1. Docker 的技術實現
Docker 的實現,主要歸結于三大技術:
- 命名空間 ( Namespaces )
- 控制組 ( Control Groups )
- 聯合文件系統 ( Union File System )

1.1 Namespace
命名空間可以有效地幫助Docker分離進程樹、網絡接口、掛載點以及進程間通信等資源。Linux 的命名空間機制提供了以下七種不同的命名空間,包括 CLONE_NEWCGROUP、CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER 和 CLONE_NEWUTS,通過這七個選項我們能在創建新的進程時設置新進程應該在哪些資源上與宿主機器進行隔離。
命名空間是 Linux 核心在 2.4 版本后逐漸引入的一項用于運行隔離的模塊。以進程為例,通過 PID Namespace,我們可以造就一個獨立的進程運行空間,在其中進程的編號又會從 1 開始。在這個空間中運行的進程,完全感知不到外界系統中的其他進程或是其他進程命名空間中運行的進程。
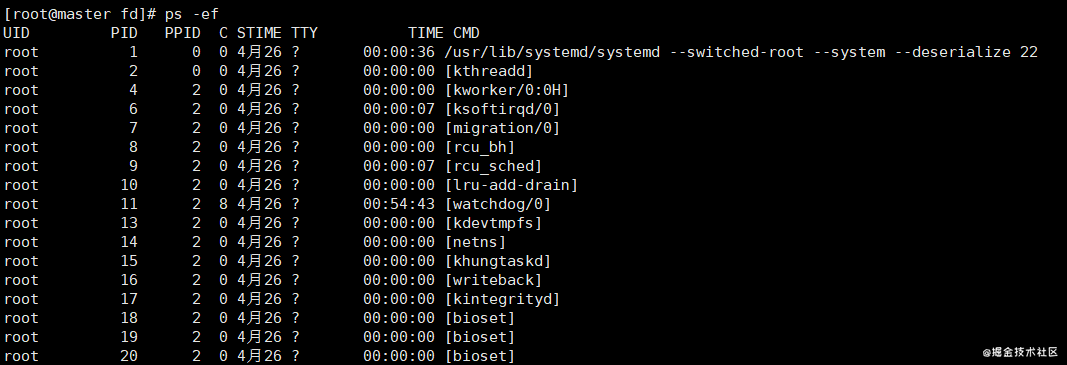
當前機器上有很多的進程正在執行,在上述進程中有兩個非常特殊,一個是 pid 為 1 的 /sbin/init 進程,另一個是 pid 為 2 的 kthreadd 進程,這兩個進程都是被 Linux 中的上帝進程 idle 創建出來的,其中前者負責執行內核的一部分初始化工作和系統配置,也會創建一些類似 getty 的注冊進程,而后者負責管理和調度其他的內核進程。
如果我們在當前的 Linux 操作系統下運行一個新的 Docker 容器,并通過 exec 進入其內部的 bash 并打印其中的全部進程,我們會得到以下的結果:
root@iZ255w13cy6Z:~# docker run -it -d ubuntu
b809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79
root@iZ255w13cy6Z:~# docker exec -it b809a2eb3630 /bin/bash
root@b809a2eb3630:/# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 15:42 pts/0 00:00:00 /bin/bash
root 9 0 0 15:42 pts/1 00:00:00 /bin/bash
