大數據ab 測試
Hello Everyone!
大家好!
I am back with another article about Data Science. In this article, I will write about what is A-B testing and how to use it on real life data-set to compare two advertisement methods.
我回來了另一篇有關數據科學的文章。 在本文中,我將介紹什么是AB測試以及如何在現實生活的數據集上使用它來比較兩種廣告方法。
What is A-B Testing and where do we use it?
什么是AB測試,我們在哪里使用它?
A/B testing is a method used to compare two versions or methods of something. It is a very popular method used by from big companies like Facebook, Google, Amazon, Ali Express etc. to many other companies. With this method, we can decide on, for example, the following:
A / B測試是一種用于比較某事物的兩個版本或方法的方法。 從Facebook,Google,Amazon,Ali Express等大公司到許多其他公司,這是一種非常流行的方法。 使用這種方法,我們可以決定例如以下內容:
- Button shape, size or color, 按鈕的形狀,大小或顏色
- Which advertisement strategy is better, 哪種廣告策略更好,
- Which email format is better, 哪種電子郵件格式更好,
- Which website design is better, 哪個網站設計更好,
- Which headline is better etc. 哪個標題更好,等等。
So let us apply this testing method on a real life situation.
因此,讓我們將這種測試方法應用于現實生活中。
案例分析: (Case Study:)
A big social platform recently introduced an advertisement method with a new bidding type “average bidding”, as an alternative to its existing advertisement method with bidding type called “maximum bidding”. One of their clients has decided to test this new feature and wants to conduct an A/B test to understand if average bidding brings more conversions than maximum bidding.
大型社交平臺最近推出了一種具有新出價類型“平均出價”的廣告方法,以替代其現有的具有出價類型的廣告方法“最高出價”。 他們的一位客戶決定測試此新功能,并希望進行A / B測試,以了解平均出價帶來的轉化次數是否大于最高出價。
In this A/B test, the client randomly splits its audience into two equally sized groups, e.g. the test and the control group. The existing ad campaign with “maximum bidding” is served to “control group” and the new campaign with “average bidding” is served to the “test group”. The A/B test has run for 1 month and now the client wants to analyze and present the results of this A/B test.
在此A / B測試中,客戶將受眾隨機分為兩個大小相等的組,例如測試組和對照組。 現有的具有“最高出價”的廣告系列將投放到“對照組”,而具有“平均出價”的新廣告系列將投放到“測試組”。 A / B測試已經進行了1個月,現在客戶希望分析并展示此A / B測試的結果。
To understand the data variables better, we need to understand the customer journey for the campaign. The customer journey for this campaign is as in the order below:
為了更好地了解數據變量,我們需要了解廣告系列的客戶旅程。 此廣告系列的客戶流程如下:
1. User sees an ad (Impression)
1.用戶看到一個廣告(展示)
2. User clicks on the website link on the ad (Website Click)
2.用戶點擊廣告上的網站鏈接(網站點擊)
3. User makes a search on the website (Search)
3.用戶在網站上進行搜索(搜索)
4. User views details of a product (View Content)
4.用戶查看產品的詳細信息(查看內容)
5. User adds the product to the cart (Add to Cart)
5.用戶將產品添加到購物車(添加到購物車)
6. User purchases the product (Purchase)
6.用戶購買產品(購買)
數據理解 (Data Understanding)
The variables are the same in both groups. There are totally 10 variables (10 columns): “Campaign Name”, “Date”, “Spend[USD]”, “# of Impressions (the number of times an ad is displayed)”, “Reach (the number of unique people who saw an ad)”, “# of Website Clicks (the number of clicks on ad links directed to Advertiser’s website)”, “# of Searches”, “# of View Content”, “# of Add to Cart”, “# of Purchase”. There are equal number of observations in both groups (30 rows each).
兩組中的變量相同。 總共有10個變量(10列):“廣告系列名稱”,“日期”,“支出[USD]”,“展示次數(顯示廣告的次數)”,“到達率(唯一身份的人數)誰看到了廣告)”,“網站點擊次數(指向廣告商網站的廣告鏈接的點擊次數)”,“搜索次數”,“查看內容數量”,“添加到購物車的數量”,“#購買”。 兩組中的觀察數相等(每組30行)。
The most important metric for analyzing success for the customer is “# of Purchases”.
分析客戶成功的最重要指標是“購買數量”。
Other metrics that are widely used and compared are CTR (Click Through rate), CPA (Cost per Action), CR (Conversion rate):
