時間序列預測 預測時間段
1.簡介 (1. Introduction)
During these COVID19 months housing sector is rebounding rapidly after a downtime since the early months of the year. New residential house construction was down to about 1 million in April. As of July 1.5 million new houses are under construction (for comparison, in July of 2019 it was 1.3 million). The Census Bureau report released on August 18 shows some pretty good indicators for the housing market.
自今年初以來,在經歷了停工之后,在這19個COVID19個月中,住房行業Swift反彈。 四月份的新住宅建設量降至約100萬套。 截至7月,正在建造150萬套新房屋(相比之下,2019年7月為130萬套)。 人口普查局 8月18日發布的報告顯示了一些相當好的房地產市場指標。
New house construction plays a significant role in the economy. Besides generating employment it simultaneously impacts timber, furniture and appliance markets. It’s also an important indicator of the overall health of the economy.
新房建設在經濟中起著重要作用。 除了創造就業機會,它同時影響木材,家具和家電市場。 它也是經濟整體健康狀況的重要指標。
So one might ask, how will this crucial economic indicator play out the next few months and years to come after the COVID19 shock?
因此,有人可能會問,在COVID19沖擊之后的幾個月和幾年中,這一至關重要的經濟指標將如何發揮作用?
Answering these questions requires some forecasting.
回答這些問題需要一些預測。
The purpose of this article is to make short and medium-term forecasting of residential construction using a popular time series forecasting model called ARIMA.
本文的目的是使用流行的時間序列預測模型ARIMA對住宅建筑進行短期和中期預測。
Even if you are not much into the housing market but are interested in data science, this is a practical forecasting example that might help you understand how forecasting works and how to implement a model in real-world application cases.
即使您對房地產市場的興趣不大,但對數據科學感興趣,這也是一個實用的預測示例,可以幫助您了解預測的工作原理以及如何在實際應用案例中實現模型。
2.方法摘要 (2. Methods summary)
The objective is forecasting the construction of residential housing units in the short and medium-term using historical data obtained from census.gov database. Note that in the Census Bureau database, you’ll see there’re several datasets on housing indicators including “housing units started” and “housing units completed”; I’m using the latter for this article.
目的是使用從census.gov數據庫獲得的歷史數據預測短期和中期的住宅單元建設。 請注意,在人口普查局數據庫中,您會看到有關房屋指標的多個數據集,包括“房屋單元已開始”和“房屋單元已完成”; 我在本文中使用后者。
Census Bureau is a great source of time series data of all kinds on a large number of social, economic and business indicators. So if you are interested in time series analysis and modeling and want to avoid toy datasets, the Census Bureau is a great place to check out.
人口普查局是有關大量社會,經濟和商業指標的各種時間序列數據的重要來源。 因此,如果您對時間序列分析和建模感興趣,并且希望避免使用玩具數據集,那么人口普查局是個很好的結帳地點。
I am doing the modeling in R programming environment. Python has great libraries for data science and machine learning modeling, but in my opinion, R has the best package, calledfpp2, developed by Rob J Hyndman, for time series forecasting.
我正在R編程環境中進行建模。 Python擁有用于數據科學和機器學習建模的出色庫 ,但我認為R具有由Rob J Hyndman開發的用于時間序列預測的最佳軟件包fpp2 。
There are many methods for time series forecasting, and I have written about them in a few articles before (you can check out this and this), but for this analysis I am going to use ARIMA. Before settling on ARIMA I ran a couple of other models — Holt-Winter and ETS — but found that ARIMA has a better performance for this particular dataset.
時間序列預測有很多方法,我之前已經在幾篇文章中對此進行了介紹(您可以查看this和this ),但是對于此分析,我將使用ARIMA。 在著手ARIMA之前,我還運行了其他幾個模型(Holt-Winter和ETS),但是發現ARIMA對于此特定數據集具有更好的性能。
3.數據準備 (3. Data preparation)
The only library I am using is fpp2. If you install this library all required dependencies will accompany.
我使用的唯一庫是fpp2 。 如果安裝此庫,則所有必需的依賴項都會伴隨。
After importing data in the R programming environment (RStudio) I call the head() function.
在R編程環境(RStudio)中導入數據后,我調用head()函數。
