季節性時間序列數據分析
為什么要進行探索性數據分析? (Why Exploratory Data Analysis?)
You might have heard that before proceeding with a machine learning problem it is good to do en end-to-end analysis of the data by carrying a proper exploratory data analysis. A common question that pops in people’s head after listening to this as to why EDA?
您可能已經聽說,在進行機器學習問題之前,最好通過進行適當的探索性數據分析來對數據進行端到端分析。 聽了為什么要使用EDA的一個普遍問題在人們的腦海中浮現。
· What is it, that makes EDA so important?
·這是什么使EDA如此重要?
· How to do proper EDA and get insights from the data?
·如何進行適當的EDA并從數據中獲取見解?
· What is the right way to begin with exploratory data analysis?
·探索性數據分析的正確方法是什么?
So, let us how we can perform exploratory data analysis and get useful insights from our data. For performing EDA I will take dataset from Kaggle’s M5 Forecasting Accuracy Competition.
因此,讓我們了解如何進行探索性數據分析并從數據中獲得有用的見解。 為了執行EDA,我將從Kaggle的M5預測準確性競賽中獲取數據集。
了解問題陳述: (Understanding the Problem Statement:)
Before you begin EDA, it is important to understand the problem statement. EDA depends on what you are trying to solve or find. If you don’t sync your EDA with respect to solving the problem it will just be plain plotting of meaningless graphs.
開始EDA之前,了解問題陳述很重要。 EDA取決于您要解決或找到的內容。 如果您不同步您的EDA以解決問題,那將只是無意義的圖形的簡單繪圖。
Hence, before you begin understand the problem statement. So, let us understand the problem statement for this data.
因此,在您開始理解問題陳述之前。 因此,讓我們了解此數據的問題陳述。
問題陳述: (Problem Statement:)
We here have a hierarchical data for products for Walmart store for different categories from three states namely, California, Wisconsin and Texas. Looking at this data we need to predict the sales for the products for 28 days. The training data that we have consist of individual sales for each product for 1914 days. Using this train data we need to make a prediction on the next days.
我們在這里擁有來自三個州(加利福尼亞州,威斯康星州和德克薩斯州)不同類別的沃爾瑪商店產品的分層數據。 查看這些數據,我們需要預測產品28天的銷售量。 我們擁有的培訓數據包括1914天每種產品的個人銷售。 使用此火車數據,我們需要在未來幾天進行預測。
We have the following files provided from as the part of the competition:
作為比賽的一部分,我們提供了以下文件:
- calendar.csv — Contains information about the dates on which the products are sold. calendar.csv-包含有關產品銷售日期的信息。
- sales_train_validation.csv — Contains the historical daily unit sales data per product and store [d_1 — d_1913] sales_train_validation.csv-包含每個產品和商店的歷史每日單位銷售數據[d_1-d_1913]
- sample_submission.csv — The correct format for submissions. Reference the Evaluation tab for more info. sample_submission.csv —提交的正確格式。 請參考評估選項卡以獲取更多信息。
- sell_prices.csv — Contains information about the price of the products sold per store and date. sell_prices.csv-包含有關每個商店和日期出售產品的價格的信息。
- sales_train_evaluation.csv — Includes sales [d_1 — d_1941] (labels used for the Public leaderboard) sales_train_evaluation.csv-包括銷售[d_1-d_1941](用于公共排行榜的標簽)
Using this dataset we need to make the sales prediction for the next 28 days.
使用此數據集,我們需要對未來28天進行銷售預測。
分析數據框: (Analyzing Dataframes:)
Now, after you have understood the problem statement well, the first thing to do, to begin with, EDA, is analyze the dataframes and understand the features that are present in our dataset.
現在,在您很好地理解了問題陳述之后,首先要做的是EDA,首先要分析數據框并了解數據集中存在的特征。
As mentioned earlier, for this data we have 5 different CSV files. Hence, to begin with, EDA we will first print the head of each of the dataframe to get the intuition of features and the dataset.
如前所述,對于此數據,我們有5個不同的CSV文件。 因此,首先,EDA我們將首先打印每個數據框的頭部,以獲取要素和數據集的直覺。
Here, I am using Python’s pandas library for reading the data and printing the first few rows. View the first few rows and write your observations.:
在這里,我正在使用Python的pandas庫讀取數據并打印前幾行。 查看前幾行并寫下您的觀察結果:
日歷數據: (Calendar Data:)
First Few Rows:
前幾行:
Value Counts Plot:
值計數圖:
To get a visual idea about our data we will plot the value counts in each of the category of calendar dataframe. For this we will use the Seaborn library.
為了對我們的數據有一個直觀的了解,我們將在日歷數據框的每個類別中繪制值計數。 為此,我們將使用Seaborn庫。

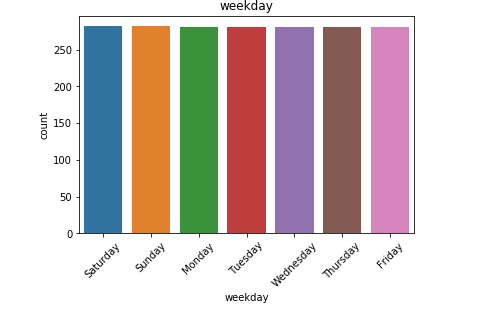
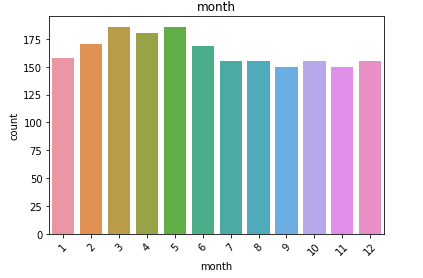
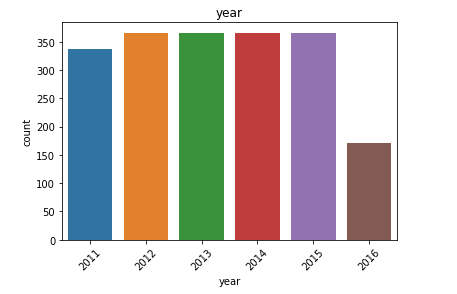