廣泛使用和比較的其他指標是CTR(點擊率),CPA(每次操作費用),CR(轉化率):
Click Through Rate: Number of Website Clicks / Number of Impressions
點擊率:網站點擊次數/展示次數
Cost per Action: Spend / Number of Actions
每次操作費用:支出/操作次數
Conversion Rate: Number of Actions / Number of Website Clicks
轉化率:操作數/網站點擊數
Action: Can be any conversion event, such as Search, View Content, Add to Cart and Purchase.
行動:可以是任何轉化事件,例如搜索,查看內容,添加到購物車和購買。
數據預處理 (Data Pre-processing)
When analyzing the data-set, it is found that:
分析數據集時,發現:
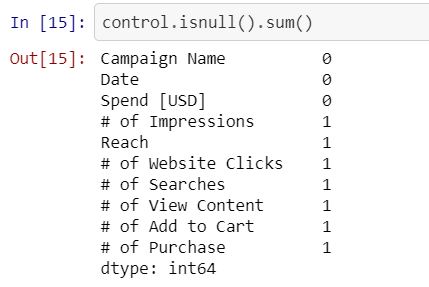
Control group has one NA row. This row has only Date and Spend values, other values are missing:
對照組有一個NA行。 該行只有日期和支出值,其他值缺失:
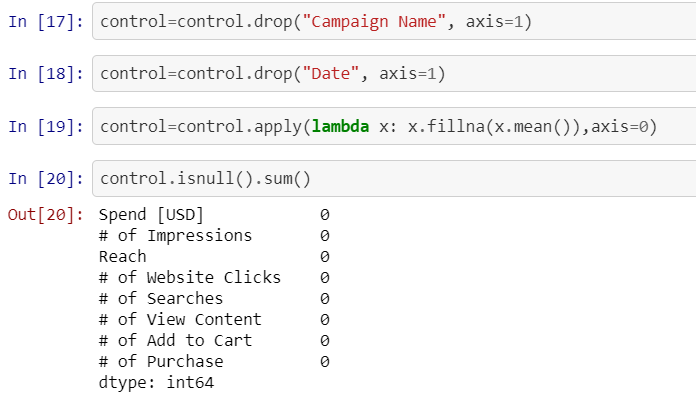
The mean values of these variables are assigned to their own NA values respectively:
這些變量的平均值分別分配給它們自己的NA值:
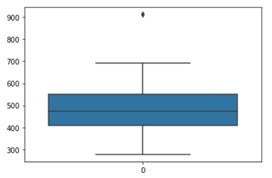
It is found that there is no outlier in the “# of Purchase” variable of the control group. Test group does not have any missing values. However, it has one outlier in # of Purchases:
發現對照組的“購買數量”變量中沒有異常值。 測試組沒有任何缺失值。 但是,它在購買數量中有一個異常值:
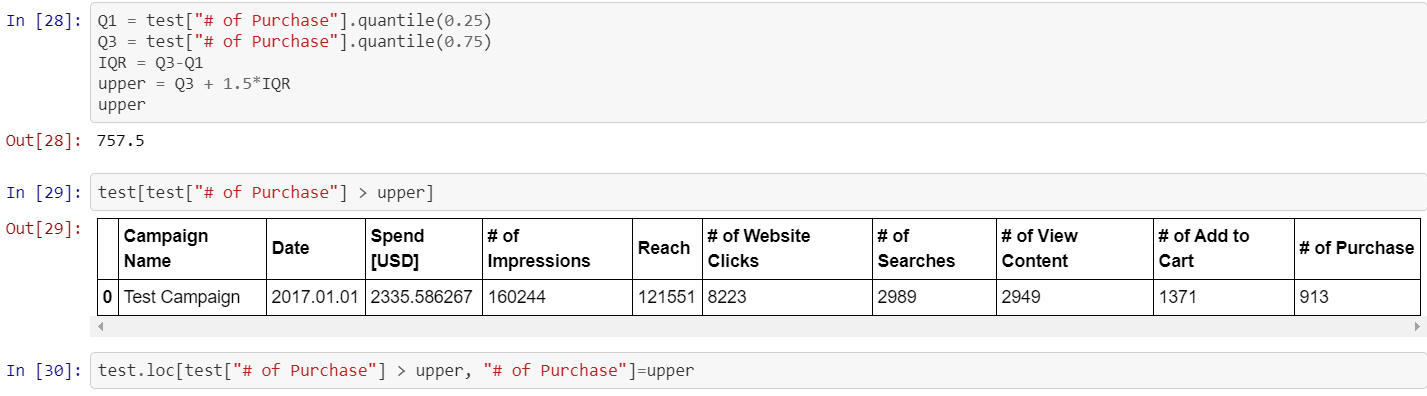
This value is repressed by assigning the upper bound value to it. Upper bound value is found by Box-plot method:
通過為其指定上限值來抑制此值。 上限值通過Box-plot方法找到:
Now we have no outliers in test group as well. The data-set is ready for hypothesis testing.
現在我們在測試組中也沒有異常值。 數據集已準備好進行假設檢驗。
· Group A: Existing method: Maximum Bidding — Control Group
·A組:現有方法:最高出價-對照組
· Group B: New method: Average Bidding — Test Group
·B組:新方法:平均出價-測試組
假設檢驗 (Hypothesis Testing)
Control Group has 507 purchases in average and test group has 481 purchases in average, meaning Control group has more purchases in average. However, we need to check if this is a significant difference. For this, we need to make hypothesis test. As we have independent and paired sample groups, we can use T-testing for Hypothesis test. A t-test is a statistic method used to determine if there is a significant difference between the means of two groups based on a sample of data. The common assumptions made when doing a t-test include normality of data distribution and equality of variance in standard deviation.
對照組平均有507筆采購,測試組平均有481筆采購,這意味著對照組平均有更多的采購。 但是,我們需要檢查這是否有顯著差異。 為此,我們需要進行假設檢驗。 由于我們有獨立且成對的樣本組,因此我們可以將T檢驗用于假設檢驗。 t檢驗是一種統計方法,用于根據數據樣本確定兩組平均值之間是否存在顯著差異。 進行t檢驗時,通常的假設包括數據分布的正態性和標準偏差的方差相等。
1. Normality of data distribution
1.數據分發的常態
2. Equality of variances
2.方差均等
1) Controlling 1st Assumption:
1)控制第一個假設:
Shapiro test is applied for checking the first assumption. The hypothesis is constructed as follows:
Shapiro檢驗用于檢查第一個假設。 假設的構造如下:
H0: The data is normally distributed
H0:數據正態分布
H1: The data is not normally distributed
H1:數據不是正態分布
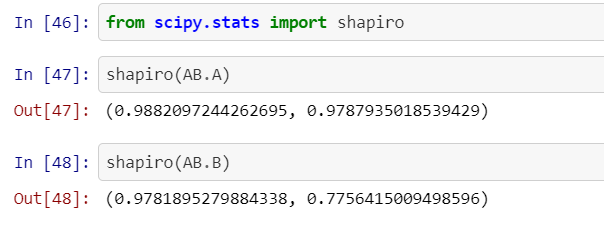
The results of the test are found as follows:
測試結果如下:
· p-value of group A is 0.979 which is >0.05 so we fail to reject H0 meaning that group A is normally distributed.
·組A的p值為0.979,即> 0.05,因此我們無法拒絕H0,這意味著組A是正態分布的。
· p value of group B is 0.776 which is <0.05 so we fail to reject H0 meaning that group B data is normally distributed.
·B組的p值為0.776,該值<0.05,因此我們不能拒絕H0,這意味著B組數據是正態分布的。
As a result of Shapiro test, it is seen that the normality assumption has been satisfied.
作為Shapiro測試的結果,可以看出正態性假設已得到滿足。
2) Controlling 2nd Assumption:
2)控制第二個假設:
Levene test is applied for checking the first assumption. The hypothesis is constructed as follows:
Levene檢驗用于檢驗第一個假設。 假設的構造如下:
H0: The variances are equal(homogeneous)
H0:方差相等(均勻)
H1: The variances are unequal(non-homogeneous)
H1:方差不相等(不均勻)

