python邊玩邊學
Podcasts are a fun way to learn new stuff about the topics you like. Podcast hosts have to find a way to explain complex ideas in simple terms because no one would understand them otherwise 🙂 In this article I present a few episodes to get you going.
播客是一種學習有趣主題的有趣方法。 播客主持人必須找到一種用簡單的術語解釋復雜想法的方法,因為沒人會以其他方式理解它們。🙂在本文中,我將介紹一些情節以助您一臂之力。
In case you’ve missed my previous article about podcasts:
如果您錯過了我以前有關播客的文章:
你應該獲得博士學位嗎 通過部分導數 (Should You Get a Ph.D. by Partially Derivative)

Partially Derivative is hosted by data science super geeks. They talk about the everyday data of the world around us.
數據科學超級極客主持了Partially Derivative。 他們談論我們周圍世界的日常數據。
This episode may be interesting for students who are thinking about pursuing a Ph.D. In this episode, Chris talks about getting a Ph.D. from his personal perspective. He talks about how he wasn’t interested in math when he was young but was more into history. After college, he had enough of school and didn’t intend to pursue a Ph.D. He sent an application to UC Davis and was presented with a challenge. Enjoy listening to his adventure.
對于想攻讀博士學位的學生來說, 這一插曲可能會很有趣。 在這一集中,克里斯談論了獲得博士學位的問題。 從他個人的角度來看。 他談到了他年輕時對數學不感興趣,但對歷史卻更加感興趣。 大學畢業后,他受夠了學業,不打算攻讀博士學位。 他向加州大學戴維斯分校發送了申請,但面臨挑戰。 喜歡聽他的冒險。
Tim, a two time Ph.D. dropout and a data scientist living in North Carolina, has a website dedicated to this topic: SHOULD I GET A PH.D.?
蒂姆(Tim),有兩次博士學位。 輟學和居住在北卡羅來納州的數據科學家,有一個專門討論這個主題的網站: 我應該獲得博士學位嗎?
Let the adventure begin…
讓冒險開始……
線性引數的核技巧和支持向量機 (The Kernel Trick and Support Vector Machines by Linear Digressions)

Katie and Ben explore machine learning and data science through interesting (and often very unusual) applications.
凱蒂(Katie)和本(Ben)通過有趣的(通常是非常不尋常的)應用程序探索機器學習和數據科學。
In this episode, Katie and Ben explain what is the kernel trick in Support Vector Machines (SVM). I really like the simple explanation of heavy machinery behind SVM. Don’t know what maximum margins classifiers are? Then listen first to supporting episode Maximal Margin Classifiers.
在這一集中,Katie和Ben解釋了支持向量機(SVM)中的內核技巧是什么。 我真的很喜歡SVM背后有關重型機械的簡單說明。 不知道什么是最大利潤率分類器? 然后,首先收聽輔助劇集《 最大邊際分類器》 。
A Maximum Margin Classifier tries to find a line (a decision boundary) between the left and right side so that it maximizes the margin. The line is called a hyperplane because usually there are more 2 dimensions involved. The decision boundary is between support vectors.
最大保證金分類器嘗試在左側和右側之間找到一條線(決策邊界),以使保證金最大化。 該線稱為超平面,因為通常涉及更多的二維。 決策邊界在支持向量之間。
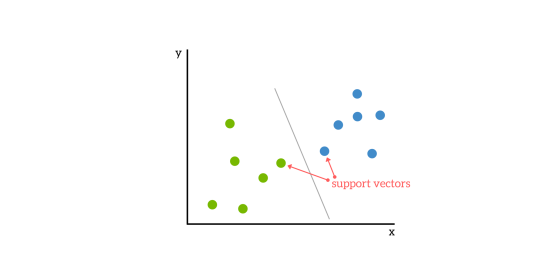
什么是內核技巧? (What is the kernel trick?)
When you have 3 points in a 2-dimensional space, you can arrange points in a way, that they cannot be separated by a line. You can always separate them by putting them in 3 dimensions. One way to introduce a new dimension is to calculate the distance from the origin:
當您在二維空間中有3個點時,可以按某種方式排列點,使它們不能用線隔開。 您始終可以通過將它們分成3維來分離它們。 引入新尺寸的一種方法是計算距原點的距離:
z = x^2 + y^2This will push points farther from the origin more than the ones closer to the origin. Let’s look at a video below. This also makes a linear classifier non-linear, because it maps the boundary to less dimensional space.
這將使離原點更遠的點比靠近原點的點更多。 讓我們看下面的視頻。 這也使線性分類器成為非線性,因為它將邊界映射到較小的空間。

