最近,有一份自然語言處理 (NLP) 進展合輯,一發布就受到了同性交友網站用戶的瘋狂標星,已經連續3天高居GitHub熱門榜首位。
合集里面包括,20多種NLP任務前赴后繼的研究成果,以及用到的數據集。
這是來自愛爾蘭的Sebastian Ruder,傾力匯總而成。

他在愛爾蘭國立大學 (戈爾韋) 讀博。另一個身份,是AI創業公司Aylien的研究人員。
塞巴斯蒂安說,NLP近來發展太快了,即便作為局內人,也很難順暢地跟進這個領域里發生的事。
無微不至的倉庫
要找到最常用的數據集,要了解自己研究的問題有了哪些新進展,還是很費力的。

所以,他就在GitHub上面建了一個倉庫,追蹤各種自然語言任務的研究成果,還有對應的數據集。
這是一間整齊的倉庫,任務是按字母順序排列——
· CCG supertagging
· Chunking
· Constituency parsing
· Coreference resolution
· Dependency parsing
· Dialog
· Domain adaptation
· Language modelling
· Machine translation
· Multi-task learning
· Multimodal
· Named entity recognition
· Natural language inference
· Part-of-speech tagging
· Question answering
· Semantic textual similarity
· Sentiment analysis
· Semantic parsing
· Semantic role labeling
· Summarization
· Text classification
作為一個情緒型選手,我點開了情緒分析 (Sentiment Analysis) 的頁面。

這里的數據集很親切,比如IMDb,電影評分網站的數據。
再比如,“ (姑且稱為) 美國的大眾點評”,Yelp的店鋪評論數據集。

每個數據集下面,都有相關研究的列表,以及所用模型的準確度。
當然,情緒的二分類 (Binary Classification) ,以及細粒度分類 (Fine-Grained Classification) ,作為兩種問題,列表也是分開的。
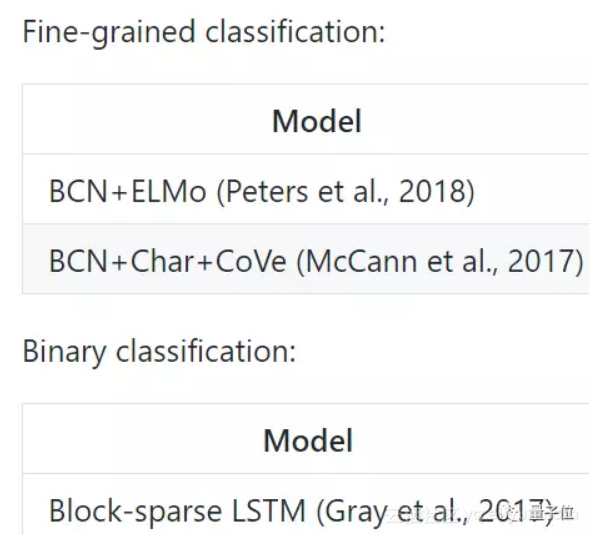
這人文關懷,無微不至。
未解之謎
塞巴斯蒂安還說了,上面列出的那些,是已經開始追蹤的NLP任務。

還有一些任務,被他加入了心愿單——
· Bilingual dictionary induction
· Discourse parsing
· Entity Linking
· Information extraction
· Keyphrase extraction
· Knowledge base population (KBP)
· More dialogue tasks
· Relation extraction
· Semi-supervised learning
這些問題的進展,在他那里還是未解之謎。
深知以一己之力難以將這部分內容補充完整,程序員還給了詳細的參與步驟,希望廣大NLP戰士,可以互相取暖。
去看一看
塞巴斯蒂安給NLP的愛,很深沉了。

他的博客,各位同行或許也很眼熟了。
變身前:Sebastianruder.com
變身后:Ruder.io
沒有收藏的話,現在可以收藏一下。
當然,這里也要手動貼上NLP倉庫的地址:
https://github.com/sebastianruder/NLP-progress
且去走一遭。
原文發布時間為:2018-06-27
本文作者:方栗子
本文來自云棲社區合作伙伴“量子位”,了解相關信息可以關注“量子位”。







![洛谷P3195 [HNOI2008]玩具裝箱TOY(單調隊列優化DP)](http://pic.xiahunao.cn/洛谷P3195 [HNOI2008]玩具裝箱TOY(單調隊列優化DP))











