樸素貝葉斯實現分類
Naive Bayes classification is one of the most simple and popular algorithms in data mining or machine learning (Listed in the top 10 popular algorithms by CRC Press Reference [1]). The basic idea of the Naive Bayes classification is very simple.
樸素貝葉斯分類是數據挖掘或機器學習中最簡單,最流行的算法之一(在CRC Press Reference [1]列出的十大流行算法中)。 樸素貝葉斯分類的基本思想很簡單。
(In case you think video format is more suitable for you, you can jump here you can also go to the notebook.)
(如果您認為視頻格式更適合您,則可以跳到此處 ,也可以轉到筆記本 。)
基本直覺: (The basic Intuition:)
Let’s say, we have books of two categories. One category is Sports and the other is Machine Learning. I count the frequency of the words of “Match” (Attribute 1) and Count of the word “Algorithm” (Attribute 2). Let’s assume, I have a total of 6 books from each of these two categories and the count of words across the six books looks like the below figure.
假設我們有兩類書籍。 一類是運動,另一類是機器學習。 我計算“匹配”(屬性1)單詞的出現頻率和“算法”(屬性2)單詞的計數。 假設,我總共擁有這六類書中的六本書,這六本書中的單詞數如下圖所示。
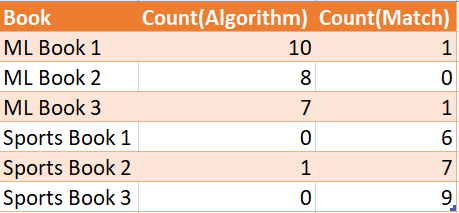
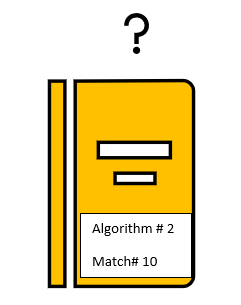
We see that clearly that the word ‘algorithm’ appears more in Machine Learning books and the word ‘match’ appears more in Sports. Powered with this knowledge, Let’s say if I have a book whose category is unknown. I know Attribute 1 has a value 2 and Attribute 2 has a value 10, we can say the book belongs to Sports Category.
我們清楚地看到,“算法”一詞在機器學習書籍中出現的次數更多,而“匹配”一詞在體育游戲中出現的次數更多。 借助這種知識,假設我有一本書的類別未知。 我知道屬性1的值為2,屬性2的值為10,可以說這本書屬于“體育類別”。
Basically we want to find out which category is more likely, given attribute 1 and attribute 2 values.
基本上,我們希望找出給定屬性1和屬性2值的可能性更大的類別。
從計數到概率: (Moving from count to Probability:)
This count-based approach works fine for a small number of categories and a small number of words. The same intuition is followed more elegantly using conditional probability.
這種基于計數的方法適用于少量類別和少量單詞。 使用條件概率可以更優雅地遵循相同的直覺。
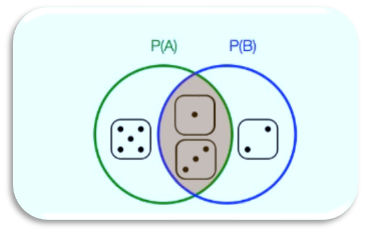
Conditional Probability is again best understood with an example
再舉一個例子可以更好地理解條件概率
Let’s assume
假設
Event A: The face value is odd | Event B: The face value is less than 4
事件A:面值是奇數| 事件B:面值小于4
P(A) = 3/6 (Favourable cases 1,3,5 Total Cases 1,2,3,4,5,6) similarly P(B) is also 3/6 (Favourable cases 1,2,3 Total Cases 1,2,3,4,5,6). An example of conditional probability is what is the probability of getting an odd number (A)given the number is less than 4(B). For finding this first we find the intersection of events A and B and then we divide by the number of cases in case B. More formally this is given by the equation