root 17 9 0 15:43 pts/1 00:00:00 ps -ef
也出現了pid為1的進程,證明當前的 Docker 容器成功將容器內的進程與宿主機器中的進程隔離。這就是在使用 clone(2) 創建新進程時傳入 CLONE_NEWPID 實現的,也就是使用 Linux 的命名空間實現進程的隔離,Docker 容器內部的任意進程都對宿主機器的進程一無所知。
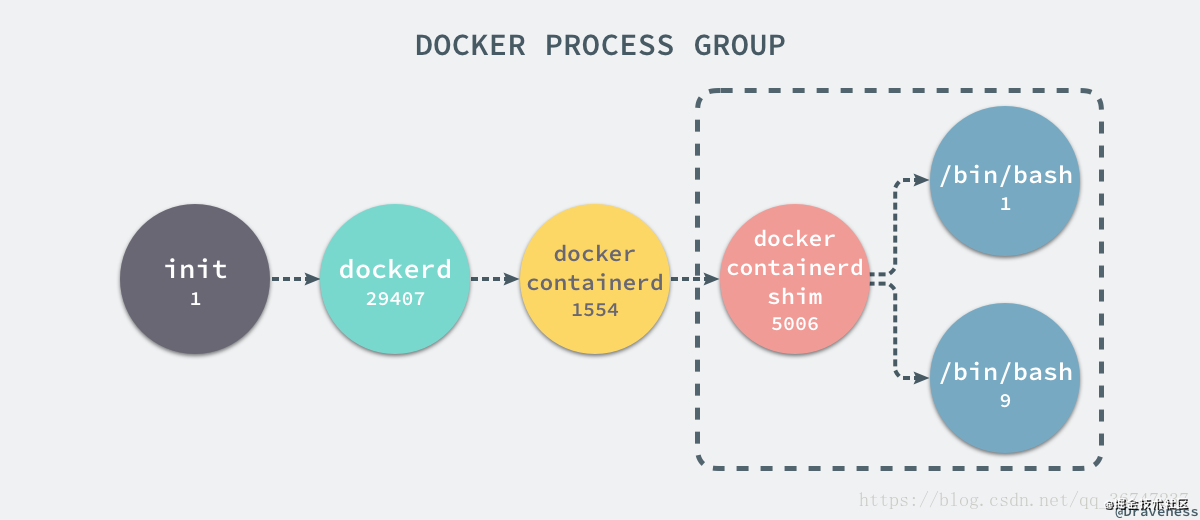
1.2 Control Groups
資源控制組 ( 常縮寫為 CGroups ) 是 Linux 內核在 2.6 版本后逐漸引入的一項對計算機資源控制的模塊。
顧名思義,資源控制組的作用就是控制計算機資源的。與以隔離進程、網絡、文件系統等虛擬資源為目的 Namespace 不同,CGroups 主要做的是硬件資源的隔離。
虛擬化除了制造出虛擬的環境隔離同一物理平臺運行的不同程序之外,另一大作用就是控制硬件資源的分配,CGroups 的使用正是為了這樣的目的。CGroups 除了資源的隔離,還有資源分配這個關鍵性的作用。通過 CGroups,我們可以指定任意一個隔離環境對任意資源的占用值或占用率
我們通過 Linux 的命名空間為新創建的進程隔離了文件系統、網絡并與宿主機器之間的進程相互隔離,但是命名空間并不能夠為我們提供物理資源上的隔離,比如 CPU 或者內存,如果在同一臺機器上運行了多個對彼此以及宿主機器一無所知的『容器』,這些容器卻共同占用了宿主機器的物理資源。
如果其中的某一個容器正在執行 CPU 密集型的任務,那么就會影響其他容器中任務的性能與執行效率,導致多個容器相互影響并且搶占資源。如何對多個容器的資源使用進行限制就成了解決進程虛擬資源隔離之后的主要問題,而 Control Groups(簡稱 CGroups)就是能夠隔離宿主機器上的物理資源,例如 CPU、內存、磁盤 I/O 和網絡帶寬。
每一個 CGroup 都是一組被相同的標準和參數限制的進程,不同的 CGroup 之間是有層級關系的,也就是說它們之間可以從父類繼承一些用于限制資源使用的標準和參數。
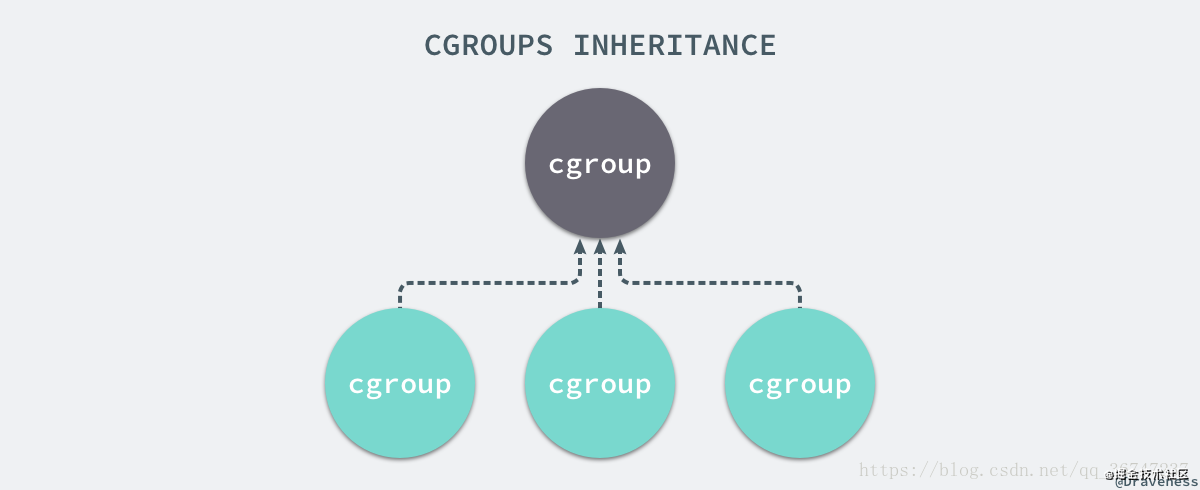
在 CGroup 中,所有的任務就是一個系統的一個進程,而 CGroup 就是一組按照某種標準劃分的進程,在 CGroup 這種機制中,所有的資源控制都是以 CGroup 作為單位實現的,每一個進程都可以隨時加入一個 CGroup 也可以隨時退出一個 CGroup。