# import library
library(fpp2)# import data
df = read.csv("../housecons.csv", skip=6)# check out first few rows
head(df)
I noticed that the first few rows are empty, so I opened the CSV file outside of R to manually inspect for missing values and found that the first data did not appear until January of 1968. So I got rid of the missing values with a simple function na.omit().
我注意到前幾行是空的,因此我在R之外打開了CSV文件以手動檢查缺失值,發現直到1968年1月才出現第一個數據。因此,我用一個簡單的方法消除了缺失值函數na.omit() 。
# remove missing values
df = na.omit(df)# check out the rows again
head(df)
As you notice in the dataframe above, it has two columns — time stamp and the corresponding values. You might think it is already a time series data so let’s go ahead and build the model. Not so fast, the dataframe may look like a time series but it’s not in a format that is compatible with the modeling package.
如您在上面的數據框中所注意到的,它具有兩列-時間戳和相應的值。 您可能會認為它已經是時間序列數據,所以讓我們繼續構建模型。 數據幀的速度不是很快,可能看起來像一個時間序列,但格式與建模包不兼容。
So we need to do some data processing.
因此,我們需要進行一些數據處理。
As a side note, not just this dataset, any dataset you use for this kind of analysis in any package, you need to do pre-processing. This is an extra step but a necessary one. After all, this is not a cleaned, toy dataset that you typically find on the internet!
附帶說明一下,您不僅需要此數據集,還需要對用于任何軟件包中的此類分析的任何數據集進行預處理。 這是一個額外的步驟,但卻是必要的步驟。 畢竟,這不是通常在互聯網上找到的干凈的玩具數據集!
# keep only `Value` column
df = df[, c(2)]# convert values into a time series object
series = ts(df, start = 1968, frequency = 12)# now check out the series
print(series)The codes above are self-explanatory. Since we got rid of the “Period” column, I had to tell the program that the values start from 1968 and it’s an annual time series with 12-month frequency.
上面的代碼是不言自明的。 自從我們刪除了“ Period”一欄之后,我不得不告訴程序該值始于1968年,它是一個12個月一次的年度時間序列。
The original data was in long-form, now after processing it is converted to a wide-form so you can now see a lot of data in a small window.
原始數據采用長格式,現在經過處理后將轉換為寬格式,因此您現在可以在一個小窗口中看到大量數據。
We are now done with data processing. Was that easy to process data for time series compared to other machine learning algorithms? I bet it was.
現在,我們完成了數據處理。 與其他機器學習算法相比,這樣容易處理時間序列數據嗎? 我敢打賭
Now that we have the data that we needed, shall we go ahead and build the model?
現在我們有了所需的數據,我們是否應該繼續構建模型?
Not so fast!
沒那么快!
4.探索性分析 (4. Exploratory analysis)
Exploratory data analysis (EDA) may not seem like a pre-requisite, but in my opinion it is! And it’s for two reasons. First, without EDA you are absolutely blinded, you will have no idea what’s going into the model. You kind of need to know what raw material is going into the final product, don’t you?
探索性數據分析(EDA)似乎不是先決條件,但我認為是! 這有兩個原因。 首先,如果沒有EDA,您絕對是盲目的,您將不知道模型會發生什么。 您有點需要知道最終產品將使用哪種原材料,不是嗎?
The second reason is an important one. As you will see later, I had to test the model on two different input data series for model performance. I only did this extra step after I discovered that the time series is not smooth, it has a structural break, which influenced the model performance (check out the figure below, do you see the structural break?).
第二個原因很重要。 稍后您將看到,我必須在兩個不同的輸入數據序列上測試模型的模型性能。 我僅在發現時間序列不平滑,有結構性中斷之后才執行此額外步驟,該結構性中斷影響了模型性能(請查看下圖,您看到結構性中斷了嗎?)。
Visualizing the series
可視化系列
The nice thing about the fpp2package is that you don’t have to separately install visualization libraries, it’s already built-in.
關于fpp2軟件包的fpp2是您不必單獨安裝可視化庫,它已經內置。
# plot the series
autoplot(series) +
xlab(" ") +
ylab("New residential construction '000") +
ggtitle(" New residential construction") +
theme(plot.title = element_text(size=8))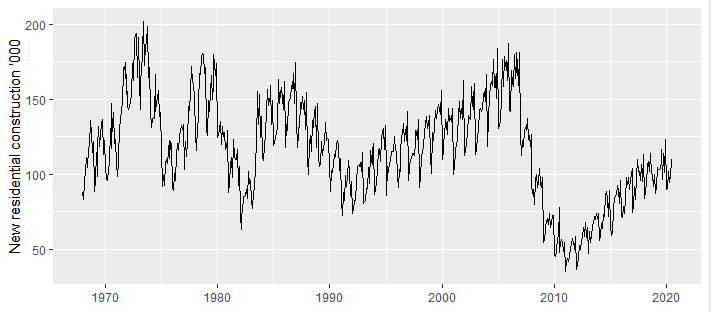