P(A)= 3/6(有利案件1,3,5總案件1,2,3,4,5,6)類似,P(B)也是3/6(有利案件1,2,3總案件) 1,2,3,4,5,6)。 條件概率的一個示例是給定奇數(A)小于4(B)的概率是多少。 為了找到這一點,我們首先找到事件A和B的交集,然后除以案例B中的案例數。更正式地說,由等式給出
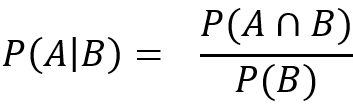
P(A|B) is the conditional probability and is read as the probability of A Given B. This equation forms the central tenet. Let’s now go back again to our book category problem, we want to find the category of the book more formally.
P(A | B)是條件概率,并被解讀為A給定B的概率。該等式形成了中心原則。 現在讓我們再回到書籍類別問題,我們希望更正式地找到書籍的類別。
樸素貝葉斯分類器的條件概率 (Conditional Probability to Naive Bayes Classifier)
Let’s use the following notation Book=ML is Event A, book=Sports is Event B, and “Attribute 1 = 2 and Attribute 2 = 10” is Event C. The event C is a joint event and we will come to this in a short while.
讓我們使用以下表示法Book = ML是事件A,book = Sports是事件B,“屬性1 = 2和屬性2 = 10”是事件C。事件C是聯合事件,我們將在一會兒。
Hence the problem becomes like this we calculate P(A|C) and P(B|C). Let’s say the first one has a value 0.01 and the second one 0.05. Then our conclusion will be the book belongs to the second class. This is a Bayesian Classifier, naive Bayes assumes the attributes are independent. Hence:
因此,問題變得像這樣,我們計算P(A | C)和P(B | C)。 假設第一個值為0.01,第二個值為0.05。 那么我們的結論將是該書屬于第二類。 這是貝葉斯分類器, 樸素貝葉斯假定屬性是獨立的。 因此:
P(Attribute 1 = 2 and Attribute 2 = 10) = P(Attribute 1 = 2) * P(Attribute = 10). Let’s call these conditions as x1 and x2 respectively.
P(屬性1 = 2和屬性2 = 10)= P(屬性1 = 2)* P(屬性= 10)。 我們將這些條件分別稱為x1和x2。
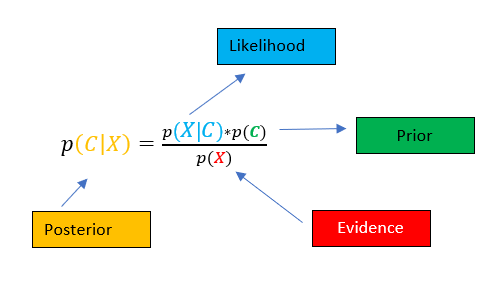
Hence, using the likelihood and Prior we calculate the Posterior Probability. And then we assume that the attributes are independent hence likelihood is expanded as
因此,使用似然和先驗,我們計算后驗概率。 然后我們假設屬性是獨立的,因此可能性隨著
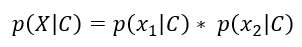
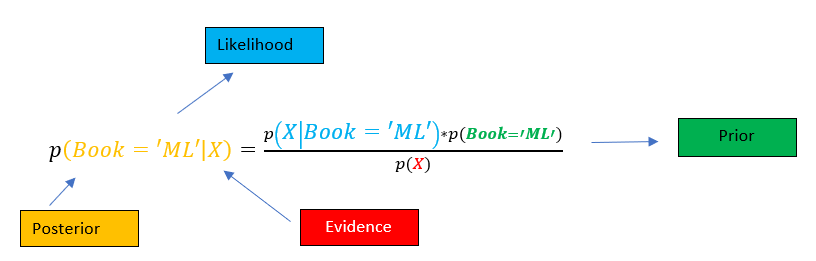
The above equation is shown for two attributes, however, can be extended for more. So for our specific scenario, the equation get’s changed to the following. It is shown only for Book=’ML’, it will be done similarly for Book =’Sports’.
上面的公式顯示了兩個屬性,但是可以擴展更多。 因此,對于我們的特定情況,方程式get更改為以下形式。 僅在Book ='ML'中顯示,對于Book ='Sports'也將類似地顯示。
實現方式: (Implementation:)
Let’s use the famous Flu dataset for naive Bayes and import it, you can change the path. You can download the data from here.
讓我們將著名的Flu數據集用于樸素貝葉斯并將其導入,即可更改路徑。 您可以從此處下載數據。
Importing Data:
匯入資料:
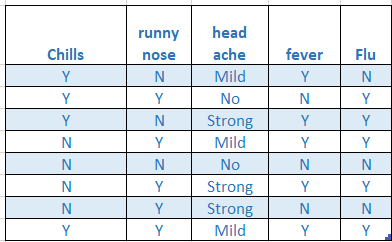
nbflu=pd.read_csv('/kaggle/input/naivebayes.csv')Encoding the Data:
編碼數據:
