nlp自然語言處理
自然語言處理 (Natural Language Processing)
到底是怎么回事? (What is going on?)
NLP is the new Computer Vision
NLP是新的計算機視覺
With enormous amount go textual datasets available; giants like Google, Microsoft, Facebook etc have diverted their focus towards NLP.
大量可用的文本數據集; 谷歌,微軟,Facebook等巨頭已經將注意力轉向了自然語言處理。
Models using thousands of super-costly TPUs/GPUs, making them infeasible for most.
使用成千上萬的價格昂貴的TPU / GPU進行建模,這對于大多數人來說是不可行的。
This gave me anxiety! (we’ll come back to that)
這讓我感到焦慮! (我們會回到那個)
Let’s these Tweets put things into perspective:
讓我們通過以下Tweet透視事物:
Tweet 1:
鳴叫1:

Tweet 2: (read the trailing tweet)
鳴叫2 :(請 閱讀尾隨的鳴叫)
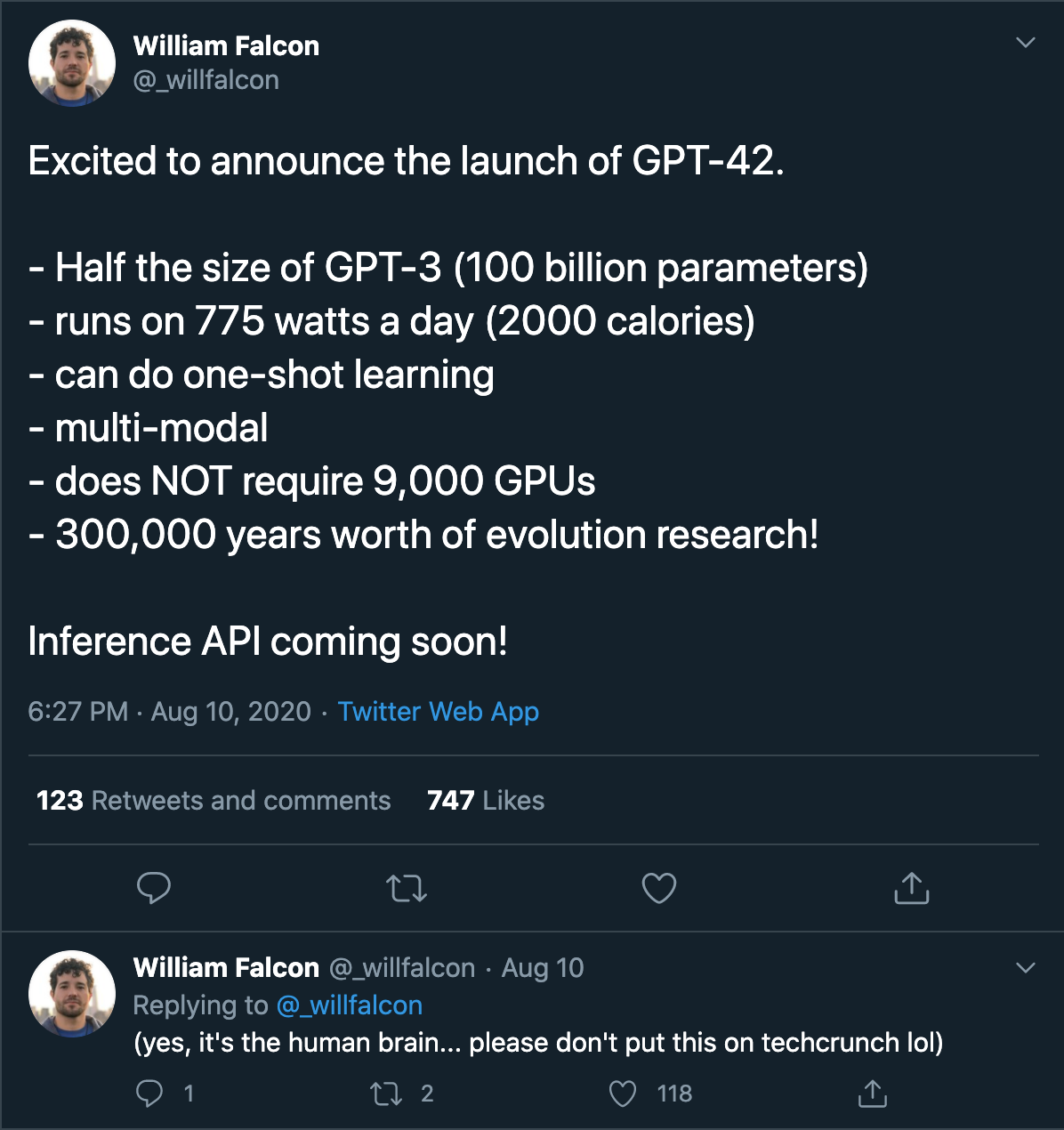
結果呢? (Consequences?)
In about last one-year following knowledge became mainstream:
在大約一年的時間里,以下知識已成為主流:
- Transformers was followed by Reformer, Longformer, GTrXL, Linformer, and others. 緊隨其后的是Transformers,Reformer,Longformer,GTrXL,Linformer等。
- BERT was followed by XLNet, RoBERTa, AlBERT, Electra, BART, T5, Big Bird, and others. BERT之后是XLNet,RoBERTa,AlBERT,Electra,BART,T5,Big Bird等。
- Model Compression was extended by DistilBERT, TinyBERT, BERT-of-Theseus, Huffman Coding, Movement Pruning, PrunBERT, MobileBERT, and others. 模型壓縮由DistilBERT,TinyBERT,Theseus BERT,Huffman編碼,Motion Pruning,PrunBERT,MobileBERT等擴展。
- Even new tokenizations were introduced: Byte-Pair encoding (BPE), Word-Piece Encoding (WPE), Sentence-Piece Encoding (SPE), and others. 甚至引入了新的標記化:字節對編碼(BPE),字片編碼(WPE),句子片編碼(SPE)等。
This is barely the tip of the iceberg.
這僅僅是冰山一角。
So while you were trying to understand and implement a model, a bunch of new lighter and faster models were already available.
因此,當您嘗試理解和實現模型時,已經有很多新的更輕,更快的模型。
如何應付呢? (How to Cope with it?)
The answer is short:
答案很簡短:
you don’t need to know it all, know only what is necessary and use what is available
您不需要一無所知,只知道什么是必要的,并使用可用的
原因 (Reason)
I read them all to realize most of the research is re-iteration of similar concepts.
我閱讀了所有內容,以了解大部分研究是對類似概念的重復 。
At the end of the day (vaguely speaking):
在一天結束時(含糊地說):
- the reformer is hashed version of the transformers and longfomer is a convolution-based counterpart of the transformers 重整器是變壓器的哈希版本,而longfomer是變壓器的基于卷積的對應形式
