided to do some investigation into the number of clusters (k) to be used as follows:
我使用“ k-means ”算法進行了聚類分析,以便根據會場類別提供的相似性將相似的鄰域分類為聚類。 為了獲得一些了解,我決定對要使用的簇數(k)進行如下調查:

Elbow method: I tried to determine the effective number of clusters (k) using the elbow method for London clustering analysis and saw a small kink around k = 6 (although not clear and sharp). The elbow method uses Within-Cluster-Sum of Squared Errors (WSS) for different values of k and one can choose the value of k for which WSS starts to diminish and can be seen as an elbow in the WSS-versus-k plot. However for Paris data, no kink was explicitly seen so I tried to look into the Silhouette score for clustering for each value of k. The silhouette value measures how similar a point is to its own cluster (cohesion) compared to other clusters (separation). A value of around k = 2 gave the global maximum for the silhouette score. Although one can see from these studies that we do not have clearly clustered data, I decided to categorise London neighbourhoods into 6 set of clusters and Paris neighbourhoods into 2 set of clusters for the purpose of our analysis. It might be useful to look into a more detailed analysis to optimise k in the future for such studies.
彎頭法 :我嘗試使用彎頭法確定有效的聚類數(k)進行倫敦聚類分析,并在k = 6處發現了一個小扭結(盡管不清楚且清晰)。 彎頭方法對k的不同值使用平方誤差的簇內和之和(WSS),并且可以選擇WSS開始減小的k值,并且可以將其視為WSS-vs-k圖中的彎頭。 但是,對于巴黎數據,沒有明確看到扭結,因此我嘗試查看Silhouette得分以對k的每個值進行聚類。 輪廓值衡量的是一個點與其自身的群集(內聚)相比其他群集(分離)的相似程度。 k = 2左右的值給出了輪廓分數的全局最大值。 盡管可以從這些研究中看出我們沒有明確的聚類數據,但出于分析的目的,我還是決定將倫敦社區分為6組聚類,將巴黎社區分為2組聚類。 對于此類研究,將來進行更詳細的分析以優化k可能會很有用。
5.結果討論 (5. Discussion of Results)
In order to solve the business problem at hand, we considered the 33 boroughs of inner and outer London and 16 districts of inner Paris. Although each of these neighbourhoods might be unique, some of them might be more similar in terms of the kind of amenities they offer. A clustering analysis was performed to find those similar neighbourhoods. One thing to note is that the data extracted from the London Wiki gave information about boroughs in inner and outer London and thus taking the suburban area into account. While the data provided by the Paris Wiki, only gave information about the districts inside inner Paris and not including much information about the large suburbs surrounding Paris where a decent fraction of the population is spread. Thus, the analysis performed in this study would need more information to compare the cities on an equal footing.
為了解決當前的業務問題,我們考慮了倫敦內部和外部的33個行政區和巴黎內部的16個區。 盡管這些社區中的每一個都可能是唯一的,但就其提供的便利設施而言,其中一些社區可能更加相似。 進行聚類分析以找到那些相似的社區。 要注意的一件事是,從倫敦Wiki提取的數據提供了有關倫敦內部和外部倫敦自治市鎮的信息,因此考慮了郊區。 盡管巴黎Wiki提供的數據僅提供了有關巴黎內部地區的信息,但并未提供有關巴黎周圍人口分散的大郊區的大量信息。 因此,在這項研究中進行的分析將需要更多信息,以平等地比較城市。
Some of the inferences which were drawn from the explanatory analysis are:
從解釋性分析中得出的一些推論是:
- Most of the areas in inner Paris are more densely populated than similar areas in inner London. While there are 9 (out of 33) boroughs in London with a density greater than 10000, only 3 districts (out of 16) in Paris have a density of less than 10000 and 4 of the neighbourhoods above 30000. 巴黎內的大多數地區比倫敦內的類似地區人口稠密。 倫敦有9個行政區(33個行政區)的密度大于10000,而巴黎僅有3個區(16個行政區)的密度小于10000,而4個街區的30000以上。
- The dense boroughs are more concentrated towards the inner regions of London in the map than the outer regions and for Paris the most dense boroughs lie towards north of Seine river. 在地圖中,稠密的行政區比倫敦更集中于倫敦的內部區域,而對于巴黎來說,最密集的行政區位于塞納河以北。
- Initial exploration of the Foursquare venue data revealed that coffee shops, cafes, pubs and juice bars are the most common venues in five main boroughs in inner London. Similarly French restaurants, Italian restaurants, and hotels were the most common venues seen in five main boroughs of inner Paris. 對Foursquare場地數據的初步探索顯示,咖啡店,咖啡館,酒吧和果汁吧是倫敦市中心五個主要行政區中最常見的場所。 同樣,法國餐廳,意大利餐廳和酒店是巴黎市中心五個主要行政區中最常見的場所。
Further, machine learning analysis of the venue based data revealed most of the boroughs of London can be grouped together into one cluster. The most common venues in such boroughs were always coffee shops, cafes, pubs, hotels or restaurants followed by some kind of clothing, convenience stores or pharmacies. Paris was categorised into two separate clusters in total. Although the most common venue in both the clusters was always a French restaurant, it was followed by a high number of Italian restaurants, hotels, and cafes in the first cluster and variations of other cuisine restaurants, bars, bistros, clothing stores or supermarkets in the second cluster.
此外,對基于場所的數據進行的機器學習分析表明,倫敦大部分行政區都可以歸為一個集群。 在這些自治市鎮中,最常見的場所通常是咖啡店,咖啡館,酒吧,酒店或飯店,然后是某些服裝,便利店或藥店。 巴黎總共分為兩個單獨的類別。 盡管這兩個集群中最常見的場所始終是法國餐廳,但在第一個集群中緊隨其后的是大量意大利餐廳,酒店和咖啡館,以及其他美食餐廳,酒吧,小酒館,服裝店或超市第二個集群。