As the p-value has been found as 0.11 which is >0.05, we fail to reject H0 meaning that the variances of both groups are equal variances.
由于發現p值為0.11(大于0.05),我們不能拒絕H0,這意味著兩組的方差是相等的方差。
As the normality and equal variance of distributions assumptions are satisfied, we can use Independent Two-Sample T-Test for testing the hypothesis:
當滿足分布假設的正態性和均方差時,我們可以使用獨立兩次樣本T檢驗來檢驗假設:
對于2-T檢驗,假設如下: (For 2-T test, the hypothesis is as follows:)
H0: There is no statistically significant difference between control and test groups with respect to the average of Number of Purchases ( μ1=μ2 )
H0:對照組和測試組之間的平均購買次數(μ1=μ2)沒有統計學上的顯著差異
H1: There is statistically significant differences between control and test groups with respect to the average of Number of Purchases (μ1 ≠ μ2 )
假設1:對照組和測試組之間的平均購買次數(μ1≠μ2)在統計上有顯著差異

After tests are applied, the p value resulted in more than 0.05 significance level. Therefore, the result is “fail to reject H0” that is there is no statistically significant difference between control and experiment groups with respect to the average of Number of Purchases (μ1=μ2).
應用測試后,p值導致超過0.05的顯著性水平。 因此,結果是“未能拒絕H0”,相對于平均購買數量(μ1=μ2),對照組和實驗組之間沒有統計學上的顯著差異。
通過假設檢驗分析其他指標: (Analyzing Other Metrics by Hypothesis Testing:)
More metrics have been tested to see if the new method is better or not. The metrics that were analyzed are Click through rate (CTR), CPA (Cost per Action) and Conversion Rate (CR). When comparing rates in two independent groups, independent 2-sample proportion test is used.
已經測試了更多指標,以查看新方法是否更好。 分析的指標為點擊率(CTR),CPA(每次操作費用)和轉化率(CR)。 比較兩個獨立組的比率時,使用獨立的2樣本比例測試。
1) CTR:
1) 點擊率:
CTR= Number of Website Clicks / Number of Impressions
點擊率=網站點擊次數/展示次數
The proportions are calculated for both groups. Control group’s CTR is found as 0.045 and Test group’s CTR is found as 0.044. There is slight difference between two groups’ CTR values and the control group has bigger rate. Let’s see if this difference is statistically significant. The hypothesis is constructed as follows:
計算兩組的比例。 對照組的CTR為0.045,測試組的CTR為0.044。 兩組的CTR值之間存在細微差異,而對照組的CTR值則較大。 讓我們看看這種差異是否具有統計意義。 假設的構造如下:
H0: There is no statistically significant difference between control and test group CTR rates.
H0:對照組和測試組的點擊率之間沒有統計學上的顯著差異。
H1: There is a statistically significant difference between control and test group CTR rates.
假設1 :對照組和測試組的點擊率有統計學差異。