Linux 使用文件系統來實現 CGroup,我們可以直接使用下面的命令查看當前的 CGroup 中有哪些子系統:

大多數 Linux 的發行版都有著非常相似的子系統,而之所以將上面的 cpuset、cpu 等東西稱作子系統,是因為它們能夠為對應的控制組分配資源并限制資源的使用。
如果我們想要創建一個新的 cgroup 只需要在想要分配或者限制資源的子系統下面創建一個新的文件夾,然后這個文件夾下就會自動出現很多的內容,如果你在 Linux 上安裝了 Docker,你就會發現所有子系統的目錄下都有一個名為 docker 的文件夾:
$ ls cpu
cgroup.clone_children
...
cpu.stat
docker
notify_on_release
release_agent
tasks$ ls cpu/docker/
9c3057f1291b53fd54a3d12023d2644efe6a7db6ddf330436ae73ac92d401cf1
cgroup.clone_children
...
cpu.stat
notify_on_release
release_agent
tasks
每一個 CGroup 下面都有一個 tasks 文件,其中存儲著屬于當前控制組的所有進程的 pid,作為負責 cpu 的子系統,cpu.cfs_quota_us 文件中的內容能夠對 CPU 的使用作出限制,如果當前文件的內容為 50000,那么當前控制組中的全部進程的 CPU 占用率不能超過 50%。

1.3 Union File System
Linux 的命名空間和控制組分別解決了不同資源隔離的問題,前者解決了進程、網絡以及文件系統的隔離,后者實現了 CPU、內存等資源的隔離,但是在 Docker 中還有另一個非常重要的問題需要解決 - 也就是鏡像。
Docker 鏡像其實本質就是一個壓縮包,我們可以使用下面的命令將一個 Docker 鏡像中的文件導出:
$ docker export $(docker create busybox) | tar -C rootfs -xvf -
$ ls
bin dev etc home proc root sys tmp usr var
你可以看到這個 busybox 鏡像中的目錄結構與 Linux 操作系統的根目錄中的內容并沒有太多的區別,可以說 Docker 鏡像就是一個文件