When there are more dimensions than the samples, we can always separate the points with a hyperplane — this is the main idea behind SVM. The polynomial kernel is one of the commonly used kernels with SVM (the most common is Radial basis function). The 2nd-degree polynomial kernel looks for all cross-terms between two features — useful when we would like to model interactions.
當尺寸大于樣本時,我們總是可以使用超平面將點分開-這是SVM的主要思想。 多項式內核是支持SVM的常用內核之一(最常見的是Radial基函數)。 2階多項式內核會尋找兩個特征之間的所有交叉項,這在我們希望對交互進行建模時很有用。
What is the kernel tricks? Popcorn that joined the army and they’ve made him a kernel
什么是內核技巧? 爆米花加入了軍隊,他們使他成為內核
懷疑論者的AI決策 (AI Decision-Making by Data Skeptic)

The Data Skeptic Podcast features interviews and discussion of topics related to data science, statistics and machine learning.
數據懷疑播客提供有關數據科學,統計和機器學習相關主題的訪談和討論。
In this episode, Dongho Kim discusses how he and his team at Prowler have been building a platform for autonomous decision making based on probabilistic modeling, reinforcement learning, and game theory. The aim is so that an AI system could make decisions just as good as humans can.
在本集中 ,Dongho Kim討論了他和他在Prowler的團隊如何建立基于概率建模,強化學習和博弈論的自主決策平臺。 目的是使AI系統能夠做出與人類一樣好的決策。
Rather than deep learning, we are most interested in Bayesian processes
而不是深度學習,我們對貝葉斯過程最感興趣
你走之前 (Before you go)

Follow me on Twitter and join me on my creative journey. I mostly tweet about Data Science.
在Twitter上關注我,并加入我的創意之旅。 我主要在推特上談論數據科學。
These are a few links that might interest you:
這些鏈接可能會讓您感興趣:
- Your First Machine Learning Model in the Cloud- AI for Healthcare- Parallels Desktop 50% off- School of Autonomous Systems- Data Science Nanodegree Program- 5 lesser-known pandas tricks- How NOT to write pandas code翻譯自: https://towardsdatascience.com/learn-data-science-while-listening-a555811b0950
python邊玩邊學
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390682.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390682.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390682.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

react css多個變量_如何使用CSS變量和React上下文創建主題引擎

vue 自定義 移動端篩選條件


如何在Windows中打開和使用命令提示符

ACM-ICPC北京賽區2017網絡同步賽H

PPPOE撥號上網流程及密碼竊取具體實現
)
leetcode 160. 相交鏈表(雙指針)

android開發入門_Android開發入門

新購阿里云服務器ECS創建之后無法ssh連接的問題處理

數據下發非標準用戶權限測試
)
leetcode 474. 一和零(dp)

邊緣計算 ai_在邊緣探索AI!

JavaScript中的全局變量介紹

初識spring-boot
)
leetcode 879. 盈利計劃(dp)

區塊鏈101:區塊鏈的應用和用例是什么?

java請求接口示例_用示例解釋Java接口

如何建立搜索引擎_如何建立搜尋引擎

用Docker自動構建紙殼CMS