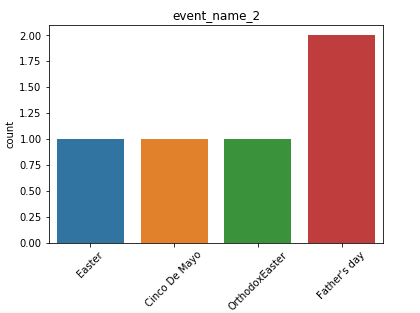
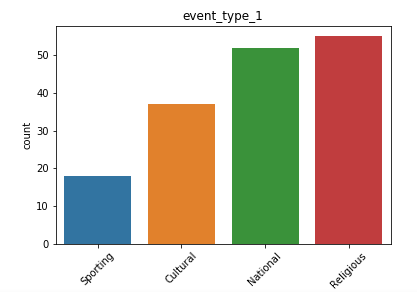
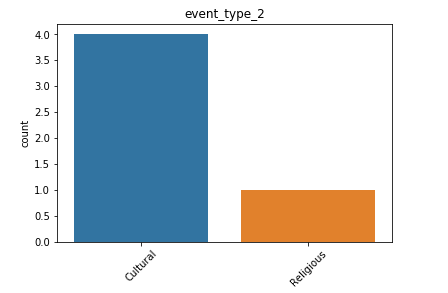
日歷數據框的觀察結果: (Observations from Calendar Dataframe:)
We have the date, weekday, month, year and event for each of day for which we have the forecast information.
我們擁有每天的日期 , 工作日 , 月份 , 年份和事件 ,并為其提供了預測信息。
- Also, we see many NaN vales in our data especially in the event fields, which means that for the day there is no event, we have a missing value placeholder. 同樣,我們在數據中看到許多NaN值,尤其是在事件字段中,這意味著在沒有事件的那天,我們缺少一個占位符。
- We have data for all the weekdays with equal counts. Hence, it is safe to say we do not have any kind of missing entries here. 我們擁有所有平日的數據,并且計數相同。 因此,可以肯定地說我們在這里沒有任何缺失的條目。
- We have a higher count of values for the month of March, April and May. For the last quarter, the count is low. 我們在3月,4月和5月的值計數更高。 對于最后一個季度,這一數字很低。
- We have data from 2011 to 2016. Although we don’t have the data for all the days of 2016. This explains the higher count of values for the first few months. 我們擁有2011年至2016年的數據。盡管我們沒有2016年所有時間的數據。這解釋了前幾個月的價值較高。
- We also have a list of events, that might be useful in analyzing trends and patterns in our data. 我們還提供了事件列表,這可能有助于分析數據中的趨勢和模式。
- We have more data for cultural events rather than religious events. 我們有更多的文化活動而非宗教活動數據。
Hence, by just plotting a few basic graphs we are able to grab some useful information about our dataset that we didn’t know earlier. That is amazing indeed. So, let us try the same for other CSV files we have.
因此,只需繪制一些基本圖形,我們就可以獲取一些我們之前不知道的有關數據集的有用信息。 確實是太神奇了。 因此,讓我們對已有的其他CSV文件嘗試相同的操作。
銷售驗證數據集: (Sales Validation Dataset:)
First few rows:
前幾行:
Next, we will explore the validation dataset provided to us:
接下來,我們將探索提供給我們的驗證數據集:

Value counts plot:
值計數圖:
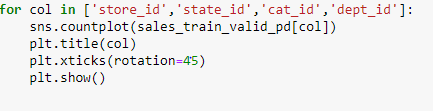
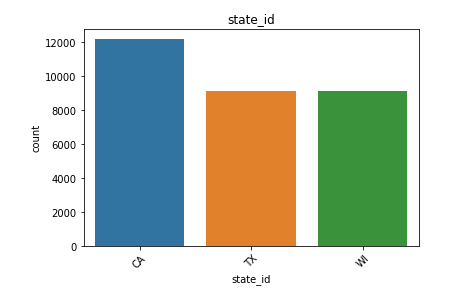
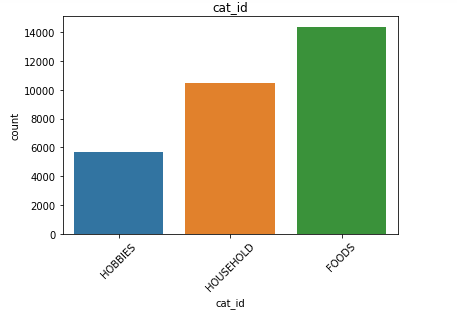
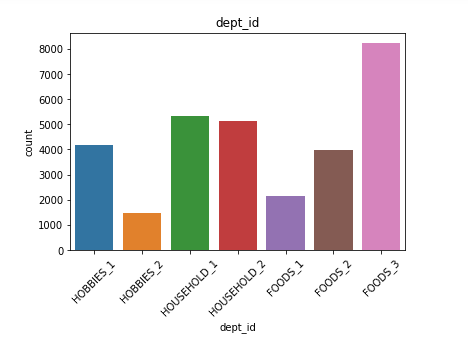
來自銷售數據的觀察: (Observations from Sales Data:)
- We have data for three different categories which are Household, Food and Hobbies 我們有三個不同類別的數據,分別是家庭,食品和嗜好
- We have data for three different states California, Wisconsin and Texas. Of these three states, maximum sales are from the state of California. 我們有加利福尼亞,威斯康星州和德克薩斯州三個不同州的數據。 在這三個州中,最大的銷售量來自加利福尼亞州。
- Sales for the category of Foods is maximum. 食品類別的銷售額最高。
賣價數據: (Sell Price Data:)
First few rows:
前幾行:
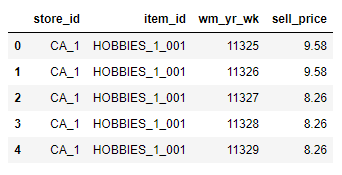
Observations:
觀察結果:
- Here we have the sell_price of each item. 這里我們有每個項目的sell_price。
- We have already seen the item_id and store_id plots earlier. 我們之前已經看過item_id和store_id的圖。
向您的數據提問: (Asking Questions to your Data:)
Till now we have seen the basic EDA plots. The above plots gave us a brief overview about the data that we have. Now, for the next phase we need to find answers of the questions that we have from put data. This depends on the problem statement that we have.
到目前為止,我們已經看到了基本的EDA圖。 上面的圖對我們提供的數據進行了簡要概述。 現在,對于下一階段,我們需要從放置數據中找到問題的答案。 這取決于我們的問題陳述。
For Example:
例如:
In our data we need to forecast the sales for each product on the next 28 days. Hence, for this we need to know if there are any kind of patterns in the sales earlier before that 28 days? Because, if that is so then the sales is likely to follow the same pattern for next 28 days too.
在我們的數據中,我們需要預測未來28天每種產品的銷售額。 因此,為此,我們需要知道在那28天之前的銷售情況中是否存在任何類型的模式? 因為,如果是這樣,那么接下來的28天銷售量也可能會遵循相同的模式。
So, here goes our first question?
那么,這是我們的第一個問題?
過去的銷售分布是什么? (What is the Sales distribution in the past?)
So, to find out the same, let us randomly select few products and see their sales distribution for 1914 days given in our validation data:
因此,要找出相同的結果,讓我們隨機選擇一些產品,并在我們的驗證數據中查看其1914天的銷售分布:

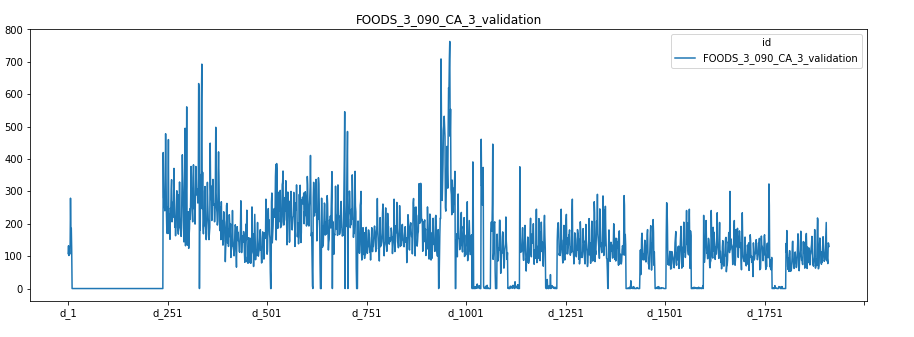
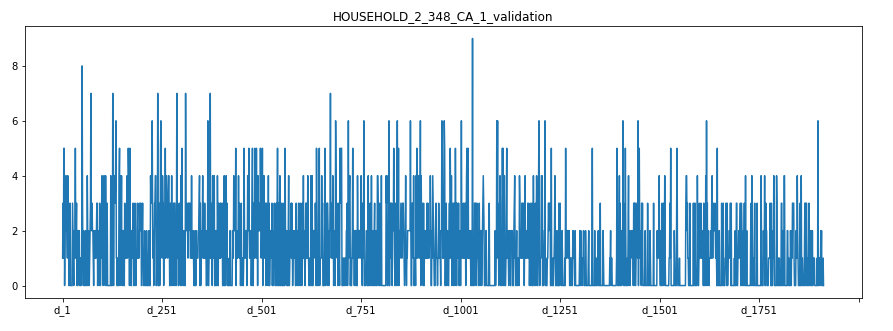
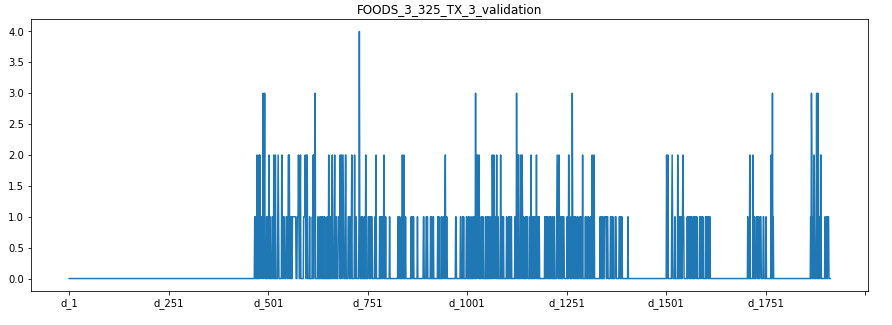
Observations:
觀察結果:
- The plots are very random and it is difficult to find out a pattern. 這些圖是非常隨機的,很難找到一個模式。
For FOODS_3_0900_CA_3_validation we see that on day1 the sales were high after which it was Nil for sometime. After that once again it reached high and is fluctuating up and down since then. The sudden fall after day1 might be because the product got out of stock.
對于FOODS_3_0900_CA_3_validation,我們 看到第一天的銷售量很高,此后一段時間內為零。 此后,它再次達到高點,此后一直在上下波動。 第一天過后的突然下跌可能是因為產品缺貨。
For HOUSEHOLD_2_348_CA_1_validation we see that the sales plot is extremely random. It has a lot of noise. On some day the sales are high and on some it got lowered considerably.
對于HOUSEHOLD_2_348_CA_1_validation,我們看到銷售情況非常隨機。 它有很多噪音。 有一天,銷售很高,有的時候卻大大降低了。
For FOODS_3_325_TX_3_validation we see absolutely no sales for first 500 days. This means that for the first 500 days the product was not in stock. After that the sales reached a peak in every 200 days. Hence, for this food product we see a seasonal dependency.
對于FOODS_3_325_TX_3_validation,我們發現前500天絕對沒有銷售。 這意味著前500天該產品沒有庫存。 此后,銷量每200天達到峰值。 因此,對于這種食品,我們看到了季節依賴性。
Hence, by just randomly plotting few sales graph we are able to take our some important insights from our dataset. These insights will also help us in choosing the right model for training process.
因此,僅通過隨機繪制少量銷售圖,我們就可以從數據集中獲取一些重要見解。 這些見解還將幫助我們為培訓過程選擇正確的模型。
每周,每月和每年的銷售方式是什么? (What is the Sales Pattern on Weekly, Monthly and Yearly Basis?)
We saw earlier that there are seasonal trends in our data. So, next let us break down the time variables and see the weekly, monthly and yearly sales pattern:
之前我們看到數據中存在季節性趨勢。 因此,接下來讓我們分解時間變量,并查看每周,每月和每年的銷售模式:

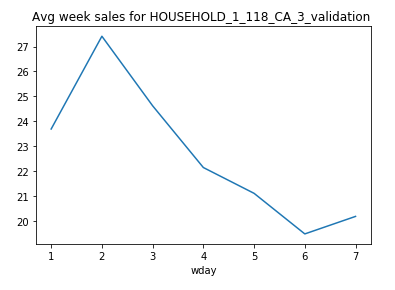
For this particular HOUSEHOLD_1_118_CA_3_validation we can see that the sales see a drop after Tuesday and hits minimum on Saturday.
對于此特定的HOUSEHOLD_1_118_CA_3_validation,我們可以看到銷售在周二之后有所下降,在周六達到最低。