聯合文件系統 ( Union File System ) 是一種能夠同時掛載不同實際文件或文件夾到同一目錄,形成一種聯合文件結構的文件系統。聯合文件系統本身與虛擬化并無太大的關系,但 Docker 卻創新的將其引入到容器實現中,用它解決虛擬環境對文件系統占用過量,實現虛擬環境快速啟停等問題。
在 Docker 中,提供了一種對 UnionFS 的改進實現,也就是 AUFS ( Advanced Union File System )。
AUFS 將文件的更新掛載到老的文件之上,而不去修改那些不更新的內容,這就意味著即使虛擬的文件系統被反復修改,也能保證對真實文件系統的空間占用保持一個較低水平。
AUFS 作為聯合文件系統,它能夠將不同文件夾中的層聯合(Union)到了同一個文件夾中,這些文件夾在 AUFS 中稱作分支,整個『聯合』的過程被稱為聯合掛載(Union Mount):
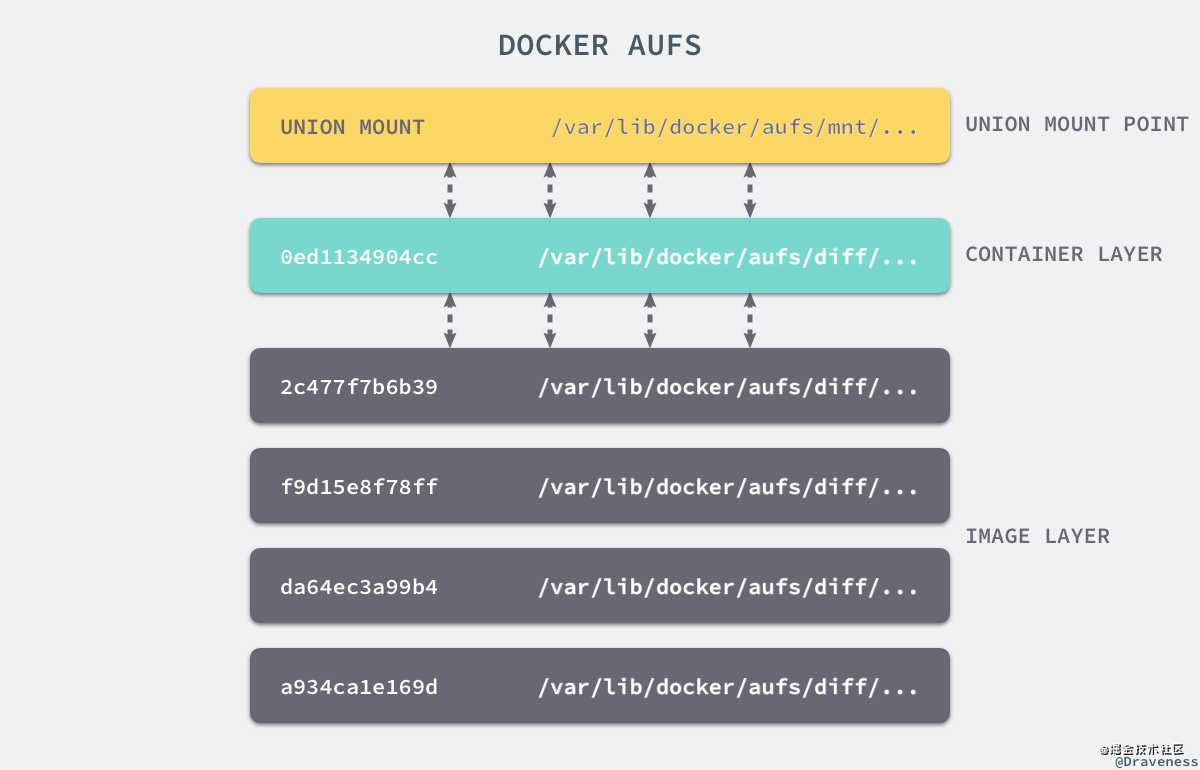
每一個鏡像層都是建立在另一個鏡像層之上的,同時所有的鏡像層都是只讀的,只有每個容器最頂層的容器層才可以被用戶直接讀寫,所有的容器都建立在一些底層服務(Kernel)上,包括命名空間、控制組、rootfs 等等,這種容器的組裝方式提供了非常大的靈活性,只讀的鏡像層通過共享也能夠減少磁盤的占用。
AUFS 只是 Docker 使用的存儲驅動的一種,除了 AUFS 之外,Docker 還支持了不同的存儲驅動,包括 aufs、devicemapper、overlay2、zfs 和 vfs 等等,在最新的 Docker 中,overlay2 取代了 aufs 成為了推薦的存儲驅動,但是在沒有 overlay2 驅動的機器上仍然會使用 aufs 作為 Docker 的默認驅動。

2. Docker 的核心組成
2.1 鏡像
所謂鏡像,可以理解為一個只讀的文件包,其中包含了虛擬環境運行最原始文件系統的內容。
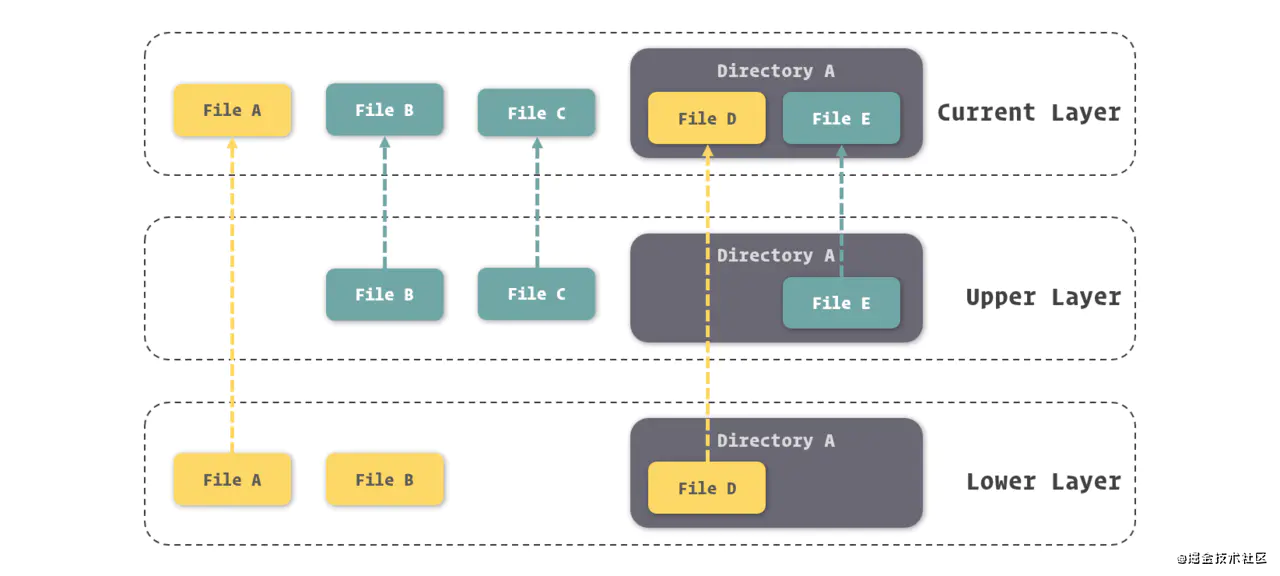
每次對鏡像內容的修改,Docker 都會將這些修改鑄造成一個鏡像層,而一個鏡像其實就是由其下層所有的鏡像層所組成的。當然,每一個鏡像層單獨拿出來,與它之下的鏡像層都可以組成一個鏡像。
另外,由于這種結構,Docker 的鏡像實質上是無法被修改的,因為所有對鏡像的修改只會產生新的鏡像,而不是更新原有的鏡像。
2.2 容器
容器 ( Container ) 就更好理解了,在容器技術中,容器就是用來隔離虛擬環境的基礎設施,而在 Docker 里,它也被引申為隔離出來的虛擬環境。