- all compression techniques are trying to consolidate information 所有壓縮技術都在嘗試整合信息
- everything from BERT to GPT3 is just a language model 從BERT到GPT3的一切都只是一種語言模型
優先級->準確性管道 (Priorities -> Pipeline over Accuracy)
Learn to use what’s available, efficiently, before jumping on to what else can be used
在跳到其他可用功能之前,學會有效地使用可用的功能
In practice, these models are a small part of a much bigger pipeline.
實際上,這些模型只是規模更大的產品線的一小部分 。
Your first instinct should not be of competeing with Tech Giants’ in-terms of training a better model.
您的第一個本能不應該是與Tech Giants在訓練更好模型方面的競爭。
Instead, Your first instinct should be to use the availbale models to build an end-to-end application which solves a practical problem.
相反,您的第一個本能應該是使用availbale模型來構建解決實際問題的端到端應用程序。
Now if you feel that the model is the performance bottleneck of your application; re-train that model or switch to another model.
現在,如果您認為模型是應用程序的性能瓶頸,那就可以了。 重新訓練該模型或切換到另一個模型。
Consider the following:
考慮以下:
- Huge deep learning models usually take thousands for GPU hours just to train. 龐大的深度學習模型通常需要數千個小時才能進行GPU訓練。
- This increases 10x when you consider hyper-parameter tuning (HP Tuning). 當您考慮進行超參數調整(HP調整)時,這將增加10倍。
- HP Tuning something as efficient as an Electra model can also take a week or two. HP調整與Electra型號一樣高效的東西也可能需要一兩個星期。
實際方案->實際加速 (Practical Scenario -> The Real Speedup)
Take an example of Q&A Systems. Given millions of documents, for this task, something like ElasticSearch is way more essential to the pipeline than a new Q&A model (comparatively).
以問答系統為例。 給定數百萬個文檔,對于此任務,相對于新的問答模型,ElasticSearch之類的東西對于管道更重要。
In production success of your pipeline will not (only) be determined by how awesome are your Deep Learning models but also by:
在生產中,成功的流水線(不僅)取決于深度學習模型的出色程度,還取決于:
the latency of the inference time
推理時間的延遲
predictability of the results and boundary cases
結果和邊界案例的可預測性
- the ease of fine-tuning 易于調整
- the ease of reproducing the model on a similar dataset 在相似的數據集上再現模型的難易程度
Something like DistilBERT can be scaled to handle Billion queries as beautifully mentioned in this blog by Robolox.