The most common type of venues in either of the cities are mostly restaurants, cafes, hotels, pubs/bars, clothing stores or parks. This in a way highlights that how similar the cities of London and Paris are in terms of services being offered.
在這兩個城市中,最常見的場所類型主要是餐館,咖啡館,酒店,酒館/酒吧,服裝店或公園。 這從某種程度上突出了倫敦和巴黎城市在提供服務方面的相似程度。
One can further use the venue data to compare the cities is a more comprehensive way where one can also explore different levels of spatial aggregation, namely grids, neighbourhoods, and the city as a whole. The level of spatial aggregation can be an important factor when characterising a city in terms of its venues.
人們可以進一步使用場館數據來比較城市,這是一種更全面的方法,其中還可以探索不同級別的空間聚合,即網格,街區和整個城市。 當根據地點來表征城市時,空間聚集的水平可能是重要的因素。
Some of the questions one can answer with different levels of spatial aggregation could be:
人們可以用不同級別的空間聚合來回答的一些問題可能是:
- How are the venue categories distributed inside a neighbourhood, i.e., is the neighbourhood more of a residential or a commercial one. 場地類別如何在鄰里分布,即鄰里更多是住宅或商業場所。
- Which city has the highest number of each of the amenities (bars, restaurants, parks, universities, libraries, shopping centres, etc.) 每種設施(酒吧,飯店,公園,大學,圖書館,購物中心等)中哪個城市擁有最多的設施
六,結論 (6. Conclusion)
To summarise, analysing cities using venue based data from Foursquare lead to an overall understanding of the type of venues in each neighbourhood and presented some of the key features of the cities but the level of data is not adequate to provide a comprehensive analysis for a city-to-city comparison. For a potential interested person (job-seeker or person deciding to move to either of the cities) or a bigger clientele like a business corporation or city planners, one would need to do a more detailed analysis adding features such as rents, salaries, transportation, cost of living, growth rate, economy, etc.
總而言之,使用來自Foursquare的基于場所的數據來分析城市,可以全面了解每個社區中場所的類型,并介紹了城市的一些關鍵特征,但是數據水平不足以對城市進行全面分析到城市比較。 對于潛在的有興趣的人(求職者或決定搬到兩個城市的人)或更大的客戶(例如商業公司或城市規劃師),您需要進行更詳細的分析,添加諸如租金,薪水,交通等功能,生活費用,增長率,經濟狀況等。
The capstone project provided a medium to understand in depth about how real life data science projects work and what all steps go in building a data science methodology. All steps from understanding the business problem, data understanding to data preparation, and model building were discussed in detail here. Many drawbacks of the current analysis and further ways to improve the analysis were also mentioned. This was an initial attempt to understand and solve the business problem at hand. However, there still exists a huge potential to extend this project in real life scenarios.
最高項目為深入了解現實生活中的數據科學項目的工作方式以及構建數據科學方法論的所有步驟提供了一種媒介。 這里詳細討論了從理解業務問題,數據理解到數據準備以及模型構建的所有步驟。 還提到了當前分析的許多缺點以及改進分析的其他方法。 這是理解和解決當前業務問題的最初嘗試。 但是,在現實生活中仍存在將這個項目擴展的巨大潛力。
About Me:
關于我:
I am a Physicist and have been analysing particle physics data for several years now. I have moved for work between Karlsruhe, Geneva, Sao Paulo, and Chicago in the last few years and currently am residing in Paris. Although such a data analysis would be a stepping stone to design a methodology to compare any of the cities, comparing London and Paris was driven by a personal choice of love for those cities. ?
我是物理學家,多年來一直在分析粒子物理數據。 過去幾年中,我曾在卡爾斯魯厄,日內瓦,圣保羅和芝加哥之間工作,目前居住在巴黎。 盡管這樣的數據分析將成為設計比較任何城市的方法的墊腳石,但倫敦和巴黎的比較是由個人對這些城市的熱愛所推動的。 ?
You can find more about me on Linkedin.
您可以在Linkedin上找到有關我的更多信息。
Links to the project summary and code.
鏈接到項目摘要和代碼 。

翻譯自: https://towardsdatascience.com/a-tale-of-two-cities-e693c15b3ddb
雙城記s001
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391433.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391433.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391433.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

python:linux中升級python版本

)
783. 二叉搜索樹節點最小距離(dfs)

linux epoll機制對TCP 客戶端和服務端的監聽C代碼通用框架實現

linux中安裝robot環境

angular 模塊構建_我如何在Angular 4和Magento上構建人力資源門戶

tableau破解方法_使用Tableau瀏覽Netflix內容的簡單方法


面試題字符集和編碼區別_您和理想工作之間的一件事-編碼面試!
-變量)
初探Golang(1)-變量
)
macaca web(4)

linux中安裝cx_Oracle

rfm模型分析與客戶細分_如何使用基于RFM的細分來確定最佳客戶
)
leetcode 208. 實現 Trie (前綴樹)
 CSDN篇)
那些年收藏的技術文章(一) CSDN篇
獲取易于閱讀的JSON樹)
chrome json插件_如何使用此免費的Chrome擴展程序(或Firefox插件)獲取易于閱讀的JSON樹


數據倉庫項目分析_數據分析項目:倉庫庫存
)
leetcode 213. 打家劫舍 II(dp)