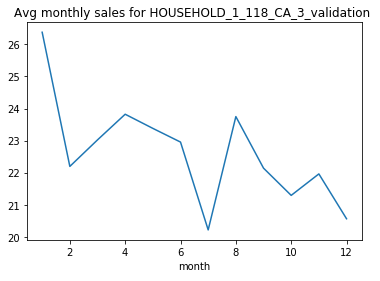
The monthly sales drop in the middle of the year. After which we can say that it reaches a minimum in 7th month that is July.
每月的銷售額在年中下降。 之后,我們可以說它在7月份的第7個月達到了最小值。

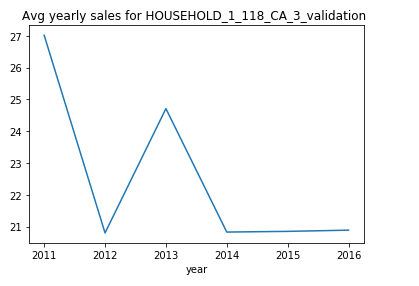
From the above graph we can see that the sales just dropped to zero from 2013 to 2014. This means that the product might be have been updated with a new product version or just removed from this store. From this plot it will be safe to say that for days to predict the sales should still be zero.
從上圖可以看出,從2013年到2014年,銷售剛剛下降到零。這意味著該產品可能已經使用新產品版本進行了更新,或者剛剛從該商店中刪除。 從該圖可以肯定地說,幾天來可以預測銷售額仍為零。
每個類別的銷售分布是什么? (What is the Sales Distribution in Each Category?)
We have sales data belonging to three different categories. Hence, it might be good to see if the sales of product depend on the category it belongs to. The same we will do now:
我們擁有屬于三個不同類別的銷售數據。 因此,最好查看產品的銷售是否取決于其所屬的類別。 我們現在將做的相同:

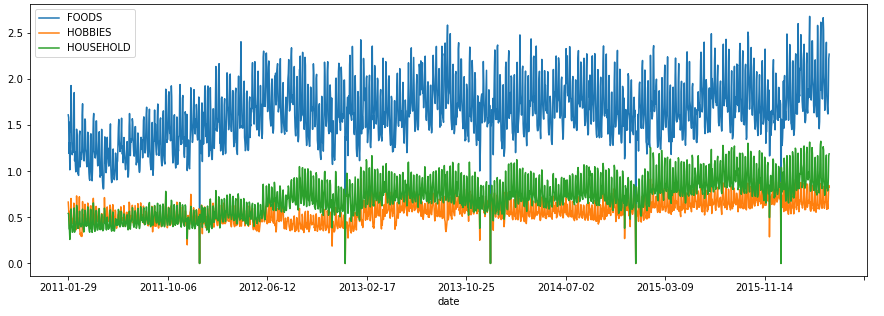
We see that the sales is maximum for Foods. Also, the sales curve for FOOD do not overlap at all with the other two categories. This shows that on any day the sales of Food is more than Household and Hobbies.
我們看到食品的銷售量最大。 另外,食品的銷售曲線與其他兩個類別完全不重疊。 這表明,在任何一天,食品的銷量都超過了家庭和嗜好 。
每個州的銷售分布是什么? (What is the Sales Distribution for Each State?)
Besides category we also have state to which the sales belong. So, let us analyze if there is a state for which the sales follow a different pattern:
除了類別,我們還具有銷售所屬的州。 因此,讓我們分析一下是否存在銷售遵循不同模式的狀態:

在每周,每月和每年的基礎上,屬于“興趣”類別的產品的銷售分布是什么? (What is the Sales Distribution for Products that belong to category of Hobbies on weekly, monthly and yearly basis?)
Now, let us see the sales of randomly selected products from the categories Hobbies and see if their weekly, monthly or yearly average follows a pattern:
現在,讓我們查看“興趣愛好”類別中隨機選擇的產品的銷售情況,并查看其每周,每月或每年的平均值是否遵循以下模式:


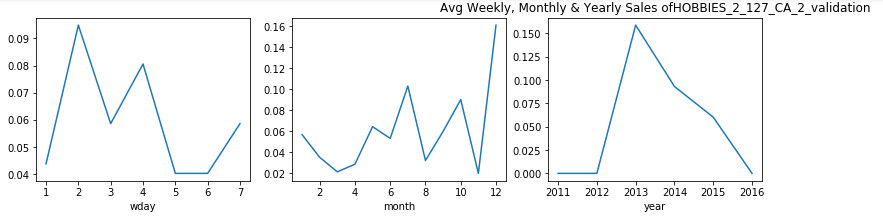


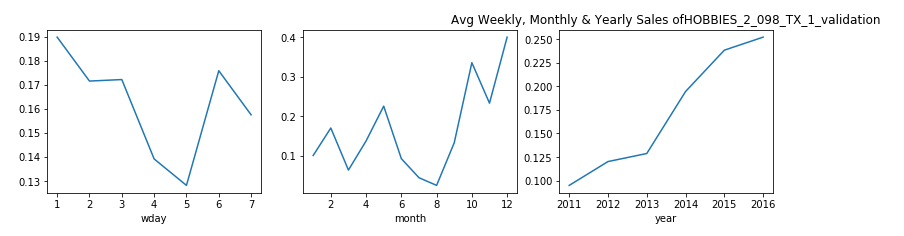


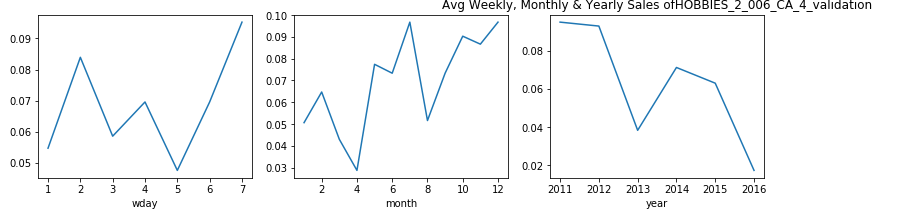
觀察結果 (Observations)
From the above plot we see that in meed week usually for 4th and 5th day (Tuesday and Wednesday), the sales drop especially in the case when states are ‘WI’ and ‘TX’.
從上圖可以看出,通常在第4天和第5天(星期二和星期三)的一周中,銷量下降,尤其是在州為“ WI”和“ TX”的情況下。
Let us analyze the results on individual states to see this more clearly, as we see different sales pattern for different states. And, this brings us to our next question:
讓我們分析各個州的結果,以便更清楚地看到這一點,因為我們看到了不同州的不同銷售模式。 并且,這將我們帶入下一個問題:
特定州在每周,每月和每年的基礎上屬于“興趣”類別的產品的銷售分布是什么? (What is the Sales Distribution for Products that belong to the category of Hobbies on weekly, monthly and yearly basis for a particular state?)