正如Robolox在本博客中提到的那樣,可以擴展DistilBERT之類的功能來處理十億個查詢。
While new models can decrease the inference time by 2x-5x.
新模型可以將推理時間減少2x-5x 。
Techniques like quantization, pruning and using Onnx can decrease the inference time by 10x-40x!
量化 ,修剪和使用Onnx等技術可以將推理時間減少10x-40x !
個人經驗 (Personal Experience)
I was working on an Event Extraction pipeline, which used:
我正在研究事件提取管道,該管道使用:
- 4 different transformer-based models 4種基于變壓器的不同模型
- 1 RNN-based model 1基于RNN的模型
But. At the heart of the entire pipeline were:
但。 整個流程的核心是:
- WordNet 詞網
- FrameNet 框架網
- Word2Vec Word2Vec
- Regular-Expressions 常用表達
And. Most of my team’s focus was on:
和。 我團隊的大部分精力都放在:
Extraction of text from PPTs, images & tables
從PPT,圖像和表格中提取文本
Cleaning & preprocessing text
清洗和預處理文本
Visualization of results
結果可視化
- Optimization of ElasticSearch ElasticSearch的優化
- Format of info for Neo4J Neo4J的信息格式
結論 (Conclusion)
It is more essential to have an average performing pipeline than to have a non-functional pipeline with a few brilliant modules.
具有平均性能的管道比具有一些出色模塊的非功能性管道更為重要。
Neither Christopher Manning nor Andrew NG knows it all. They just know what is required and when it is required; well enough.
Christopher Manning和Andrew Andrew都不知道這一切。 他們只知道需要什么,什么時候需要。 足夠好。
So, have realistic expectations of yourself.
因此,對自己有現實的期望。
Thank you!
謝謝!
翻譯自: https://medium.com/towards-artificial-intelligence/dont-be-overwhelmed-by-nlp-c174a8b673cb
nlp自然語言處理
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391059.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391059.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391059.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章


js打開飛行模式_什么是飛行模式? 它有什么作用?什么時候應該打開它?

在Java 里面怎么比較字符串
)
中小型研發團隊架構實踐三要點(轉自原攜程架構師張輝清)

時間序列預測 預測時間段_應用時間序列預測:美國住宅

zabbix之web監控

如何使用Webpack在HTML,CSS和JavaScript之間共享變量

Java中獲得了方法名稱的字符串,怎么樣調用該方法

經驗主義 保守主義_為什么我們需要行動主義-始終如此。


redis介紹以及安裝

java python算法_用Java,Python和C ++示例解釋的搜索算法

Java中怎么把文本追加到已經存在的文件

python機器學習預測_使用Python和機器學習預測未來的股市趨勢

線程系列3--Java線程同步通信技術
)
Python數據結構之四——set(集合)

volatile關鍵字有什么用

knn 機器學習_機器學習:通過預測意大利葡萄酒的品種來觀察KNN的工作方式
)
MMU內存管理單元(看書筆記)
