慣性張量的推理
With the increasing number of data scientists using TensorFlow, it might be a good time to discuss which workstation processor to choose from Intel’s lineup. You have several options to choose from:
隨著使用TensorFlow的數據科學家數量的增加,現在是討論從Intel陣容中選擇哪種工作站處理器的好時機。 您可以選擇以下幾種方式:
- Intel Core processors–with i5, i7, and i9 being the most popular 英特爾酷睿處理器-i5,i7和i9最受歡迎
- Intel Xeon W processors, which are optimized for workstation workloads Intel Xeon W處理器,針對工作站工作負載進行了優化
- Intel Xeon Scalable processors (SP), which are optimized for server workloads and 24/7 operation 英特爾至強可擴展處理器(SP),針對服務器工作負載和24/7操作進行了優化
The next logical question would be what processor to choose if TensorFlow inference performance is critical? The first thing we need to do is to look at where the performance is coming from in the TensorFlow library. One of the main influences on TensorFlow performance (and many other machine learning libraries) is the Advanced Vector Extensions (AVX), specifically those found in Intel AVX2 and Intel AVX-512. Intel’s runtime libraries use AVX, which power TensorFlow performance on Intel processors via the oneAPI Deep Neural Network Library (oneDNN). Other specialized instruction sets such as Vector Neural Network Instructions (VNNI) from Intel Deep Learning Boost are also called by oneDNN.
下一個邏輯問題是,如果TensorFlow推理性能至關重要,則應選擇哪個處理器? 我們要做的第一件事是查看TensorFlow庫中的性能來自哪里。 對TensorFlow性能(以及許多其他機器學習庫)的主要影響之一是高級矢量擴展(AVX),特別是在Intel AVX2和Intel AVX-512中發現的擴展。 英特爾的運行時庫使用AVX,后者通過oneAPI深度神經網絡庫(oneDNN)增強了Intel處理器上的TensorFlow性能。 其他專用指令集,例如Intel Deep Learning Boost的矢量神經網絡指令(VNNI),也被oneDNN調用。
What other factors matter? Does the number of cores matter? Base clock speeds? Let’s benchmark a few Intel processors to get a better understanding. For this test, we have five configurations in workstation chassis (Table 1).
還有其他因素嗎? 核心數量重要嗎? 基本時鐘速度? 讓我們對一些英特爾處理器進行基準測試以獲得更好的理解。 對于此測試,我們在工作站機箱中有五種配置(表1)。
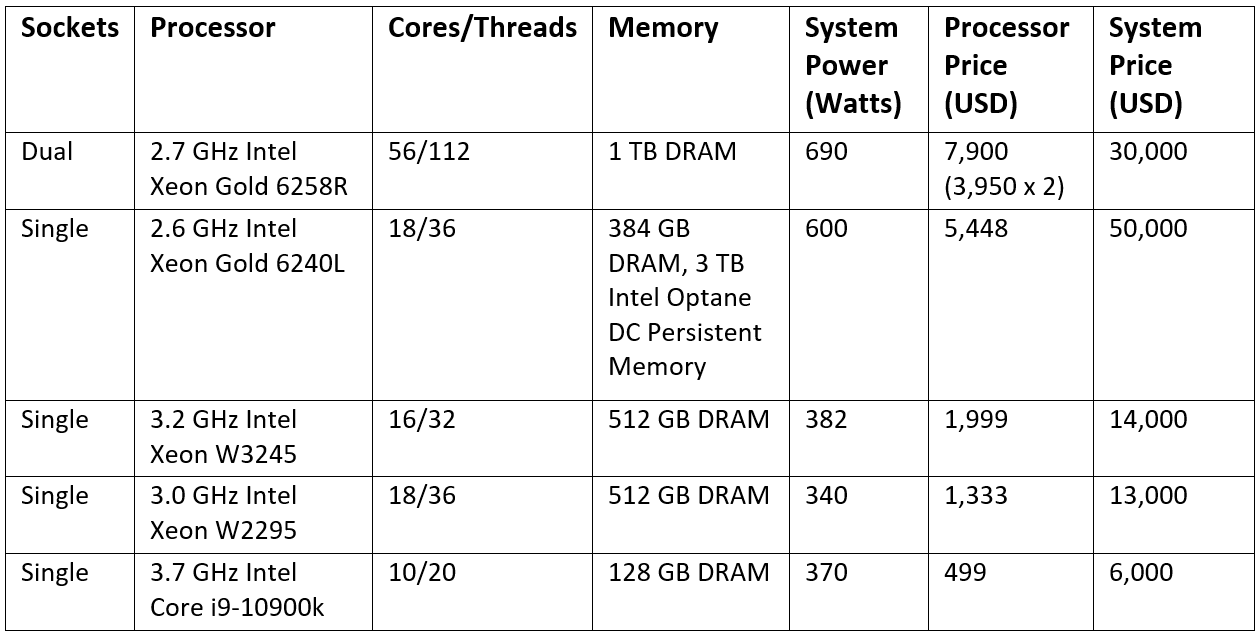
We are using the ResNet-50 model with the ImageNet data set, tested with different batch sizes for inference throughput and latency. Figure 1 shows how many images the inference model can handle per second. The 18-core systems consistently deliver better throughput. What you’re seeing in these TensorFlow benchmarks is how machine learning (ML) and deep learning (DL) translate from framework to algorithm, and then algorithm to hardware. At the end of the day, there is a limit to how well many AI algorithms. Many ML and DL algorithms aren’t naturally parallel, and in a workstation configuration where the power envelope is defined by the wall socket’s maximum current, a balance between core count and core frequency must be taken into consideration.
我們將ResNet-50模型與ImageNet數據集一起使用,并針對不同的批處理量測試了推理吞吐量和延遲。 圖1顯示了推理模型每秒可以處理多少張圖像。 18核系統始終提供更高的吞吐量。 您在這些TensorFlow基準測試中看到的是機器學習(ML)和深度學習(DL)如何從框架轉換為算法,然后從算法轉換為硬件。 歸根結底,人工智能算法的數量是有限的。 許多ML和DL算法并非自然并行,在工作站配置中,功率包絡由墻上插座的最大電流定義,必須考慮芯數和芯頻率之間的平衡。