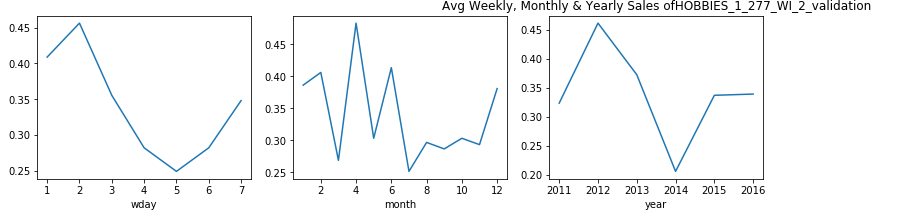
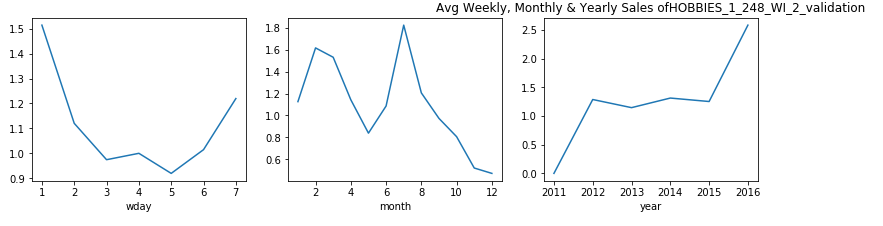
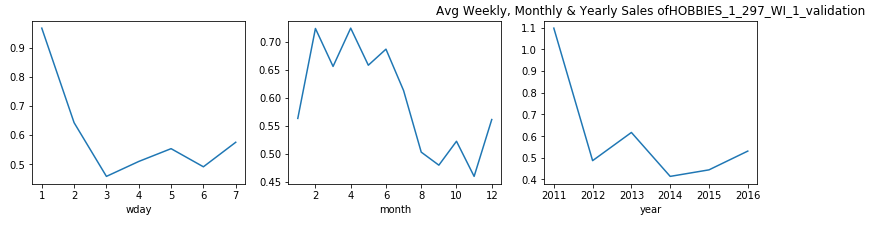
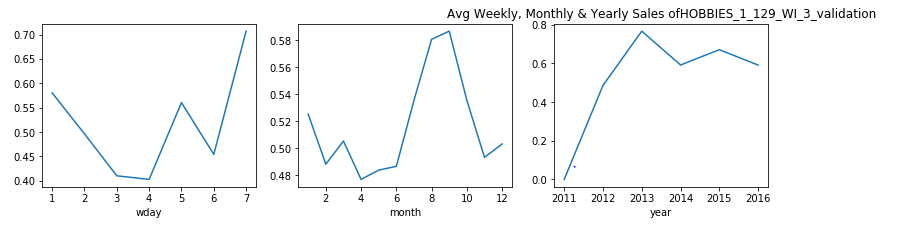
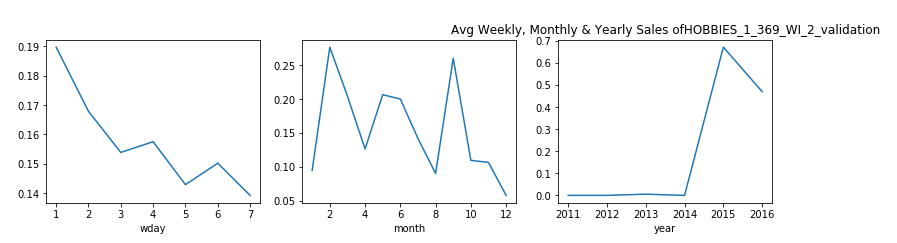

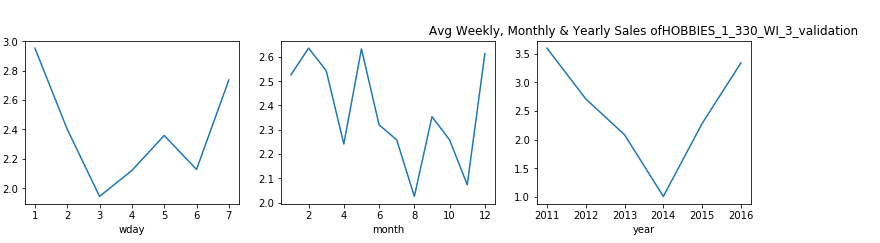
觀察結果: (Observations:)
- From the above plots, we can see that in the state of Wisconsin, for most of the products the sales decrease considerably in mid-week. 從上面的圖可以看出,在威斯康星州,大多數產品的銷售在星期三中大幅下降。
- This also gives us a little sense of life-style of people in Wisconsin, that people here do not shop much during day 3–4 which is Monday and Tuesday. This probably might be because are these are the busiest days of the week. 這也使我們對威斯康星州人們的生活方式有所了解,即這里的人們在周一至周二的第3至4天購物不多。 這可能是因為這些是一周中最忙的日子。
- From the monthly average we can see that, in first quarter the sales often experienced a dip. 從每月平均數可以看出,第一季度的銷售額經常出現下降。
- For the product HOBBIES_1_369_WI_2_validation, we see that the sales data is nill till year 2014. This shows that this product was introduced after this year and the weekly and monthly pattern that we see for this product is after the year 2014. 對于產品HOBBIES_1_369_WI_2_validation,我們看到直到2014年為止的銷售數據都是零。這表明該產品是在今年之后推出的,而我們看到的該產品的每周和每月模式是在2014年之后。
每周,每月和每年,屬于食品類別的產品的銷售分布是什么? (What is the Sales Distribution for Products that belong to category of Foods on weekly, monthly and yearly basis?)
Now, doing analysis for Hobbies individually gave us some useful insights. Let, us try the same for the category of Foods:
現在,分別對愛好進行分析可以為我們提供一些有用的見解。 讓我們對食品類別嘗試相同的方法:


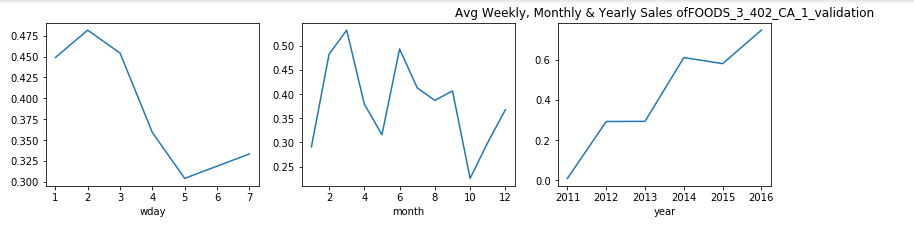

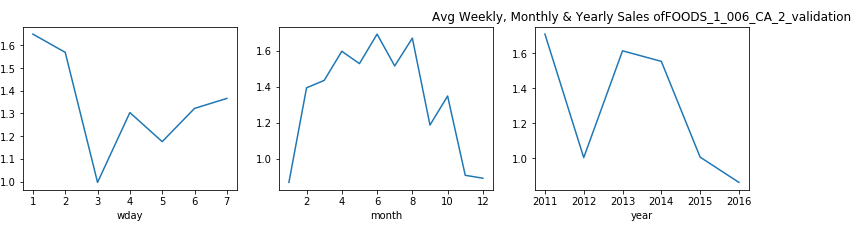
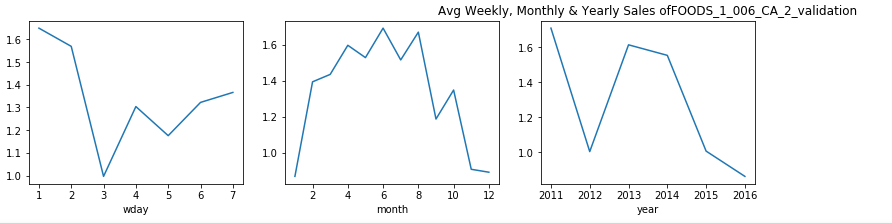
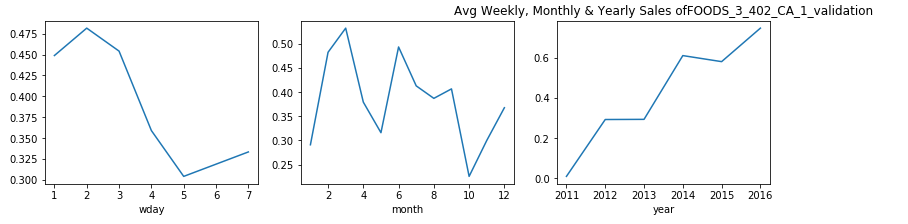
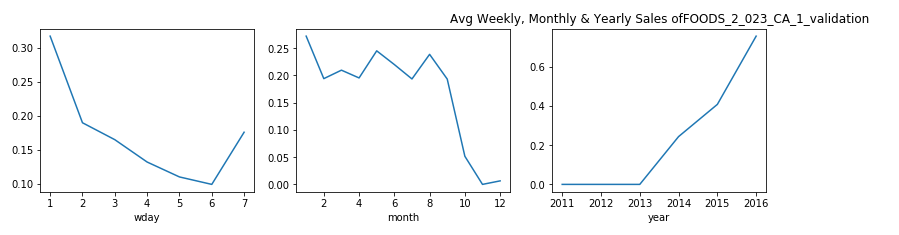
觀察: (Observation:)
- From the plots above we can say that, for food items categories the purchase is more in the early week as compared to the last two days. 從上面的圖可以看出,對于食品類別,與前兩天相比,在前一周的購買量更多。
- This is might be because people are habituated of buying food supplies during the start of the week and then keep it for the entire week. This curves shows us the similar behavior. 這可能是因為人們習慣于在一周開始時購買食品,然后整個星期都保持食用。 該曲線向我們展示了類似的行為。
每周,每月和每年,屬于家庭類別的產品的銷售分布是什么? (What is the Sales Distribution for Products that belong to category of Household on weekly, monthly and yearly basis?)