It’s just one single plot above, but there is so much going on. If you are a data scientist, you could stop here and take a closer look and find out how many bits of information you could extract from this figure.
這只是上面的一個圖,但是發生了很多事情。 如果您是一名數據科學家,則可以在這里停下來仔細觀察,找出可以從該圖中提取多少信息。
Here is my interpretation:
這是我的解釋:
- the data has a strong seasonality; 數據具有很強的季節性;
- it also shows some cyclic behavior until c.1990, which then disappeared; 它也顯示出一些周期性的行為,直到1990年左右才消失。
- the series remained relatively stable since 1992 until the housing crisis; 自1992年以來,直到住房危機之前,該系列一直保持相對穩定;
- the structural break due to market shock is clearly visible around 2008; 在2008年左右,市場沖擊引起的結構性破壞顯而易見。
- the market is recovering since c. 2011 and growing steadily; 自c。開始市場復蘇。 2011年并穩步增長;
- 2020 has yet another shock from COVID19. It’s not clearly visible in this figure, but if you zoom in you can detect it. 2020年又使COVID19感到震驚。 在此圖中看不到清晰可見的圖像,但是如果放大可以檢測到。
So much information you are able to extract from just a simple figure and these are all useful bits of information for building intuition before building models. That is why EDA is so essential in data science.
您可以從一個簡單的圖形中提取出如此多的信息,這些都是在構建模型之前建立直覺的有用信息。 這就是為什么EDA在數據科學中如此重要的原因。
Trend
趨勢
The overall trend in the series is already visible in the first figure, but if you want better visibility of the trend you can do that by removing seasonality.
該系列的總體趨勢已經在第一個圖中顯示出來了,但是如果您想更好地了解趨勢,可以通過消除季節性來實現。
# remove seasonality (monthly variation) to see yearly changesseries_ma = ma(series, 12)
autoplot(series_ma) +
xlab("Time") + ylab("New residential construction '000")+
ggtitle("Series after removing seasonality" )+
theme(plot.title = element_text(size=8))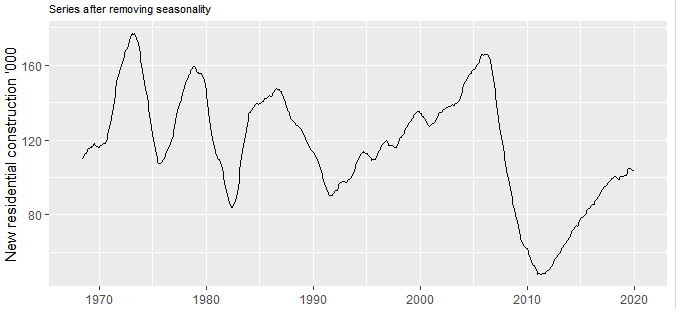
Seasonality
季節性
After seeing the general annual trend if you want to only focus on seasonality you could do that too with a seasonal sub-series plot.
在看到總體年度趨勢之后,如果您只想關注季節性,則也可以使用季節性子系列圖來實現。
# Seasonal sub-series plot
series_season = window(series, start=c(1968,1), end=c(2020,7))
ggsubseriesplot(series_season) +
ylab(" ") +
ggtitle("Seasonal subseries plot") +
theme(plot.title = element_text(size=10))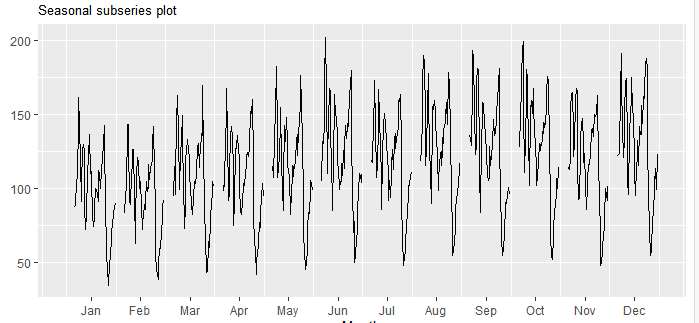
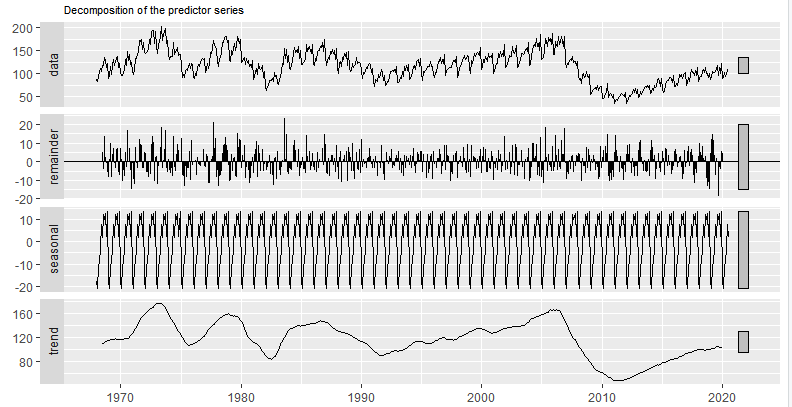
Time series decomposition
時間序列分解
There is a nice way to show everything in one figure — it’s called the decomposition plot. Basically it is a composite of four information:
有一種很好的方法可以在一個圖中顯示所有內容-這稱為分解圖。 基本上,它是四個信息的組合:
- the original series (i.e. data) 原始系列(即數據)
- trend 趨勢
- seasonality 季節性
- random component 隨機成分
# time series decomposition
autoplot(decompose(predictor_series)) +
ggtitle("Decomposition of the predictor series")+
theme(plot.title = element_text(size=8))The random data part is in this decomposition plot is the most interesting to me, since this component actually determines the uncertainty in forecasting. The smaller this random component the better.
這個分解圖中的隨機數據部分對我來說是最有趣的,因為此組件實際上確定了預測中的不確定性。 該隨機分量越小越好。
Zooming in
放大
We could also zoom in on a specific part of the data series. For example, below I zoomed in to see the good times (1995–2005) and bad times (2006–2016) in the housing market.
我們還可以放大數據系列的特定部分。 例如,下面我放大查看房地產市場的好時光(1995-2005)和不好的時光(2006-2016)。
# zooming in on high time
series_downtime = window(series, start=c(1993,1), end=c(2005,12))
autoplot(series_downtime) +
xlab("Time") + ylab("New residential construction '000")+
ggtitle(" New residential construction high time")+
theme(plot.title = element_text(size=8))# zooming in on down time
series_downtime = window(series, start=c(2005,1), end=c(2015,12))
autoplot(series_downtime) +