Let’s take a deeper look at Figure 1. If we compare the dual-socket Intel Xeon 6258R to the single-socket 6240L, the results show that an 18-core processor with slightly higher frequencies is better for TensorFlow inference than one with over 6x the number of cores. The lesson here is that many ML and DL don’t scale well, so more cores may not always be better.
讓我們更深入地看一下圖1。如果將雙插槽Intel Xeon 6258R與單插槽6240L進行比較,結果表明,使用頻率稍高的18核處理器比TensorFlow推理的頻率高6倍的處理器更好。核心數。 這里的教訓是,許多ML和DL的伸縮性都不好,因此更多的內核可能并不總是更好。
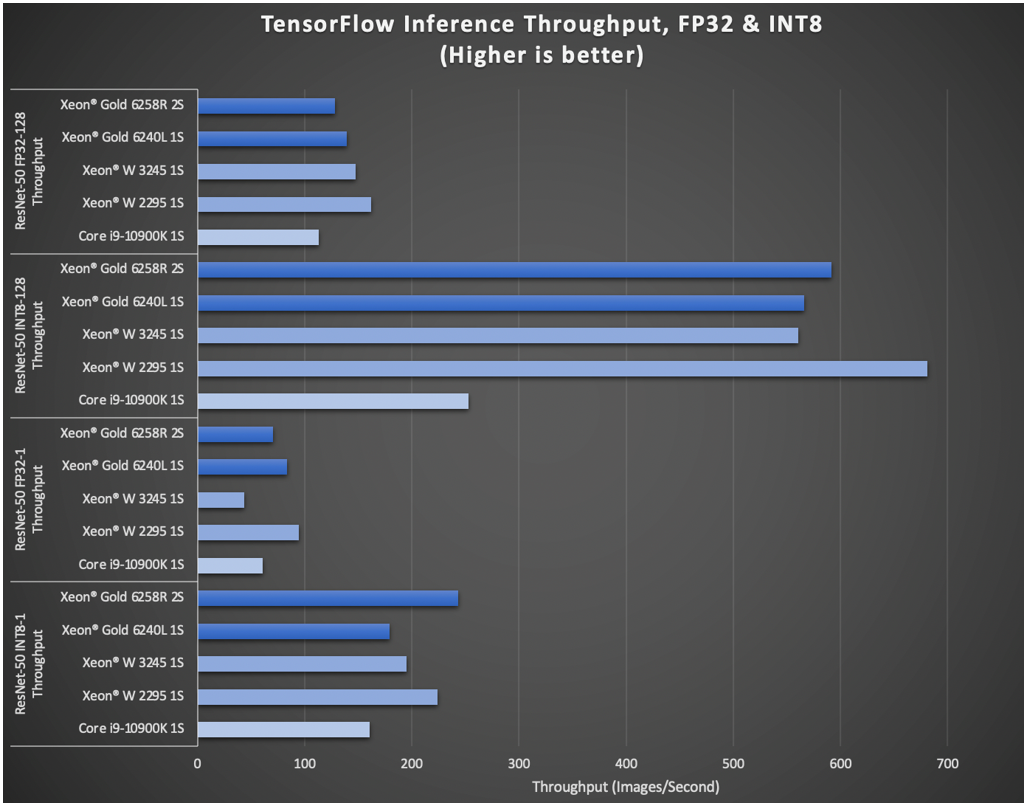
Figure 2 shows the inference latency on the benchmarking systems. This is the time it takes an inference model loaded in memory to make a prediction based on new data. Inference latency is important for time-sensitive or real-time applications. The dual-socket system has slightly higher latency in FP32 but the lowest latency in INT8. The 18-core systems have similar latencies and exhibit performance in line with the throughput performance rankings in Figure 1.
圖2顯示了基準測試系統上的推理延遲。 這是將推理模型加載到內存中以根據新數據進行預測的時間。 推理延遲對于時間敏感或實時應用很重要。 雙路系統在FP32中具有稍高的延遲,但在INT8中具有最低的延遲。 18核系統具有類似的延遲,并且表現出與圖1中的吞吐量性能排名一致的性能。
The Intel Xeon W2295 does the best in most of the tests, but why is that? It has to do with the Intel AVX-512 base and turbo frequencies. The Intel Xeon W processor series is clocked higher than the Intel Xeon SP under AVX instructions. Under any AVX instructions, the processor moves to a different speed to offset the additional power draw, and with the vast majority of ML and DL using AVX-512, the higher base and turbo frequencies of the Intel Xeon W give faster throughput over the comparable Intel Xeon SP processor. Additionally, 18 cores appears to be the best balance between core count and AVX-512 frequency in these tests: more cores over 18 sacrificing AVX frequencies and increasing latency, and fewer cores decreasing in throughput and increasing in latency.
英特爾至強W2295在大多數測試中表現最好,但是為什么呢? 它與Intel AVX-512基本頻率和Turbo頻率有關。 根據AVX指令,Intel Xeon W處理器系列的時鐘頻率高于Intel Xeon SP。 在任何AVX指令下,處理器將以不同的速度移動以抵消額外的功耗,并且在使用AVX-512的絕大多數ML和DL中,Intel Xeon W的較高基本頻率和Turbo頻率提供了比同類產品更快的吞吐量。英特爾至強SP處理器。 此外,在這些測試中,18個內核似乎是內核數量與AVX-512頻率之間的最佳平衡:超過18個內核犧牲了AVX頻率并增加了延遲,更少的內核減少了吞吐量并增加了延遲。
Why is there such an advantage in INT8 batch inference with the Intel Xeon processors over the Intel Core i9? What you are seeing there is the use of the VNNI instructions by oneDNN, which reduce convolution operations from three instructions to one. The Intel Xeon processors used in these benchmarks support VNNI for INT8, but the Intel Core processor does not. The performance difference is quite noticeable in the previous charts.
為什么與英特爾?酷睿?i9相比,英特爾?至強?處理器在INT8批量推理中具有如此優勢? 您所看到的是oneDNN使用VNNI指令,這將卷積運算從三個指令減少到一個。 這些基準測試中使用的Intel Xeon處理器支持INT8的VNNI,但Intel Core處理器不支持。 在以前的圖表中,性能差異非常明顯。
Finally, let’s talk about how to choose the Intel processor to best fit your TensorFlow requirements:
最后,讓我們討論一下如何選擇最適合您的TensorFlow要求的英特爾處理器:
- Do you need large memory to load the data set? Do you need the ability to administer your workstation remotely? If so, get a workstation with the Intel Xeon Gold 6240L, which can be configured with up to 3.3 TB of memory using a mix of Intel Optane DC Persistent Memory and DRAM. 您是否需要大內存來加載數據集? 您是否需要能夠遠程管理工作站? 如果是這樣的話,請購買配備Intel Xeon Gold 6240L的工作站,該工作站可以使用Intel Optane DC持久性內存和DRAM進行配置,最多可配置3.3 TB內存。
- Need the best all-rounder with the Intel Xeon features with moderate system memory? Use the Intel Xeon W2295. In lieu of some of the server-class features like Intel Optane DCPMM and 24/7 operation, you can get equivalent inference performance at half the cost of the Intel Xeon SP configurations and over 30% less power. 是否需要具有適度系統內存的Intel Xeon功能的最佳全能產品? 使用英特爾至強W2295。 代替某些服務器級功能(如Intel Optane DCPMM和24/7操作),您可以獲得等效的推理性能,而成本僅為Intel Xeon SP配置的一半,而功耗卻降低了30%以上。
- Need a budget-friendly option? An Intel Core processor such as the i9–10900k fits the bill. 需要預算友好的選擇嗎? 像i9–10900k這樣的Intel Core處理器非常適合。
Have additional inference needs on the workstation beyond the CPU? We have products such as Intel Movidius and purpose-built AI processors from Intel’s Habana product line that can help fit those needs.
除了CPU,工作站上還有其他推理需求嗎? 我們擁有英特爾Movidius等產品以及英特爾Habana產品系列中的專用AI處理器,可以幫助滿足這些需求。
With the performance attributes of TensorFlow detailed above, picking the right workstation CPU should be a bit easier.
有了上面詳細介紹的TensorFlow的性能屬性,選擇合適的工作站CPU應該會容易一些。
If you want to reproduce these tests to evaluate your TensorFlow needs, use the following instructions. First download the GitHub repo (https://github.com/IntelAI/models) and configure the Conda (Channel: Intel, Python=3.7.7) and runtime environment:
如果要重現這些測試以評估TensorFlow需求,請使用以下說明。 首先下載GitHub存儲庫( https://github.com/IntelAI/models )并配置Conda(渠道:Intel,Python = 3.7.7)和運行時環境:
Set
OMP_NUM_THREADSto the number of cores將
OMP_NUM_THREADS設置為內核數KMP_BLOCKTIME=0KMP_BLOCKTIME=0intra_op_parallelism_threads=<cores>intra_op_parallelism_threads=<cores>inter_op_parallelism_threads=2inter_op_parallelism_threads=2Prepend
numactl --cpunodebind=0 --membind=0to the command below for systems with two or more sockets對于具有兩個或多個套接字的系統,在下面的命令前添加
numactl --cpunodebind=0 --membind=0
Finally, run the following command: python launch_benchmark.py --in-graph <built model> --model-name resnet50 --framework tensorflow --precision fp32<or int8> --mode inference --batch-size=128 --socket-id 0 --data-location <synthetic or real dataset>
最后,運行以下命令: python launch_benchmark.py --in-graph <built model> --model-name resnet50 --framework tensorflow --precision fp32<or int8> --mode inference --batch-size=128 --socket-id 0 --data-location <synthetic or real dataset>
For more information or to learn more about Intel products, please visit www.intel.com.
有關更多信息或要了解有關英特爾產品的更多信息,請訪問www.intel.com 。