如果把鏡像理解為編程中的類,那么容器就可以理解為類的實例。鏡像內存放的是不可變化的東西,當以它們為基礎的容器啟動后,容器內也就成為了一個“活”的空間。
容器的組成
- 一個 Docker 鏡像
- 一個程序運行環境
- 一個指令集合
2.3 網絡
網絡是進程間通信方式的一種,網絡通訊是目前最常用的一種程序間的數據交換方式了。
在 Docker 中,實現了強大的網絡功能,我們不但能夠十分輕松的對每個容器的網絡進行配置,還能在容器間建立虛擬網絡,將數個容器包裹其中,同時與其他網絡環境隔離。
另外,利用一些技術,Docker 能夠在容器中營造獨立的域名解析環境,這使得我們可以在不修改代碼和配置的前提下直接遷移容器,Docker 會為我們完成新環境的網絡適配。
Docker 雖然可以通過命名空間創建一個隔離的網絡環境,但是 Docker 中的服務仍然需要與外界相連才能發揮作用。
每一個使用 docker run 啟動的容器其實都具有單獨的網絡命名空間,Docker 為我們提供了四種不同的網絡模式,Host、Container、None 和 Bridge 模式。
2.4 Docker Engine
雖然我們說 Docker Engine 是一款軟件,但實實在在去深究的話,它其實算是由多個獨立軟件所組成的軟件包。在這些程序中,最核心的就是 docker daemon 和 docker CLI 這倆了。
所有我們通常認為的 Docker 所能提供的容器管理、應用編排、鏡像分發等功能,都集中在了 docker daemon 中,而我們之前所提到的鏡像模塊、容器模塊、數據卷模塊和網絡模塊也都實現在其中。在操作系統里,docker daemon 通常以服務的形式運行以便靜默的提供這些功能,所以我們也通常稱之為 Docker 服務。
在 docker daemon 管理容器等相關資源的同時,它也向外暴露了一套 RESTful API,我們能夠通過這套接口對 docker daemon 進行操作。如果我們在控制臺中編寫一個 HTTP 請求以借助 docker daemon 提供的 RESTful API 來操控它,那顯然是個費腦、費手又費時間的活兒。所以在 Docker Engine 里還直接附帶了 docker CLI 這個控制臺程序。
參考資料
《開發者必備的 Docker 實踐指南》




)





Docke的安裝和基本配置)





)

鏡像與容器)