xlab("Time") + ylab("New residential construction '000")+
ggtitle(" New residential construction down time")+
theme(plot.title = element_text(size=8))
Enough of exploratory analysis, now let’s move on to the fun part of model building, shall we?
足夠的探索性分析之后,現在讓我們繼續進行模型構建的有趣部分,對吧?
5. ARIMA的預測 (5. Forecasting with ARIMA)
I already mentioned the rationale behind choosing ARIMA for this forecasting and it is because I tested the data with two other models but ARIMA showed a better performance.
我已經提到選擇ARIMA進行此預測的基本原理,這是因為我用其他兩個模型測試了數據,但是ARIMA顯示出更好的性能。
Once you have your data preprocessed and ready to use, building the actual model is surprisingly easy. As an aside, it is also the case in most modeling exercise; writing codes and executing models is a small part of the whole process you need to go through — from data gathering & cleaning, to building intuition to finding the right model.
一旦對數據進行了預處理并可以使用,構建實際模型就非常簡單。 順便說一句,在大多數建模練習中也是如此。 編寫代碼和執行模型只是您需要經歷的整個過程的一小部分-從數據收集和清理到建立直覺到找到正確的模型。
I followed 5 simple steps for implementing ARIMA:
我遵循了5個簡單的步驟來實現ARIMA:
1 ) determining the predictors series
1)確定預測變量序列
2 ) model parameterization
2)模型參數化
3 ) plotting forecast values
3)繪制預測值
4 ) making a point forecast for a specific year
4)預測特定年份的分數
5 ) model evaluation/accuracy test
5)模型評估/準確性測試
Below you get all the codes needed for model implementation.
在下面,您可以獲得模型實現所需的所有代碼。
# determine the predictor series (in case you choose a subset of the series)
predictor_series = window(series, start=c(2011,1), end=c(2020,7))
autoplot(predictor_series) + labs(caption = " ")+ xlab("Time") + ylab("New residential construction '000")+
ggtitle(" Predictor series")+
theme(plot.title = element_text(size=8))# decomposition
options(repr.plot.width = 6, repr.plot.height = 3)
autoplot(decompose(predictor_series)) + ggtitle("Decomposition of the predictor series")+
theme(plot.title = element_text(size=8))# model
forecast_arima = auto.arima(predictor_series, seasonal=TRUE, stepwise = FALSE, approximation = FALSE)
forecast_arima = forecast(forecast_arima, h=60)# plot
autoplot(series, series=" Whole series") +
autolayer(predictor_series, series=" Predictor series") +
autolayer(forecast_arima, series=" ARIMA Forecast") +
ggtitle(" ARIMA forecasting") +
theme(plot.title = element_text(size=8))# point forecast
point_forecast_arima=tail(forecast_arima$mean, n=12)
point_forecast_arima = sum(point_forecast_arima)
cat("Forecast value ('000): ", round(point_forecast_arima))print('')
cat(" Current value ('000): ", sum(tail(predictor_series, n=12))) # current value# model description
forecast_arima['model']# accuracy
accuracy(forecast_arima)Like I said before, I ran ARIMA with two different data series, the first one was the whole data series from 1968 to 2020. As you see below, the forecasted values are kind of flat (red series) and come with a lot of uncertainties.
就像我之前說過的那樣,我使用兩個不同的數據系列運行ARIMA,第一個是1968年至2020年的整個數據系列。正如您在下面看到的那樣,預測值有點平坦(紅色系列),并且存在很多不確定性。
The forecast looked a bit unrealistic to me given the trend over the last 10 years. You might think it is due to COVID19 impact? I don’t think so, because the model shouldn’t have picked up that signal just yet since COVID impact is a tiny part of the whole series.
考慮到過去10年的趨勢,這一預測對我而言似乎有些不切實際。 您可能會認為是由于COVID19的影響? 我不這么認為,因為COVID的影響只是整個系列的一小部分,因此該模型還不應該接收該信號。
Then I realized that this uncertainty is because of the historical features in the series, including the uneven cycles and trend and the structural break. So I made the decision to use the last 10 years data as a predictor.
然后我意識到這種不確定性是由于該系列的歷史特征,包括周期和趨勢的不均勻以及結構性斷裂。 因此,我決定使用最近10年的數據作為預測指標。