翻譯自: https://medium.com/intel-analytics-software/choosing-the-right-intel-workstation-processor-for-tensorflow-inference-and-development-4afeec41b2a9
慣性張量的推理
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390008.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390008.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390008.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

MongoDB數據庫查詢性能提高40倍
,使用FormData進行Ajax請求)
通過Ajax方式上傳文件(input file),使用FormData進行Ajax請求

并發插入數據庫會導致失敗嗎_會導致業務失敗的數據分析方法

434. 字符串中的單詞數

zooland 新開源的RPC項目,希望大家在開發的微服務的時候多一種選擇,讓微服務開發簡單,并且容易上手。...

187. 重復的DNA序列
)
牛客網_Go語言相關練習_選擇題(2)

機器學習模型部署_9月版部署機器學習模型

352. 將數據流變為多個不相交區間

Java常用的八種排序算法與代碼實現

熊貓ai智能機器人量化_機器學習中的熊貓是什么


調用百度 Echarts 顯示重慶市地圖

JEESZ-SSO解決方案

女朋友天天氣我怎么辦_關于我的天氣很奇怪
,size()的區別)
Java中length,length(),size()的區別

5895. 獲取單值網格的最小操作數

為什么要用Redis

第一次馬拉松_成為數據科學家是一場馬拉松而不是短跑