We store the columns in different variables and encode the same
我們將列存儲在不同的變量中并進行相同的編碼
# Collecting the Variables
x1= nbflu.iloc[:,0]
x2= nbflu.iloc[:,1]
x3= nbflu.iloc[:,2]
x4= nbflu.iloc[:,3]
y=nbflu.iloc[:,4]# Encoding the categorical variables
le = preprocessing.LabelEncoder()
x1= le.fit_transform(x1)
x2= le.fit_transform(x2)
x3= le.fit_transform(x3)
x4= le.fit_transform(x4)
y=le.fit_transform(y)# Getting the Encoded in Data Frame
X = pd.DataFrame(list(zip(x1,x2,x3,x4)))Fitting the Model:
擬合模型:
In this step, we are going to first train the model, then predict for a patient
在這一步中,我們將首先訓練模型,然后為患者預測
model = CategoricalNB()# Train the model using the training sets
model.fit(X,y)#Predict Output#['Y','N','Mild','Y']
predicted = model.predict([[1,0,0,1]])
print("Predicted Value:",model.predict([[1,0,0,1]]))
print(model.predict_proba([[1,0,0,1]]))Output:
輸出:
Predicted Value: [1]
[[0.30509228 0.69490772]]The output tells the probability of not Flu is 0.31 and Flu is 0.69, hence the conclusion will be Flu.
輸出表明非Flu的概率為0.31,Flu為0.69,因此結論為Flu。
Conclusion:
結論 :
Naive Bayes works very well as a baseline classifier, it’s fast, can work on less number of training examples, can work on noisy data. One of the challenges is it assumes the attributes to be independent.
樸素貝葉斯(Naive Bayes)作為基線分類器的效果非常好,速度很快,可以處理較少數量的訓練示例,可以處理嘈雜的數據。 挑戰之一是它假定屬性是獨立的。
Reference:
參考:
[1] Wu X, Kumar V, editors. The top ten algorithms in data mining. CRC Press; 2009 Apr 9.
[1] Wu X,Kumar V,編輯。 數據挖掘中的十大算法。 CRC出版社; 2009年4月9日。
[2] https://towardsdatascience.com/all-about-naive-bayes-8e13cef044cf
[2] https://towardsdatascience.com/all-about-naive-bayes-8e13cef044cf
翻譯自: https://towardsdatascience.com/a-short-tutorial-on-naive-bayes-classification-with-implementation-2f69183d8ce1
樸素貝葉斯實現分類
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391022.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391022.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391022.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

python:改良廖雪峰的使用元類自定義ORM
)
2019年度年中回顧總結_我的2019年回顧和我的2020年目標(包括數量和收入)

在Java里重寫equals和hashCode要注意什么問題

vray陰天室內_陰天有話:第1部分

【codevs2497】 Acting Cute

漸進式web應用程序_漸進式Web應用程序與加速的移動頁面:有什么區別,哪種最適合您?

高光譜圖像分類_高光譜圖像分析-分類

在Java里如何給一個日期增加一天

CentOS 7安裝和部署Docker

JavaScript字符串方法終極指南-拆分
)
機器人的動力學和動力學聯系_通過機器學習了解幸福動力學(第2部分)

在Java里怎將字節數轉換為我們可以讀懂的格式?

ubuntu 16.04 安裝mysql

shell:多個文件按行合并

form子句語法錯誤_用示例語法解釋SQL的子句
)
leetcode 1310. 子數組異或查詢(位運算)

大樣品隨機雙盲測試_訓練和測試樣品生成

vue組件命名指南,不為取名而糾結

JavaScript 基礎,登錄驗證