As a result, the p-value found smaller than 0.05 meaning that we reject the null hypothesis. When bidding methods are examined, there is a statistically significant difference between CTR rates. And this difference is in favor of the control group (current existing “max bidding” method).
結果,發現p值小于0.05,這意味著我們拒絕了原假設。 在檢查出價方法時,點擊率之間在統計上有顯著差異。 這種差異有利于對照組(當前現有的“最高出價”方法)。
2) CPA:
2) 每次轉化費用:
CAP= Spend / Number of Actions = Spend/Number of Purchases
CAP =支出/操作次數=支出/購買次數
Number of actions is taken as the number of the purchases in this calculation.
在此計算中,將操作數作為購買數。
The proportions are calculated for both groups and found as follows:
計算兩組的比例,結果如下:
Control group’s CPA is found as 5, it means that a customer’s one purchase costed us 5 USD in average. Test group’s CPA is found as 5.23, it means that a customer’s one purchase costed us 5.23 USD in average.
對照組的CPA為5,這表示客戶一次購買的平均費用為5美元。 測試組的CPA為5.23,這表示客戶一次購買的平均費用為5.23美元。
The hypothesis is constructed as follows:
假設的構造如下:
H0: There is no statistically significant difference between control and test group CPA rates.
H0:對照組和測試組的CPA率之間沒有統計學上的顯著差異。
H1: There is a statistically significant difference between control and test group CPA rates.
H1 :對照組和測試組的CPA率之間存在統計學差異。