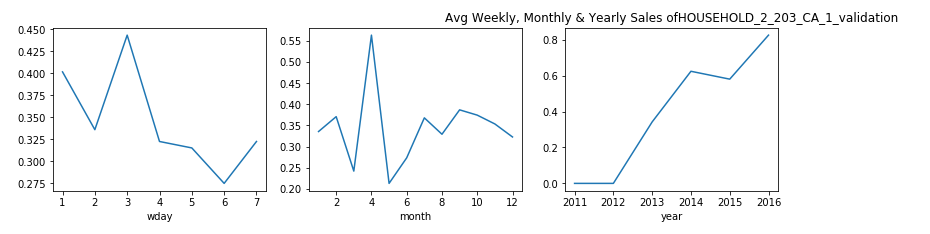
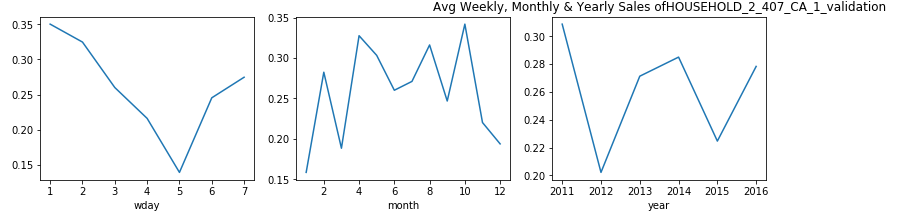
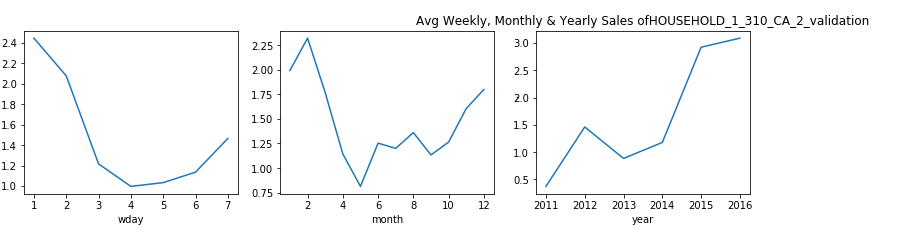
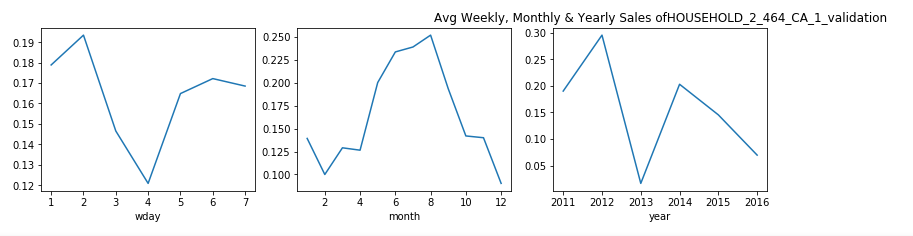
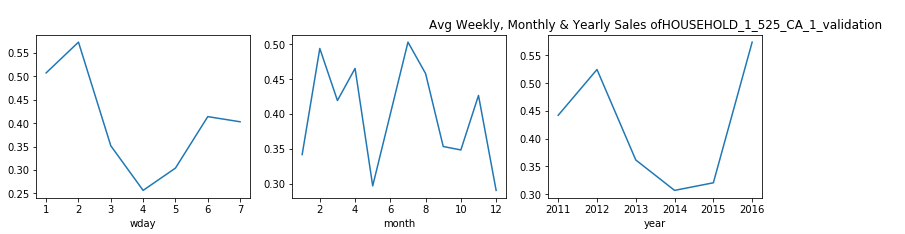
觀察: (Observation:)
From the plots above we can say that, for Household items categories the purchase shows a dip for Monday and Tuesday.
從上面的圖可以看出,對于家庭用品類別,購買顯示星期一和星期二有所下降。
- In the start of week people are busy with office work and hardly go for shopping. This is the pattern that we see here. 在一周的開始,人們忙于辦公室工作,幾乎不去購物。 這就是我們在這里看到的模式。
有沒有辦法在不丟失信息的情況下更清楚地看到產品的銷售情況? (Is there a way to see the sales of products more clearly without losing information?)
We saw plots for sales distribution earlier for each products. These were quite cluttered and we couldn’t see the pattern clearly. Hence, you might be wondering if there is a way to do so. And, the good news is yes there is.
我們早先看到了每種產品的銷售分布圖。 這些非常混亂,我們看不清模式。 因此,您可能想知道是否有辦法做到這一點。 而且,好消息是,是的。
Here comes denoising in picture. We will denoise our dataset and see the distribution.
圖片降噪 。 我們將對數據集進行去噪并查看分布。
Here we will see two common denoising techniques. Wavelet denoising and Moving average.
在這里,我們將看到兩種常見的降噪技術。 小波去噪與移動平均 。
Wavelet Denoising:
小波去噪:
From the sales plots of invidual products we saw that the sales changes rapidly. This is because the sales of a product on a day depend on multiple factors. So, let us try denoising our data and see if we are able to find anything intresesting.
從單個產品的銷售圖上,我們看到銷售變化Swift。 這是因為一天的產品銷售取決于多個因素。 因此,讓我們嘗試對數據進行去噪處理,看看是否能夠找到令人感興趣的東西。
The basic idea behind wavelet denoising, or wavelet thresholding, is that the wavelet transform leads to a sparse representation for many real-world signals and images. What this means is that the wavelet transform concentrates signal and image features in a few large-magnitude wavelet coefficients. Wavelet coefficients which are small in value are typically noise and you can “shrink” those coefficients or remove them without affecting the signal or image quality. After you threshold the coefficients, you reconstruct the data using the inverse wavelet transform.
小波去噪或小波閾值處理的基本思想是,小波變換導致許多現實信號和圖像的稀疏表示。 這意味著小波變換將信號和圖像特征集中在幾個大幅度的小波系數中。 小值的小波系數通常是噪聲,您可以“縮小”這些系數或將其刪除而不影響信號或圖像質量。 對系數設定閾值后,您可以使用小波逆變換來重建數據。
For wavelet denoising, we require the the library pywt.
對于小波去噪,我們需要庫pywt。
Here we will use wavelet denoising. For deciding the threshold of denoising we will use Mean Absolute Deviation.
在這里,我們將使用小波去噪。 為了確定降噪的閾值,我們將使用平均絕對偏差 。
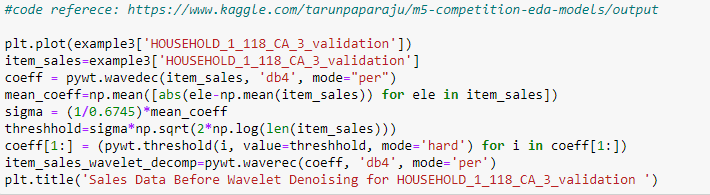

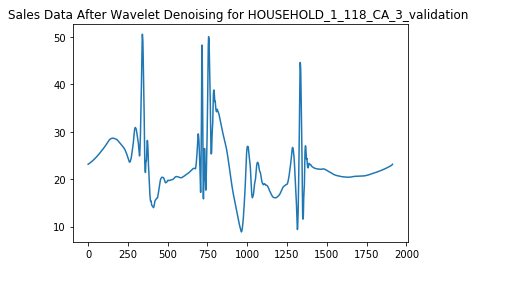
Observations:
觀察結果:
We are able to see a pattern more clear after denoising the data. It shows the same pattern every 500 days which we were not able to see before denoising.
去噪數據后,我們可以看到更清晰的圖案。 它每500天顯示一次相同的模式,這是我們在去噪之前無法看到的。
Moving Average Denoising:
移動平均降噪:
Let us now try a simple smoothing technique.In this technique, we take a fixed window sie and move it along out time-series data calculating the average. We also take a stride value so as to leave the intervals accordingly. For example, let's say we take a window size of 20 and stride as 5. Then our first point will be the mean of points from day1 to day 20, the next will be the mean of points from day5 to day25, then day10 to day30 and so on.
現在讓我們嘗試一種簡單的平滑技術,在此技術中,我們采用固定的窗口sie并將其沿時間序列數據移出以計算平均值。 我們還采用跨度值,以便相應地保留間隔。 例如,假設我們的窗口大小為20,跨度為5,那么我們的第一個點將是從第1天到第20天的點的平均值,下一個是從第5天到第25天的點的平均值,然后是從第10天到第30的點的平均值。等等。
So, let us try this average smoothing on our dataset and see if we find any kind of patterns here.
因此,讓我們對數據集嘗試這種平均平滑處理,看看是否在這里找到任何類型的模式。
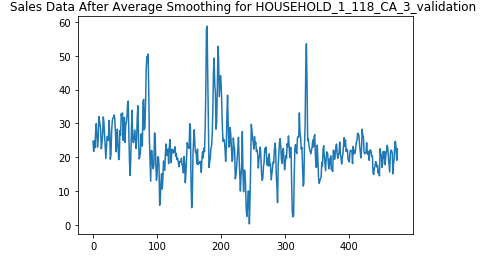
Observations:
觀察結果:
We see that the average smoothing does remove some noise but not as effective as the wavelet decomposition.
我們看到,平均平滑確實消除了一些噪聲,但效果不如小波分解。
每個州的總銷售額是否有所不同? (Do the sales vary overall for each state?)
Now, from a broader perspective let us see if the sales vary for each state:
現在,從更廣泛的角度來看,讓我們看看每個州的銷售額是否有所不同:

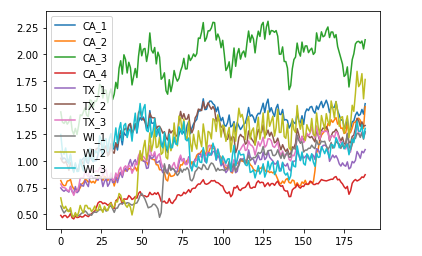
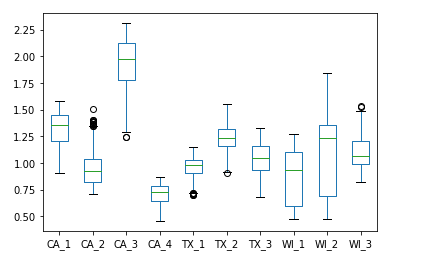
觀察結果: (Observations:)
- From the above plot we can see that the sales for store CA_3 lie above the sales for all other states. The same applies for CA_4 where the sales are lowest. For other sales the patterns are distinguishable to some extent. 從上圖可以看出,商店CA_3的銷售額高于所有其他州的銷售額。 CA_4的銷售額最低也是如此。 對于其他銷售,這些模式在一定程度上是可以區分的。
- One thing that we observe that all these patterns follow a similar trend that repeats itself after some time. Also, the sales reaches a higher value in the graph. 我們觀察到的一件事是,所有這些模式都遵循類似的趨勢,并在一段時間后重復出現。 同樣,銷售額在圖中達到更高的值。
- As we saw from the line-plot, the box plot also shows non-overlapping sales patternf for CA_3 nd CA_4. 從線圖中可以看到,箱形圖還顯示了CA_3和CA_4的非重疊銷售模式f。
- No overlapping between the stores of California and totally independent of the fact that all of these belong to the same state. This shows high variance for the state of California. 加利福尼亞的商店之間沒有重疊,并且完全獨立于所有這些商店都屬于同一州。 這表明加利福尼亞州的差異很大。
- For Texas the states TX_1 and TX_3 have quite smiliar patterns and intersect a couple of times. But TX_2 lies above them with maximum sales and more disparity as compared to the other two. In the later parts, we see that TX_3 is growing rapidly and is approaching towards TX_2. Hence, from this, we can conclude that sales for TX_3 increase at the fastest pace. 對于得克薩斯州,州TX_1和TX_3具有相當明顯的模式,并且相交幾次。 但是TX_2位于它們之上,與其他兩個相比,其銷售量最大且差異更大。 在后面的部分中,我們看到TX_3正在快速增長,并且正在接近TX_2。 因此,由此可以得出結論,TX_3的銷售額增長最快。
結論: (Conclusion:)
Hence, by just plotting few simple graphs we are able to know our dataset quite well. Its just a matter of questions that you want to ask to the data. The plotting will give you all the answers.
因此,僅繪制幾個簡單的圖,我們就能很好地了解我們的數據集。 這只是您要向數據詢問的問題。 繪圖將為您提供所有答案。
I hope this would have given you an idea of doing simple EDA. You can find the complete code in my github repository.
我希望這會給您帶來進行簡單EDA的想法。 您可以在我的github存儲庫中找到完整的代碼。
https://www.appliedaicourse.com/course/11/Applied-Machine-learning-course
https://www.appliedaicourse.com/course/11/Applied-Machine-learning-course
https://www.kaggle.com/tarunpaparaju/m5-competition-eda-models/output
https://www.kaggle.com/tarunpaparaju/m5-competition-eda-models/output
https://mobidev.biz/blog/machine-learning-methods-demand-forecasting-retail
https://mobidev.biz/blog/machine-learning-methods-demand-forecasting-retail
https://www.mygreatlearning.com/blog/how-machine-learning-is-used-in-sales-forecasting/
https://www.mygreatlearning.com/blog/how-machine-learning-is-used-in-sales-forecasting/
https://medium.com/@chunduri11/deep-learning-part-1-fast-ai-rossman-notebook-7787bfbc309f
https://medium.com/@chunduri11/deep-learning-part-1-fast-ai-rossman-notebook-7787bfbc309f
https://www.kaggle.com/anshuls235/time-series-forecasting-eda-fe-modelling
https://www.kaggle.com/anshuls235/time-series-forecasting-eda-fe-modelling
https://eng.uber.com/neural-networks/
https://eng.uber.com/neural-networks/
https://www.kaggle.com/mayer79/m5-forecast-keras-with-categorical-embeddings-v2
https://www.kaggle.com/mayer79/m5-forecast-keras-with-categorical-embeddings-v2
翻譯自: https://medium.com/analytics-vidhya/how-to-guide-on-exploratory-data-analysis-for-time-series-data-34250ff1d04f
季節性時間序列數據分析
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389912.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389912.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389912.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

TortoiseGit上傳項目到GitHub

496. 下一個更大元素 I

利用PHP擴展Taint找出網站的潛在安全漏洞實踐

美團騎手檢測出虛假定位_在虛假信息活動中檢測協調

869. 重新排序得到 2 的冪

org.apache.maven.archiver.MavenArchiver.getManifest


CertUtil.exe被利用來下載惡意軟件


回歸分析假設_回歸分析假設的最簡單指南

Spring Aop之Advisor解析
函數)
react事件處理函數中綁定this的bind()函數

301. 刪除無效的括號


Chrome無法播放m3u8格式的直播視頻流的問題解決

大數據相關從業_如何在組織中以數據從業者的身份閃耀


Django進階之中間件