The figure below is how it looks like once we use a subset of the series as a predictor. You can just visually compare the forecast area and the associated uncertainties (in red) between the two figures.
下圖是一旦我們使用系列的子集作為預測變量后的樣子。 您可以直觀地比較兩個數字之間的預測區域和相關的不確定性(紅色)。
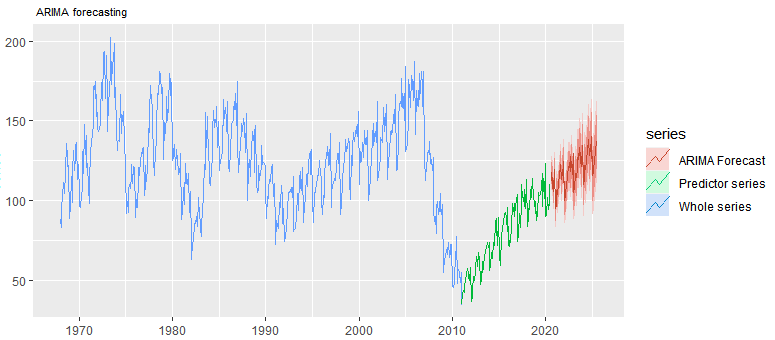
Below is more a quantitative way of comparing the performance of two models based on two input series. As you can see both the AIC and RMSE have dramatically declined to give the second model a solid performance.
下面是一種比較定量的方法,用于比較基于兩個輸入序列的兩個模型的性能。 如您所見,AIC和RMSE都大大降低了第二模型的性能。