The p-value has been found smaller than 0.05. We reject H0 meaning that there is statistically meaningful difference between two groups CPA values.
發現p值小于0.05。 我們拒絕H0,這意味著兩組CPA值之間存在統計上有意義的差異。
We can say that the existing method: max bidding is better than the new one as it has cheaper cost per purchase. So still, we cannot say that the new method is better than the existing one. Lastly, CR has been tested.
可以說,現有方法:最高出價比新方法要好,因為它的每次購買費用更便宜。 因此,我們仍然不能說新方法比現有方法更好。 最后,CR已通過測試。
3) CR:
3) CR:
Conversion Rate: Number of Actions / Number of Website Clicks
轉化率:操作數/網站點擊數
For number of actions, 3 different metrics have been analyzed:
對于操作數,已分析了3個不同的指標:
Firstly, the proportions (“# of Purchase”/”# of Website Clicks”) are found as follows:
首先,找到比例(“購買次數” /“網站點擊次數”):
Control CR= 0.098
控制CR = 0.098
Test CR= 0.099
測試CR = 0.099
The hypothesis is constructed as follows:
假設的構造如下:
H0: There is no statistically significant difference between control and test group CR values.
H0:對照組和測試組的CR值之間沒有統計學上的顯著差異。
H1: There is a statistically significant difference between control and test group CR values.
H1 :對照組和測試組的CR值在統計上有顯著差異。
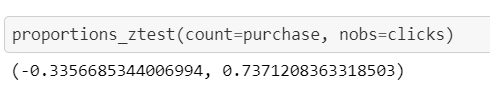
As a result, we fail to reject the null hypothesis meaning that there is no statistically significant difference between control and test groups with respect to the first CR.
結果,我們不能拒絕零假設,即相對于第一個CR,對照組和測試組之間沒有統計學上的顯著差異。
Secondly, the proportions (“# of Purchase”/”# of Add to Cart”) are found as follows:
其次,找到比例(“購買數量” /“添加到購物車數量”):
Control CR2= 0.512
控制CR2 = 0.512
Test CR2= 0.588
測試CR2 = 0.588
This result shows that the occurrence number of buying items after they are added into cart is more in test group. Let’s see if this is significant difference.
結果表明,在測試組中,將購買的商品添加到購物車后的出現次數更多。 讓我們看看這是否有顯著差異。
The hypothesis is constructed as follows:
假設的構造如下:
H0: There is no statistically significant difference between control and test group CR2 values.
H0:對照組和測試組的CR2值之間沒有統計學上的顯著差異。
H1: There is a statistically significant difference between control and test group CR2 values.
H1 :對照組和測試組的CR2值在統計上有顯著差異。

As a result, p-value has been found lower than< 0.05. We reject H0 meaning that there is statistically meaningful difference between two groups CPA values and the difference is in favor of the new method.
結果,發現p值小于<0.05。 我們拒絕H0意味著兩組CPA值之間在統計上存在有意義的差異,并且該差異有利于新方法。
It is the first result that has ever favored the new method.
這是有史以來使用該新方法的第一個結果。
Let’s check the final CR:
讓我們檢查最終的CR:
Lastly, the proportions (“# of Purchase”/”# of View Content”) are found as: Control CR3= 0.334 and Test CR3= 0.345
最后,比例(“購買數量” /“觀看內容數量”)為:控件CR3 = 0.334和測試CR3 = 0.345
Test group has better rate but let’s see if this is significant by applying Hypothesis testing:
測試組的評分較高,但通過使用假設檢驗來看看這是否有意義:
H0: There is no statistically significant difference between control and test group CR3 values.
H0:對照組和測試組的CR3值之間沒有統計學上的顯著差異。
H1: There is a statistically significant difference between control and test group CR3 values.
H1 :對照組和測試組的CR3值在統計上有顯著差異。

As a result, the p-value (0.567) has been found bigger than 0.05. We fail to Reject H0 meaning that there is not statistically meaningful difference between two groups. We cannot conclude anything in here.
結果,發現p值(0.567)大于0.05。 我們無法拒絕H0,這意味著兩組之間在統計上沒有顯著差異。 我們在這里不能得出任何結論。
結果 (Results)
Based on my analysis, I would recommend to client to collect more data for few more months before drawing any conclusions. If there is no chance (no time, no budget etc.), it is not suggested to use the new bidding type (average bidding). Because:
根據我的分析,我建議客戶在得出結論之前再收集幾個月的更多數據。 如果沒有機會(沒有時間,沒有預算等),建議不要使用新的出價類型(平均出價)。 因為:
- Average spend value of new method is more that the existing one. No need to spend more while there is no significant difference between two models: 新方法的平均花費價值大于現有方法。 兩種模式之間沒有顯著差異時,無需花費更多:
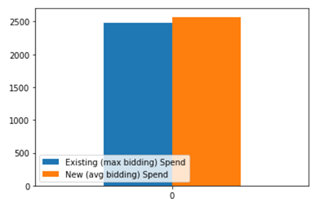
- # of purchase is decreasing when using the new method: 使用新方法時,購買數量正在減少:
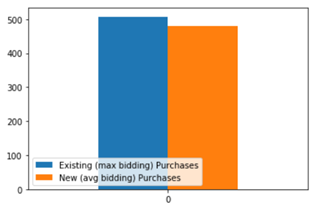
- # of clicks is decreasing when using the new method: 使用新方法時,點擊次數正在減少:
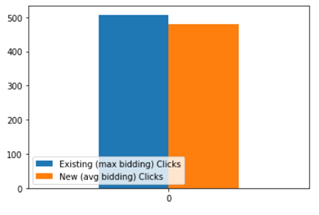
As a result, it doesn’t bring more conversions than existing bidding type (max bidding). I recommend to the client to continue with existing bidding type if a decision must be made now.
因此,它帶來的轉化次數不會超過現有的出價類型(最高出價)。 如果必須立即做出決定,我建議客戶繼續使用現有的出價類型。
In this article, I have given brief information about A/B Testing and where it is used in real life. I have also applied it on a real data-set to compare two advertisement methods. I hope this article will be helpful for you to understand A/B Testing and its applications. You can reach to the full code from my GitHub account:
在本文中,我簡要介紹了A / B測試及其在現實生活中的使用情況。 我還將其應用于實際數據集以比較兩種廣告方法。 希望本文對您了解A / B測試及其應用程序有所幫??助。 您可以從我的GitHub帳戶獲取完整代碼:
https://github.com/bsrymn/AB-Test/blob/master/CaseStudyAB-Test_BusraYaman.ipynb
https://github.com/bsrymn/AB-Test/blob/master/CaseStudyAB-Test_BusraYaman.ipynb
See you in my next articles!!
下篇再見!!
參考資料 (REFERENCES)
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html
https://docs.scipy.org/doc/scipy/reference/generation/scipy.stats.ttest_ind.html
- Veri Bilimi Okulu (Data Science School) Class Notes Veri Bilimi Okulu(數據科學學院)課程筆記
https://hbr.org/2017/06/a-refresher-on-ab-testing
https://hbr.org/2017/06/a-refresher-on-ab-testing
https://medium.com/@ng.dasci/ger%C3%A7ek-verilerle-ab-testi-uygulamas%C4%B1-yeni-reklam-teklif-y%C3%B6ntemi-sat%C4%B1n-alma-say%C4%B1s%C4%B1n%C4%B1-artt%C4%B1rd%C4%B1-m%C4%B1-f9cdd45cdb21
https://medium.com/@ng.dasci/ger%C3%A7ek-verilerle-ab-testi-uygulamas%C4%B1-yeni-reklam-teklif-y%C3%B6ntemi-sat%C4%B1n-alma -say%C4%B1s%C4%B1n%C4%B1-artt%C4%B1rd%C4%B1-m%C4%B1-f9cdd45cdb21
翻譯自: https://medium.com/swlh/a-b-test-application-on-real-data-8ec58f8280f9
大數據ab 測試
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389922.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389922.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389922.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章


node:爬蟲爬取網頁圖片

如何更好的掌握一個知識點_如何成為一個更好的講故事的人3個關鍵點

centos 搭建jenkins+git+maven


記錄一次spark連接mysql遇到的問題

什么事數據科學_如果您想進入數據科學,則必須知道的7件事

python基礎03——數據類型string

Java基礎-基本數據類型

季節性時間序列數據分析_如何指導時間序列數據的探索性數據分析

TortoiseGit上傳項目到GitHub

496. 下一個更大元素 I

利用PHP擴展Taint找出網站的潛在安全漏洞實踐

美團騎手檢測出虛假定位_在虛假信息活動中檢測協調

869. 重新排序得到 2 的冪

org.apache.maven.archiver.MavenArchiver.getManifest


CertUtil.exe被利用來下載惡意軟件