預測值 (Forecast values)
Enough about the model building process, but this article is about doing an actual forecast with a real-world dataset. Below are the forecast values for new residential house construction in the United States.
關于模型構建的過程已經足夠了,但是本文是關于使用真實數據集進行實際預測的。 以下是美國新住宅建筑的預測值。
Current value (‘000 units): 1248
當前值('000單位):1248
1-year forecast (‘000 units): 1310
1年預測(000個單位):1310
5-year forecast (‘000 units): 1558
五年預測('000單位):1558
6。結論 (6. Conclusions)
If the residential house construction continues along with the trend, 300K new residential housing units are expected to be built over the next 5 years. But this needs to be closely watched as the impact of COVID19 shock might be more apparent in the next few months.
如果住宅建設繼續保持這種趨勢,那么未來5年預計將建造30萬套新住宅。 但這需要密切注意,因為在接下來的幾個月中,COVID19沖擊的影響可能會更加明顯。
I probably could’ve gotten a better model by tuning parameters or finding another model, but I wanted to keep it simple. In fact, as the adage goes, all models are wrong but some are useful. Hopefully, this AIMA model was useful in understanding some market dynamics.
我可能可以通過調整參數或找到其他模型來獲得更好的模型,但我想保持簡單。 實際上,正如諺語所說,所有模型都是錯誤的,但有些模型是有用的。 希望該AIMA模型有助于理解某些市場動態。
翻譯自: https://towardsdatascience.com/applied-time-series-forecasting-residential-housing-in-the-us-f8ab68e63f94
時間序列預測 預測時間段
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391054.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391054.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391054.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

zabbix之web監控

如何使用Webpack在HTML,CSS和JavaScript之間共享變量

Java中獲得了方法名稱的字符串,怎么樣調用該方法

經驗主義 保守主義_為什么我們需要行動主義-始終如此。


redis介紹以及安裝

java python算法_用Java,Python和C ++示例解釋的搜索算法

Java中怎么把文本追加到已經存在的文件

python機器學習預測_使用Python和機器學習預測未來的股市趨勢

線程系列3--Java線程同步通信技術
)
Python數據結構之四——set(集合)

volatile關鍵字有什么用

knn 機器學習_機器學習:通過預測意大利葡萄酒的品種來觀察KNN的工作方式
)
MMU內存管理單元(看書筆記)

Java中如何讀取文件夾下的所有文件

github pages_如何使用GitHub Actions和Pages發布GitHub事件數據

c# .Net 緩存 使用System.Runtime.Caching 做緩存 平滑過期,絕對過期

python 實現分步累加_Python網頁爬取分步指南

Java 到底有沒有析構函數呢?
